
多视角分布式视频编码中基于置信度的时空边信息融合
2016-11-09 01:11黄碧波唐振华覃团发
计算机应用与软件 2016年9期
黄碧波 唐振华,2,3* 覃团发,2,3
1(广西大学计算机与电子信息学院 广西 南宁 530004)2(广西多媒体通信与网络技术重点实验室培育基地 广西 南宁 530004)3(广西高校多媒体通信与信息处理重点实验室 广西 南宁 530004)
多视角分布式视频编码中基于置信度的时空边信息融合
黄碧波1唐振华1,2,3*覃团发1,2,3
1(广西大学计算机与电子信息学院广西 南宁 530004)2(广西多媒体通信与网络技术重点实验室培育基地广西 南宁 530004)3(广西高校多媒体通信与信息处理重点实验室广西 南宁 530004)
在现有的多视角分布式视频编码MDVC(Multi-view Distributed Video Coding)边信息SI(side information)生成方法中,时间与空间边信息的融合未能有效地选择和提取两种边信息的可靠部分。针对这个问题,提出一种基于置信度的时空边信息的融合方法。利用时间和空间边信息的可靠性模版以及时空置信度的模版,获得时空融合模版;然后,利用时空融合模版从时间边信息与空间边信息中选择出最优的像素组成最终的融合边信息。实验结果表明,在相同码率的条件下,获得的峰值信噪比PSNR(Peak Signal to Noise Ratio)相比于时间主导融合方法最高有0.79 dB的提升,相比于时空补偿融合模板最高有0.58 dB的提升。此外,获得的重构帧能有效地保留原始图像的细节部分。
多视角分布式视频编码边信息融合置信度
0 引 言
多视角分布式视频编码MDVC[1]是将分布式视频编码DVC(Distributed Video Coding)[2]与多视角视频编码MVC(Multi-view Video Coding)[3]相结合的视频编码方法。MDVC有机地融合了DVC将编码端复杂度转移到解码端的特点以及MVC中的视差预测技术,适合于由多个资源受限的终端设备组成的无线视频应用,如无线视频监控和无线视频传感器网络等。MDVC采用Wyner-Ziv(WZ)编码方式[4]时,由于WZ帧经编码之后仅将校验位传递到解码端,解码端需利用已解码的信息生成一个WZ帧的估计,即边信息SI来辅助解码。在相同的重构视频质量的条件下,边信息的质量越好,解码所需要的校验位就越少,所需要的编码码率越小。MDVC解码过程中将生成两种边信息:时间边信息与空间边信息。一般而言,时间边信息能较好地保留背景部分,空间边信息能较好地保留前景部分,利用融合模版将时间边信息与空间边信息相融合能有效地提高最终边信息的质量[5]。
目前,针对时间边信息与空间边信息的融合方法主要有三类。第一类是在像素层面上生成针对时间边信息可靠程度的模版,并以此为基准生成最终的融合模版,称为时间主导融合模版,空间边信息在融合过程中只是起辅助作用。文献[6]首先提出该类边信息融合方法,在编码端得到二进制的时间像素转移模版;然后在解码端利用这个模版与已经解码的WZ帧的前后两帧来生成一个相关帧;最终的融合边信息的像素采用时间边信息与空间边信息中更接近相关帧的像素值。然而,该方法存在三个缺点:1) 实际生成时间边信息或者空间边信息要经过像素内插,相关帧的参考价值下降;2) 融合模版的生成过程中没有判断空间边信息可靠性,最终融合的效果也会下降;3) 需要编码端生成像素转移模版,会增加编码端的计算与传输的开销,违背了分布式视频编码中编码尽量简单的原则。
第二类方法是在像素层面上生成针对空间边信息可靠程度的模版,对空间边信息中不可靠的位置采用时间边信息对应位置的像素值,称为空间补偿融合模版。代表方法是Maugey等人提出基于密集视差的边信息融合模板生成方法[7]。该方法利用计算机视觉中相关技术生成左右视角的视差图,然后对视差图中显著的位置采用空间边信息,其余位置选用时间边信息。由于目前生成视差图的方法在精确度上都有所欠缺,不能在像素层面上有效地实现前景与背景的区分。Zhang等人提出基于运动矢量映射与3D曲线的边信息融合模板生成方法[8]。该方法利用左右视角在3D曲面上的差异,以左右视角为基准生成两个空间像素转移模板,相互异或得到最终的像素转移模板。该方法充分考虑了同一个物体在左右视角中成像的轮廓的差异,能够极为准确地获得空间边信息的可靠程度。但是,由于没有分析时间边信息的可靠程度,若空间边信息的生成质量不高时,融合的效果很差。
第三类方法是在像素层面上分别得到时间边信息与空间边信息的可靠性模版,综合分析得到最终的融合模版,称为时空补偿融合模版。代表技术为Brites等人在文献[9]中提出的时空转移融合TVDF(Time-View Driven Fusion)技术。在解码端对时间上WZ帧的前后两帧与时间边信息两两做残差运算,对得到的残差图像进行处理得到三个像素可靠性模版,综合分析得到时间边信息的可靠性模版。利用计算机视觉中投影矩阵得到左右视角向中间视角的投影图像,分别结合WZ帧的前一帧,按照时间残差帧的生成办法得到两个投影图像的可靠性模版,综合分析得到空间边信息的可靠性模版。综合分析时间边信息与空间边信息的可靠性模版,得到最终的时空融合模版。相比于前两种方法,TVDF方法能有效地提高最终的时空融合边信息的效果,不受时间边信息与空间边信息质量的影响。但是该方法主要存在两个缺点:1) 空间像素转移模版的生成方法需要使用摄像机参数中的投射矩阵,而如今的摄像机大部分都是变焦的,焦距的改变会改变投射矩阵,在现实环境中很难实现;2) 没有区分时间与空间边信息在相同位置上的置信度。只是认为在时间边信息不可靠而空间边信息可靠时,选用空间边信息对应位置的像素值,没有分析更多的情况。
为了解决上述时空边信息融合方法中存在的问题,本文提出一种基于置信度的时空边信息融合方法。该方法利用时间边信息生成阶段得到的运动矢量与空间边信息生成阶段得到的视差向量,得到时间与空间边信息之间的置信度;再结合时间像素转移模版与空间像素转移模版,得到最终的时空融合模版,进而获得最终的时空融合边信息。
1 多视角分布式视频编码框架
本文采用文献[9]中的多视角分布式视频编码框架。如图1所示,以三个视角联合编码为例,对左右视角与中间视角的关键帧(K帧)采用传统的帧内编码,中间视角的WZ帧采用Wyner-Ziv编码,具体流程如下:在编码端对WZ帧进行DCT变换和量化,对量化系数进行低密度校验编码LDPC(Low Density Parity Code),将得到的校验位存放在缓存器中;在解码端利用中间视角的前后帧生成时间边信息,左右视角相同时刻已经解码的帧生成空间边信息,经过视角融合得到最终的边信息;将边信息传递到相关噪声建模CNM(Correlation Noise Model)模块,得到相关噪声系数;LDPC解码器利用边信息、相关噪声系数与从缓存器中得到的校验位得到解码后的码流;经过重构与反DCT变换得到最终解码后的视频帧。

图1 多视角分布式视频编码框架
2 基于置信度的时空边信息融合方法
现有时空边信息融合方法中主要存在两个问题:1) 在生成时空融合模版时,只单独确认了时间边信息或空间边信息的可靠程度,没有对两种边信息地可靠程度进行区分;2) 没有充分分析所有可能的情况,简单地在时间边信息不可靠时采用空间边信息或空间边信息不可靠时采用时间边信息,没有提出当时间边信息与空间边信息都可靠或都不可靠时的处理办法。针对这两个问题,本文提出了一种基于置信度的时空边信息融合方法,具体实现框架如图2所示。

图2 时空边信息融合模版生成框架
2.1时间边信息可靠性模版生成

(1)
其中,D(x,y)代表残差图像的像素值,x为水平方向坐标,y为垂直方向的坐标。
(2) 直方图均衡化。原始的残差图在很多区域的值过于集中,无法准确进行可靠性区分。为了获得更加明显的差异,需要对其进行直方图均衡化处理[11]。计算残差图像中像素的累计归一化直方图Dc,并记录残差图像中的最大值PMAX与最小值PMIN。最终均衡化的结果为DE,其计算公式为:
DE(x,y)=Dc[D(x,y)]×(PMAX-PMIN)+PMIN
(2)
θ=(μ0+μ1)×0.5
(3)
直到θ的值趋向稳定,最后得到归一化图像S:
(4)
(5)
其中,FT的值为0代表时间边信息中的像素值是可靠的,对应原始WZ帧中背景的部分;1代表时间边信息中该位置的像素值不可靠,对应原始WZ帧中前景的部分。
2.2空间边信息可靠性模版生成

(2) 空间边信息可靠性模版生成。由于左右视角存在边界或遮盖等情况,空间边信息不完全是由左右视角相同物体的像素取均值得到,实际操作中可能单独使用了左视角或者右视角的像素值。为了更好地表示空间上左右视角之间像素的差异性,空间像素模版FS采用三种值表示不同的可靠程度。
(6)
其中,如果FS的值为2,表示空间边信息中该位置是可靠的,对应原始WZ帧的前景部分;如果为0,则代表空间边信息中该位置完全不可靠,对应原始WZ帧的背景部分;1则代表该空间边信息在该位置的可靠性未知。
2.3时空置信度模版生成
虽然时间与空间可靠性模版FT与FS能较好地体现时间边信息SIT、空间边信息SIS与原始WZ帧的相似程度,但是当FT与FS所代表的位置都可靠或者都不可靠时无法进行可靠程度区分,即无法判断此时SIT与SIS谁更接近原始的WZ帧。为了解决这个问题,本文提出一种基于像素的时空置信度模版FT&S的生成方法。
Dufaux在文献[13]提出用像素差异表示置信度的筛选原则。在边信息的生成过程中大部分区域都是采用像素内插的方法,若WZ帧在时间上前后两帧对应的映射块的差异越大,说明时间边信息在该映射块位置与原始WZ帧的差异越大,空间边信息也遵循这个原则。本文采用绝对差值和SAD(sum of absolute difference)表示块之间差异,若WZ帧的基准块在空间上左右视角中的映射块之间的差异值SADS小于在时间上前后两帧的映射块之间的差异值SADT,说明空间边信息在这个基准块的位置上更接近原始的WZ帧,反之则时间边信息更接近。
直接使用块进行操作会降低最终结果的精确度,即使时间边信息对应块的置信度更高,也可能存在空间边信息对应块中部分像素更接近原始的WZ帧的情况。为了解决这个问题,本文对块内像素按照该块的运动矢量和视差向量的映射分别计算差的绝对值并进行对比。实际操作中运动矢量和视差向量存在很多错误,需要对对应块之间的SAD值和像素之间的差异值进行限定,具体步骤如下:
步骤1越界判断。以像素为单位,代入该像素所属块的时间运动矢量MV与空间视差向量DV,并判断对应的像素的位置是否越界。如果代入MV后没有越界而DV越界,表示时间边信息更可靠,将该像素位置的FT&S的值设为0;如果代入DV后没有越界而MV越界,则表示空间边信息更可靠,将其设为1;如果代入DV与MV都越界,表示时间边信息与空间边信息可靠性未知,将其设为2。通过越界判断可以确保MV与DV对应的位置存在。
步骤2块可靠性判断。计算待处理像素所属的块代入MV后在时间上前后帧中对应块之间的绝对差值和SADT,与代入DV后空间上左右视角在当前时刻的帧中对应块之间的绝对差值和SADS。设置阈值TB,当SADT小于TB而SADS大于该阈值时,该像素位置FT&S的值设置为0;当SADT大于TB而SADS小于该阈值时设为1;当SADT与SADS都大于TB时设为2;当SADT与SADS都小于TB时进行下一步操作。
步骤3像素可靠性判断。计算待处理像素位置代入MV后在时间上前后帧对应位置像素值之间的差异PixelT,代入DV后在空间上左右视角在相同时刻的帧对应位置像素值之间的差异PixelS。设置阈值TP,当PixelT小于TP而PixelS大于该阈值时,该像素位置FT&S的值设置为0;当PixelT大于TP而PixelS小于该阈值时设为1;当PixelT与PixelS都大于TP时设为2;当PixelT与PixelS都小于TP时进行下一步操作。
步骤4最终置信度模板生成。经过步骤1-步骤3的操作后可以认为PixelT与PixelS分别代表时间与空间边信息在该像素位置的置信度。当PixelT小于PixelS时,该像素位置FT&S的值设置为0;当PixelT大于PixelS时设为1;当PixelT等于PixelS时设为2。
2.4时空融合模版生成
通过2.1节、2.2节和2.3节可以分别得到生成过程不相关的三个模板,最终时空融合模板的生成需要确定不同模板之间的权重。当时间边信息质量远超空间边信息时,以时间边信息可靠性模板为主,用空间边信息可靠性模板与时空置信度模板进行辅助纠正;当空间边信息效果超过时间边信息时,以空间边信息可靠性模板为主;当时间运动矢量与空间视差向量准确度较高时,时空置信度模板最为接近理想状况。
目前,时间边信息的生成方法较为成熟,而空间边信息的生成方法对不同景深、视差的序列的结果存在较大差异[14]。为了克服上述问题,本文采用以时间像素转移模板与空间像素转移模板为主,用时空置信度模板辅助生成时空融合模板F(x,y),具体步骤如下:
(1) 当FT(x,y)值为0以及FS(x,y)值为0或1时,说明图像中(x,y)位置上的时间边信息可靠而空间边信息不可靠。此时,F(x,y)的值设为0,表示时空融合边信息在该位置采用时间边信息中对应位置的像素值。
(2) 当FT(x,y)值为1而FS(x,y)值为2时,图像中(x,y)位置上时间边信息不可靠而空间边信息可靠。F(x,y)的值设为1,表示时空融合边信息在该位置采用空间边信息中对应位置的像素值。
(3) 当FT(x,y)值为0而FS(x,y)值为2时,图像中(x,y)位置上时间边信息与空间边信息都可靠,需要利用时空置信度模板进行进一步区分。若FT&S在(x,y)位置的值为0,则F(x,y)的值为0;若FT&S为1,则F(x,y)的值设为1;如果FT&S值为2,表明时间上前后帧的差异要小于空间上左右帧的差异,可将F(x,y)的值设为0。若序列在时间上变化远大于空间上的差异,则F(x,y)的值设为1。
(4) 当FT(x,y)值为1而FS(x,y)的值为0时,图像中(x,y)位置上时间边信息与空间边信息都不可靠,与(3)相同。
(5) 当FT(x,y)值为1而FS(x,y)的值为1时,时间边信息不可靠而空间边信息可靠性未知。若FT&S在(x,y)位置的值为0,则F(x,y)的值设为0;若FT&S值为1或者2,则F(x,y)的值为1。
由于利用了时空置信度模板,并考虑了各种可能情况,故本文提出的时空融合模版生成方法得到的融合边信息更加接近实际的WZ帧。
3 实验结果及分析
本文的仿真实验平台采用以基于LDPC码的DCT域的Wyner-Ziv编码系统[2]为基础的多视角分布式视频编解码系统。实验采用ballroom、vassar与exit这三个序列,视频序列的分辨率为176×144,格式为YUV420,长度为50帧。实验中,编码结构设为IPIPIPIP,帧率为20帧/秒。采用JPEG的帧内编码方式对左右视角与中间视角的K帧进行编码,WZ帧与K帧都采用JPEG量化码表。本实验中出现的参数设为TB=500,TP=25。时间边信息生成方法采用传统的时间运动内插补偿[9],空间边信息生成方法采用传统的视角预测视差补偿[5],对比算法采用在线的以时间主导融合方法[5]与时空补偿融合方法[8]。
图3给出了在三个算法在三个序列中的率失真(R-D)曲线。从图中可以看出,本文的时空融合方法在不同序列、量化级别下都有一定程度的提升。在vassar序列中码率为177.41 kbps时相比于时间主导融合方法,峰值信噪比的提升最大为0.79 dB。这主要是由于这个序列中空间边信息的结果相对较好,而时间主导融合方法对空间边信息利用较差。在exit序列中码率为324.40 kbps时相比于时空补偿融合模板,峰值信噪比提升最大为0.58 dB。这主要是由于这个序列的景物深度差异很大,时间边信息与空间边信息的结果都不太好,而时空补偿融合模板没有对时间边信息与空间边信息的可靠程度进行区分。在ballroom序列中,三个算法效果相当,本文的算法略优。出现这种情况主要是由于该序列中时间边信息与空间边信息的结果都较为优秀,不论采用哪种边信息,结果差异不大,由于本文综合分析了所有可能情况,因此效果相对最优。

图3 三种序列的R-D曲线
为了更加详细比较上述三种融合方法的性能,表1给出了ballroom、vassar和exit视频序列在不同量化系数和不同时空边信息融合方法下WZ系统的平均PSNR与平均码率。从表1可以看出,本文提出的基于置信度的时空边信息融合方法在不同的量化系数下达到相同PSNR所需的平均码率均小于时间主导融合方法与时空补偿融合方法。这主要是由于本文的方法对时间边信息与空间边信息的可靠程度进行了区分,并分析了所有可能性。在计算复杂度没有明显增加的情况下,能够有效地降低MDVC系统的码率,提高压缩性能。
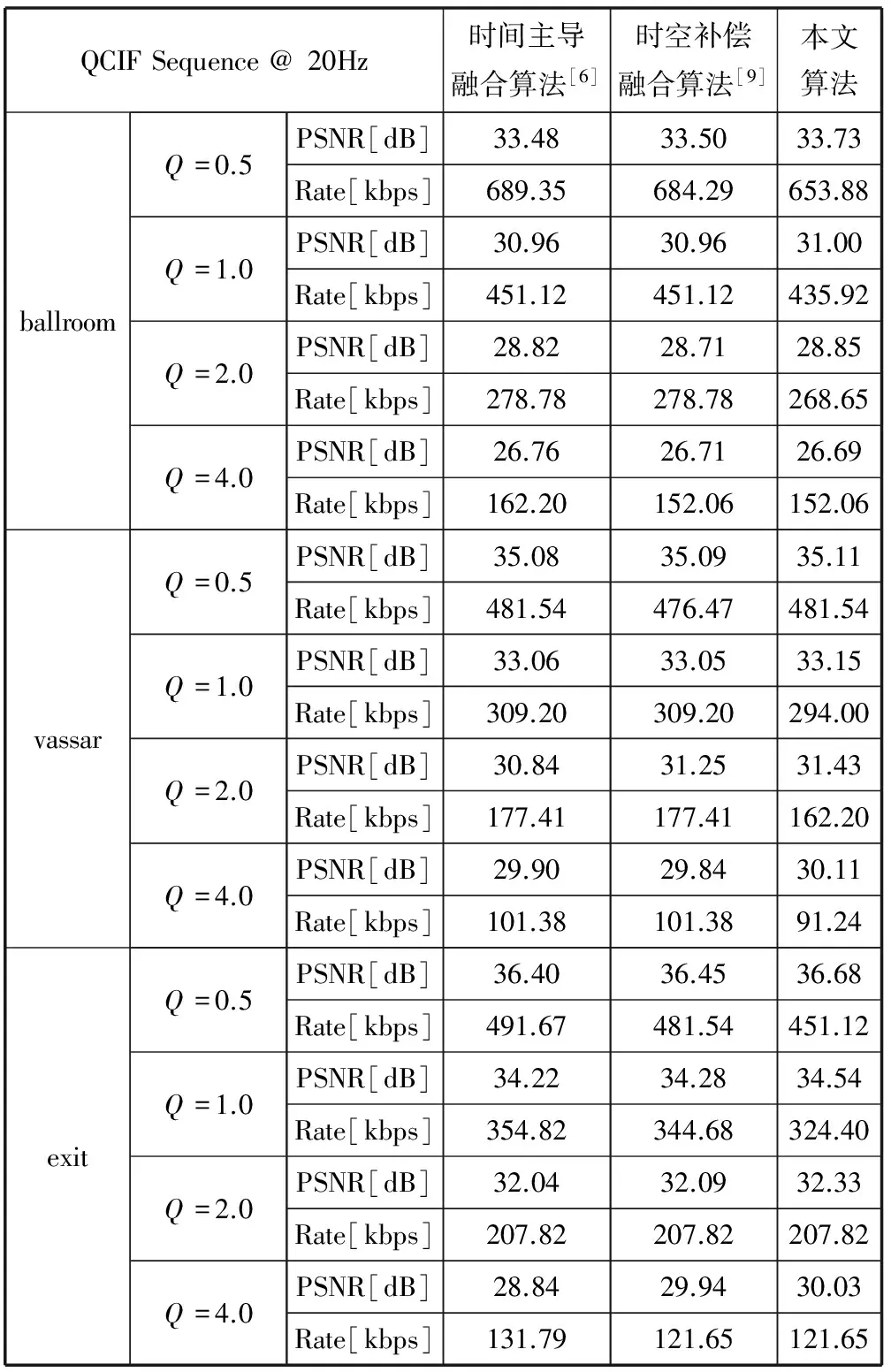
表1 ballroom、vassar和exit对应的平均PSNR值和平均码率
图4给出了vassar序列的第二帧在量化参数Q=0.5的情况下采用不同融合模板得到的融合边信息的视觉效果。可以看出,本文算法能最好地保留图像中汽车和门的边框部分。时间主导融合方法没有分析空间边信息的可靠性,无法剔除空间边信息中不可靠的部分。时空补偿融合方法由于没有引入对时间边信息与空间边信息可靠程度的分级,没有选择出时间边信息与空间边信息中最优的部分。

图4 vassar序列中第二帧在不同实验下视觉对比图
4 结 语
本文针对现有时空边信息融合中存在的问题,提出了一种基于置信度的时空边信息融合方法。该方法利用边信息生成阶段得到的时间上的运动矢量与空间上的视差向量得到时空置信度模板,再结合时间边信息可靠性模板与空间边信息可靠性模板,得到最终的时空融合模板。在相同码率下,相比于时间主导融合方法最高有0.79 dB的提升,相比于时空补偿融合模板最高有0.58 dB的提升。此外,本文的算法能较好地保留图像中的细节部分,主观效果更加优秀。
[1] Guo X,Lu Y,Wu F,et al.Distributed multi-view video coding[C]//Visual Communications and Image Processing,Florida,United States,April 17-21,Bellingham:SPIE,2006.
[2] Girod B,Aaron A M,Rane S,et al.Distributed video coding[J].Proceedings of the IEEE,2005,93(1):71-83.
[3] Hannuksela M M,Rusanovskyy D,Su W,et al.Multiview-video-plus-depth coding based on the advanced video coding standard[J].IEEE Transactions on Image Processing,2013,22(9):3449-3458.
[4] Xu Q,Xiong Z.Layered wyner-ziv video coding[J].IEEE Transactions on Image Processing,2006,15(12):3791-3803.
[5] Brites C,Pereira F.Multiview side information creation for efficient Wyner-Ziv video coding:Classifying and reviewing[J].Signal Processing:Image Communication,2015,30(1):1-36.
[6] Ouaret M,Dufaux F,Ebrahimi T.Multiview Distributed Video Coding with Encoder Driven Fusion[C]//European Conference on Signal Processing,Poznan,Poland September 3-7,Poznan:Eusipco Proceedings,2007:2100-2104.
[7] Maugey T,Miled W,Pesquet-Popescu B.Dense disparity estimation in a multi-view distributed video coding system[C]//IEEE International Conference on Acoustics,Speech and Signal Processing,Taipei,Taiwan,April 19-24,New York:IEEE,2009:2001-2004.
[8] Zhang Q,Liu Q,Li H.Distributed residual coding for multi-view video with joint motion vector projection and 3-D warping[C]//IEEE International Symposium on Circuits and Systems,Rio de Janeiro,May 15-18,New York:IEEE,2011:2905-2908.
[9] Brites C,Pereira F.Epipolar Geometry-based Side Information Creation for Multiview Wyner-Ziv Video Coding[J].IEEE Transactions on Circuits & Systems for Video Technology,2014,24(10):1771-1786.
[10] Abou-Elailah A,Dufaux F,Farah J,et al.Fusion of global and local motion estimation for distributed video coding[J].IEEE Transactions on Circuits and Systems for Video Technology,2013,23(1):158-172.
[11] Lee C,Lee C,Lee Y Y,et al.Power-constrained contrast enhancement for emissive displays based on histogram equalization[J].IEEE Transactions on Image Processing,2012,21(1):80-93.
[12] Ascenso J,Brites C,Pereira F.Content adaptive Wyner-Ziv video coding driven by motion activity[C]//IEEE International Conference on Image Processing,Atlanta,New York:IEEE,2006:605-608.
[13] Dufaux F.Support vector machine based fusion for multi-view distributed video coding[C]//17th International Conference on Digital Signal Processing,Corfu,July 6-8 2011.New York:IEEE,2011:1-7.
[14] Fu X,Liu J,Guo J,et al.Novel Side Information Generation Algorithm of Multiview Distributed Video Coding for Multimedia Sensor Networks[J].International Journal of Distributed Sensor Networks,2012,143(4):869-876.
TEMPORAL AND SPATIAL SIDE INFORMATION FUSION BASED ON CONFIDENCE LEVEL IN MULTI-VIEW DISTRIBUTED VIDEO CODING
Huang Bibo1Tang Zhenhua1,2,3*Qin Tuanfa1,2,3
1(School of Computer and Electronic Information,Guangxi University,Nanning 530004,Guangxi,China)2(GuangxiKeyLaboratoryofMultimediaCommunicationsandNetworkTechnology(CultivatingBase),GuangxiUniversity,Nanning530004,Guangxi,China)3(GuangxiCollegesandUniversitiesKeyLaboratoryofMultimediaCommunicationsandInformationProcessing,GuangxiUniversity,Nanning530004,Guangxi,China)
In current side information (SI) generation methods for multi-view distributed video coding (MDVC), the fusion of temporal and spatial SI fails to effectively select and extract the reliable parts of two SI. To address this issue, we propose a confidence level-based temporal and spatial SI fusion method. The method utilises the reliability mask of temporal and the spatial SI as well as spatiotemporal confidence mask to obtain the temporal and spatial fusion mask; then it uses fusion mask to select the optimal pixels from temporal and spatial SI for generating final fusion SI. Experimental results show that, under the condition of same bit rate, the peak signal to noise ratio (PSNR) obtained by this fusion method gains the improvement up to 0.79 dB than the temporal-leading fusion method, and the improvement up to 0.58 dB compared with the temporal-spatial compensating fusion mask. In addition, the reconstructed frame obtained can effectively preserve the details of the original image.
Multi-view distributed video codingSide information fusionConfidence level
2015-05-26。国家自然科学基金项目(61461006,6126 1023);广西自然科学基金项目(2013GXNSFBA019271);广西高校科学技术研究项目(YB2014322)。黄碧波,硕士生,主研领域:多视角分布式视频编码。唐振华,副教授。覃团发,教授。
TP919.8
A
10.3969/j.issn.1000-386x.2016.09.032
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小型微型计算机系统(2022年4期)2022-05-09
四川党的建设(2022年8期)2022-04-28
核科学与工程(2021年4期)2022-01-12
小学生学习指导(低年级)(2020年11期)2020-12-14
红领巾·萌芽(2019年8期)2019-08-27
作文大王·低年级(2018年10期)2018-12-06
计算机应用(2018年5期)2018-07-25
中国与非洲(法文版)(2017年10期)2017-11-23
小猕猴智力画刊(2016年5期)2016-05-14
