
基于位置服务上的信息发布/订阅数据建模研究
2016-10-26 00:52张素智徐家兴魏萍萍
现代计算机 2016年23期
张素智,徐家兴,魏萍萍
(郑州轻工业学院计算机与通信工程学院,郑州450002)
基于位置服务上的信息发布/订阅数据建模研究
张素智,徐家兴,魏萍萍
(郑州轻工业学院计算机与通信工程学院,郑州450002)
目前,基于内容、主题在线发布/订阅系统的数据建模和匹配算法缺乏面向LBS的支持,因此提出基于LBS服务的信息发布/订阅数据建模。在该建模中,用户只需要订阅感兴趣的信息,就能够在当前所在位置接收订阅信息,这有效地解决现有的发布/订阅系统中数据匹配的冗余和低精度的问题。通过仿真实验,将数据模型应用于城市信息发布平台系统中。测试结果表明,该模型提高准确度,减少数据冗余,适合大规模发布/订阅应用需求。
查询处理;索引;信息发布;位置定位
0 引言
随着互联网的迅速发展和普及,特别是随着移动计算、网格计算、云计算等新的网络计算模式的兴起,分布式应用系统的范围和规模都发生了很大变化,分布式计算已成为构建大型信息发布系统的主流技术。这就需要一个更加机动的通信和互动机制,以反映系统中动态的和松散耦合等特点,并发布/订阅模型使功能上能够满足上述要求,这种机制受到越来越多科学家的关注。典型的发布/订阅系统的基本模型,如图1所示,其中包括发布、订阅和事件代理。
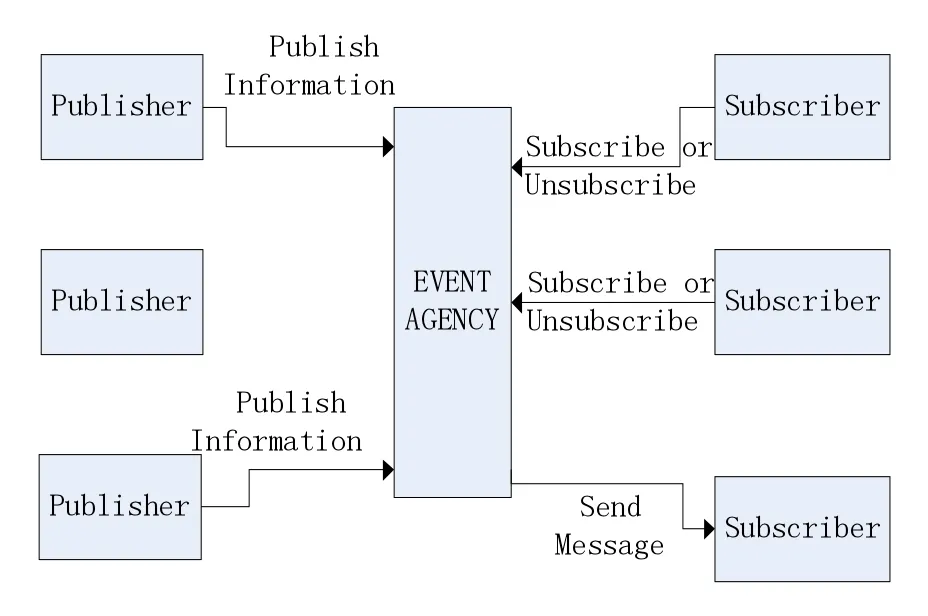
图1 发布/订阅模型
1 数据建模
LBS发布/订阅数据模型包括:概念模型、发布事件模型,和订阅事件[1]模型。
1.1概念模型
在城市信息发布平台中,使用本体建立一个概念模型。本体[2]是一个特定于域的概念,是概念之间的关系和概念定义关系应该遵循的约束条件。概念模型[3]清楚地定义一个字段的约束以及它们之间的应遵循的关系等。发布内容的事件必须满足限制的概念和关系,即内容必须定义在一个概念模型中,必须有存在概念模型中定义的事件;当事件模型接收到一个事件,它必须接触事件内容和概念模型,并进行解决;用户发布订阅必须满足定义和概念模型的约束。因此,概念模型是整个系统的基础,并发挥着重要的作用。
定义1:一个概念模型可以使用six-tuples O=(C、P、CR、PR、X、L):
(1)C表示一组概念类的应用程序域,每个实体属于一个或多个类。例如在基于网络图的信息发布平台中,类层次结构之间的关系如图2所示。
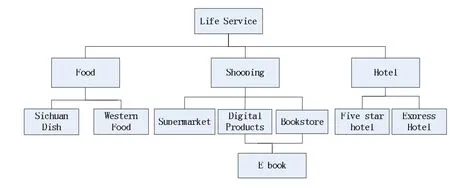
图2 类和信息平台的关系
(2)P表示一组属性。每个类都有一个或多个属性。基于网络图的在城市信息发布平台,例如,一些属性之间的关系如图3所示。
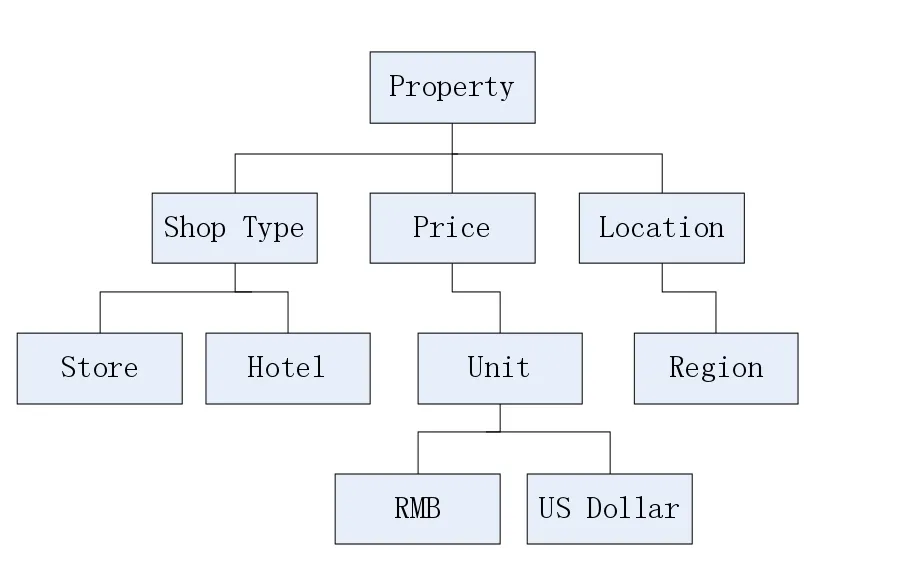
图3 属性和关系的信息平台
(3)CR是一组概念之间的关系,RP是一组相关的更多属性。概念及其属性关系主要是继承、相交、平行等。
(4)X代表一组约束之间的概念和属性,描述为每个类允许哪些属性存在,属性的属性值为空,是什么类型的信息等。
(5)L表示一组区域信息,包括一些地理区域,它的大小并不是固定的,但是根据相关性划分。每个消息都有相应的位置信息。
这是一个订阅条件,和一个实体类B,A到B的子类或间接父类,那么这两个可以匹配。同样,如果P1属性订阅和事件数据的属性P2和P1,P2的子类或间接父类,这两个也可以匹配。例如,某人的订阅条件shopType=“餐馆、茶馆”,在一个事件数据shopType=“餐馆、茶馆”,那么事件和订阅条件相匹配。
1.2事件模型
城市信息发布平台使用RDF语言[4]来描述事件模型,与triple-tulles(主题、属性、对象)的形式表达每个triple-tulle称为语句的事实。其中,主题是说对资源URI引用,属性代表属性URI引用,对象代表价值或URI引用,或者文字值。商家发布信息,并将改变概念模型到事件模型,最后统一到RDF格式。最后,事件服务代理将发送一个RDF-formatted事件到所有相匹配的用户,这在一定程度上,解决异构结构的问题。
定义2:使用RDF eight-tuples事件模型:
(1)V代表一个组中的所有节点的事件模型图。节点包括URI引用节点,文本节点,或者一个空白的节点。
(2)A代表一个弧的所有事件模型图,和弧是URI引用。
(3)LV表示一组标签中的所有节点事件模型。
(4)LA表示一组标签所有弧事件模型。
(5)θ表示一组映射函数从节点到节点的标签,即vθ-LV。
(6) 表示一组电弧弧标签的所有映射函数,即v -LV。
(7)X表示一组约束事件模型。
(8)L表示一组区域信息的概念。
图4显示了我们,在城市的信息发布平台,李宁专卖店,东风5号公路附近卖篮球鞋,他们的价格是1000至2000元人民币。商家发布的信息,事件模型统一格式的事件模型。
1.3订阅模式
用户的订阅[5]是由几个”和“操作的“报表模式”。模式每个语句描述的事件发表声明,并且每个订阅可以表示为一系列的5个元素。
定义3:订阅声明为5个元素(主体、客体、价值、过滤器(主题)、过滤器(对象)),主体和客体提供订阅的主题和对象的语句,它可以表示为一个特定的值,或者也可以使用变量来表示,每个变量”?”作为前缀,如?l,?2,等等。弧连接到主体和客体的属性代表,其中每个属性代表一个类型。
过滤器(主题)和过滤器(对象)代表顶点,绑定可以是空的。在事件图中,每个顶点都有一个特定的值,但是在订阅图中,我们允许的对象和对象都之间是约束和不受约束的变量,它可以在事件中的匹配任何值,约束变量只能匹配约束的值。过滤器可以被表示为一个约束(?x,op,v)?x是一个变量,op是运营商,v代表一个变量值。例如,(?1>100)描述这个变量节点只能有一个匹配的值大于100的节点图。过滤操作符作为一元运算符,即:>、<、=、≥≤,≠,和∈。
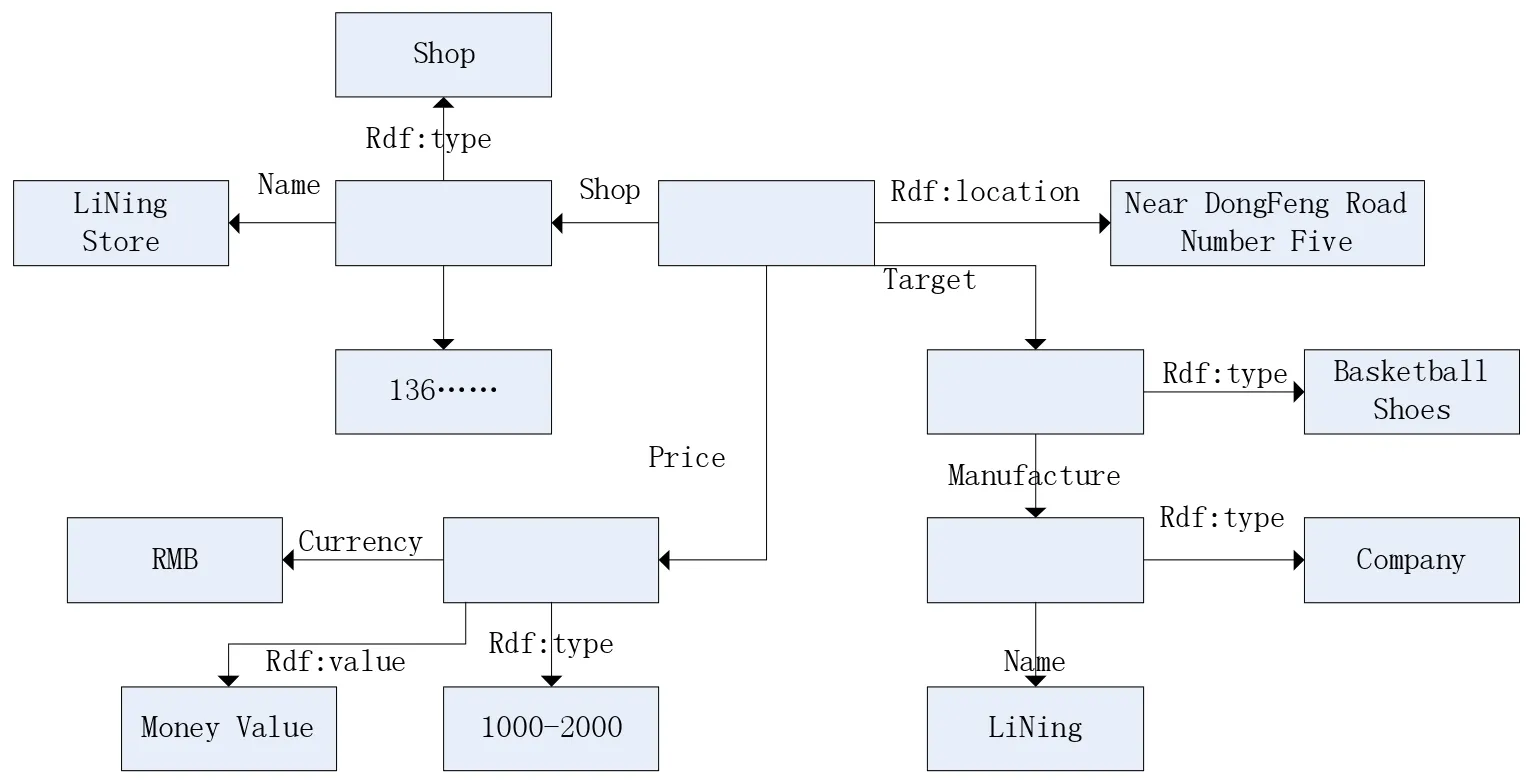
图4 示例事件模型图
如果一个人现在在郑州轻工业大学附近(东风路5号)想买一双李宁的篮球鞋,它的价格在1000~2000元之间,对应的订阅声明可以被描述为:
(_R,rdf:位置?1、null(?1、∈的东风5号路附近)
(_R目标?2、null(?2='篮球鞋'))
(_R、名称?3、null(?3=“LiNing”))
(_R、价格?4、null(?4><1000~2000))
每个订阅事件可以表示为一个订阅图,如图5所示:
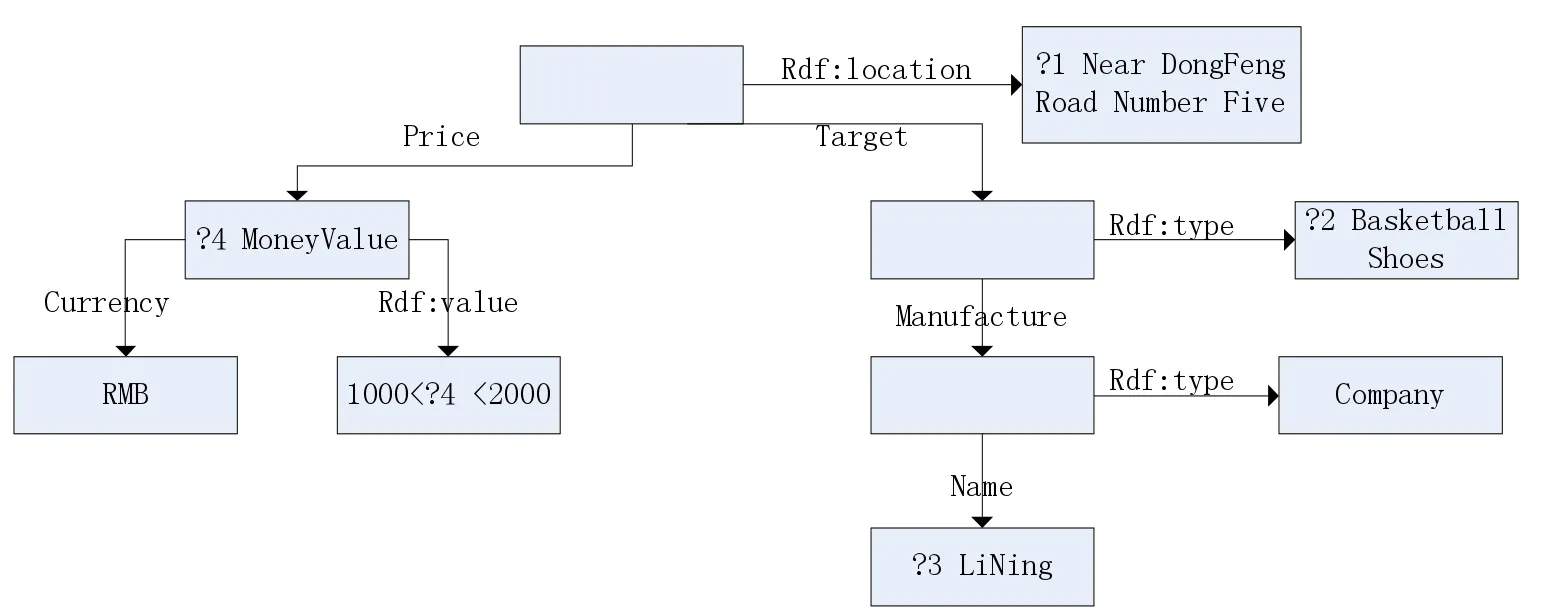
图5 订阅模型图的例子
2 模型应用
2.1匹配算法
匹配算法的实质是给定一个订阅集S和发布事件P,找到满足订阅集S的所有发布事件集合的过程,暴力匹配方法匹配[6]算法是最典型的方法,它会将所有的发布事件的元素P组与订阅信息匹配,匹配算法需要每个属性来比较,这样用户等待时间太长,并且会产生大量的重复匹配,大大减少匹配的效率。为了解决匹配效率低下等问题,结合基于LBS的信息数据模型[7],设计多个属性索引的快速匹配算法。算法描述如下:
(1)建立一个索引表的订阅集,过滤器的过滤条件下(主题)和过滤器(对象)在相应的分类和排序,即每个订阅报表需要分类和排序操作。如果运算符“>”和“>=”,按照升序排序;如果它是“<”和“<=”,在降序排列。当一个序列中的值满足要求,之后的一切属性的值对应值来满足需求,价值不符合上述标准将不再找到匹配,这可以极大地减少匹配。
步骤2:根据操作符的类型,事件模型属性设置匹配约束,发现和绑定在一个位置,其属性权重增加,附近的位置信息,找到匹配的位置。使用Haversin算法:
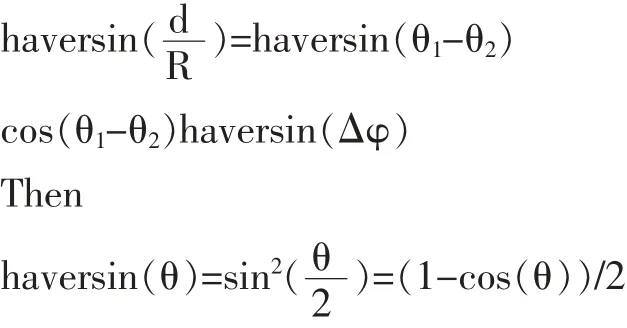
地球的半径R,理想的平均6371公里;代表两个纬度,θ1θ2代表两个经度不同;Δφ代表经度差异,让θ1= θ2then Δφ=rcsin(sin(d/2R))/cosθ弧度转换:dlng= Δφ*180/π,让Δφ=0,Δθ=d/R弧度转换得:dlat= Δθ*180/π。最后,我们可以得到4点:左上角:(lat+dlat,lng-dlng),右上角:(lat+dlat,lng+dlng),左下角:(latdlat,lng-dlng),右下角:(lat dlat,lng+dlng)。
(3)根据操作符寻找匹配,如果“=”操作符,则直接匹配模型的产权约束,否则覆盖的集合中的原有操作符,包括匹配的属性,将满足需求订阅信息收集到临时TempList集合,然后在临时集合templist中的第二属性作为第一属性匹配方法匹配,重复第三步依次类推,直到这一事件模型的所有属性完全匹配。
(4)临时返回结果集TempList,其中结果之一是匹配成功的订阅消息。
2.2实验结果
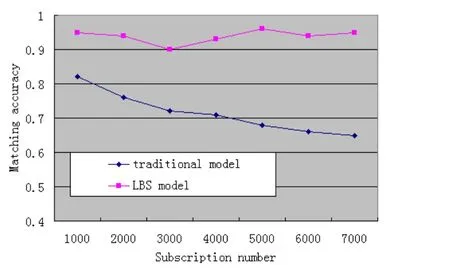
图6 不同的数据模型来匹配精度的影响
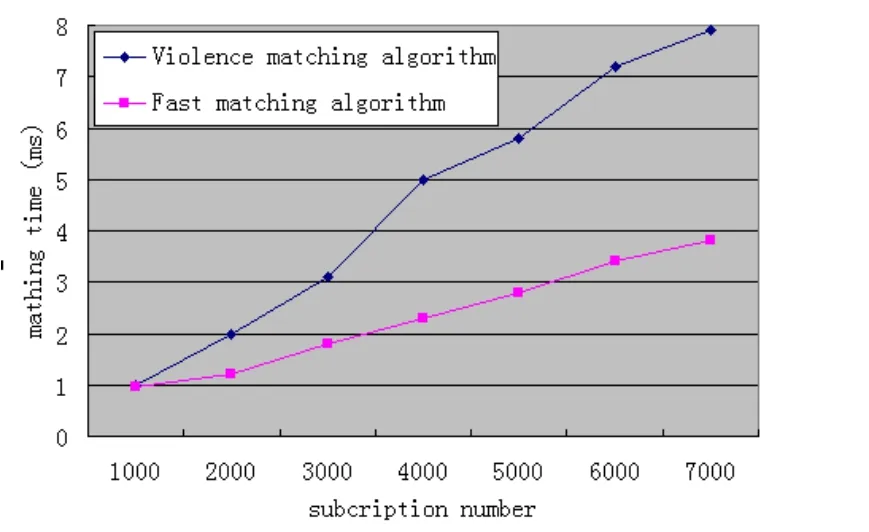
图7 订阅数量匹配速度的影响
实验I:测试不同的数据模型来匹配精度的影响,如图6。
结果表明,传统在订阅模式匹配的准确性随着订阅数量增多不断减少,并且在相同订阅数量的情况下,基于LBS的订阅系统在准确度上一直占有优势,该图表明,满足用户需求的结果所占的比例越来越少;基于LBS的准确发布订阅模型匹配的变化不明显,且精度更高,更接近用户需求。随着需求的不断增长,新的订阅模型更利于满足用户的订购。
实验II:测试的影响订阅的数量匹配速度,如图7。
结果表明,传统的算法随着订阅数量的增多,消耗时间越来越长,与多属性索引匹配算法相比较,在最初订阅数量少时,还拥有较好的匹配效率,当订阅数量过多时,新算法明显优于传统的算法。由于提出的算法支持排序、适应多属性索引、选择连续、减少比较次数,从而减少了匹配时间,提高了匹配效率,因此多属性索引匹配算法更适合于大量的订阅过程。
3 结语
近年来,随着计算机网络技术的迅速发展,特别是移动网络,发布/订阅模型[8]逐渐增多并得到广泛应用。模型的关键是如何实现信息和订阅之间的匹配效率。相对于基于主题/内容的发布/订阅系统模型,我们提出一个新的基于LBS发布/订阅模型数据模型。它使用逻辑算子的特点来实现精确、快速和高效的匹配,因此基于LBS的定位系统更适用于大规模分布式发布-订阅系统。总之,实验表明数据模型匹配的准确性比其他方法有更大的进步。
[1]Jiangang Ma,Tao Huang.Underlying Techniques for Large-Scale Distributed Computing Oriented Publish/Subscribe System[J].Jiangang Ma.Beijing:Journal of Software,2006:134-147.
[2]Jing An.Design of Information Service System Based on LBS[C].Jing An.Zhejiang:Digital Technology and Application,2014:164.
[3]Xi-wei Feng,Jian-hua Wang,Yao Feng,Pei-guang Lin.Semantic Web-Based Matching Algorithm for Publish/Subscribe System[J]. Xiwei Feng.Beijing:Journal of University of Science and Technology Beijing,2013:544-550.
[4]Xiao Zheng,Jun-zhou Luo,Jiu-xin Cao,Ai-bo Song.A Publish Subscribe Based Information Dissemination Model for QoS of Web Services[J].Xiao Zheng.Beijing:Journal of Computer Research and Development,2010:56-69.
[5]Guo-yan Xu,Zhi-jian Wang,Xiao-fang Li.Research on Publish/Subscribe Model Based on Web Services[J].Guoyan Xu.Nanjing:Microelectronics&Computer,2009:29-60.
[6]Zhi-wen Zou,Qiao Li.Subscription Partition Based Multi Index Parallel Matching Algorithm[J].Zhiwen Zou.Jiangsu:Journal of Huazhong University of Science and Technology(Natural Science Edition),2013(S2).
[7]Yong-feng Li,Hui-lin Wang.Indexing and Filtering Metadata for Content Based Publish/subscribe System[J].Yongfeng Li.Beijing:Computer engineering and design,2013:10-32.
[8]Qiang Zhang,Jian-hua Li.Real-Time Performance Analysis of Information Sharing Based on a Publish/Subscribe Model[J].Qiang Zhang.Beijing:Military Operations Research and Systems Engineering,2013:33-35.
Research on Data Modeling of Information Publish/Subscribe Based on LBS
ZHANG Su-zhi,XU Jia-xing,WEI Ping-ping
(School of Computer and Communication Engineering,Zhengzhou University of Light Industry,Zhengzhou 450002)
At present,the content-based,theme-based publish/subscribe system currently has short of supporting LBS in data modeling and matching algorithm,so proposes a data modeling of information publish/subscribe based on LBS,and applies the traditional pattern of the publish/subscribe to LBS in the information service.In the model,users only need to subscribe your interested information,and then receive subscription information near your current location,and effectively solve the existing publish/subscribe system in the data matching redundancy and low accuracy of the results.Through simulation experiment,the data modeling is applied to the city information publishing platform system.The test results show that the model has a great improvement in the accuracy of matching results and reduces the data redundancy,which is suitable for large scale publish/subscribe application requirements.
Query Processing;Index;Information Release;Position Location
国家自然科学基金青年科学基金项目(No.61201447)
1007-1423(2016)23-0027-05DOI:10.3969/j.issn.1007-1423.2016.23.007
张素智(1965-),男,教授,博士,研究方向为Web数据库、分布式计算和异构系统集成
徐家兴(1990-),男,硕士研究生,研究方向为数据挖掘与集成
魏萍萍(1990-),女,硕士研究生,研究方向为数据挖掘与集成
2016-05-24
2016-08-10
猜你喜欢
纺织科技进展(2021年5期)2021-07-22
现代信息科技(2021年21期)2021-05-07
农机质量与监督(2020年8期)2020-09-29
舰船科学技术(2020年2期)2020-04-17
科技与创新(2019年13期)2019-08-12
汽车文摘(2018年12期)2018-12-05
军事运筹与系统工程(2018年3期)2018-03-26
发明与创新·大科技(2017年5期)2017-05-16
商业经济研究(2016年24期)2017-01-10
电脑知识与技术(2016年24期)2016-11-14
