
基于多类别语义词簇的新闻读者情绪分类
2016-09-29 17:40温雯吴彪蔡瑞初郝志峰王丽娟
计算机应用 2016年8期
关键词:情感分析
温雯 吴彪 蔡瑞初 郝志峰 王丽娟
摘要:分析和研究文本读者情绪有助于发现互联网的负面信息,是舆情监控的重要组成部分。考虑到引起读者不同情绪主要因素在于文本的语义内容,如何抽取文本语义特征因此成为一个重要问题。针对这一问题,提出首先使用word2vec模型对文本进行初始的语义表达;在此基础上结合各个情绪类别分别构建有代表性的语义词簇,进而采用一定准则筛选对类别判断有效的词簇,从而将传统的文本词向量表达改进为语义词簇上的向量表达;最后使用多标签分类方法进行情绪标签的学习和分类。实验结果表明,该方法相对于现有的代表性方法来说能够获得更好的精度和稳定性。
关键词:情感分析;情绪分类;语义词簇;多标签学习;word2vec
中图分类号:TP391
文献标志码:A
0引言
随着Web2.0的到来,在互联网上获得大量新闻语料及读者的评论文本和情绪标签已经成为一件轻而易举的事情。通过对文本情绪的分析,能够让我们更加清楚了解文本给人们日常生活带来的影响,有助于监控和定位特殊情绪的传播[1]。近年来,大量情感文本的出现使得情感分析已经成为了文本挖掘的热点。整体而言,情感分析的研究分为两大类。
一类是文本的直接情感分析,一般定义为文本直接呈现出的情感极性,主要是作者写作时的情感,包括正面和负面的态度,通常采用单标签及极性度量表示,目前的主流方法包括:
1)简单的基于情感词典极性词的研究。例如,Hatzivassiloglou等[2]从大语料库华尔街日报(Wall Street Journal)中发掘出大量的形容词性的评价词语;周咏梅等[3]通过新闻评论语料和基础情感词典获得评论情感词集和种子词,判定评论情感词集的极性并计算其强度,进而构建新闻评论情感词典。2)较为复杂的基于情感句或篇章的研究。例如,Tang等[4-5]通过构建情感词典和情感三元组研究篇章集的情感分析。
另外一类是针对文本所可能引发的读者情绪的研究。情绪分析强调的是个体自身的情绪变化,如喜、怒、哀、乐、悲等,在分析时需要综合考虑多个方面的信息,相对于热门的文本直接情感的研究,读者情绪的研究是一个更加困难的工作,目前仍处于起步的阶段,各种研究技术存在一定的缺陷,主要采用多标签的方式表示读者的情绪,标签之间并不是互斥关系,可以同时存在。例如,2010年,Quan等[6]研究句子层面上的文本情绪分类问题,将句子的情绪分类问题看成是多标签文本分类。首先基于标注文档集抽取每类情绪词集合,利用线性核函数方法计算句子与每类情绪词集合之间的相似度,根据预设定的阈值确定句子的情绪类别。哈工大徐睿峰团队[7-9]认为情绪分析、情绪归因、情绪预测和情绪个性化建模这四个问题之间并不是孤立的,而是相互联系的,因此提出了基于“刺激认知反射输出”机制的文本情绪计算[7-8]以及用隐含狄利克雷分配(Latent Dirichlet Allocation, LDA)模型进行多标签的情绪分析。
通过对读者情绪的研究分析,可以让我们实时监控网上的文本信息,及时发现负面信息,趁早介入,避免负面信息给社会带来大的影响。传统的舆情监控主要采用监控关键词以及热点分析的办法,但是这样的方式有一定的缺陷,因为热点事件表明该事件已经发生,并且对社会造成了一定的影响,采用热点分析的方法会有一定的延时,所需要的代价也更大。相反,采用情绪分析的方法,可以更快地预测文本可能给读者带来的情绪,及早发现并解决问题。此外,情感分析还能够用于信息检索中[10]。
考虑到不同的读者在阅读时由于个人经历以及思维的不同所产生的情绪也不尽相同,甚至同样一篇文章可能给不同的读者带来完全相反的情绪,或者是同一个读者可能同时产生多种情绪,包括人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。显然,仅仅从作者的角度出发采用单标签的方式研究人们阅读文本后产生的情绪,逻辑上是不够严密的。因此,本文主要关注的是读者阅读完新闻以后可能产生的情绪,采用多标签的方式对文本进行情绪的分析及预测。为了更够获得更好的效果,我们需要做的是结合文档的上下文信息以及标签信息,对文档进行特征提取,然后将特征放入到合适的分类器中进行训练预测以及效果的评估。
1相关工作
读者情绪受到两个要素影响:其一是读者阅读的文本自身所包含的内容;其二是读者个体是否易激发某种情绪的特性(简称其为“个体信息”)。由于读者的个体信息不容易被采集和量化,当前面向文本的读者情绪预测通常被建模成一类特殊的文本分类问题,认为分类后的文本所属的情绪类别即为读者可能产生的情绪,从而完成读者的情绪预测问题[11-12]。采用这种方式研究读者的情绪,需要解决两个关键的问题:第一个是如何表达文本可能引起读者某类情绪的属性;第二个是如何设计有效而符合显示的分类器。 首先,构建这种分类器需要可以量化的文本属性,一般采用把文本转换成特征向量。众所周知,文本由词组成,最直接的办法就是采用词来表示文本。如果用传统的稀疏表示法表示词,在解决某些任务时(比如构建语言模型)会造成维数灾难[13]。人们在研究过程中发现使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。文本的情绪其实蕴涵在文字之间,所以一般认为通过找出蕴涵在词中的情感的关系,就能够分析出文本的情感倾向。以往大多数情感分析任务都采用词袋模型,甚至有一种基本的假设,即读者的情绪会与新闻的某个主题相关,相同或者相似的主题事件会引起读者产生相似的情绪,因此也有不少研究采用基于词袋模型改进的主题模型[14]。词袋模型假定对于一个文本,忽略其词序和语法、句法,将其仅仅看作是一个词的集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现。这种假设对自然语言进行了简化,便于模型化,所以也被广泛用在文本分类的一些方法当中。当传统的贝叶斯分类被应用到文本当中时,贝叶斯中的条件独立性假设正是词袋模型的基础。但是,词袋方法没有考虑词与词之间的顺序。随着人们对本文处理技术的深入研究, Blei等[14]在2003年提出了主题模型。LDA基于一个常识性假设:文档集合中的所有文本均共享一定数量的隐含主题。基于该假设,它将整个文档集特征化为隐含主题的集合,而每篇文本被表示为这些隐含主题的特定比例的混合。LDA是三层的贝叶斯概率模型,包含词、主题和文档三层结构,利用统计学的知识,分析文档集内部信息,将集合映射到基于隐含主题的特征空间上,过滤噪声等干扰信息。从文档到词符合Dirichlet分布,主题到词符合多项式分布,它可以用来识别大规模文档集或语料库中潜藏的主题信息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于它采用了词袋的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息,这降低了问题的复杂性。例如,李芳等[15]对名词性短语运用LDA模型挖掘潜在的评价主题也获得了不错的效果。虽然LDA能够考虑潜在语义信息,不单纯从机械的词频统计角度分析文档,但LDA模型只考虑了文本的主题分布,而主题向量的维度有限,仅利用这样的向量来计算文本相似度,必然丢失大量的信息,区分文本的力度是不够的。
目前流行的一种文本情感分析方法是利用word2vec模型获得语料的词向量。word2vec模型是Google在2013年提出的一个深度学习模型[16],它将词表征成实数值向量,采用连续词袋模型(Continuous Bag-Of-Words Model,CBOW)和Skip-Gram(continuous Skip-Gram model)两种模型。在文本聚类的过程中,相似度计算是文本聚类中非常重要的一个步骤,对聚类结果的好坏有着直接的影响,但传统的相似度计算模型仅采取词频统计来表示文本,丢失了文本间大量的语义信息,从而影响了相似度计算的效果。
简单地采用词袋模型的方法则忽略了词与词之间的关系,往往会丢失上下文的信息,导致区分文本的力度不够。而词向量所体现的是语义和语法的信息,word2vec能够结合上下文的信息,训练出词向量,通过把词映射到V维的向量空间,词与词之间的向量操作能够与语义相对应[17]。相当于如果把词当作是特征,那么就是把特征映射到V维的向量空间,通过训练,可以把对文本处理的内容简化为V维的向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。因此,word2vec输出的词向量可以被用来做很多自然语言处理相关的工作。此外,与复杂的深度神经网络相比,word2vec去掉了十分费时的非线性隐层,采用了Negative Sampling和随机梯度下降算法,并且只遍历一遍数据,不需重复迭代,所以十分高效[18]。与此同时,word2vec还有一些比较精细的应用,比如计算词的相似度、词的类比关系以及文章的相似度等。
除此之外,由于文本的情绪分析是一个多标签学习的问题,因此还需要寻找合适的多标签分类方法,将转化文本得到的特征输入到多标签分类器中,最终得到需要的模型。在过去,也有一些采用多标签分类器进行文本处理的工作,例如,2007年,Zhang 等[19]提出基于算法名称中大写且不斜体?k近邻的多标签(MLKNN)学习算法处理文本的标签信息,通过计算k近邻的所属的类别来确定自己所属的类别;2009年,Cheng等[20]利用Logistics回归进行多标签分类学习,Logistics回归通过引入对数,解决了因变量是不连续变量的问题。MLKNN分类器以及Logistics回归分类器对于不同的分类任务都获得了不错的效果。
2模型定义及方法
2.1问题定义
读者在阅读新闻文本之后可能产生多种情绪,包括喜、怒、哀、乐、悲等。在能够采集相关语料及读者情绪标注的情况下,该问题可以转化为以下机器学习模型:
假设给定包N个文档的文档集D={D1,D2,…,DN},其对应的情绪标签集为:Y={y1,y2,…,yN},且yi∈2L,L为对应一篇文档的不同情绪类型(例如“开心”“愤怒”“无聊”等)的数量。情绪分类的学习模型可以定义为:根据已标注的语料文档及其标签,获得多标签分类模型。从机器学习的角度,该问题可以转化为一类典型的分类问题加以解决,其中包含两个关键的步骤:
1)文本特征的抽取,即从文本集中抽取有代表性的特征,其过程可以表示为构建一种特征映射:φ=D→x,为后续情绪分类作准备。
2)分类器的设计,即构建文本特征空间到标签空间的映射: f=x→y。由于同一文本所引发的读者情绪具有多种可能性,这一步所需做的工作就是构建一个合适的多标签分类器(例如采用典型的多标签分类器,或将该问题转化为单标签多类问题进行解决)。
在以往的工作中,对不同的情绪标签,往往采用相同的文本特征,但考虑到文本之所以引发读者的不同情绪,其对应的情绪特征理应是有差异性的。本文主要着眼于这一问题,尝试设计结合类标签的文本特征。具体思路表达如下:
步骤1针对不同的情绪标签,提取有差异化的文本特征,即建立φl:D→xl(l=1,2,…,L);
步骤2在差异化的文本特征基础上,分别构建针对不同标签的分类器fl=xl→yl(l=1,2,…,L)。
为了更好地表达文本中的主要信息,本文主要基于word2vec及语义词簇的思想提取文本特征。
2.2基于多类别语义词簇的情绪分类
2.2.1基于语义词簇的特征提取
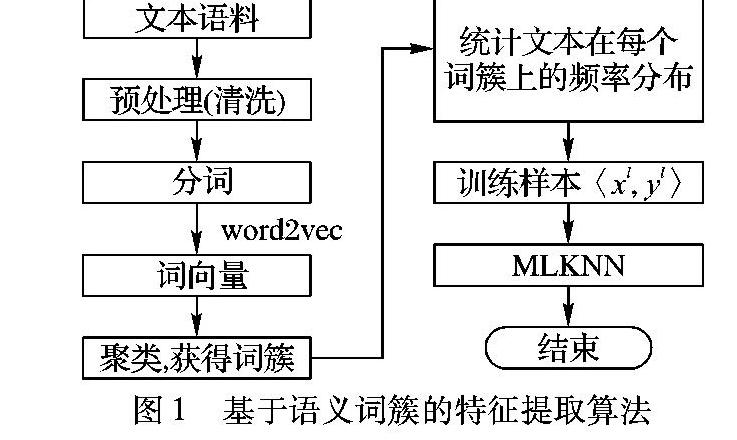
在语料中可以观察到,对于包含不同语义的文本,读者所呈现的情绪有所区别。例如,对于文本中出现与恐怖袭击、灾难相关的信息,大多数用户所呈现的情绪是悲伤或愤怒。为此,在文本特征提取方面,本文主要借助语义向量(word2vec)对语料进行初始表达。具体做法是:如图1所示,首先对文本进行预处理,然后分词,进而采用word2vec将词语映射到语义空间,在此基础上构建语义词簇,最后通过计算文本中各个词簇出现的频率获得可量化的文本特征。
之所以选用word2vec模型作为词语的初始表达,是因为该模型通过语料的学习,可以结合上下文信息,将词映射到V维的语义向量空间。基于这个转化,不同词语语义相似度可以通过其在语义向量空间上的相似度来度量,从而有望获得语义信息接近的词簇。在此基础上获得的词簇将比单纯的词语更有语义代表性,在一定程度上能够解决一义多词的问题。另一方面,将高维度的词向量聚集成词簇,还有助于解决传统词向量模型中的维度过高的问题。
2.2.2结合情绪标签的文本特征提取
然而,由于word2vec是一种无监督的学习方法,在训练时考虑的是整个语料库的信息,所有标签的代表词簇被融合在一起;尤其在标签集本身就有不平衡性(imbalanced)时,某些情绪标签的代表词簇有可能被样本数量较多的标签的代表词簇所影响。为了解决这一问题,我们在前述方法的基础上提出了一种改进方法——基于word2vec的多类别语义词簇构建方法mwc-word2vec(multiple word clustering based on word2vec)。
该方法基于以下假设:影响读者情绪的文本特征可以通过不同语义词簇的频率来刻画;引起读者不同情绪的文本中的代表词簇有所差别。
多类别语义词簇量化文本的过程如图2所示。其第一个关键点在于将语料根据情绪标签分成L个子集,对于每个子集Ωi 分别采用word2vec模型映射成词向量,再通过类似2.2.1节的方式得到文档在词簇向量上的频率,作为最终的文本特征。
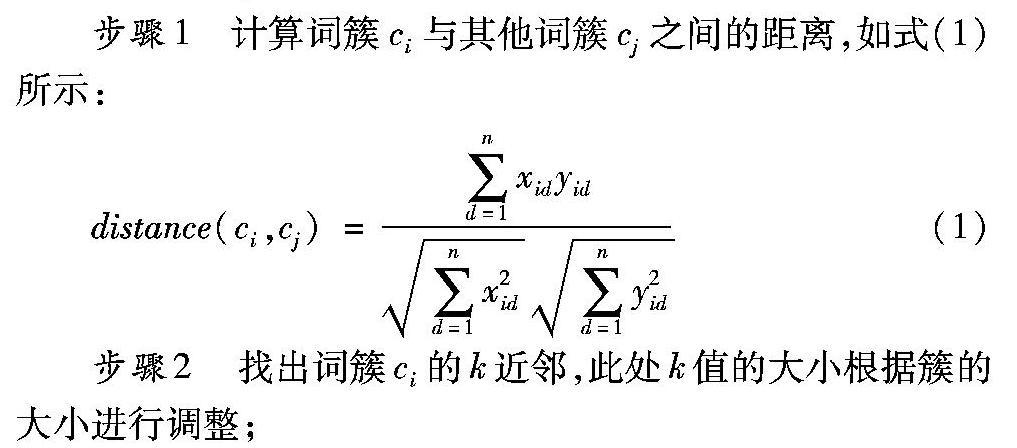
第二个关键点则是,考虑到同一个标签内的簇对该标签的影响力有一定的区别,也有可能存在不同标签之间的词簇相似度很大的问题,这样的词簇并不利于情绪的分析与计算。所以通过计算簇之间的余弦距离,筛选剔除掉对情绪标签分类没有实际意义的簇,即图2中的词簇筛选(*)。定义如下筛选原则:若任意一个簇的k近邻的标签信息都与自己的标签不同,则该词簇对于该标签没有代表性,因此可以被剔除。
在完成词簇的筛选以后,按照式(1)统计文本在每个词簇上的频率分布,从而完成文本的量化工作,得到结合情绪标签的文本特征,输入多标签分类器中。
2.3针对特征进行多标签分类
在完成文本的量化工作以后,将所得到的特征向量输入多标签分类器中。在多标签分类的阶段,采用MLKNN的方法进行分类。MLKNN是基于k近邻的多标签学习算法,它属于Lazy-learning的有监督的方法,直到给定一个测试元组才开始构造分类模型。采用MLKNN算法的优势是非常简单、易于实现。后续实验也表明,处理本文的多标签分类问题时,选择MLKNN作为本文的分类器是合适且有效的。
3实验结果与分析
实验数据来自于Yahoo Qimo的新闻语料,共有49000篇新闻,每篇包括标题、内容、投票总数以及各种情绪所占的比例。其中情绪的标签有8个,分别是:实用、感人、开心、超扯、无聊、害怕、难过、火大。实际的数据中有少量是没有投票的数据,也有部分是投票较少的数据,为了标签的准确性,避免数据的杂乱以及人为的干扰,选用有10票及以上投票的数据进行实验分析,实验数据共有22841篇新闻文本。
本文实验结果中采用汉明损失(HammingLoss,HL)、平均精度(AVerage Precision,AVP)、排序损失(RankingLoss,RL)、覆盖率(Coverage,Cov)以及1-错误率(OneError,OE)这五个指标进行评价,AVP的值越大说明分类的效果越好。HL、RL、Cov和OE的值越小说明效果越好。具体到每个标签的话,还采用F1值对分类效果进行评价。
3.1数据基本情况
选取具有相对较多读者投票(20票及以上)的15851篇新闻文本,共6369816投票数,即平均每篇新闻的投票数约为401,统计单标签情况下文本的标签分布情况,如表1所示。
由表1可知,单个标签情况下,数据存在不平衡的现象。某些标签,例如火大或者开心,有比较多的语料,而某些则存在语料不足的情况。通过观察数据的特点,不断调整阈值,最终选择较好的分界阈值为0.23,即如果某个标签有23%或者以上的投票比例,则默认该文档有这个标签,且把此标签标记为1,否则标记为0,由此得到的分布情况如表2所示。
通过表2发现,2个或以上的标签占了总数的52%,这也符合实际情况,同时反映了采用单标签分类技术来处理新闻文本的情绪分析问题不太合理,也从侧面验证了多标签是有必要的。实验中,将数据集分成两部分:随机选择总样本集中的2/3作为训练样本,剩余的1/3作为测试样本,并进行4次重复实验求平均值后再进行对比。
3.2实验对比
采用几种不同的方法对文本进行量化表达,然后将量化后的特征放入到MLKNN分类器中进行训练及测试,同时采用不同的参数进行实验效果的对比,结果如表3所示,其中LDA-MLKNN是文献[9]中所提出的一类方法;word2vec-mlknn及mwc-word2vec-mlknn是本文提出的方法。
固定特征数量为120时,通过选取不同的k值,比较k值对于MLKNN模型平均精度的影响。由表3以发现,当k=8时,能够获得相对较好的结果。但是,k值的选取对于平均精度的影响却不是很大,所以,在后续的实验当中选择k=8进行实验分析。
通过表4可以发现,采用word2vec模型处理数据的效果明显比LDA好,平均准确度比LDA增加约3个百分点,其他几种评价指标也更好。LDA的最好效果在特征维度为40时取得,最好的平均精度为77.18%;而word2vec的性能比较稳定,最好效果在特征为200个维度时取得,平均精度约为8046%;采用多类别语义词簇的方法处理文本数据得到的性能最好,平均精度约为83.14%,在word2vec的基础上有所提高。随着特征词簇的增大,word2vec以及多类别语义词簇的方法趋向稳定,且效果比LDA好。
具体到每个标签的情况,比较各个方法下最优参数的F1值,结果如表5所示。其中,LDA-MLKNN最好的F1值在特征维度为80时取得,word2vec-mlknn以及mwc-word2vec-mlknn最好的F1值都是在特征为240时取得。
我们发现,在不同的标签下F1值有比较大的差异,这其中存在一定的客观原因,包括某些标签语料不足等。但是,总的来说,在不同的方法中,mwc-word2vec-mlknn依然效果相对最好。
为了考察筛选参数对于模型的影响,给出了不同筛选参数对应的结果如图3所示,可以看出,选择不同的参数,对效果有不一样的影响。这里,考虑到不同的词簇大小应该根据不同的k值大小进行相应设置,令k值为词簇总数的百分比。结果显示,当筛选参数为词簇总数的1/4时,获得的平均精度整体上最高,也更加稳定。
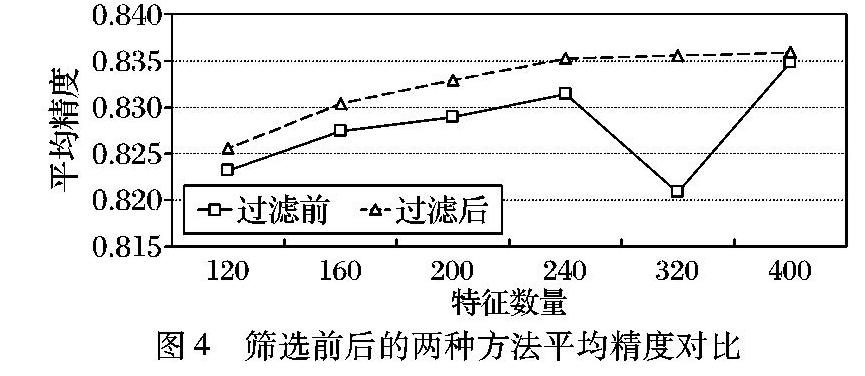
更进一步,针对mwc-word2vec-mlknn,设定筛选系数为词簇总数的1/4,改变词簇的数量,进行进一步的实验分析,结果如图4所示。图4显示随着特征数的增大,分类的平均精度慢慢趋向平稳。而且比较实验还显示:如果不进行过滤,在特征维度为320时,精度会有所波动;但采用了过滤方法后稳定性更好,更加健壮。这也说明了在情绪分类时过滤一些对标签分类没有明显区分度的词簇是有必要的。
4结语
本文深入研究了针对新闻文本的读者情绪分类和学习方法。通过研究word2vec对于文本分析的作用以及实际效果,明确了word2vec对于文本的情绪分析的作用。基于数据的特点,对word2vec作了改进,提出了多类别语义词簇的方法,解决了针对不同情绪标签下文本语义词簇的构建和表达。在word2vec训练的过程中加入文本的标签的控制,避免不同特定情绪标签语义词簇的干扰。同时,采用启发式的方法,对非代表性语义词簇进行过滤,强化了代表性词簇的表达能力,使得针对不同的情绪标签,所获得的特征具有更好的区分度。
情绪分析目前是一个热门的话题,也是一个重要的领域。在未来的工作中,我们将结合读者的评论信息以及个人信息,对文本的情绪进行更加细粒度的分析,获得更加完善的模型和方法。
参考文献:
[1]赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848. (ZHAO Y Y, QIN B, LIU T. Sentiment analysis [J].Journal of Software, 2010, 21(8): 1834-1848.)
[2]HATZIVASSILOGLOU V, MCKEOWN K R. Predicting the semantic orientation of adjectives [C]// ACL 98: Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 1997: 174-181.
[3]周咏梅,阳爱民,杨佳能.一种新闻评论情感词典的构建方法[J].计算机科学,2014,41(8):67-69. (ZHOU Y M, YANG A M, YANG J N. Construction method of sentiment lexicon for new reviews [J]. Computer Science, 2014, 41(8): 67-69.)
[4]TANG D, QIN B, LIU T. Learning semantic representations of users and products for document level sentiment classification [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1014-1023.
[5]TANG D, QIN B, LIU T. Document modeling with convolutional-gated recurrent neural network for sentiment classification [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1422-1432.
[6]QUAN C, REN F. Sentence emotion analysis and recognition based on emotion words using Ren-CECps [J]. International Journal of Advanced Intelligence Paradigms, 2010, 2(1): 105-117.
[7]XU R, CHEN T, XIA Y, et al. Word embedding composition for data imbalances in sentiment and emotion classification [J]. Cognitive Computation, 2015, 7(2): 226-240.
[8]GUI L, YUAN L, XU R, et al. Emotion cause detection with linguistic construction in Chinese Weibo text [C]// NLPCC 2014: Proceedings of the Third CCF Conference on Natural Language Processing and Chinese Computing, Volume 496 of the series Communications in Computer and Information Science. Berlin: Springer-Verlag, 2014: 457-464.
[M]// Communications in Computer and Information Science.
[9]叶璐.新闻文本的读者情绪自动预测方法研究[D].哈尔滨:哈尔滨工业大学,2012:35-43. (YE L. Research on emotion prediction of news articles from readers perspective [D]. Harbin: Harbin Institute of Technology, 2012: 35-43.)
[10]HURST M F, NIGAM K. Retrieving topical sentiments from online document collections [C]// Proceedings of SPIE 5296: Document Recognition and Retrieval Ⅺ. Bellingham, WA: SPIE, 2004: 27-34.
[11]雷龙艳.中文微博细粒度情绪识别研究[D].衡阳:南华大学,2014:20-36. (LEI L Y. Research on fine-grained sentiment analysis base on Chinese micro-blog [D]. Hengyang: University of South China, 2014: 20-36.)
[12]WANG S, LI D, WEI Y, et al. A feature selection method based on Fishers discriminant ratio for text sentiment classification [C]// WISM 2009: Proceedings of the 2009 International Conference on Web Information Systems and Mining, LNCS 5854. Berlin: Springer-Verlag, 2009: 88-97.
http://xueshu.baidu.com/s?wd=paperuri%3A%28a6e3d1f433b123dc1be397879e9a267e%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fwww.sciencedirect.com%2Fscience%2Farticle%2Fpii%2FS0957417411000972&ie=utf-8&sc_us=5991109085789876904
[J]. Expert Systems with Applications. Volume 38, Issue 7, July 2011, Pages 8696–8702
[13]BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [J]. The Journal of Machine Learning Research, 2003, 3: 1137-1155.
[14]BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[15]李芳,何婷婷,宋乐.评价主题挖掘及其倾向性识别[J].计算机科学,2012,39(6):159-162. (LI F, HE T T, SONG L. Opinion topic mining and orientation identification [J]. Computer Science, 2012, 39(6): 159-162.)
[16]MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [J]. ICLR Workshop, arXiv preprint arXiv:1301.3781, 2013.
http://xueshu.baidu.com/s?wd=paperuri%3A%289b96fcef89a076065163c0793f74f68c%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fadsabs.harvard.edu%2Fabs%2F2013arXiv1301.3781M&ie=utf-8&sc_us=151487362127720313
[17]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Advances in Neural Information Processing Systems 26. Cambridge, MA: MIT Press, 2013: 3111-3119.
[18]邓澍军,陆光明,夏龙.Deep Learning实战之word2vec[Z].网易有道, 2014: 16-17. (DENG S J, LU G M, XIA L. Deep learning practice of word2vec [Z]. Youdao, 2014: 16-17.)
[19]ZHANG M-L, ZHOU Z-H. ML-KNN: a lazy learning approach to multi-label learning [J]. Pattern Recognition, 2007, 40(7): 2038-2048.
[20]CHENG W, HLLERMEIER E. Combining instance-based learning and logistic regression for multilabel classification [J]. Machine Learning, 2009, 76(2): 211-225.
猜你喜欢
电子技术与软件工程(2016年15期)2017-04-27
软件工程(2016年12期)2017-04-14
电脑知识与技术(2017年5期)2017-04-08
电脑知识与技术(2017年3期)2017-03-27
智能计算机与应用(2017年1期)2017-03-23
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
读写算·教研版(2016年17期)2016-11-08
电脑知识与技术(2016年5期)2016-04-14
