
基于区域划分的出租车统一推荐算法
2016-09-29 17:40吕红瑾夏士雄杨旭黄丹
计算机应用 2016年8期
吕红瑾 夏士雄 杨旭 黄丹
摘要:针对在极端天气或交通繁忙时乘客无法快速搭乘出租车到达目的地的问题,提出一种基于区域划分的出租车统一推荐算法,不仅提供普通打车服务,同时提供拼车服务。首先,将区域作为旅程标识,在旅程匹配方面化不可能为可能;其次,在拼车服务中算法将两对路线相近的乘客进行即时匹配,帮乘客拼车共乘;最后,选取绕远时间比例最小的出租车推荐给用户。使用包含14747辆出租车的全球定位系统(GPS)数据对算法进行评估,与CallCab系统相比虽然在减少的总里程数上下降了10%左右,但每次拼车平均只需要多花费6%的时间,且降低的送达乘客总里程数同样达到30%,不仅大幅度减少汽车尾气的排放,同时在用户更加关注的时间消耗方面表现更佳。
关键词:拼车;区域划分;全球定位系统数据;MapReduce;里程数
中图分类号:TP311
文献标志码:A
0引言
在大都市的日常生活中,出租车在所有的交通工具中扮演着一个重要的角色,例如在纽约,有超过100家公司经营着1.3万台出租车以满足每天66万多次出租车搭载请求[1-2]。然而在早晚高峰时间段,大量的乘客依旧无法快速搭乘空闲出租车。在高峰时段,乘客有时需要等待30min以上才可以搭乘空出租车离开[2]。本文提出基于区域划分的出租车统一推荐算法,包括空闲出租车服务和拼车服务,其中拼车服务可以大幅度缓解以上问题,同时降低了车辆的空驶率,司机在同一时间段内可以多载一位付费乘客,多获得一笔车费;另一方面,乘客的出行费用也会相应降低。
虽然拼车服务具有如此多的优点,但几乎所有的出租车推荐系统均集中于空闲出租车的推荐,没有真正在拼车领域进行相关探究[3-7],即使存在对于拼车模式的研究,也无法完全满足大量实时用户的拼车请求[8]。并且与空闲出租车服务不同,提供拼车服务的出租车无法随意地将乘客送往其所要到达的任意目的地。在拼车服务中,乘客需要找到可搭乘的出租车,可搭乘的含义即出租车中已经存在的乘客的目的地与新乘客的目的地方向相似。一个目的地方向为南方的乘客不会认为一辆准备开往北方的出租车是其所愿意搭乘的出租车,因为若乘坐此出租车则意味着要多耗费大量的时间。
本文算法首先将全球定位系统(Global Positioning System, GPS)经纬度点对转化为区域,并通过MapReduce计算模型[9-12]获取以区域标识的旅程信息和特定时刻特定区域的通过时间;然后,以三种不同的标准筛选出相比于其他实时出租车更有可能去往乘客目的地方向的出租车;最后,相比距离,本文算法以乘客更加关注的时间为标准,计算实时出租车的绕远时间比例并推荐绕远时间比例最小的实时出租车给乘客;本文最后对算法进行了相关评测。
1研究背景
1.1设备信息
出租车实时GPS跟踪器会不断地发送GPS数据给后台,每一个GPS数据都由六部分组成,分别表示:车牌号、时间、经度、纬度、状态和速度。
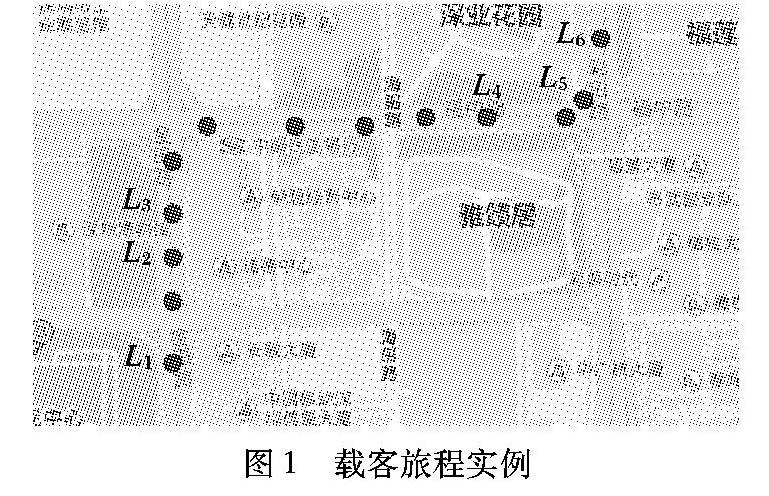
如图1所示:在L1点、L2点状态值为0表示出租车没有搭载乘客;在L3点状态值从0变为1,认为出租车完成了一次搭载乘客动作;在L4点时状态值为1而在L5点时变为0,认为出租车完成一次旅程,乘客下车,出租车继续行驶[13]。
通过持续跟踪一辆出租车的GPS数据,再根据状态值的改变判定旅程的开始与结束,可以获得旅程的起点、终点以及中间地点。根据这种方法,推荐算法可以通过原始GPS数据获取所有旅程信息。
1.2情景演示
对于普通搭载空出租车的服务众所周知,本文就不在此详细介绍,本文重点介绍拼车服务。
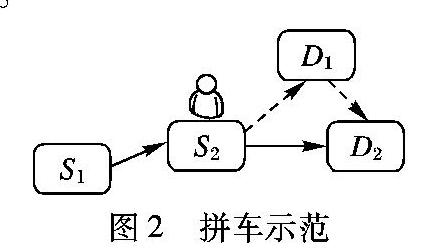
从图2中可知,一名乘客在S2点等待一辆出租车,其目的地是D2,此时乘客以起点S2、目的地D2作为基本信息提出搭乘请求。推荐算法基于实时GPS数据,在其周围无法找到空闲出租车,但是可以找到即将通过S2的已经存在乘客的出租车T,其起点为S1,所以出租车T可以作为潜在的可进行拼车服务的出租车。
乘客在S2点搭乘出租车T,基于先上先服务的原则,出租车T首先应该将已上车的乘客送达目的地D1(D1的位置并不确定,需要通过历史数据获得),之后从D1再开往D2。乘客无论选择普通搭载服务还是拼车服务,都需要等待出租车的到来,当等待时间超过本次旅程的时间,那么乘客会放弃搭车,所以算法将旅程时间作为随机等待时间的上限。
乘客搭载出租车T进行拼车,那么到达目的地的时间为:TD=等待时间+(S2→D1)+(D1→D2);若进行普通搭车请求,到达目的地时间为:TP=等待时间+(S2→D2)。通过绕远时间比例=(TD-TP)/TP来区分不同实时出租车的效用。对于空闲出租车,其D1=D2绕远时间比例为0。
计算中需要的实时已存在乘客出租车T的起点S1和可能目的地D1都无法从现有的设备中获得。但随着GPS数据的积累,推荐算法可以从大量的出租车GPS数据中获得算法所需要的信息,具体过程接下来将进行详细介绍。
2算法流程
2.1算法概述
算法会根据用户特定的起始地、目的地、请求时间与历史GPS数据库信息,实时推荐某辆已有乘客出租车为用户提供“花费较短绕远时间”的拼车服务。
算法主要面临着两个难题:
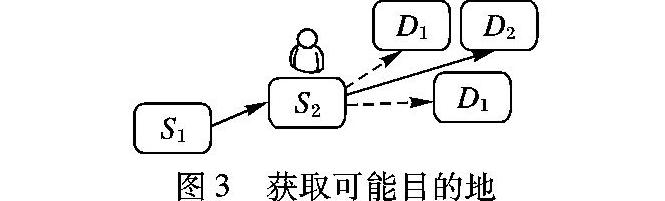
1)根据现有的设备,无法直接获取已有乘客出租车的目的地,如果无法预测已有乘客出租车的目的地,那么拼车服务将无法实现。针对此问题,算法反向跟踪已有人出租车GPS数据,获取其搭载乘客起点,以用户起点作为旅程中间点匹配历史旅程信息,获取相应的可能目的地。
2)用户提出请求时,周围实时一般会存在多辆出租车,如何区分不同出租车的优劣,并对其优劣程度进行量化为用户推荐最优选择是又一个难题。本文算法站在用户的角度,对于时间消耗给予最大限度的关注,采用绕远时间比例对实时出租车进行对比,下文会进行详细叙述。
算法在前期会对历史GPS数据进行处理,获取旅程路线信息和区域时间信息。针对用户的特定请求,算法主要进行了三步处理:获取实时出租车信息;针对各个实时出租车,判定可能目的地,计算出租车对应的绕远时间比例;最后推荐绕远时间比例最小的出租车为用户提供拼车服务。
2.2前期准备
2.2.1旅程信息
推荐算法根据海量的GPS数据,持续跟踪每辆出租车可以得到所有每次旅程的起点、终点以及中间地点。通过这样的方式,推荐算法首先从海量的GPS数据中取得了出租车所有的旅程信息,之后根据已经得知的出租车起点(作为旅程的起点)、用户起点(作为中间经过地点)可以推测出可能的目的地。如图3所示,可能目的地D1有多种可能,使用虚线描述。
因此推荐算法需要先对原始GPS数据集进行处理,获得旅程信息,旅程信息的获得是这整个推荐算法的关键。
2.2.2区域与区域时间
如果采用GPS经纬度点对作为匹配旅程的标志,那么会造成几乎无法匹配到具有相同起点和中间地点的旅程,因为在同一个GPS经纬度点进行搭车的情况几乎没有。
为了将不可能化为可能,本文采用区域划分的方法,将区域作为旅程的标识,即将多个相近GPS经纬度点对转换为同一区域。在持续跟踪同一出租车GPS数据时,同一个区域内会包含此出租车多个GPS记录,最晚时间与最早时间的差可以作为此出租车通过这个区域的时间消耗[14]。
通过区域划分,推荐算法以多个区域编号标记一次搭载旅程,在旅程匹配方面化不可能为可能。划分区域后,整个旅程只在起点和终点区域存在很小的时间误差,更加接近现实情况。
2.3计算绕远时间比例
对于普通拼车服务,绕远时间比例为0。对于拼车服务,当接收到用户的拼车请求之后,推荐算法为了推荐一辆出租车给此特定乘客,会进行以下四步运算:
1)根据用户起点和时间,获取实时已有乘客出租车车牌号,根据时间反跟踪其GPS数据,获取其出发区域。
2)已知出租车起点区域,将新用户起点作为旅程中间区域,与旅程信息相比较,获得可能的出租车目的地。
3)对目的地进行筛选。平均分配每个目的地概率,计算该出租车对应的绕远时间比例。
4)比较所有实时出租车,推荐绕远时间比例最小的一辆出租车给乘客,完成一次请求任务。
对于用户来说,最好的推荐选项即为最有可能去往其目的地方向的出租车。假设对于某特定用户请求而言,可能目的地Db相比可能目的地Da拥有更小的绕远时间比例,此时有实时两辆出租车:出租车T1可能目的地有10个,8个为Da,2个为Db;出租车T2可能目的地也有10个,6个为Da,4个为Db。虽然两辆出租车均更有可能去往Da,但站在用户角度,只关心具有更小绕远时间比例的Db,所以相比T1,算法会推荐T2给乘客。
所以,本文对出租车可能目的地集合进行筛选的三种模式均站在用户角度,只关心相比其他实时出租车,推荐车辆是否具有最小的绕远时间比例,以具有更小的绕远时间比例作为筛选的依据。
图4是整个算法的操作流程;图5则针对“计算绕远时间比例”的三种不同模式,使用示意图展示其不同。下面对这三种模式进行详细的描述:
3数据处理
大数据处理工具有许多,例如Hadoop(主要包括MapReduce和Hadoop分布式文件系统(Hadoop Distributed File System, HDFS))、Spark和Storm。Storm适用于实时计算,而本文算法主要时间消耗为历史GPS数据的批量处理,Hadoop更加适合。Hadoop在外存处理数据,Spark在内存处理数据,Hadoop适合迭代处理,擅长批量处理;相对而言Spark更适合流处理,不擅长迭代处理。Spark处理速度确实比Hadoop快,但是对于服务器的内存有着较大需求,算法为了保证能够实时地推荐出租车给用户提供拼车服务,最终选择Hadoop,这样既可以减少历史GPS数据批量处理的时间消耗,也可以保证充分的内存空间应对实时用户请求的处理。
3.1前期准备
原始数据集合由成千上万条GPS数据集合获得。原始数据不能够直接被推荐算法使用,需要进行处理,以获取旅程信息和区域时间。在进行以下工作时,已经对原始数据进行数据清洗操作,并按照时间增序对数据进行排列,方便接下来的数据处理。
3.1.1旅程信息
从原始GPS数据中获取旅程信息,需要对单个出租车进行持续跟踪,并且需要对其状态进行监测,提取出连续状态值为1(即有乘客)的连续区域集合。
如图6、表1及表2所示,根据原始GPS数据集合,本文算法可获取到以区域标记的旅程信息,使用区域编号代替一个个GPS经纬度点对描述整个旅程,如图6所示,经过区域划分后,一次旅程变为:
通过这种持续跟踪与区域划分的思想,将原始GPS数据集合转化为用区域标记的旅程信息。
3.1.2区域与区域时间
由表3、表4可以看出某辆出租车进入区域Jd52Wd11的时间为0:01:36,驶出区域Jd52Wd11的时间为0:03:39,所以可以得知,这辆出租车经过区域Jd52Wd11所耗费时间为123s,依据同样的方法可以获得各个区域的时间。
需要格外注意的是,求区域时间时,无需考虑出租车状态,因为搭载乘客与否对于通过区域的时间不会产生影响;并且计算区域时间时,同一区域不同时间段的时间消耗是不一样的,所以本文采用时间段、区域两个变量来确定某区域在某个时间段的时间消耗,更加贴近现实情况。
3.2数据处理流程
3.2.1旅程信息
通过Map阶段获得起点区域为某特定区域(出租车起点)的旅程信息,Reduce阶段在Map的基础上获取中间区域包含某特定区域(用户起点)的旅程,并最终输出满足两个条件的旅程终点区域,这个终点区域即为出租车可能的目的地。
3.2.2区域时间
首先通过Map阶段完成对相同车牌号的GPS数据进行分类,并输出。在Reduce阶段,循环遍历特定车牌号所有GPS数据,驶出区域时间减去驶入区域时间,得到此时刻的区域时间。之后对某区域特定时间段的区域时间求平均值,最终获得此区域特定时间段的时间消耗。
3.2.3绕远时间比例计算
当用户以起点区域和目的地区域作为基础信息提出搭乘出租车请求时,推荐算法根据实时数据,找到周围出租车信息和起点区域。并根据出租车起点区域和用户起点区域推算可能的目的地区域集合。之后对于三种不同模式大体步骤相同,如下所述:
1)缩减可能目的地集合:根据不同模式的要求在Map阶段,筛选出满足模式要求的可能目的地,去除不满足的目的地。
2)计算:在Reduce阶段计算所有满足条件目的地的绕远时间比例,平均分配概率,计算该出租车对应的绕远时间比例。
3.2.4在线推荐
计算出多个实时出租车的绕远时间比例后,进行比较,选出绕远时间比例最小的出租车推荐给乘客,完成本次推荐任务。
4算法测试与评估
为了检测算法的性能,本文采用了14727台出租车组成的1.74GB出租车数据进行检测,其中包含了450万条GPS原始数据集合[14]。在使用此GPS数据集合进行测试时,会出现诸如出租车速度不为0但经纬点对无变化等错误情况,这些现象可能由于设备故障、传输失真、人为因素等产生,在对数据处理之前需要对这些不合理现象进行处理,提高实验结果的准确性。
4.1测试综述
算法将原始GPS数据分为五份,其中一份作为实时数据,从中提取出的旅程信息作为用户的请求,例如某次旅程在X0时刻Y0区域开始,在X1时刻Y1区域结束,那么此次旅程可以转化为一次从X0时刻Y0区域到X1时刻Y1区域的用户搭乘请求。根据请求信息,算法首先在实时数据集合中找到周围的实时出租车,根据出租车起点区域和用户的起点区域Y0找到可能的目的地区域集合,之后根据不同模式的要求筛选满足条件的可能目的地,并进行计算推荐操作。
测试时采用两种性能进行评测:一个是绕远时间比例,算法会将绕远时间比例最小的出租车推荐给乘客;第二个是减少的里程数。随着汽车的增多,空气污染越来越严重,与分别送两名乘客到达目的地的总里程数相比,拼车服务送达两名乘客会减少出租车所走的总里程数,减少汽车尾气的排放,对环境保护有极大的推动作用。
4.2具体测评
4.2.1绕远时间比例
本部分对在算法进行测试时,24h不同时段三种不同模式绕远时间比例的变化情况进行说明解释。图7、8中横轴刻度代表某一时间段,如刻度6,表示6:00:00—6:59:59时间段的平均属性。
从图7中可知,在一天24h内,模式1与模式2的绕远时间比例都远远大于模式3,因为相比模式1和模式2,模式3的筛选更加准确所以产生更小的绕远时间消耗。在早高峰时间段(7:00—9:00)由于乘客的需求规律性不高,乘客目的地为分布于整个城市的各个工作地点,所以此时进行拼车具有较大的时间消耗;在晚高峰时间段(18:00—21:00),此时大多数的居民结束一天的工作正是下班高峰期,拼车去往较为集中的居住地与娱乐场所的乘客需求较多,所以此时拼车算法表现最为良好。
4.2.2减少的公里数
本部分主要从减少里程数的角度对三种不同的模式进行测试评估。
从图8中可知:无论是哪种模式都可以较为明显地减少总共的里程数,且基本都达到15%以上,三种模式在减少里程数上具有相同的变化情况。在早高峰与晚高峰时间段,搭乘出租车的旅程较多,所以减少的里程数相比其他时间段更加明显,达到30%以上;在凌晨阶段,由于乘客的目的地随机性较大,所以减少的里程数相比于其他时间段比例较小。
具有相同目的(即减少出租车总里程数)的CallCab系统[15]在减少的总里程数上具有良好的表现,在繁忙时间段(7:00—9:00)甚至达到50%以上。相比CallCab,本文算法将区域时间作为基本点,更关注用户到达目的地的时间消耗,最终目的是为了更快速地将用户送达目的地,尽可能地减少拼车造成的时间消耗,所以相比基于距离的CallCab系统,会产生更少的时间消耗,但相对而言减少的总里程数效果会稍差。
5结语
本文分析、设计并且评估了基于区域划分的出租车推荐算法,针对在极端天气或交通繁忙时乘客无法快速搭乘出租车到达目的地的问题,以降低乘客拼车时间消耗为着重点,为用户推荐时间消耗最小的出租车。经过实验验证,每次拼车平均只需要多花费6%的时间,且降低的送达乘客总里程数达到30%,不仅能大幅度减少汽车尾气的排放,同时在用户更加关注的时间消耗方面的表现也更佳。
本文算法通过挖掘海量历史GPS信息来获取各个区域时间,然后为用户推荐具有较短时间消耗的出租车,但对于GPS数据的挖掘依旧不够充分,这将在以后的工作当中进行深入研究。
参考文献:
[1]Taxi of tomorrow survey [EB/OL]. [2015-11-16]. http://www.nyc.gov/html/tlc/downloads/pdf/tot_survey_results_02_10_11.pdf.
[2]The New York city taxicab fact book [EB/OL]. [2015-11-16]. http://www.schallerconsult.com/taxi/taxifb.pdf.
[3]BALAN R K, NGUYEN K X, JIANG L. Real-time trip information service for a large taxi fleet [C]// MobiSys 11: Proceedings of the 9th International Conference on Mobile Systems. New York: ACM, 2011: 99-112.
[4]WU W, NG W S, KRISHNASWAMY S, et al. To taxi or not to taxi? — enabling personalised and real-time transportation decisions for mobile users [C]// MDM 12: Proceedings of the 2012 IEEE 13th International Conference on Mobile Data Management. Washington, DC: IEEE Computer Society, 2012: 320-323.
[5]GE Y, XIONG H, TUZHILIN A, et al. An energy-efficient mobile recommender system [C]// KDD 10: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2010: 899-908.
[6]LIU W, ZHENG Y, CHAWLA S, et al. Discovering spatiotemporal causal interactions in traffic data streams [C]// KDD 11: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 1010-1018.
[7]HUANG Y, POWELL J W. Detecting regions of disequilibrium in taxi services under uncertainty [C]// SIGSPATIAL 12: Proceedings of the 20th International Conference on Advances in Geographic Information Systems. New York: ACM, 2012:139-148.
[8]肖强,何瑞春,张薇,等.基于模糊聚类和识别的出租车合乘算法研究[J]. 交通运输系统工程与信息,2014,14(5):119-125. (XIAO Q, HE R C, ZHANG W, et al. Algorithm research of taxi carpooling based on fuzzy clustering and fuzzy recognition [J]. Journal of Transportation Systems Engineering and Information Technology, 2014, 14(5): 119-125.)
[9]白竹,金晓红.出租车GPS数据的应用研究[J].黑龙江工程学院学报,2014,28(2):50-54. (BAI Z, JIN X H. Research on the application of taxi GPS data[J]. Journal of Heilongjiang Institute of Technology, 2014, 28(2): 50-54.)
[10]DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [C]// OSDI 04: Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation. Berkeley, CA: USENIX Association, 2004, 6: Article No. 10.
Proceedings of the 6th conference on Symposium on Opearting Systems Design & Implementation, 2014, 51(1): 107-113.)
[11]何贤国,孙国道,高家全,等.出租车GPS大数据的道路行车可视分析[J].计算机辅助设计与图形学学报,2014,26(12):2163-2172. (HE X G,SUN G D,GAO J Q, et al. Visual analytics of road traffic with large scale taxi GPS data[J]. Journal of Computer-Aided Design & Computer Graphics, 2014, 26(12): 2163-2172.)
[12]桂智明,向宇,李玉鉴. 基于出租车轨迹的并行城市热点区域发现[J]. 华中科技大学学报(自然科学版),2012,40(S1):187-190. (GUI Z M, XIANG Y, LI Y J. Parallel discovering of city hot spot based on taxi trajectories [J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2012, 40(S1): 187-190.)
[13]唐炉亮,郑文斌,王志强,等.城市出租车上下客的GPS轨迹时空分布探测方法[J]. 地球信息科学学报,2015,17(10):1179-1186. (TANG L L, ZHENG W B, WANG Z Q, et al. Space time analysis on the pick-up and drop-off of taxi passengers based on GPS big data[J]. Journal of Geo-Information Science, 2015, 17(10): 1179-1186.)
[14]Data description for UrbanCPS [EB/OL]. [2015-11-20]. http://www-users.cs.umn.edu/~tianhe/BIGDATA/.
[15]ZHANG D S, HE T, LIU Y, et al. CallCab: A unified recommendation system for carpooling and regular taxicab services [C]// IEEE Big Data 2013: Proceedings of the 2013 IEEE International Conference on Big Data. Piscataway, NJ: IEEE, 2013: 439-447.
