
基于低分辨率视频图像的手语识别方法
2016-11-09 01:11严焰刘蓉
计算机应用与软件 2016年9期
严 焰 刘 蓉
1(湖北师范学院教育信息与技术学院 湖北 黄石 435002)2(华中师范大学物理科学与技术学院 湖北 武汉 430079)
基于低分辨率视频图像的手语识别方法
严焰1刘蓉2
1(湖北师范学院教育信息与技术学院湖北 黄石 435002)2(华中师范大学物理科学与技术学院湖北 武汉 430079)
实际环境中常遇到大量低分辨率手语视频图像需要识别,但其只含有相对有限的判别信息,识别效率不高,因此提出一种手语识别方法。该方法在采用实时皮肤颜色特征提取目标区域的基础上,计算目标区域形心、边界链码两种识别特征值,利用动态时间规整算法依次识别手势起始帧与结束帧,结合识别结果还原手语单词。在南佛罗里达大学公共手语数据集进行实验,采用该方法与现有方法比较,识别出正确手语单词增加21个,错误手语单词减少1个,消除了手语单词残缺干扰,证明该方法的有效性。
手语识别动态时间规整算法数字图像处理
0 引 言
低分辨率图像识别是在分辨率低于320×240图像数据中进行自动目标内容识别的过程。该类图像中目标内容尺寸占整个图像像素10%以下,并伴有一定噪声和运动模糊[1]。
与高分辨率图像识别系统相比,低分辨率图像识别系统需要克服图像信息量小、噪声多、较少的可利用方法与工具等特殊难点。传统基于高分辨率图像识别算法直接应用于低分辨率图像中性能大多不理想。目前基于低分辨率图像识别方法有:1) 超分辨率增强。首先对低分辨率图像进行增强得到高分辨率图像,然后利用传统的高分辨率识别方法进行识别[2,3]。该种方法需要冗长的图像重建时间,并且所应用的算法并非针对低分辨率图像识别设计。2)分辨率稳健特征表达。直接从低分辨率图像上提取识别特征信息,根据识别对象本身特点设计识别器[4,5]。
基于低分辨率视频图像手势识别是手势识别中一个研究热点。虽然科学工作者在低分辨率手势识别系统设计方面做了大量工作,但在实际应用中,尤其在手语视频中仍然存在一些挑战性难题。本文针对以下两个难题进行研究:1) 分辨率稳健特征提取。广泛应用高分辨率手势识别系统中的有效特征如颜色、纹理特征[6,7],对光照变化比较敏感,手部与人脸、背景区分度不高,将其直接应用于低分辨率条件下性能有待提高。2) 基于多帧图像的手语自动识别。已有算法大部分关注单帧自定义手势指令识别[8,9],而手语作为一种以手势变化为表达形式,具有完整语法规则的日常交流语言[10],其识别技术有待发展。
1 手语图像特征提取
在低分辨率图像手势识别过程中,静态全局皮肤颜色特征易受到场景光线变化、手与身体其他部分相互遮挡影响,不能有效提取目标区域。而手语中手势动作既有手部相对于头部的位移信息又有手形变化信息,如何在低分辨率图像中计算合适的识别特征值是一个难题。
1.1目标区域检测
本文采用相邻帧差分法,快速去除背景,检测运动目标,然后在运动目标中提取皮肤颜色特征,从低分辨率图像中提取需要目标区域。由于每一帧提取目标区域所使用的颜色模版都是由该帧与后一帧进行差分运算提取的运动目标颜色特征构建,因此有效地避免了整个视频中不同光照对皮肤颜色特征的影响,并减小如背景、脸部等运动幅度小的区域颜色对颜色模版构建过程的干扰。整个目标区域检测算法流程如图1所示。图2是该目标区域提取方法在低分辨率公共手语数据集进行实验的结果。
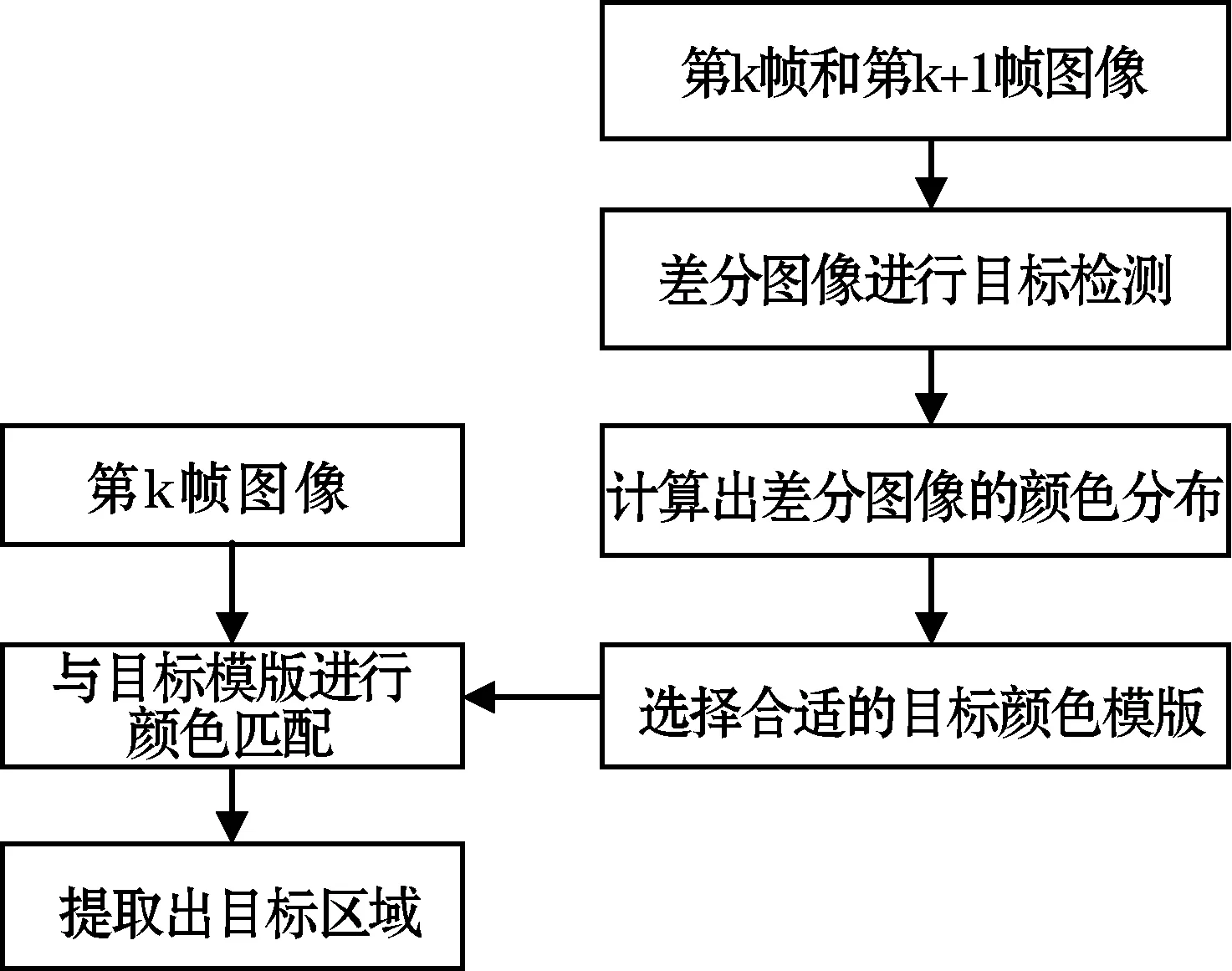
图1 目标区域检测算法流程图

图2 目标区域提取结果
1.2手势特征提取
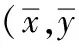
(1)
手形变化主要体现在手部像素边界的改变,而八连通链码与常用四连通链码相比较,更符合局部细节像素分布情况,因此采用八连通链码简化手部边界描述。
2 基于低分辨视频图像的手语识别器设计
2.1手语的运动学特点
手语单词是构建手语这门独立语言的最小、完整、有意义的要素[11],因此识别手语单词是计算机在手语交互应用发展中必须解决的难题。从手势识别角度分析,手语单词是一种变形类手势,具有运动区域多变、运动快慢不同的特点。因此手语识别器设计过程需要充分研究手语自身语言特点。在人机交互应用中,已有的预定义静态手势指令识别器识别自然手语性能不佳。
通过对不同手语视频分析,手语句言简意赅、语素完整,手语单词分布均匀,无“省略”、“倒装”等复杂语法。一个完整手语单词包括手形、位置和运动三个要素。手语单词内部由一系列连续变化的手势动作组成,手语单词之间由明显起始、终止动作区分。
2.2目标手语单词识别
常见手语识别器大多利用全局检索方法在人工构建的手语词典上进行手语识别。例如中科院设计的中国手语识别系统[12],利用HMM算法将数据手套采集信息转换成手语特征数据,然后进行全局检索手语识别。复杂的算法计算和全局检索方式直接应用在数据规模较大的低分辨率手语视频中效果不一定理想。
在实际应用中,手语单词包含丰富运动轨迹、手形变化信息,视频帧数受到摄像机采集速率、用户表达习惯、词语使用场景等因素影响而造成不同。动态时间规整(DTW)算法是一种能够消除不同时空表示模式之间时间差异的简便有效算法。为了快速识别手语,通过识别手语单词的起始帧和终止帧特征信息,减少手语识别过程计算量,并利用起始帧与终止帧之间约束关系缩小检索范围,提高识别效率。
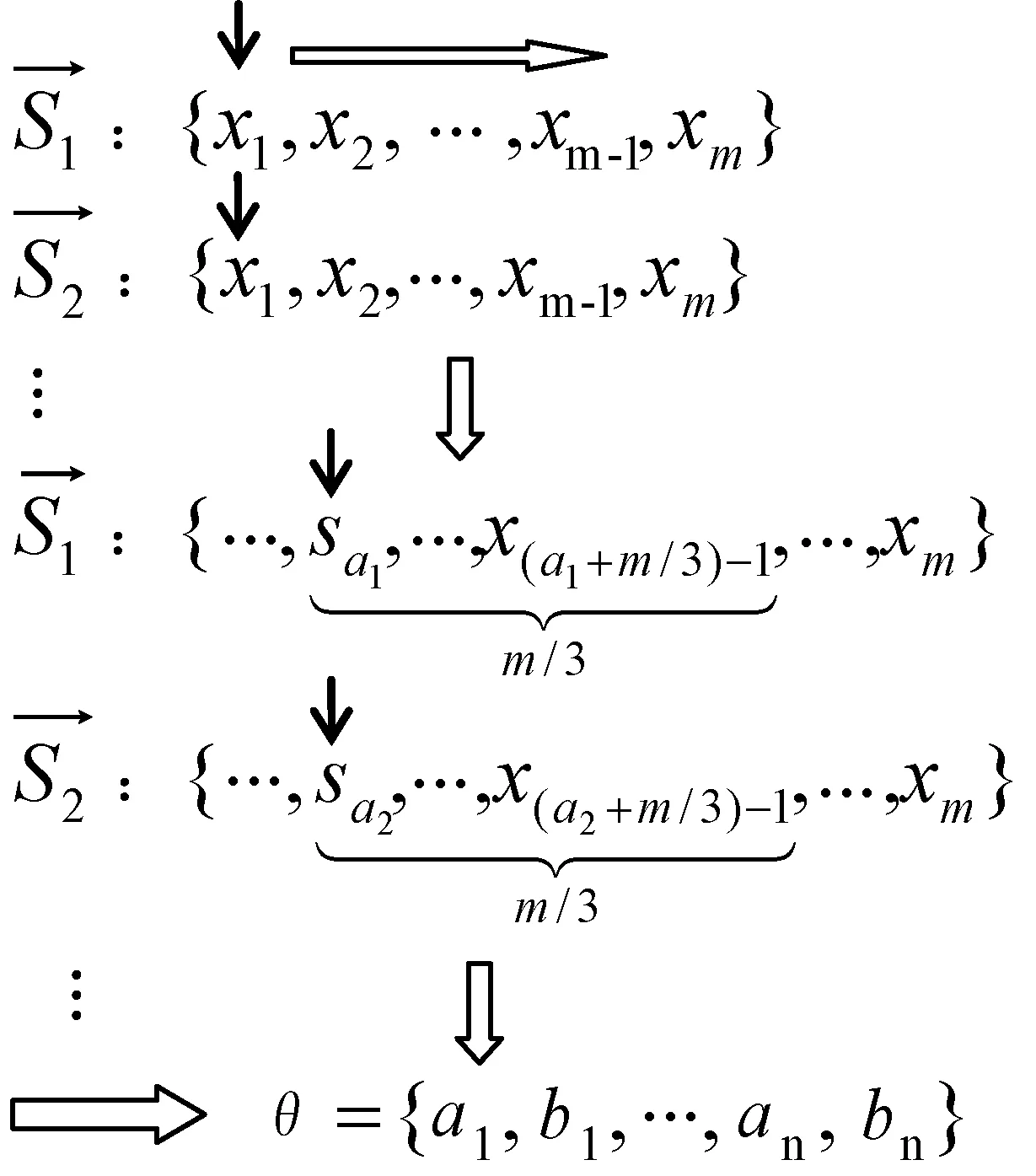
具体步骤如下:
1) 在起始帧识别过程中,利用条件迭代模式,计算一条手语短句每一帧与同组其他手语短句各帧之间BTW距离。将每帧BTW距离与该条手语短句所有帧BTW距离和的比值作为目标手语单词起始帧的后验概率,根据后验概率分布,构建起始帧备选集。
2) 在结束帧识别过程中,由于完整手语短句在语法上包括主语、谓语、宾语,同一人表达语速平稳,因此将起始帧备选集各帧作为步骤2)搜索的起点,沿时间轴向后搜索三分之一总帧长。然后按照步骤1)在搜索范围内构建目标手语结束帧备选集。
3) 因为需要考虑所还原手语单词应符合人们观察认知习惯,所以在步骤1)、步骤2)识别出的起始帧前、结束帧后各取一帧作为过渡帧,与识别结果组合还原完整目标手语单词。
3 手语识别实验与结果分析
本文选择的实验素材(http://marathon.csee.usf.edu/ASL/)满足低分辨率视频识别实验要求。视频分辨率为24位,184×176;视频流帧率为15.00 fps;视频比特率为436 kbps。该手语视频数据集由136条机场出行常用手语短句的视频序列组成,分为动词、名词两大类共10组手语单词。本文实验识别结果如表1所示。

表1 实验仿真结果
在相同手语数据集进行实验,本文提出的方法与文献[13]相比较,识别结果:完整正确手语单词增加21个,错误手语单词减少1个,消除了手语单词残缺干扰。郑韡等[14]利用数据手套采集10种美国单词的动态手势,其平均识别率为87%。本文采用的方法识别效果与之相当,但低分辨率摄像机拍摄与数据手套采集方式比较,在外部设备成本与用户体验方面具有一定的优势。
4 结 语
本文针对手语识别在低分辨率视频条件下遇到的两个难题展开研究,在识别过程中结合手语手势内在特性,提高识别效率。并与国内外的相关成果进行比较,证明本文提出手语识别方法的有效性。在进一步工作中,寻找描述目标区域各部分之间层次关系的有效特征,解决左右手之间位置关系不明显、头部和手部边界重合问题,提高识别效率。
[1] Fookes C, Lin F,Chandran V,et al. Evaluation of image resolution and super-resolution on face recognition performance[J].Journal of Visual Communication and Image Representation,2012,23(1):75-93.
[2] Xiang Ma,Junping Zhang,Chun Qi.Hallucinating face by position-patch[J].Pattern Recognition,2010,43(6):2224-2236.
[3] Yu Hu,KinMan Lam,Guoping Qiu,et al.From local pixel structure to global image super-resolution:A new face hallucination framework[J].IEEE Transactions on,Image Processing,2011,20(2):433-445.
[4] Zhen Lei,Ahonen T,Pietikainen M,et al.Local frequency descriptor for low-resolution face recognition[C]//IEEE International Conference on,Automatic Face & Gesture Recognition and Workshops, 2011:161-166.
[5] Jae Young Choi,Yong Man Ro,Plataniotis K N.Boosting color feature selection for color face recognition[J].IEEE Transactions on,Image Processing,2011,20(5):1425-1434.
[6] 张彤,赵莹雪.基于肤色与边缘检测及排除的手势识别[J].软件导刊,2012,11(7):151-152.
[7] Vasilis Papadourakis,Antonis Argyros.Multiple objects tracking in the presence of long-term occlusions[J].Computer Vision and Image Understanding,2010,114(7):835-846.
[8] 林水强,吴亚东,陈永辉.基于几何特征的手势识别方法[J].计算机工程与设计,2014,35(2):636-640.
[9] 杨波,宋晓娜,冯志全,等.复杂背景下基于空间分布特征的手势识别算法[J].计算机辅助设计与图形学学报,2010,22(10):1841-1848.
[10] 姜华强,潘红.基于关键帧的多级分类手语识别研究[J].计算机应用研究,2010,27(2):491-493.
[11] 肖晓燕.欧美手语语言学研究[J].中国特殊教育,2011(8):41-46.
[12] 张良国,高文,陈熙霖,等.面向中等词汇量的中国手语视觉识别系统[J].计算机研究与发展,2006,43(3):476-482.
[13] Nayak S,Sarkar S,Loeding B.Automated extraction of signs from continuous sign language sentences using Iterated Conditional Modes.[C]//IEEE Conference on,Computer Vision and Pattern Recognition, 2009:2583-2590.
[14] 郑韡,沈旭昆.基于连续数据流的动态手势识别算法[J].北京航空航天大学学报,2012,38(2):273-279.
SIGN LANGUAGE RECOGNITION METHOD BASED ON LOW RESOLUTION VIDEO
Yan Yan1Liu Rong2
1(College of Educational Information and Technology,Hubei Normal University,Huangshi 435002,Hubei,China)2(CollegeofPhysicalScienceandTechnology,CentralChinaNormalUniversity,Wuhan430079,Hubei,China)
In practical environment,there are a lot of recognition requirements in regard to low resolution sign language video,but only relatively limited discrimination information are contained,thus the recognition efficiency is low.In light of this,we proposed a sign language recognition method.Based on the extraction of target area using real-time skin colour feature,the method calculates two recognition feature values of centroid and boundary chain code of target area,uses dynamic time warping algorithm to recognise the starting frame and ending frame of hand gestures in turn,and restores the sign language words in combination with recognition results.In experiment using the public sign language dataset of the University of South Florida,the use of the proposed method has been compared with current method.The correctly recognised sign language words were increased by 21,and the wrong words was decreased by 1.It eliminated the interference of crippled sign language words,and this proved the effectiveness of the method.
Sign language recognitionDynamic time warpingDigital image processing
2015-03-25。国家社会科学基金项目(12BTQ038)。严焰,助教,主研领域:人机交互,图像处理。刘蓉,副教授。
TP3
A
10.3969/j.issn.1000-386x.2016.09.036
猜你喜欢
红外技术(2022年11期)2022-11-25
计算机应用(2020年7期)2020-08-06
红领巾·萌芽(2019年9期)2019-10-09
活力(2019年15期)2019-09-25
小学科学(学生版)(2018年12期)2018-12-19
艺术科技(2018年2期)2018-07-23
小学阅读指南·低年级版(2017年6期)2017-06-12
现代特殊教育(2016年21期)2016-12-14
青少年科技博览(中学版)(2015年8期)2015-10-28
