
基于贝叶斯分类的垃圾短信过滤方法研究*
2016-10-26 05:17陈静怡秦江龙谢仲文
计算机与数字工程 2016年9期
林 英 陈静怡 秦江龙 谢仲文
(云南大学软件学院 昆明 650091)
基于贝叶斯分类的垃圾短信过滤方法研究*
林英陈静怡秦江龙谢仲文
(云南大学软件学院昆明650091)
随着智能手机的普及,短信在给人们生活带来便利的同时,也引发了诸如短信诈骗、短信骚扰、违法信息传播等信息安全问题。由于传统基于朴素贝叶斯分类进行短信过滤的方法在后验概率接近的情况下,分类效果并不理想。论文提出一种多层次的短信过滤方法。该方法首先结合阈值与特征评分的方法,提高垃圾短信分类的准确率;其次,在此方法的基础上,引入增量学习机制,解决由于短信的时新性、复杂性带来的误判。实验结果表明相较于朴素贝叶斯分类及单独改进的方法,多层次过滤的改进方法能有效提高短信分类的正确率。
垃圾短信; 朴素贝叶斯; 文本分类; 特征评分; 阈值; 增量学习
Class NumberTP309.2
1 引言
近年来,短信的安全性成为一个研究的热点。在短信安全中,尤其值得注意的是垃圾短信泛滥成灾的现象。垃圾短信不仅占用了大量的通讯资源,而且给人们的生活带来诸多困扰。例如,骗子利用短信诈骗钱财;商家通过短信发送广告等。在大数据时代,如何有效地阻止垃圾短信的传播已迫在眉睫。
目前来看,垃圾短信的安全监控和拦截是一个较新的课题。迄今为止,并没有形成一套较为有效的方法[1]。一般来说,现有垃圾短信的防范方法主要分为两大类:
一类是基于短信号码的技术,即黑白名单技术。用户手动添加号码到黑白名单列表,实现对短信的过滤。凡是属于黑名单的号码,都判定为垃圾短信;凡是属于白名单的号码,都判定为正常短信。然而,这种方法的缺点很明显,当垃圾短信的发送号码只对一个用户发送一次时,实用性较差。
另一类是基于内容的技术。主要包括:基于关键字过滤、基于规则过滤、基于文本内容过滤等。其中,基于关键字过滤方法通过在系统中设定一些垃圾短信的常见关键词,如:免费、办证、大奖等。这种方法的针对性较强,其效果却依赖关键词的设定。垃圾短信的发送方可以故意绕过这些关键词,来避免被拦截。基于规则过滤方法在IDS中应用较多,虽然它可以过滤掉大多数的垃圾短信,但它是静态的过滤方法,容易被绕过。基于文本内容的垃圾短信过滤,就是采用机器学习方法把短信自动分为正常短信和垃圾短信。常见的方法有贝叶斯分类(Bayesian)[2]、支持向量机(Support Vector Machine,SVM)[3]、K最近邻(KNN)[4]、人工神经网络[5]等。
贝叶斯分类算法是目前所知的文本文档分类算中最为有效的算法之一[6],在某些应用领域内表现出的性能与神经网络和决策树学习器相媲美[7]。贝叶斯方法还具有稳定、简单和处理速度快等特点,易于开发维护,符合手机短信过滤的要求[8],因此本文分类方法主要基于贝叶斯算法展开。
2 相关工作
在国内,使用贝叶斯分类应用在短信分类的研究自从2006年左右就已经开始。虽然贝叶斯分类具有分类正确率高、分类速度快等优点,但朴素贝叶斯仍然存在误判的情况。为了解决这一问题,张琛[9]和李钦[10]等使用阈值进行改进,即当该测试短信属于垃圾短信的后验概率大于等于其属于正常短信的后验概率的λ倍时,判定为垃圾短信;否则,判定为正常短信。
基于特征评分的方法利用了垃圾短信共有的特征,如短信长度较长、包含URL链接等。黄诚[11]和杨凤霞[12]等都利用这些特征对短信进行分类。具体流程为,对于每一条待分类的短信,计算特征加权,再通过公式判断计算出的特征评分和初始设定的初始值的大小关系。小于初始值时,判定为正常短信;大于等于初始值时,判定为垃圾短信。
增量学习技术是一种得到广泛应用的智能化数据挖掘与知识发现技术。一种机器学习方法是否具有良好的增量学习功能己经成为评价其性能优劣的重要标准之一[13]。罗福星提出了设置一个置信度的方法[14]。该方法并不是将所有的待分类文本进行增量学习,而是只对经过置信度严格判断的文本进行增量学习。当使得分类结果小于置信度时,认为是不可靠的分类结果,只可对短信文本分类,但不利用它来修正分类器。对于大于置信度的短信文本,进行增量学习以修正分类器。
单独采用上面三种方法进行垃圾短信分类各有优缺点,其中,阈值的改进方法虽然能降低正常短信的误判率,然而依赖λ的取值;特征评分的改进方法虽然可在一定程度上降低垃圾短信的误判率,但特征项的不断变化会对垃圾短信分类的正确性带来一定影响;增量学习的改进方法较为谨慎,但可以舍弃无用样本而减小训练集。本文在研究上述三种方法的基础之上,通过将三种方法巧妙地结合起来,提出一种多层次的分类方法,通过实验测试,发现多层次的分类方法既可以保持高正确率和低误判率,又可以解决稳定性-可塑性两难问题。
3 研究工作
3.1结合阈值和特征评分的方法研究
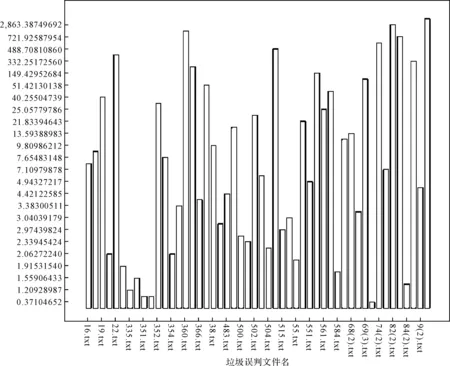
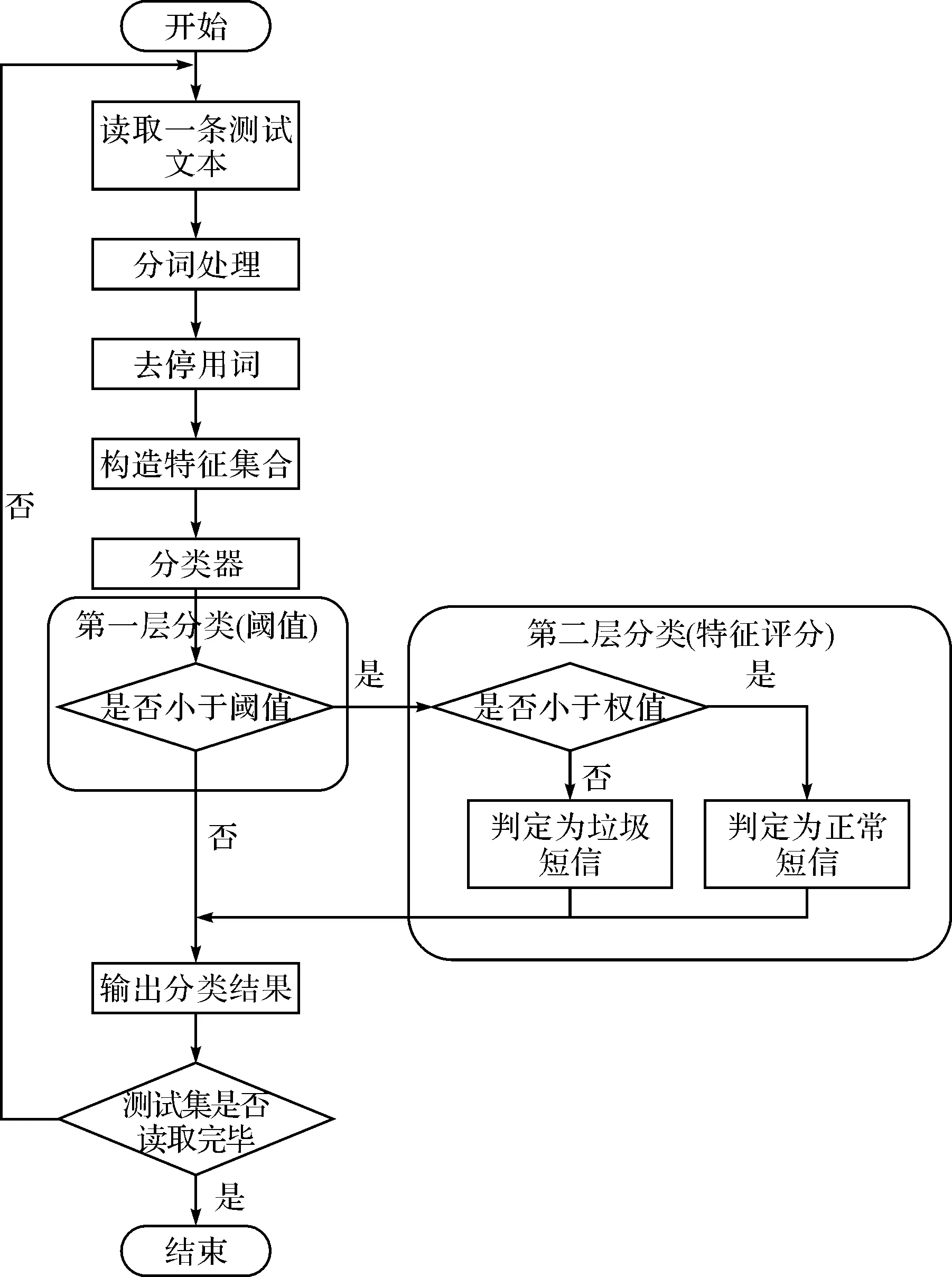
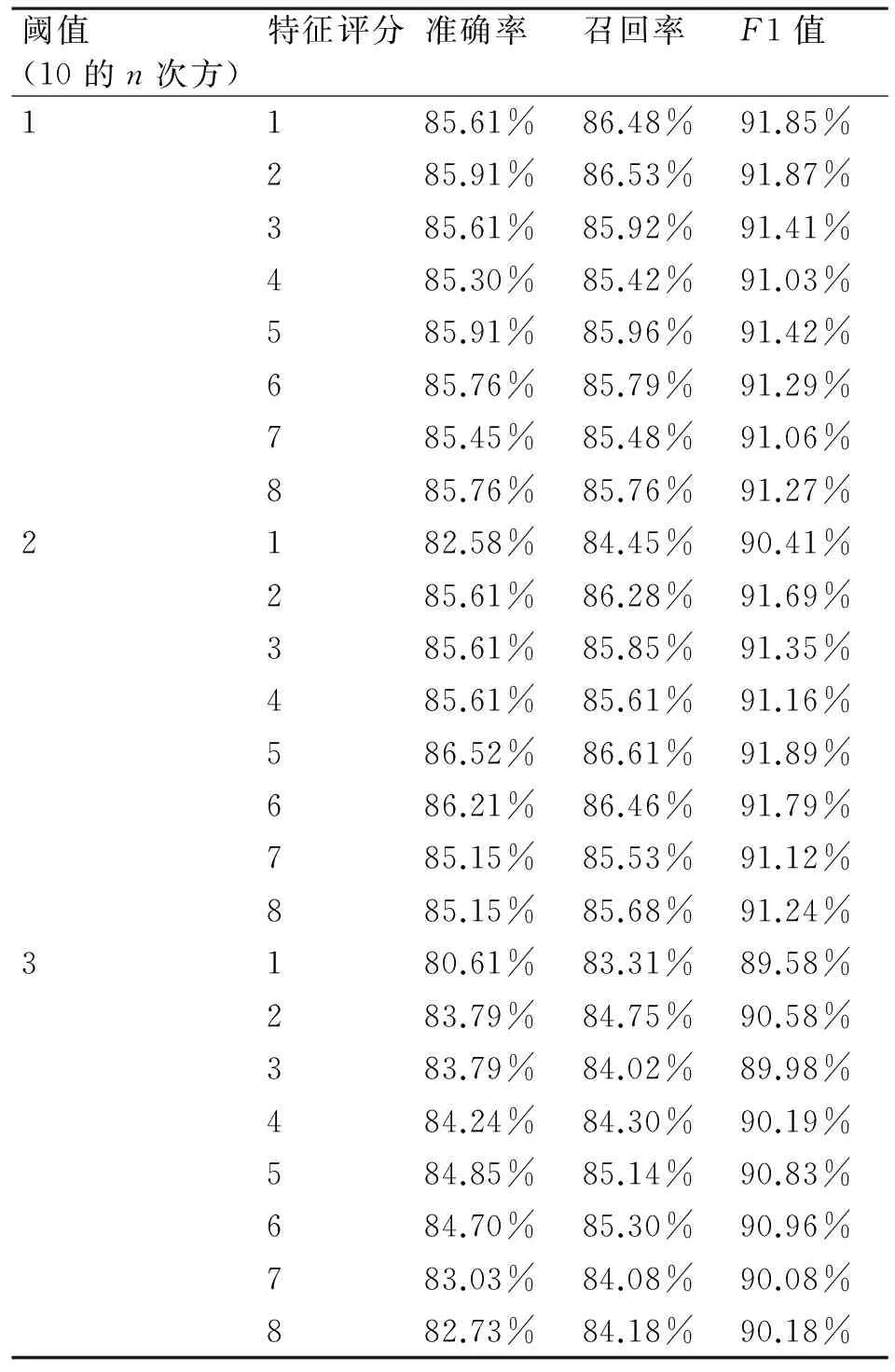
本文初次改进工作主要是采用结合阈值和特征评分的方法来实现的。采用该改进方法的原因是通过分析贝叶斯分类误判时的分类概率,发现当贝叶斯分类器判断一条短信为正常短信的后验概率P(C正常/d)和为垃圾短信的后验概率P(C垃圾/d)比较接近时,贝叶斯分类器判断结果的错误率比较高,造成贝叶斯分类器的分类结果不可信,其中:C正常代表正常短信类,C垃圾代表垃圾短信类,d代表文本。该分析过程如下所示。图1是使用SPSS软件对正常短信测试集进行朴素贝叶斯分类后,对正常短信误判为垃圾短信的一个分析展示。该图的横轴代表测试短信文件名,纵轴表示后验概率的比值,为了表示纵轴,令P1=P(C正常/d),P2=P(C垃圾/d),当P1≥P2时,纵轴表示P1/P2;当P1 因此为了降低误判,本文在贝叶斯分类器得到两类后验概率后,判定这两个概率的比值(以较大的概率比较小的概率)是否小于一个给定的阈值。这是第一层过滤。若小于,则进一步通过特征评分来判断这条短信的类型,这是第二层过滤;否则,信任朴素贝叶斯分类的结果。本文主要采用标点属性、长度属性、关键字属性、要求回复/发送属性和电话号码/网址属性这五个特征,分别表示为v1,v2,…,v5。本条测试文本的特征评分V的计算公式为:V=(v1+v2+v4+b5)/2+V3[15]。 图1 SPSS绘制的正常短信误判图 图2 SPSS绘制的垃圾短信误判图 可以看出,此次改进方法的本质是分层过滤。第一层为朴素贝叶斯分类结合阈值进行分类,第二层为特征评分的方法进行分类,具体流程如图3所示。 3.2结合增量学习的方法研究 虽然贝叶斯分类具有高效、准确率高等特点,然而,一方面,垃圾短信的特征项会不断改变;另一方面,训练集的文本不具备完备性。对于训练集中不存在的特征,贝叶斯分类的效果就受影响,因此,我们在前面改进的基础上,再次引入增量学习方法,以不断适应新的短信特征,从而寻求更优的效果,结合增量学习后的流程图如图4所示。 图3 结合阈值与特征评分的流程图 图4 再次改进贝叶斯的流程图 实现流程为:对于每一条待判定的短信,当该短信的两类后验概率的比值大于阈值时,再判断上述比值与置信度的关系,若大于置信度,将本条短信放入滑动窗口,滑动窗口用于临时保存大于置信度的测试短信;否则,不作处理。滑动窗口在收到一定的数目后会反馈窗口中的文本到相应的训练集。 由于短信具有保密性,且目前没有公开的短信库可供实验使用,而运营商短信服务中心收集的垃圾短信并不对外公开。因此,我们的实验数据主要通过手工收集。根据不同的人有不同的短信书写习惯和省略用语等问题,我们在很多同学、老师、朋友以及网友的帮助下通过筛选,共采集垃圾短信和非垃圾短信1600余条。收集的范围涵盖了:广告短信、欺诈短信、陷阱短信、违法短信陌、生号码短信、骚扰短信、日常生活短信、运营商服务短信、节日祝福短信以及其他个性化短信。 为了使测试结果具有说服性,本文采用K-折交叉验证,对短信文本进行分类测试和评价。选择660条短信文本,其中垃圾短信和正常短信各330条,每类文本又分成三份,一份用于测试,剩余两份用于训练。交叉验证重复3次(此处K=3),再将三次得到的准确率的结果取平均值。本次测试采用基于Lucene实现的开源分词器IK Analyzer,阈值选取,特征评分的值选取1~8。分类结果如表2所示。 4.1结合阈值和特征评分的方法 使用同一组测试数据,测试在不同的阈值和特征评分中的初始值的组合下的正确率、召回率及Fβ值,测试结果如表1所示。Fβ值是使用广泛的文本分类算法性能测试标准。根据MUC系列会议,β取值一般为1,0.5,2。在此处β=1。 通过对阈值和特征评分中的初始值的不同组合进行分析,选取结果最优的阈值、特征评分中初始值的大小。从表中可以看出:特征评分值不变时,随着阈值的增加,准确率、召回率、F1值均表现出先上升后下降的趋势;同样,阈值不变时,随着特征评分值的增加,三项指标也是先上升后下降。当特征评分中初始值太小或太大时,都不能获得较好的分类效果。经多次测试,本次实验将最佳阈值锁定为,最佳特征评分值锁定为5,此时正确率、召回率、Fβ值都是最优水平。在此情况下,与传统朴素贝叶斯相比,阈值与特征值相结合的分类效果在正确率、召回率、Fβ值三个指标上均有提升,如图5所示。 表1 基于阈值和特征评分方法的贝叶斯分类的结果 图5 两种方法的对比 4.2结合增量学习的方法 由于短信文本随着时间的变化,其内容会发生变化。这样,原有的训练集文本就不能代表当前短信文本的普遍特征。为了保证训练集的完备性,引入增量学习的方法,将测试集中特征明显的新文本反馈到训练集中。使用同样的数据进行K-折交叉验证,得到如表5的结果。此时,置信度设为100,窗口大小设为5。为了作对比,此次仍然对阈值为,特征评分1~8的这组数据做测试,得到如表2所示的结果。 表2的实验结果表明:使用增量学习方法再次改进分类器,在准确率、召回率及F1值上均有普遍的提升。图6展示了结合增量学习的方法可以更进一步提升正确率、召回率、Fβ值三个指标。 表2 再次改进的贝叶斯分类的结果 综合来看,朴素贝叶斯的正确率为82.3%,使用阈值和特征评分组合来改进贝叶斯的正确率为86.5%,而使用增量学习来再次改进贝叶斯的正确率为87.0%。可以看出,每一次改进后的模型较之前的都有一定程度的改善,原因在于增量学习提高了训练集的文本的完备性,同时使用置信度保证了稳定性不受影响。 图6 三种方法的对比 本文研究了贝叶斯算法在垃圾短信分类方面的现状,结合三种改进方法实现垃圾短信的多层次的分类。初次改进是先将阈值和特征评分的方法相组合,这种方法相比于单独使用特征评分或单独使用阈值的方法,组合的方式效果更好。在此基础上,引入增量学习的方法再次改进,分类效果较之前的改进有一定程度的提高。在后续的工作中,将考虑结合情感分析实现更智能的垃圾短信分类。 [1] 易阳峰.垃圾短信监控的原理与实现[J].中兴通讯技术,2005,11(6):49-54. YI Yangfeng. Principles and Implementation of Spam Short Message Monitoring[J]. ZTE Communications,2005,11(6):49-54. [2] Lewis D D. Naive (Bayes) at forty: The independence assumption in information retrieval[C]//Machine learning: ECML-98. Springer Berlin Heidelberg,1998:4-15. [3] Joachims T. Text categorization with support vector machines: Learning with many relevant features[M]. Springer: Berlin Heidelberg,1998:137-142. [4] Yang Y. An evaluation of statistical approaches to text categorization[J]. Information Retrieval,1999,1(1-2):69-90. [5] Wiener E, Pedersen J O, Weigend A S. A neural network approach to topic spotting[C]//Proceedings of SDAIR-95, 4th annual symposium on document analysis and information retrieval,1995:317-332 [6] 钟延辉.基于文本挖掘的垃圾短信过滤方法[D].成都:电子科技大学,2009. ZHONG Yanhui. Filtering algorithm of junk SMS based on text mining[D]. Chengdu: University of Electronic Science and Technology of China,2009. [7] 百度百科.贝叶斯分类算法[EB/OL].http://baike.baidu.com/link?url=OqMbCEzqTGzosAUNklIsJ4rie ozWNSqw8i_TZD8alu1JDN7-BDhwSTR4YbCtlH7Ls16 jPjkCZEJVZI_MMQYy8a,2015-6-9. [8] Largeron C, Moulin C, Géry M. Entropy based feature selection for text categorization[C]//Proceedings of the 2011 ACM Symposium on Applied Computing. ACM,2011:924-928. [9] 张琛.基于Android的垃圾短信过滤系统[D].南京:南京邮电大学,2012. ZHANG Chen. Android-based spam messages processing system[D]. Nanjing: Nanjing University of Posts and Telecommunications,2012. [10] 李钦.基于贝叶斯算法的短信过滤系统设计[EB/OL].北京:中国科技论文在线[2007-09-30].http://www.paper.edu.cn/releasepaper/content/200709-658. LI Qin. SMS Filtering System Based on Native Bayes[EB/OL]. Beijing: Sciencepaper Online [2007-09-30]. http://www.paper.edu.cn/releasepaper/content/200709-658. [11] 黄诚.智能手机垃圾短信过滤技术的研究[D].武汉:华中科技大学,2012. HUANG Cheng. Research on SMS Filtering Technology on Intelligent Mobilephone[D]. Wuhan: Huazhong University of Science and Technology,2012. [12] 杨凤霞.基于特征选择的垃圾短信过滤研究[J].沧州师范专科学校学报,2011,27(3):117-119. YANG Fengxia. A Feature-selection-based Study on Junk-SMS-filtering[J]. Journal of Cangzhou Teacher’s College,2011,27(3):117-119. [13] Liao Dongping, Wei Xizhang, Li Xiang, et al. An incremental support vector machine learning algorithm[J]. Journal of National University of Defense Technology,2007,29(3):65-70. [14] 罗福星.增量学习朴素贝叶斯中文分类系统的研究[D].长沙:中南大学,2008. LUO Fuxing. Research on incremental learning naive Bayes classification system[D]. Changsha: Central South University,2008. [15] Sebastiani, Fabrizio. Machine Learning in Automated Text Categorization[J]. ACM Computing Surveys,2002,34(1):1-47. Spam Messages Filtering Methods Based on Bayes Classification LIN YingCHEN JingyiQIN JianglongXIE Zhongwen (School of Software, Yunnan University, Kunming650091) With the popularity of smart phones, text message brings convenient on people’s life, but at the same time it causes many information security problems such as fraud, harassment and illegal information spreading. Considering some traditional filtering methods which based on naive bayes classification are not effective in some circumstances, this paper proposes a multi-level filtering method which combines threshold method, feature score method, and incremental learning mechanism. The experimental results show that compared with naive bayes and single improved method, this multi-level filtering method can effectively improve the accuracy of text classification. spam messages, Naive Bayes, text classification, feature score, threshold, incremental learning 2016年3月8日, 2016年4月24日 云南省软件工程重点实验室开放基金(编号:2010KS01)资助。 林英,女,博士,副教授,研究方向:信息安全、软件工程。陈静怡,女,硕士研究生,研究方向:信息安全。秦江龙,男,博士研究生,讲师,研究方向:软件工程。谢仲文,男,博士,讲师,研究方向:软件工程。 TP309.2DOI:10.3969/j.issn.1672-9722.2016.09.027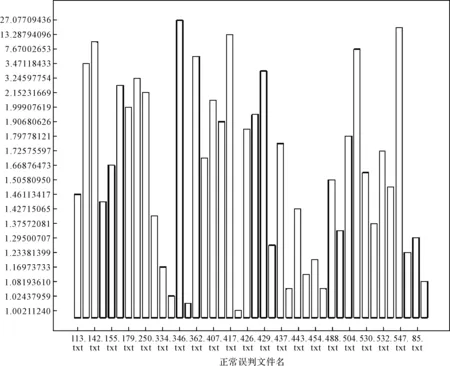

4 实验结果及分析



5 结语
猜你喜欢
当代陕西(2022年6期)2022-04-19
中学生数理化·中考版(2019年9期)2019-11-25
当代工人(2019年4期)2019-04-22
当代工人(2018年21期)2018-03-06
电信科学(2016年9期)2016-06-15
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
电子设计工程(2015年16期)2015-02-27
郑州大学学报(理学版)(2014年2期)2014-03-01
