
基于贡献度随机森林模型的公司债信用风险实证分析
2016-11-09 10:04汪政元伍业锋
经济数学 2016年3期
汪政元+伍业锋


摘 要 运用贡献度随机森林方法(CRF)方法探讨公司债财务指标比率与其违约率的关系.运用连续属性离散化方法(OB)进行财务指标最优降维;运用WOE变换进行模型变量约简.研究表明,CRF模型的分类性能显著优于其他模型,测试集评估总体正确率达90.47%,AUC统计量、AR比率及K-S值分别提升了2.6%、7.6%、4.38%,变量贡献度量化了各财务指标对违约率影响,为诠释随机森林预测机制提供了依据.
关键词 财务管理;违约预测;实证分析; 贡献度随机森林; 连续属性离散化; WOE变换
中图分类号 F224 文献标识码 A
Abstract The contribution forest model(CRF) was used to research the inner connection between the corporate bonds and its financial index ratio,. The method of discretization and WOE transformation were applied to reduce the dimension of these indexes. The results show that the CRF model's performance significantly outperforms the other models, and the performance of the model on test dataset reaches a accuracy of 90.47%. And the other assessment indexes,AUC statistics, AR ratio and K-S values, are improved by 2.6%, 7.6%, 4.38%. Furthermore, the contribution of variables evaluated its influence on probability of default in a quantitative way, which provides a new point of view to interpret the process of forecast of random forest.
Key words financial management; default prediction; empirical analysis ; contribution andom forest model; discretization; WOE transformation
1 引 言
随着金融体系的快速发展,金融市场不断实现快速迭代不断更新,取得显著成就的同时,危机事件却频出不穷.2016年以来国内先后出现多起银行危机事件,先后有中国农业银行39.15亿元票据案件、中信银行9.69亿票据案件、天津银行7.86亿票据案件.上述危机之所以爆发,一个重要原因就是风险管理不当.而信用风险作为Basel新资本协议所强调的重要风险之一,由于其复杂多变,对信用风险的识别、计量往往面临更大的挑战.如何对借债企业的信用风险进行评估、预判其违约概率是信用风险管理的重点内容.因此,建立科学有效的信用风险评估模型,无论是对商业银行增强抵御风险能力,还是对企业管理者宏观审慎的战略决策均有显著意义.
从信用风险的现有研究成果来看,方法体系多分布于传统的统计分析方法、定性评级法、基于期权理论以及现代数据挖掘类方法.其中,最早研究开始于Altman(1968)[1], 认为企业违约可能性的大小与其财务健全与否有直接密切联系,选择五个重要的财务比率,建立了区别倒闭公司与非倒闭公司的Altman模型.Deakin(1972)[2]认为,己经破产、无力偿还债务的公司容易发生信用风险.由于我国目前信用评级机构尚不完善,信用评级数据严重缺失,国内关于企业信用风险的研究多从财务数据中提取特征指标建立相应信用评价模型.Prinzie(2008)[3]将随机森林方法与logistic方法相结合,利用随机森林的构造决策树的思想构建logistic决策森林,提高了logistic模型的估计精度.Yeh等(2012)[4]利用实际金融市场数据,基于KMV模型、随机森林方法、粗糙集理论构建混合KNV-RF-RST模型,评价企业信用风险问题.张奇等(2015)[5]构建了Logit-SVM混合评价模型,提高了模型在训练集上的二分类预测能力.Cui (2015)等[6]充分利用社交媒体大数据,结合BP神经网络模型,构建现代商业银行信用风险评价模型,拓展了传统的信用风险研究指标选择方式.上述研究从不同角度充实了信用风险评价研究,但多数研究都注重模型精度的提高,而忽略了在提高模型精度的同时增加模型的解释能力.如何改进已有的学习算法,在提高模型精度的同时也保证模型的解释能力、量化评估指标的贡献度.基于此,本文采用最优分箱(Optimal Binning,OB)和证据权重变换(Weight Of Evidence,WOE)对数据集进行转变进一步提升模型预测精度,并提出贡献度随机森林(Contribution Random Forest,CRF)方法分解预测函数,在提升预测性能同时也提升了传统RF模型的解释能力.
2 贡献度随机森林模型构建
2.1 随机森林原理回顾
随机森林是Breiman(2001)[8]提出的一种组合分类算法.随机森林通过随机的方式建立多个决策树,利用bootstrap抽样方法从样本数据中抽取k个bootstrap样本Si(i=1,2,…,k),再每次从原始M个自变量中选择n输入变量(nM),由被选择的n个自变量构成随机特征输入向量X,并利用分类回归树(CART)算法建立相应无剪枝的元决策树分类器,最后利用这k个元分类器构成一个组合分类决策系统,最终采用简单投票法做出最终预测.endprint
2.2 连续属性离散化与WOE变换
原始随机森林算法模型虽然分类精度高,但计算负荷大、评估速度慢,在数据集指标维度过大时这一点尤为明显.而对于采用信息熵、Gini指数作为节点分裂标准的随机森林而言,在决策树的生成过程中倾向于选择取值分布广的连续变量,无法有效处理连续变量属性,而通过离散化连续变量,恰可以消除这一影响.根据Fayyad和Irani(1993)[10]的基于熵的连续变量离散化最优分箱方法,以下简称最优分箱(Optimal Binning,OB),其原理和步骤如下:
(5)对分割后的左右子集,重复上述步骤,直至达到最大分组数K.
通过对连续变量进行OB分箱,一方面约束了连续变量的取值维度,使得各变量之间利用信息增益、Gini指数作为节点分裂标准有了可比性,且在一定程度上避免了极端值的影响;另一方面变量取值的降维大大降低了算法的开销.在上述连续变量分箱后,相当于若干个虚拟变量,这就导致原始数据集变量取值过于稀疏,因此需要对分箱后的数据进一步规约,考虑进行证据权重变换(Weight of Evidence,WOE) [10],对分箱后的变量进行重新编码.
从式(7)可以看出,CRF模型预测值可以分解为各决策树的初始决策值的平均值与各特征变量的平均贡献值之和.CRF模型虽然对随机森林对预测函数进行了分解,但最终对响应变量的预测结果和传统随机森林的投票法完全一致.
3 实证分析
3.1 数据准备与指标体系说明
选取发行公司债券的沪深上市公司作为研究对象,数据来源于WIND金融咨询终端,样本包括截止2016年8月1日已到期债券和已摘牌债券.由于企业的财务状况是企业经营现状的直接反馈,其信用风险亦可从财务指标角度考察,因此从财务指标比率的角度建立信用风险评价模型.参考中诚信、鹏元资信、大公国际等评级机构信用风险评价指标体系,结合刘畅[11]等提出的中小企业信用风险预警指标体系,从资本结构、盈利能力、偿债能力、营运能力、发展能力以及现金流量情况6个方面,遴选以下25项财务比率指标作为信用风险评估候选指标集,见表1.在研究样本中,剔除数据缺失严重的样本,最终初始样本量为230.在230只债券中,已发生违约的债券有28只,记为Bad类,正常债券202只,记为Good类.在数据时间截点选择上,选择债券违约发生前一年或被评级机构降级前一年的财务数据,以此达到建模预警目的.由于现有样本Bad类样本过少,为平衡样本结构,对于债券或主体评级为BBB以下、债券(主体)评级或评级展望被连续降级的也归为Bad类,最后利用SMOTE[12]方法选择每个Bad类样本临近的5个样本合成部分Bad类样本,最终Bad类样本为166.
3.2 模型设定
设定训练集与测试集比例为7:3,分别设定随机森林中元分类器数量为100、200、300、400,设定候选特征数的变化范围为2-25,训练集中各模型的OOB误差如图1所示.
在n=100,候选特征数为 8时,OOB误差达最小值为0.0702;在n=200,候选特征数为 4时,OOB误差达最小值为0.0742;在n=300,候选特征数为 4时,OOB误差达最小值为0.0661;在n=400,候选特征数为 3时,OOB误差达最小值为0.0713 .综合来看,随着模型训练次数的增加,OOB误差逐渐收敛于稳定水平,过高的训练次数范围反而增加计算负荷,而候选特征数不宜过大或多小,因此设定模型元分类器数量为300,候选特征数为4.在实施最优分箱过程中,对连续变量的分组数不宜过大也不宜过小,过大则无法达到降维的目的,过小则区分度不足.设定每次划分带来的信息增益最小阈值为0.01,最大分组数K的变动范围为3—10,不同分组条件下,随机森林模型的准确率情况如表2所示.当分组数等于3时,模型的准确率最低;当分组数等于5或6时,准确率达最大;当分组数大于6时,准确率开始下降.因此,设定最大分组数为5或6为宜,为减小计算负荷,此处设为5.
3.3 模型比较
经过前述OB-WOE变换、预测函数贡献度分解,即得变换后的CRF模型,为评估最优分箱WOE变换对其他模型影响,考察决策树、支持向量机、logistic回归、贝叶斯分类、KNN最近邻分类以及神经网路在最优分箱WOE变换下的预测表现,如表3所示.
在实施最优分箱WOE变换的训练集中,随机森林对Good类样本的准确率为98.39%,相比不变化情况上升了6.07个百分点;对Bad类的准确率为98.17%,上升了8.5个百分点.在测试集中,变换后的数据集对Good类样本的准确率为91.80%,对Bad类的准确率为89.13%,分别上升了2.5、6.5个百分点.由此可见,无论是对于训练集还是测试集,对于随机森林分类方法而言,OB-WOE变换后的数据集能显著提升模型分类效果.对于其他模型而言,提升效果较为明显的是logistic回归、神经网络.其中,logistic回归对于Good类的预测能力的提升效果尤为明显,训练集中由76.45%上升到90.32%,测试集中由76.82%上升到86.36%.对于神经网络而言,无论是测试集还是训练集,其Good类准确率和Bad类准确率都上升了10个百分点以上.究其原因,最优分箱本质是对数据集的一种规约,通过降低自变量取值维度来提炼各样本之间的共性,故对于分类评估模型而言,最优分箱后的数据往往更能提升分类效果.模型准确率只是模型评估的一方面,为综合评估一个信用风险评价模型,还需要从ROC曲线、K-S曲线、CAP曲线等角度综合度量.
3.4 模型总体效应评估
考虑到准确率只是评估模型优劣的一种方法,在信用风险评估研究中还经常从ROC曲线、CAP曲线及K-S曲线三个角度考察模型的曲线性质.其中,ROC曲线是在混合矩阵基础上利用图形综合揭示模型预测的灵敏性和误报率的一种方法,横轴表示误报率(模型错误预测的Bad类占比总Good类比率),纵轴表示灵敏性(模型正确预测到Bad类占比总Bad类比率).CAP曲线又称累计正确率曲线,CAP和准确性比率(AR)通常广泛用于信用评级领域,通过模型为受评对象计算一个风险评分,将风险评分作为其信用的综合评价,评分越高风险越大,通过求得不同风险评分范围百分比下累计违约的概率部分来刻画CAP曲线.K-S曲线是对模型区分Good类样本和Bad类样本的另一种评估方法,利用评估模型为每个研究样本计算一个违约概率,再将所有样本进行K等分分割,对每部分样本按照违约概率大小进行降序,计算每个样本中违约与正常百分比的累计分布,二者之间的差异就是K-S曲线的构成要素.endprint
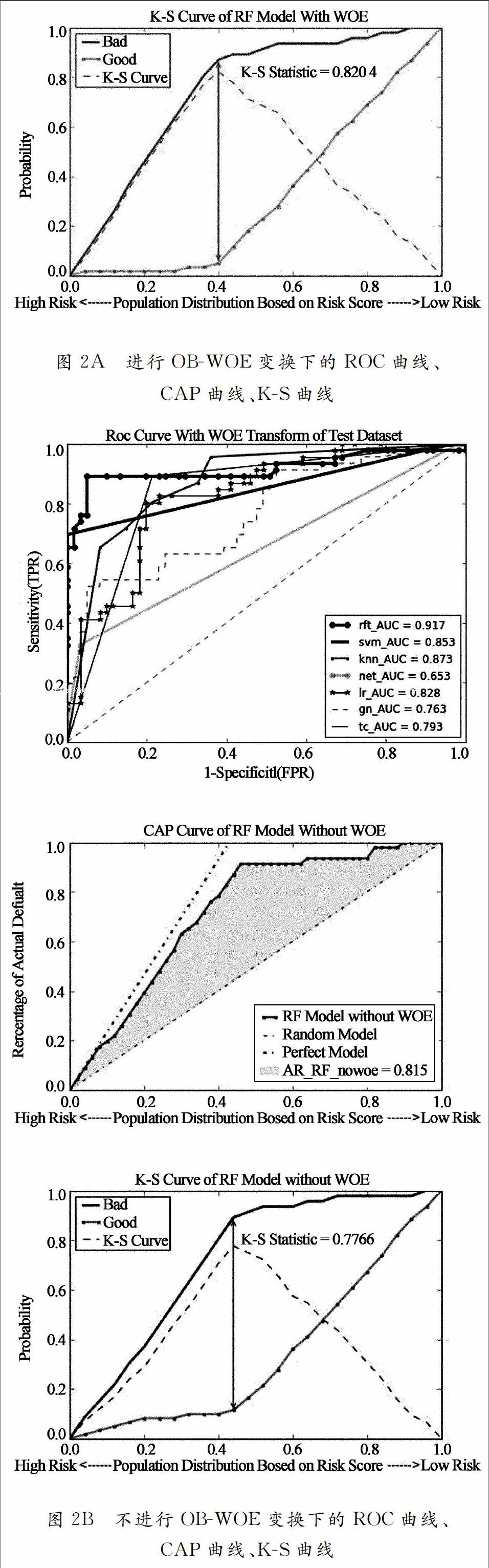
如图2所示,从各模型的测试集的ROC曲线来看,在误报率在0.05左右时,变换后的CRF模型对Bad类的覆盖率已达到92%,AUC统计量达0.943,而不变化的CRF模型模型对Bad类的覆盖率约88%,AUC统计量统计量为0.917.对于其他模型,变换前后效果也很明显,其中神经网络模型的AUC统计量有0.653提升到0.872,在误报率为0.1时的覆盖率由0.38左右提升到0.8.综合来看,实施变换后,各模型的优劣次序依次为随机森林、SVM、KNN、神经网络、logistics回归、贝叶斯、决策树,与测试集准确率评估结果基本一致.从各模型的CAP曲线来看,在前40%左右的样本,变换后的CRF模型的CAP曲线贴近理想结果,其AR比例为0.891,不变换的CRF模型的CAP曲线与理想结果有一定差距,最终其AR比率为0.815,说明进行最优分箱变换能提高模型对Bad类的辨识度.从K-S曲线来看,变换后的模型,其K-S值达到0.8204,而不变换的CRF模型其K-S值为0.776 6,处于较高水平,进一步说明进行连续变量的OB-WOE变换能提升模型的分类性能.
3.5 变量重要性与变量贡献度比较
根据式(7)建立变换后的CRF模型,以“11超日债”2013年年度财务数据为例,评估其变量贡献度,并对比随机森林方法下的变量重要性. 在变量贡献度分析方法下,各变量变量贡献度之和为0.802,即说明划分为Bad类的概率为0.802,从而可以认为其风险较高.评级机构在超日债违约后才将其信用等级下调至C级,在某种程度上有一定时滞.而根据变换后的CRF模型,基于“超日债”发债主体2013年年度财务指标数据可判断其违约概率为0.802,在判别“11超日债”为违约过程中,各变量的变量变量贡献度如表4所示.
由(7)式可知,在判断“11超日债”为Bad类过程中,贡献度排在前5位的变量与变量重要性排在前5位的变量重复率为40%;贡献度排在前10位的变量与变量重要性排在前10位的变量重复率为60%;贡献度排在前15位的变量与变量重要性排在前15位的变量重复率为73%;贡献度排在前20位的变量与变量重要性排在前20位的变量重复率为85%.其中吻合度较高的变量为EBITtoSaale、Asset_TR、Gro_profit、TAtoD_R、AR_TR;差异较大的变量为Z_Value、Inventory_TR、EM、LDA_R.这是因为变量重要性是对全部样本共性的提炼,旨在说明在各变量在总体数据集的表现情况,多用于从大量指标中选择有作用的变量;而变量贡献度侧重评估对象个性的描述,旨在说明在判断其为Good类或Bad类过程中,哪些变量发挥的作用相对明显,可用于个体分析判断.从贡献度来看,ROE的贡献度最大,说明从ROE角度相对最能说明超日债的风险情况,其次是EBITtoSaale、GropToRev、NetPro_M等等,这也与实际的财务分析理念一致.企业长期经营战略必须提升其ROE,ROE过低则自有资产利用效率低,偿债压力增大.此外,还注意到贡献排名前12的变量中,其WOE值均为正,说明该分组子集中负例占比总负例的比率大于集中正例占比总正例的比率,即落入该分组的个案更多体现Bad类别的特征.结合 “11超日债”实际财务数据来看,其ROE为-1169.6,EBITtoSaale 为-793.56、GropToRev为-64.317、ROA为-65.783等均远低于平均水平,而其Z_Value为-3.34,远远低于Altman的破产概率预警阈值1.8[1],从而上述指标在 “11 超日债”的判别过程中区分能力强,对违约率影响显著.
因此,从预测结果分解的维度上来看,CRF模型是对预测过程的一个分解,将“黑盒”的决策过程还原为各变量的贡献度之和,进而衡量在预测过程中哪些变量发挥的作用相对明显,再从财务分析角度予以对比印证,在个案分析层面增加了模型的可解释性.
4 结 论
针对传统随机森林方法的“黑盒”弊端提出贡献度随机森林方法,通过变量贡献度视角研究了财务指标与违约率的关系.利用对数据集进行基于熵的最优分箱处理、WOE变换实现数据集约简目的,并进一步构建CRF模型评估变量在个案预测过程中的贡献度,实现预测过程的可解释性,最后基于ROC曲线、CAP曲线、K-S曲线对模型进行评估.经对比分析,实施最优分箱、WOE变换能有效提升各模型的准确率,但仍属CRF模型准确率最高,达90.47%.相比不变换的CRF模型,其AUC统计量、AR比率、K-S值分别提升了2.6%、7.6%、4.38%.在“11 超日债”单个样本评估分析中,变量贡献度和指标重要性排在前5、10、15、20位指标的重复度分别为40%、60%、73%、85%,两种评估方式一致程度高.变量贡献度排名靠前的指标均对违约率影响显著,通过变量贡献度角度分解了随机森林预测过程,量化各项指标的影响大小,增加了模型的可解释性.
参考文献
[1] Altman E I. Financial Ratios, Discriminate analysis and the prediction of corporate bankruptcy[J].Journal of Finance,1968, 12(23):589-609.
[2] Deakin E B. A discriminate analysis of prediction for business failure[J]. Journal of Accounting Research,1972, 14(10):167-169.
[3] Prinzie A, Van den Poel D. Random forests for multiclass classification: Random multinomial logit[J]. Expert systems with Applications, 2008, 34(3): 1721-1732.endprint
[4] Yeh C C, Lin F, Hsu C Y. A hybrid KMV model, random forests and rough set theory approach for credit rating [J]. Knowledge-Based Systems, 2012, 22(33):166-172.
[5] 张奇, 胡蓝艺, 王珏. 基于Logit与SVM的银行业信用风险评价模型研究[J]. 系统工程理论与实践,2015, 10(7):1784-1790.
[6] Cui D. Financial credit risk warning based on big data analysis [J]. Journal of Accounting Research , 2015, 8(10):133-141.
[7] 李军,信聪,陈暮紫,杨晓光. 诉讼处置不良贷款违约损失率估计的模型簇[J].系统工程,2015, 11(08):123-132.
[8] Breiman L. Random forests[J].Machine Learning,2001, 45(1):145-168.
[9] Fayyad U M, Irani K B. Multi-interval discretization of continuous valued attributes for classification learning[J]. Thirteenth International Joint Conference on Articial Intelligence, 1993, 12(2):1022-1027
[10]Bill H Y, Mykola T . Modeling exposure at default and loss given default: Empirical approaches and technical implementation [J]. Journal of Credit Risk, 2012, 8(2):81-102
[11]刘畅, 郭敏, 莫铌, 等. 基于巴塞尔协议Ⅱ内部评级法构建我国商业银行中小企业贷款信用风险有效度量和预警指标体系[J]. 金融监管研究, 2012, 12(7):26-39.
[12]Chawla N, Bowyer K, Hall L. Smote: Synthetic minority Over-Sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(3):321-357.endprint
猜你喜欢
河南水利年鉴(2020年0期)2020-06-09
消费导刊(2018年8期)2018-05-25
商场现代化(2016年26期)2016-11-21
经营者(2016年12期)2016-10-21
经营者(2016年12期)2016-10-21
行政事业资产与财务(2016年10期)2016-09-26
行政事业资产与财务(2015年23期)2015-10-26
现代农业(2015年5期)2015-02-28
河南科技(2014年22期)2014-02-27
