
基于共享内存的并行LDA算法
2016-09-26 07:20刘晓升严建峰
计算机应用与软件 2016年3期
杨 希 刘晓升 杨 璐 严建峰
(苏州大学计算机科学与技术学院 江苏 苏州 215006)
基于共享内存的并行LDA算法
杨希刘晓升杨璐严建峰*
(苏州大学计算机科学与技术学院江苏 苏州 215006)
现有的共享内存的并行潜在狄利克雷分配(LDA)主题模型,通常由于数据分布的原因,线程之间一般存在等待导致效率低下。针对线程等待问题进行研究,提出一种基于动态的线程调度方案。该方案能够根据线程的数量进行分块,在此基础上及时为空闲的线程动态地分配任务,从而减少线程间等待时间。实验表明,这种新的调度方案能够有效地解决线程等待问题。该方案不仅在保证收敛精度的同时能够获得加速比25%的提升,还能显著提高向上扩展比。对于大规模分布式集群上单个节点的并行LDA算法来说,这种调度可以更有效地利用计算资源。
潜在狄利克雷分配共享内存并行动态调度
0 引 言
潜在狄利克雷分配(LDA)是现下非常流行的一种概率主题模型,自从2003年由Blei[1]等人提出以后,在文本挖掘,计算机视觉以及计算生物学等方面有着很好的应用。LDA已经被认为是分析大规模的非结构化文档集合的最有效的工具。LDA常用的近似推理方法有三种,吉布斯采样GS(GibbsSampling)[2]、变分贝叶斯VB(VariationalBayes)[3]、置信传播BP(BeliefPropagation)[4],其中精度最好的就是置信传播算法。随着近年来大数据的普及,单机单核版本的计算已经无法满足日益增加的数据处理需求,而并行计算就是最好的解决方案之一。而并行计算可以分为共享内存以及非共享内存两个方面。对于共享内存我们有多线程并行计算的OpenMP等,对于非共享内存的我们有消息传递机制MPI(MessagePassingInterface),以及hadoop,spark等平台。相对于非共享内存的并行计算,共享内存并行计算具有在多核或多CPU结构上效率高、内存开销小的优势。通常大规模的分布式集群就是将非共享内存与共享内存的并行算法进行混合编程,实现多主机与单机之间的优势互补。但是由于内存的共享,导致不同线程之间存在着读取写入的冲突,而通过“锁”这种方式虽然能够一定程度上解决冲突问题,但是依然会导致线程之间相互等待的问题。
本文基于共享内存的方式,在LINUX操作系统使用g++的编译环境,利用std中的thread模块来灵活地调动线程,通过动态调度线程来消除线程等待时间,实验表明,动态调度的线程能够显著提高算法的效率以及并行的加速比。
1 相关工作
非共享内存与共享内存这两种不同的并行框架,其本质的区别的就是对于内存的使用。对于非共享内存的方法,相对来说已经非常成熟了,从Newman等人提出近似分布LDA(AD-LDA)[5]开始,异步通信的异步分布LDA(AS-LDA)[6],使用MapReduce实现的Parallel-LDA(PLDA)[7],以及与AS-LDA完全不同的PLDA+[8]、Mr.LDA[9]的相继提出,非共享内存的LDA计算方法上得到了很好的扩充。
而对于共享内存的LDA,2007年的Yan[10]等人提出了将数据进行二维切分。这种分割方式,让数据能够在小内存的GPU上进行计算。通过这种数据流的方式来避免数据的冲突,从而实现了共享内存的并行LDA计算。GPU使得共享内存的LDA使用成百上千线程进行并行计算变成了可能,但是GPU的核心只能处理简单的计算,而且GPU本身的成本相对较高。而后,Yahoo!LDA[11]提出了一种黑板结构的memcached技术,通过分布式的共享缓存服务,使得LDA的参数矩阵保存共享状态。同时通过加锁的方式来解决两个或两个以上访问同一个内存块会导致严重的访问冲突。但是加锁的方式依旧会导致线程间会产生等待的问题。
2 LDA模型
LDA模型是一个无监督的概率生成模型[2]。模型假设文档集合是由有D篇文档组成的,该集合共有K个隐含的主题,其文档的生成过程如下:
θd~Dir(α)φk~Dir(β)
(1)
首先我们从β的狄利克雷分布中获得每个主题上单词的概率分布φk,重复K次。
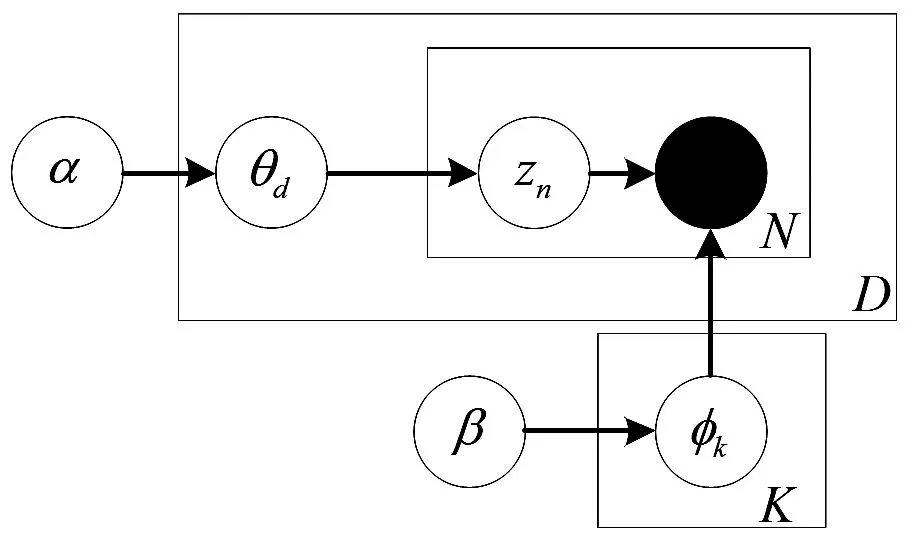
图1 LDA图模型
然后对于每一篇文档d,我们从α的狄利克雷分布中获取文档d上主题的概率分布θd,而zn是满足概率分布为θd的多项式分布的,我们可以通过θd中采样获得该文档的一个主题zn。在这里zn就是φk中的k,而我们知道wn是满足φk的多项式分布的,我们可以通过φk获得单词wn。重复以上过程N次,就是LDA中一篇文档的生成过程。其图模型如1所示。
3 基于共享内存的并行LDA
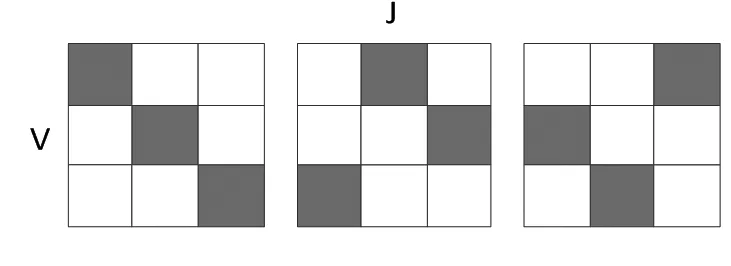
图2 互不冲突的块
对于一般的共享内存的并行LDA算法解决内存冲突的办法就是分块(blocks),通过为每一个线程划分出处理的范围,从而达到互不干扰的目的。如GPU-LDA中就是将文档划分为J={1,z,…,D},将单词划分为V={1,z,…,W},将互不冲突的块,分配给不同的线程。如图2所示。
我们可以看到,在这里的每个块,都是互不冲突的。即相互之间不存在相同的单词或者文档序列。
本文主要选取了BP算法作为主要的比较对象的原因是,BP算法在精度上有较大的优势,同时BP算法中不同文档之间是完全独立的。 另外一个原因是BP算法有相应的在线版本OBP(Online Belief Propagation),以及主动版本ABP(Active Belief Propagation)[12]等,有利于本文中调度方法后续的扩展。
在这里我们将一般的并行LDA算法称为PBP(Parallel Belief Propagation)。其中μw,d表示文档d中单词w的主题分布。具体算法过程如下:

算法1并行LDA(PBP)重复:1. Forl=0toT-1do:2. ForeachthreadTinparalleldo:3. 获取文档集d=Jt⊕l,获取单词集w=Vt⊕l4. 通过全局的θd,ϕw更新μw,d5. Endfor6. Endfor7. 同步,更新全局的θ,ϕ直到达到停止条件
对于每一次迭代,不同的线程之间是并行计算的。这里t⊕l表示t+lmodT,这保证了各个线程之间是相互独立不发生数据上的冲突的。在每个线程中都可以独立更新那一部分的μw,d,当所有的分块都计算完毕之后,我们再同步更新全局的θ和φ。当然在这里我们可以把中间的步骤换成任何一个LDA近似推断的方法也是可以的。
4 并行算法的调度优化
可以发现,传统的调度方法是通过为每个线程分配固定的非冲突任务来实现线程独立,进而来避免读写数据冲突。然而这种方法在数据分布不均匀时(大部分时候数据的分布并不是均匀的),就会造成不同线程之间任务的分配不均匀。这样最终导致的后果就是同步更新时,大多数线程需要等待某个任务最重(运行时间最长)的线程。
对此我们首先对数据进行随机洗牌[13],即对单词以及文档的序列进行随机的调换位序,这样可以一定程度上使得数据分布均匀(本文所有数据都由随机洗牌进行预处理)。另外就是不再为每个线程安排固定的任务,每当有线程呈现空闲状态的时候,可以通过调度获得与当前运行线程不产生冲突的任务块,直到当前次迭代任务完结需要进行同步更新为止,这种动态的调度处理,可以让每个线程在当前迭代过程中均为满负载运算。
图3是2个线程的动态调度示例,也就是我们动态调度的基本原理。将数据进行随机洗牌后,我们将数据分割成4P2块。当某个线程完成当前数据块的计算之后,能够迅速为空闲的线程找到一个与其他当前运行线程不会产生读写冲突的块,将之分配给该线程之后进行计算。例如:我们开始将1号块分给1号线程,而将6号块分给2号线程。当2号线程结束在6号块的计算时,1号线程还在进行1号块的计算。此时我们为2号线程分配了8号块,这是个与1号块不会产生冲突的块。当1号块的计算完毕之后,我们又为1号线程分配了14号块,此时2号线程依然在进行8号块的计算,依次类推直到所有的块都计算完毕。

图3 动态调度的线程
我们可以看到,2个线程在整个过程中没有等待时间的满负载运行。同时我们也可以注意到,不同的数据块,由于数据分布的问题,其计算时间也是不同的。比如,1和9号块,其计算时间差不多相差一倍。如果还是通过硬性分配的话,线程之间的等待时间无疑会是一个巨大的浪费。我们通过线程之间的动态调度,消除了等待时间。
我们称动态调度的并行算法为DPBP(DynamicParallelBeliefPropagation),其中R为训练数据集,P为线程数,其余变量与算法1中相同,其计算方法如下:

算法2加速优化并行LDA(DPBP)将数据R分为4P2块{R0,...,R4P2-1}重复:1. While(notallblocksfinished)2. Getonefreethreaddo:3. GetonefreeblockRi4. 由Ri获取文档集d=Ji,获取单词集w=Vi5. 通过全局的θd,ϕw更新μw,d6. Endfor7. Endfor8. 同步,更新全局的θ,ϕ直到达到停止条件
5 实验分析
5.1实验环境与数据集
本文基于单机多核服务器进行实验,该服务器有2个IntelXeonX5690 3.47GHz的CPU,每个CPU有6个核,总计12个核,140GB内存。在这里,为了保证并行效率,我们最多使用了12个线程进行实验。本文使用的两个数据集,分别是ENRON和NYTIMES,具体统计,概括统计实验用的三个数据集,这里D是文档的总数目,W是单词表的大小,NNZ表示总共有多少条记录,也就是非零数据的数量。具体如下:

表1 数据集
实验先验参数初始化都设置为α=0.01,β=0.01,由于主题数对我们并行LDA实验没有任何影响,故我们在这里统一将主题数K设置为100。本文中所有实验都是以主题数为100来进行计算的。
我们的实验将表1中的数据切割出1/5文档作为测试集,其余部分作为训练集。实验将表1中的数据在训练集上求得模型,在测试集上得到测试混淆度结果。同时为了满足向上扩展比的计算,本文将相对较大的数据集NYTIMES另外分出10到120MB(10,20,40,60,80,100,120)不同大小的7个小的数据集,而ENRON则是另外分出1到12MB(1,2,4,6,8,10,12)的7个数据集。
本文对基于共享内存的并行LDA即PBP进行线程调度上的优化,新的算法记为DPBP。
5.2评价标准
本文主要采用了混淆度,加速比以及纵向扩展比来评价算法的效果。其中混淆度,经常被用于语言模型之中,用来衡量语料库建模能力的好坏,混淆度的计算公式如下:
(2)
此处xw,d表示文档d中单词w的词频。其余变量与前文相同。越低的混淆度表示越好的泛化能力。
加速比通常用于评价并行的能力,加速比越高,说明并行能力越好。加速比其实也可以认为是并行资源的利用率。
纵向扩展比则是,在数据大小发生变化时,通过增加相应的线程,对并行算法效率的提升,也可以说是算法的泛化能力的一种比较。比如使用1个线程计算1MB的数据的时间和10个线程计算10MB数据的时间肯定是有差距的,其比值就是纵向扩展比。纵向扩展比越小,其泛化能力越好。
5.3实验结果分析
(1) 收敛效果比较
图4和图5是DPBP与PB在NYTIMES数据集以及ENRON数据集上收敛曲线的比较。

图4 DPBP与PBP在NYTIMES 数据集上的收敛比较

图5 DPBP与PBP在ENRON 数据集上的收敛比较
表2是我们在2个数据集上的综合比较,表示的是2个算法在不同的数据集的测试集上的收敛精度。

表2 DPBP与PBP的训练集集收敛时间与测试集收敛的混淆度
可以较明显的看出,DPBP算法不仅具有更快的收敛速度,同时其收敛精度与原算法并没有太大的差别。相对于PBP,DPBP并不会在本质上改变算法,只是通过调度改变了数据的计算顺序,通过减少调度时间,DPBP不仅能够对精度不产生影响并且能够显著地提升收敛速度。
(2) 加速比与向上扩展比
图6和图7是DPBP与PBP在NYTIMES数据集以及ENRON数据集上加速比的比较。当我们使用12个线程的时候在NYTIMES数据集上,DPBP相对于PBP的加速比提高了25%,而在ENRON数据集上,我们的DPBP要比PBP的加速比提高了18%。这是由于我们的调度算法可以更加有效地调度线程,使线程的利用更加的高效。当线程数量增加得越多、分块粒度越小,DPBP在加速比上的优势就更加明显。

图6 DPBP与PBP在NYTIMES数据集上的加速比

图7 DPBP与PBP在ENRON数据集上的加速比

图8 DPBP与PBP在NYTIMES数据集上的向上扩展比

图9 DPBP与PBP在ENRON数据集上的向上扩展比
图8和图9是DPBP与PBP分别在NYTIMES以及ENRON上关于向上扩展比的比较。我们可以看到当使用12个线程的时候,在NYTIMES上,我们的DPBP在向上扩展度方面,要比PBP提高了57%。而在数据集相对较小的ENRON数据集上,使用相应的线程数,我们的PDBP要比PBP提高51%。这是由于我们DPBP分割线程的粒度更小,使得数据量越是增加,线程之间负载越是均匀,DPBP的效率优势自然是越大。从而可以看出我们的DPBP在处理更大数据的时候有着更好的适应能力。
6 结 语
本文介绍了基于共享内存的并行LDA的一般构架,提出了通过动态调度实现的并行LDA算法。通过改进线程的调度,提高了线程的利用率,使得算法的运行更有效率,从而改善了基于共享内存的LDA算法。通过实验的比较,动态的线程调度,不仅在保证精度没有太大变化的同时,使得并行LDA的收敛速度以及加速比明显的提高,而且也使得算法的向上扩展比也得到了显著的提升。PDBP能够使并行LDA算法更加适用于海量的数据,以及大规模分布式集群并行算法的单机扩展。
[1] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of machine Learning research,2003,3(1):993-1022.
[2] Heinrich G.Parameter estimation for text analysis[R].Fraunhofer IGD Darmstadt,2005.
[3] Teh Y W,Newman D,Welling M.A collapsed variational Bayesian inference algorithm for latent Dirichlet allocation[C]//Advances in neural information processing systems.2006:1353-1360.
[4] Zeng J,Cheung W K,Liu J.Learning topic models by belief propagation[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2013,35(5):1121-1134.
[5] Newman D,Smyth P,Welling M,et al.Distributed inference for latent dirichlet allocation[C]//Advances in neural information processing systems.2007:1081-1088.
[6] Smyth P,Welling M,Asuncion A U.Asynchronous distributed learning of topic models[C]//Advances in Neural Information Processing Systems.2009:81-88.
[7] Wang Y,Bai H,Stanton M,et al.Plda:Parallel latent dirichlet allocation for large-scale applications[M].AAIM,2009:301-314.
[8] Liu Z,Zhang Y,Chang E Y,et al.Plda+:Parallel latent dirichlet allocation with data placement and pipeline processing[J].ACM TIST,2011,2(3):26.
[9] Zhai K,Boyd Graber J,Asadi N,et al.Mr.LDA:A flexible large scale topic modeling package using variational inference in mapreduce[C]//Proceedings of the 21st international conference on World Wide Web.ACM,2012:879-888.
[10] Yan F,Xu N,Qi Y.Parallel inference for latent dirichlet allocation on graphics processing units[C]//NIPS,2009:2134-2142.
[11] Smola A,Narayanamurthy S.An architecture for parallel topic models[J].Proceedings of the VLDB Endowment,2010,3(1-2):703-710.MLA.
[12] Zeng J.A topic modeling toolbox using belief propagation[J].The Journal of Machine Learning Research,2012,13(1):2233-2236.MLA.
[13] Zhuang Y,Chin W S,Juan Y C,et al.A fast parallel SGD for matrix factorization in shared memory systems[C]//Proceedings of the 7th ACM Conference on Recommender Systems.ACM,2013:249-256.
PARALLELLDAALGORITHMBASEDONSHAREDMEMORY
YangXiLiuXiaoshengYangLuYanJianfeng*
(School of Computer Science and Technology,Soochow University,Suzhou 215006,Jiangsu,China)
ExistingtopicalmodelofparallellatentDirichletallocation(LDA)withsharedmemoryneedstowaitbetweenthreadsasaruleusuallyduetotheunbalancedistributionofdata,whichleadstolowefficiency.Inthispaperwestudytheproblemofthreadwaitingandproposeadynamic-basedthreadsschedulingscheme.Theschemecanpartitionthedatatoblocksaccordingtothenumberofthreadsanddynamicallyallocatestaskstoidlethreadstimelyonthisbasis,soastoreducethewaitingtimebetweenthreads.Experimentshowsthatsuchnewschedulingschemecaneffectivelysolvethreadswaitingproblem.Itcanachievea25%raiseinspeedupswhileensuringconvergenceaccuracy,besides,itcanalsoremarkablyimprovetheupwardexpansionratio.ForparallelLDAalgorithmofasinglenodeinlarge-scaledistributedcluster,theschedulingcanmoreeffectivelyutilisethecomputingresource.
LatentDirichletallocationSharedmemoryParallelDynamicscheduling
2014-10-29。国家自然科学基金项目(61373092,61033013,61272449,61202029);江苏省教育厅重大项目(12KJA520004);江苏省科技支撑计划重点项目(BE2014005);广东省重点实验室开放课题(SZU-GDPHPCL-2012-09)。杨希,硕士生,主研领域:机器学习。刘晓升,博士生。杨璐,副教授。严建峰,副教授。
TP3
ADOI:10.3969/j.issn.1000-386x.2016.03.059
猜你喜欢
四川建筑(2022年2期)2022-06-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
山西电子技术(2019年4期)2019-09-07
科技视界(2018年28期)2018-01-16
科技风(2017年20期)2017-07-10
铁道建筑(2016年8期)2016-09-12
城市道桥与防洪(2014年5期)2014-02-27
组合机床与自动化加工技术(2013年1期)2013-12-23
