
基于Hadoop的心电数据库存储研究*
2016-11-09 08:32熊艳陈宇蒋文涛王冠石舒敬恒
生物医学工程研究 2016年3期
熊艳,陈宇,蒋文涛,王冠石,舒敬恒
(1.四川大学制造与工程学院,创新方法与创新设计实验室,成都610065;2.四川大学工程力学系,生物力学工程实验室,成都610065)
1 引 言
心血管疾病、传染病和癌症是当前人类死亡的三大主要原因,其中心血管疾病是人类死亡首要原因[1]。心脏疾病的快速检测因此显得尤为重要。目前心脏远程检测系统在国内外已经应用于临床,对心脏病患者进行长时间心电监护是治疗心脏病的重要手段,同时也是预防突发性心脏病导致严重后果的重要途径[2]。随着移动互联网、物联网等技术,大数据时代(Big Data)已经来临,大数据有四个特点:规模性、多样性、高速型和灵活性。大数据是继云计算和物联网之后IT行业的又一次颠覆性技术变革[3]。
2 Hadoop平台
Hadoop是大数据平台的代名词,具有分布性、高可靠、通用性、高效率、成本低等特点,是Apache下的一个项目,也是Google云计算模型的开源实现。Hadoop的文件系统[4]、MapReduce框架[5]和Bigtable[6]都是根据这些核心技术来实现,其中两个非常重要部分就是HDFS(hadoop distributed file system,HDFS)和MapReduce并行计算框架。经过多年发展,已经形成了以Hadoop为核心的大数据生态系统,也是通用的大数据处理基础构架平台。Hadoop增加了数据管理和信息提取的困难性和复杂性,因此,对大数据的存储管理非常重要。
考虑到安装配置的方便,使用Linux作为Hadoop的开发测试环境,在Windows下安装VMWare虚拟机,在虚拟机上安装 Ubuntu/Linux环境,然后再依次安装 Hadoop,NoSQL数据库HBase,数据仓库HIVE和分布式系统的协调服务Zookeeper,完成整个系统的搭建。
3 心电数据库设计
3.1 心电数据格式
心电图数据格式采用Philips公司的Trim II型心电图机,记录的心电信息数据和心电图机测量的波形参数,存放为大小200~250 K的XML格式数据文件[7]。心电数据中,其中一部分数据格式和设备中导联数量密切相关,另外包含数据量在200 K左右的一个波形文件[8]。
3.2 数据库设计
Hadoop采用HBase数据库。HBase适用于存储松散型非结构化数据,面向列的Key-value数据库,表索引由行关键字、列关键字和时间戳组成,HBase只有字符串类型,以HDFS为底层框架[9],是Bigtable在Hadoop框架上的实现。
HBase二维表结构中,Column Family(CF)包含多个Column Key(CK),CK可以动态增加,CK是列标示,RowKey是行标示。在传统数据库一对多的处理上,可以以相同患者在一个时间点作为RowKey,达到一对多的效果。比如患者ID为ID00010的患者,在2015年10月10日上午10点正的采集数据的RowKey就是“ID00010-1444442400”,前面是患者ID,后面是timestamp,主表信息和12导联的信息都采用相同的RowKey,实现一对多的主从关系表。
3.3 应用场景设计
假设医院有50名患者需要进行心电监控,远程心电监控仪每分钟发送一次数据,需要保存一个月的数据,同时需要及时呈现每天的实时数据。因此,针对每位患者每天1440次采集,需要记录的数据量每月就是4.32万次。50位患者的记录数就是216万次。如果采用12导联的心电仪,以刚刚分析的数据库设计来看,每一导联需要一次记录,这样记录数是两千多万个记录。同样,记录一年的数据量将达到3亿条。

图1 JSON格式的心电数据[10]Fig 1 The format of JSON for ECG data[9]
如果同时记录的患者人数再增加的话,那么每年将产生几十亿条记录的心电数据,这样海量的数据,将成为医院极大的负担。如何实时监控患者的信息,当患者心电数据出现问题如何报警?如何对海量数据进行预测?都将面临极大的问题,这些问题,同时也是大数据普遍存在的问题。
3.4 测试结果及分析
本次测试在下面环境完成:
硬件环境:DELL XPS 8700-R38N6型主机,内存 16G,主频3.6GHz。
系统环境:Windows8.1系统。
软件环境:VMWare Workstation 8.0,Hadoop 2.5.0,HBase1.1.2,HIVE1.2.1,ZooKeeper3.4.6
3.4.1 数据存储时间 向HBase数据库写入50位患者在一个月中以每分钟采集一次的间隔,进行实时心电数据的收集。
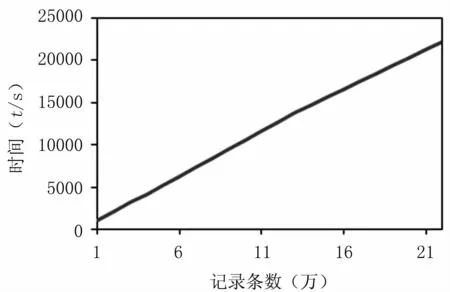
图2 Hadoop心电数据入库时间Fig 2 Hadoop ECG data storage time
从测试结果来看,每10万条记录写入的时间是1 000 s,完成也就是每秒可以写入100位患者的心电数据,完成50位患者一个月的数据记录的数据库写入时间是375 min。也就是说,平台可支持的最大容量是每分钟对六千位患者的心电数据进行实时记录,即每分钟采集一次的采样频率,可以达到支持6 000位患者的并发能力,完全满足实际要求。
3.4.2 数据查询时间 采用scan Rowkey的方式,从数据库取得1 min,1 h,1 d的数据量,调查数据查询的时间。

从上面测试结果可以看出,取得一位患者一天的心电数据需要4 s时间,数据库的总记录数是3千万条,按此效率进行读取可以满足实际需求,能够实时提取数据,对数据进行实时分析。
HIVE是基于Hadoop的数据仓库平台,HIVE定义了类似SQL的查询语言,能够将SQL转化为相应的Mapreduce程序执行。下面是HIVE执行结果:

可以看出,对于一条记录的查询时间,HIVE都经历了Map和Reduce阶段,时间大约是2 min,比Hbase shell的执行时间慢了两个数量级,并不适合实时查询。因此,HIVE适合做离线分析,类似SQL的语法更便于分析。
3.4.3 数据存储空间 HBase是Apache下Hadoop的子项目,是一个分布式、面向列的开源数据库,Rowkey是HBase的主键,每次写入Column的时候,都会带上Rowkey和Timestamp,因此,HBase的存储空间利用不及 MySQL等结构化数据库,也不及MongoDB等文档数据库。
HDFS是Hadoop分布式文件系统,HDFS可以使用廉价的硬件搭建系统,并能提供可容错的高性能服务和高吞吐量的数据访问,非常适合在大规模数据集群上应用。HDFS为了保证高可靠性和高可用性,采用了冗余存储的方式,一份数据至少保存3个以上的备份,所以存储空间上,Hadoop和传统数据库相比,有很大的劣势,但是保证了数据存储的可靠,即使有数据节点坏掉,也不会造成数据的丢失。
4 结束语
从大数据的角度来看,Hadoop无疑是目前应用最为广泛的大数据库平台,对海量数据存储、数据挖掘和并发响应等,在处理心电大数据方面有自身的优势。只有解决大数据存储才能使实时采集心电监控数据成为可能。通过本文的研究,针对心电大数据的存储,以Hadoop分布式集群技术,在存储时间和访问效率上都能很好满足心电数据的存储要求。
猜你喜欢
昆明医科大学学报(2021年4期)2021-07-23
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
中国生物医学工程学报(2019年6期)2019-07-16
心电与循环(2019年2期)2019-02-19
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
