
基于weighted slope one用户聚类的林产品推荐算法
2016-10-10 03:25王名扬陈广胜
森林工程 2016年5期
郑 丹,王名扬,陈广胜
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)
基于weighted slope one用户聚类的林产品推荐算法
郑丹,王名扬*,陈广胜
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)
随着电商平台用户、林产品数量规模不断扩大,协同过滤推荐时构建的用户-林产品评分矩阵变得高维稀疏,导致推荐算法精度和可扩展度下降。基于此本文提出一种weighted slope one用户聚类推荐算法,将其应用在林业产品个性化推荐服务中。首先,通过weighted slope one算法的思想填充高维稀疏的用户-林产品评分矩阵;其次,使用K-means聚类算法对用户进行聚类,产生相似用户集合,缩小推荐过程中邻居用户的搜索范围;最后,在大数据Mahout平台进行实际推荐,为林产品贸易平台个性化推荐服务的大规模实现奠定基础。经仿真实验表明,文中提出的算法能够全面提升推荐的精度和可扩展性。
林产品推荐;weighted slope one;K-means;协同过滤
0 引 言
近年来,科学技术的发展使林产品不断被精深加工,加之其所具有绿色、环保、天然的优势,林产品不断成为健康产品的主流选择。电子商务平台的不断发展带动了林产品的推广和销售,但用户和林产品的不断增多出现了严重的信息负载,个性化推荐服务应运而生。通过个性化推荐服务省去了用户搜索、筛选林产品的时间成本,直接为用户推荐其可能感兴趣的林产品,不但能提升用户在电商平台的购物体验,同时还能够为商家带来销售收入。
国家林业局于2011年提出《林业发展“十二五”规划》中指出,要加快推进林业产品信息化,实现林业产品贸易化发展[1]。因此实现林产品智能推荐是推进我国林业信息化、实现《林业发展“十二五”规划》的重要环节。完善林业产品平台的产品推荐个性化服务技术是建设人性化、智能化林产品商务网站的关键技术与必然趋势[2]。
协同过滤算法是目前应用最为广泛的推荐算法,最早是由GlodBreg等人在90年代开发推荐系统Tapestry时提出来的,并在后来被广泛的研究和应用[3]。随着电商平台上用户、林产品规模的不断扩大,构建出的用户-林产品评分矩阵将具有高维稀疏性,其中大部分元素都是0元素,这对于计算用户、产品之间相似性生成最近邻居,提升算法推荐精度、可扩展性都是非常紧迫的挑战。
为解决这一困境,近年来学者们提出了很多组合算法来提升推荐算法的推荐效果。通过降低用户-产品评分矩阵的规模来实现提升推荐精度与可扩展性。Zhan Li等提出了通过取用户的hyper-plane相似性和传统的余弦相似性的折衷来解决数据的稀疏性问题,仿真实验表明,该方法确实可以在一定程度上缓解数据的稀疏性问题[4]。Pirasteh P等人认为即使是相似性相同的两个人也不应该推荐给他们完全相同的一个产品,他们将加权策略考虑进了相似性的度量中,实验表明,的确能提升推荐算法的推荐精度,但是对于可扩展性的提升并不大[5]。陈洪涛等提出了一种新的基于社交关系的相似度传播式协同过滤推荐算法,通过量化用户社交关系计算用户之间的相似性,然后基于社交网络的相似度传播模型来给出推荐列表[6]。王茜等通过引入社交网络中的信任机制,从个体的社交圈中的主观信任和全局声誉角度出发建模,将直接、间接信任度聚合在一起构成用户信任关系,解决冷启动问题和用户-评分矩阵稀疏性问题[7]。
在对学者们的研究现状进行了充分调研的前提下,文中提出一种基于weighted slope one的用户聚类推荐算法,以有效应对用户-产品评分矩阵的高维稀疏性带来的推荐效率低的问题,并将其应用在电子商务平台上的林产品个性化推荐服务上。
1 数据源
以京东商城的产品分类中的食品、酒类、生鲜、特产为一级目录,以地方特产、茗茶、生鲜食品作为二级目录,收集二级目录下的坚干果、可食用菌类、茗茶等类目林产品为代表作为本文的林产品数据集,通过八爪鱼采集器收集产品的评论页面中的评价详情、评价时间、评价星级、林产品名称、用户名称、用户等级,用户所在地点,采集的部分数据情况如图1所示,共采集到72358条用户-林产品评价信息。

图1 爬取的林产品数据信息Fig.1 Forestry products data information
将重复的林产品进行合并,并且认为同一用户对同一种商品的评价中时间最早的评价星级为有效评论。对数据经过清洗后共有2555条有效评论,在这些评论中包含了1899个用户和60种林产品。在此基础上,构建用户-林产品评分矩阵,矩阵大小为1899×60,其中每列表示一种林产品,每行代表一个用户,每个元素代表用户对于林产品的评分情况。由于每个用户能够评论的林产品是有限的,所以呈现出的用户-林产品评分矩阵具有高维稀疏性,直接在此矩阵上无论是进行用户聚类推荐还是协同过滤推荐都存在用户之间关联性太低的问题,因此不易寻找最近邻居给出推荐结果[8-9]。
2 基于weighted slope one用户聚类协同过滤推荐算法
传统的协同过滤推荐算法遇到了性能的瓶颈,算法的推荐精度和可扩展性都在下降。在对学者们提出的算法进行了深入的分析研究之后,提出了一种基于weighted slope one用户聚类推荐算法,该算法首先构建用户-产品的评分矩阵,将weighted slope one方法实现产品推荐思想的应用于稀疏矩阵的0元素填充,然后使用K-means算法实现相似用户聚集,产生推荐列表,如图2所示。

图2 基于 weighted slope one算法填充后的用户-林产品评分矩阵(部分)Fig.2 User-forestry products matrix based on weighted slope one(part)
2.1weighted slope one算法
slope one算法是Daniel Lemire教授于2005年提出的一个基于用户打分的推荐算法,该算法通过以f(x)=x+b作为预测器,通过线性回归来预测目标用户对于未评分项目的打分情况,其中b是用户对两个项目的评分的平均偏差[10-11]。weighted slope one是slope one算法的一个递进形式,它将用户共同评分的差异度以及不同项目被用户同时评论的次数也考虑进了打分预测中。因此weighted slope one算法所预测的评分更接近于真实的用户评分。但是,文献[12]研究表明slope one在用户-项目评分矩阵比较稀疏时,其推荐的效果并不好。因此,文中并不直接利用weighted slope one算法进行目标用户对项目的打分预测,而是通过使用该算法的思想将其应用于初始的用户-林产品稀疏矩阵填充上。先降低初始用户-林产品评分矩阵的稀疏程度,确保后续进行用户聚类以及推荐的结果更优。
将weighted slope one算法应用于初始用户-林产品评分矩阵填充(以目标用户u的0元素填充为例)的具体过程为:首先,寻找目标用户u与用户v评分的林产品交集Iuv=Iu∩Iv,计算目标用户u的未评分项目j对于项目i的偏移量devji,见公式(1)。然后计算目标用户对于项目j的评分值,见公式(2)。这是经典的slope one算法预测目标用户对项目打分的方式。但显然的,用户v与目标用户u之间评分林产品的交集越多说明用户与目标用户更为相似,对其的预测评分的影响也就越深刻。因此,weighted slope one算法修正用户u对项目最终的预测评分,见公式(3)。

(1)
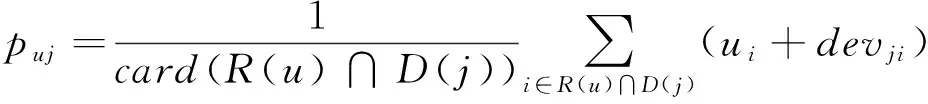
(2)

(3)
式中:uj、ui表示用户u对于项目i、j的评分值;card(i∩j)表示项目i、j同时被评分过的用户数目;R(u)表示目标用户u已经给出评分的项目集合;D(j)表示与目标项目j计算得到的平均偏移量devji的集合。
通过weighted slope one算法对高维稀疏矩阵进行填充后,用户-林产品的评分矩阵如图2所示,显然有效降低了数据的稀疏程度。再通过K-means算法对用户进行聚类,缩小邻居用户的搜索范围,在提升推荐算法可扩展性的同时,为快速给出推荐结果奠定基础。
2.2K-means算法
K-means聚类算法思想简单,又容易实现对数据的大规模聚类,因此是使用的最为广泛的聚类算法之一。 其基本思想为:首先从N个数据对象中随机选择k个对象作为初始聚类中心;对于剩下的其他对象,则根据它们与这些聚类中心的相似度(距离),分别将其分配给与其最相似的聚类;然后再计算每个聚类新的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到准则函数收敛为止[13-14]。K-均值算法采用误差平方和函数作为准则函数,定义为:

(4)
式中:k表示聚类的数目;Cj(j=1,2,…,k)为j个簇;x为簇Cj中任意数据对象;mj为簇Cj中数据对象的均值;E是数据样本与簇中心间距离的平方和,E值越小,聚类结果的质量就越高。因此,该算法设法找到使聚类准则函数E的值达到最小的聚类结果。
文中使用K-means算法对填充过的用户-林产品评分矩阵进行聚类,用户之间距离的度量使用余弦相似性进行度量,见公式(5)。产生相似用户的候选集合,减少后续推荐的相似用户搜索的时间、空间复杂度。

(5)
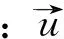
2.3协同过滤推荐
传统的协同过滤算法可以分为基于用户的协同过滤推荐和基于项目的协同过滤推荐,基于用户的协同过滤算法实现推荐时基于如下事实:如果用户对一些项目的评分比较相似就认为他们在其他项目的评分上具有相似关系[15]。算法首先遍历用户集合中的所有用户,计算目标用户与所有用户的相似性,找出前N个最相似的用户作为目标用户的最近邻居,见公式(5);其次,对于目标用户未评分的项目,搜索邻居用户集合对于目标用户未评分项目的评分,并结合其与目标用户的相似度计算目标用户对于未评分项目的预测评分,见公式(6)。最后,针对预测评分的值给出目标用户的推荐列表。
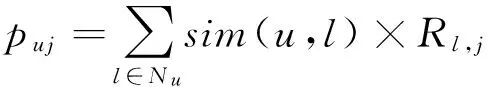
(6)
式中:sim(u,l)表示邻居用户l与目标用户u的相似性,Rl,j表示邻居用户l对项目j的评分,项目j是目标用户的未评分项目。Nu是目标用户的邻居用户集合。
2.4基于weighted slope one用户聚类推荐算法
设U={u1,u2,…,um}为收集的用户集合,U′={C1,C2,…,Ck}表示生成的用户簇类,k表示具体的用户簇类个数,Ck表示第k个簇类,算法的具体描述如下:
输入:用户-评分矩阵D,聚类个数k,最近邻居大小N,推荐列表的个数M。
输出:目标用户的推荐列表以及对应的评分。
step1:根据weighted slope one算法的思想对初始用户-林产品评分矩阵D中的0元素进行填充,生成填充矩阵Dζ。
Step2:利用K-means算法对Dζ进行聚类分析,生成k个聚类输出,各聚类的中心为ci,i=1,2,……,k。
Step3:通过公式(5)计算目标用户与聚类中心ci的相似度,将目标用户分配到距离最小的聚类Ci(i=1,2,……,k)中去。
Step4:在目标用户所属的簇类中,根据公式(5)计算目标用户与其他用户的相似性,搜索出相似性最大的前N个用户作为目标用户的最近邻居集合,记为Nu。
Step5:利用公式(6)计算各个项目的预测评分,列出M个预测评分最大的项目推荐给目标用户。
3 仿真实验与结果分析
以收集到的京东商城的用户、林产品评分数据为实验数据,评分值是按照用户在评价产品时给的评分星级,用户标亮5颗星就认为用户对该林产品的评分为5,未评分的用0来表示,评分越高,说明用户对于该林产品的偏好性越强。
3.1实验环境
文中通过JAVA语言来进行数据的清洗、去重复等工作,从而获取初始的用户、林产品评分信息。构造用户-林产品评分矩阵、基于weighted slope one算法对用户-林产品评分矩阵中的0元素进行填充、实现用户聚类均是以Matlab语言完成,最后在Apache Mahout上构建推荐平台完成推荐过程,为后续的林产品大规模推荐实现奠定基础。
3.2推荐框架(Apache Mahout)
Apache Mahout是Apache Softwear Foundation(ASF)开发的一个基于大数据的开源项目,该项目中开发了很多机器学习的算法的接口,可以供开发人员、学者直接进行调用测试,算法涵盖了聚类、分类、推荐等。
文中的推荐算法均在Apache Mahout上直接实现。在Taste组件中包含了可以进行编程扩展的接口,包括SO算法、基于内容的协同过滤推荐算法、基于项目的协同过滤推荐算法等,同时还提供了扩展接口,工程开发人员可以根据需要实现自己提出的推荐算法。Taste组件的工作原理如图3所示:

图3 Apache Mahout Taste推荐组件执行过程Fig.3 Apache Mahout taste components for execution
底层是数据存储层,用于存储用户的偏好信息,在推荐系统层,用户的偏好信息被建模成Users’ Preferences(接口),一个preference就是一个三元组,其构成为<用户ID,物品ID,评价详情>。推荐引擎将Users’ Preferences提交给Recommender模块,推荐引擎通过DataModel对用户评价信息进行压缩表示,DataModel是用户评价信息的接口,它的具体实现支持从任意类型的数据源抽取用户评价信息,它支持文件读取和数据库的读取。Apache Mahout在进行协同过滤时,首先通过用户的历史行为构建DataModel,在Recommmender模块中根据用户的偏好计算用户之间的相似性,产生最近邻居,然后产生推荐策略给上层的应用层。
3.3评测指标
协同过滤推荐算法最终的目标要给出推荐产品列表以及产品的具体评分,因此涉及到两个指标,即topM个项目的推荐性能以及评分预测的偏差。评分预测的度量多是通过MAE(平均绝对误差)来进行度量,见公式(7),而topM推荐的预测准确率一般通过准确率和召回率来进行度量[16],见公式(8)和公式(9)。

(7)


(8)
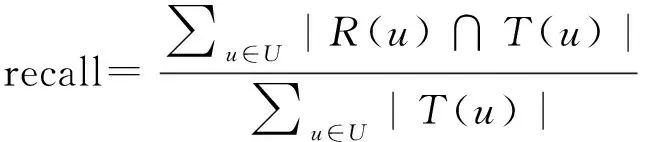
(9)
式中:R(u)是给目标用户的推荐列表;而T(u)则是目标用户实际的行为列表。很明显的,precision表示了推荐的准确性程度,而recall则反映了推荐列表中所推荐的产品被用户响应的程度。从公式(8)和公式(9)来看,准确率和召回率都应该是越高越好。当准确率为NAN说明根据现有的用户数据无法给出推荐产品列表,典型的就是常见的冷启动问题。召回率为NAN说明用户对于推荐的响应列表也为空,可以理解为不活跃用户。
3.4实验结果分析
为了验证改进算法的有效性,使其能够大范围的应用在林业产品贸易平台的使用上,以收集到的数据为测试数据,分别将文中提出的算法与传统的协同过滤算法、基于K-means用户聚类的算法的MAE、precision、recall进行对比,随机地取用户聚类个数为10,选取top 5个林产品作为产品列表推荐给用户。 实验结果见表1。
根据表1可知,利用文中提出的算法对用户-林产品评分矩阵首先进行填充可以有效避免数据稀疏性的问题,在与基于K-means用户聚类推荐算法的比较中可以看到,除去cluster4,cluster6之外,基于K-means用户聚类推荐的算法都出现了NAN的情况,说明文中提出算法的无论是在预测评分还是topM推荐上其整体效果都优于基于K-means用户聚类推荐,可见数据稀疏性对于推荐系统推荐结果的影响。同时,观察到cluster4、cluster9的文中提出的算法所得到的precision、recall相对比较低。通过分析聚类结果发现,首先,cluster4、cluster9簇类内用户数量较少,小用户集合中进行推荐的能力有限;其次,簇类内用户的评分行为较集中,即用户购买评分的项目基本相同。由于用户数量和小差异的集中的购买评分现象,造成了cluster4、cluster9的precision和recall都比较低。去除cluster4、cluster9这两个聚类的precision和recall值发现,文中算法的平均precision、平均recall可以达到84.73%、87.28%。虽然与传统的协同过滤算法相比较在precision上文中的算法还略低一点,但是其在recall、MAE上面的表现却是完全优于传统的协同过滤推荐算法。recall比传统的算法提升了近60%多,MAE下降的幅度也比较大。

表1 各算法的precision、recall、MAE值比较
除此之外,由于文中提出的算法通过K-means聚类算法获取了相似用户的簇类,当需要对某个目标用户进行推荐时,首先判断该目标用户所属的簇类,在目标用户所属的簇类内实现推荐而非以往在所有用户集中实现推荐过程。由于相似用户簇类的用户数量远远小于所有用户集合,因此将目标用户最近邻居的搜索空间将大大降低,从而有效提升了算法的可扩展性。
4 结束语
电子商务的不断发展会带动林产品贸易平台的完善和发展,完善林产品个性化推荐服务是推进我国林业信息化的重要途径。文中以林产品为主题,收集关于用户、林产品、评论等重要信息,通过对数据进行去重、整理生成用户-林产品评分矩阵,引入weighted slope one算法进行推荐的思想,填充稀疏矩阵矩阵进行K-means聚类产生相似用户集合,在低维的相似用户空间中实现林产品的推荐。经仿真实验表明,文中提出的方法能够很好地提升林产品推荐的效率。
[1]国家林业局.《林业发展“十二五”规划》[Z].2011.
[2]王梓.林产品贸易信息用户兴趣模型及个性化搜索[D].北京:北京林业大学,2013.
[3]Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[4]Li Z,Peng J Y,Geng G H,et al.Video recommendation based on multi-modal information and multiple kernel[J].Multimedia Tools & Applications,2015,74(13):4599-4616.
[5]Pirasteh P,Hwang D,Jung J E.Weighted similarity schemes for high scalability in user-based collaborative filtering[J].Mobile Networks & Applications,2015,20(4):1-11.
[6]陈洪涛,肖如良,邓新国.一种新的基于社交关系的相似度传播式推荐算法[J].小型微型计算机系统,2015,36(5):1073-1077.
[7]王茜,王锦华.结合信任机制和用户偏好的协同过滤推荐算法[J].计算机工程与应用,2015,51(10):261-265.
[8]李华,张宇,孙俊华.基于用户模糊聚类的协同过滤推荐研究[J].计算机科学,2012,39(12):83-86.
[9]贺桂和.基于用户偏好挖掘的电子商务协同过滤推荐算法研究[J].情报科学,2013,31(12):38-42.
[10]李朝阳.基于Slope One算法的协作过滤个性化推荐系统设计与实现[D].武汉:华中科技大学,2010.
[11]王毅.基于Hadoop的Slope One及其改进算法实现[D].成都:西南交通大学,2011.
[12]董丽,邢春晓,王克宏.基于不同数据集的协作过滤算法评测[J].清华大学学报:自然科学版,2009,49(4):590-594.
[13]熊忠阳,陈若田,张玉芳.一种有效的K-means聚类中心初始化方法[J].计算机应用研究,2011,28(11):4188-4190.
[14]王千,王成,冯振元,叶金凤.K-means聚类算法研究综述[J].电子设计工程,2012,20(7):21-24.
[15]李涛,王建东,叶飞跃,等.一种基于用户聚类的协同过滤推荐算法[J].系统工程与电子技术,2007(7):1178-1182.
[16]项亮.推荐系统实战[M].北京:人民邮电出版社,2014.
Research on Users’ Clustering of Forest Products RecommendationAlgorithm Based on Weighted Slope One
Zheng Dan,Wang Mingyang*,Chen Guangsheng
(College of Information and Computer Engineering,Northeast Forestry University,Harbin 150040)
With the rapid popularization of the Internet,number of users and products for E-commerce platform is getting huge.Traditional collaborative filtering algorithm encounters data sparseness problem,which cause the accuracy,scalability of recommendation algorithm a sharply drop.In this paper,a users’ clustering recommendation algorithm based on weighted slope one was proposed with aiming at the research of the recommendation for forest products.Firstly,the zero items in user-item matrix items were filled by weighted slope one algorithm.This operation can effectively reduce the data sparseness.Secondly,users could be clustered by K-means algorithm.Finally,the corresponding forestry products were recommended to the target users according to their nearest neighbors which were found by the users’ collaborative filtering recommendation algorithm on Mahout platform.Experiments showed that the improved algorithm can significantly reduce the data sparseness and improve the accuracy and scalability of recommendation.
forest products recommendation;weighted slope one;K-means;collaborative filtering
2016-02-29
中央高校基本科研业务费专项资金项目(2572014DB05);中国博士后科学基金面上基金(2012M520711);国家自然科学基金(No.71473034)
郑丹,硕士研究生。研究方向:数据挖掘。
王名扬,博士,副教授。研究方向:数据挖掘、社交网络挖掘。E-mail:wangmingyang@nefu.edu.cn
郑丹,王名扬,陈广胜.基于weighted slope one用户聚类的林产品推荐算法[J].森林工程,2016,32(5):65-70.
S 759.1
A
1001-005X(2016)05-0065-06
猜你喜欢
科学大众(2020年23期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
汽车观察(2019年2期)2019-03-15
雷达学报(2017年6期)2017-03-26
中国卫生(2016年5期)2016-11-12
中国林业产业(2016年5期)2016-04-03
国际木业(2016年6期)2016-02-28
国际木业(2016年5期)2016-02-28
浙江林业(2015年1期)2015-11-30
电子设计工程(2015年6期)2015-02-27
