
基于相机运动子空间的人脸图像非均匀去模糊
2016-09-26 07:20郭晓磊曹萌萌薄一航
计算机应用与软件 2016年3期
郭晓磊 曹萌萌 薄一航
1(开封大学信息工程学院 河南 开封 475004)2(北京电影学院美术系 北京 100088)
基于相机运动子空间的人脸图像非均匀去模糊
郭晓磊1曹萌萌1薄一航2
1(开封大学信息工程学院河南 开封 475004)2(北京电影学院美术系北京 100088)
由于在相机拍摄的人脸中往往会存在较大的模糊,为了有效去除人脸图像的抖动模糊,提出一种基于非均匀去模糊与人脸特殊属性相结合的人脸图像去模糊方法。首先研究非均匀去模糊的原理,并提出通过约束相机运动子空间的方法来估计出相机与人脸之间的相对运动路径。再根据人脸的特殊属性,通过对清晰人脸训练得到一组清晰的人脸字典,建立人脸的先验知识。最后利用得到的非均匀模糊核和人脸字典对模糊人脸图像进行去卷积。实验结果表明,提出的方法相对于现有的去模糊算法可以得到更清晰的人脸图像,对后续的人脸识别有很大的辅助作用。
图像去模糊稀疏表达人脸图像非均匀模糊相机运动子空间
0 引 言
目前图像去模糊的方法有很多种,根据运动模糊的不同特征可以分为均匀去模糊[1]和非均匀去模糊[2]。在传统的去模糊中,通常都假设图像的模糊为均匀的,即只考虑相机与物体之间的相对平面内的平移运动。目前,针对均匀模糊的去除方法主要包括基于专业硬件芯片[3,4]、梯度统计[5]、稀疏表达[6,7]和边缘透明度的方法[8]等。但是这些方法只有针对自然图像的去模糊效果才比较明显,却很少有专门针对人脸图像模糊的去除方法[9]。视频监控已经广泛应用于生活的各个领域,通过视频图像对目标人物进行定位识别跟踪、刑事侦察和打卡签到应用中有着迫切的需求。但是在很多情况下,由于相机的抖动或者人物的行走会引起的人脸图像模糊,导致后续的人脸识别失效。为此提出了人脸图像的去模糊方法,传统方法都将运动模糊视为均匀模糊,没有考虑在相机成像平面外的运动。但在实际应用中,因为相对运动不能总是维持在成像平面内,均匀模糊的去除方法往往不能真正达到去模糊效果[10]。较早的文献通常将一幅输入图像分割成很多区域,其中每一个区域看作是均匀模糊,不同区域的模糊核各不相同,达到估计非均匀模糊核的目的[11]。Whyte[12]等人提出了一种新的非均匀去模糊的模型,将模糊图片看作是沿着相机路径拍摄的每一张图片的叠加总和,这些图片可以看作是清晰图片在相对运动轨迹上每个轨迹点的变形图片。基于这个新的模型,可以通过计算相机的抖动路径去除非均匀模糊。Gupta[13]等人提出了一种相似的去模糊模型,用相机在相机平面内的平移和旋转对相机的运动轨迹进行建模,也证明了只需要这三个自由度的参数就可以近似地估计出相机在空间中的平移与旋转。本文将非均匀模糊去除方法应用在人脸去模糊中,通过对相机的运动轨迹进行约束,可以更快速准确地估计出相机的运动轨迹。由于大部分文献对图像的先验知识是根据自然图像设定的,并不适合于本文的人脸图像。因此通过对人脸图像训练又得到人脸特有的稀疏字典,增加了人脸图像的约束,可以得到更好的人脸去模糊效果。
1 非均匀去模糊模型与图像先验知识
1.1非均匀去模糊模型
非均匀去模糊的模型可描述为过程:
B=∫f(Hθ,L)w(θ)dθ+n
(1)
其中,B代表模糊图像,L代表清晰图像。θ代表相机的运动轨迹参数,n代表噪声。采取文献[13]的方法,用平面内的平移和旋转来近似相机的抖动路径。Hθ代表在在相机姿势θ下的单应矩阵,f(Hθ,L)即为在θ相机姿势下变形后的图片。模糊图片B可以看作是在相机路径下所有变形图片的叠加与噪声n的总和。在离散情况下,模糊图片的离散表达形式为:
(2)
其中,Kθ代表在相机姿势θ下的变形矩阵。在三维空间中,相机的运动轨迹包括在x轴、y轴、z轴的移动和旋转,共计6个参数[14]。但是本文只考虑沿着x轴、y轴的平移和围绕z轴的旋转。因为沿着x轴、y轴的旋转可以用沿着y轴、x轴轴的平移近似。而沿着z轴的平移对图片的影响很小可以忽略不计。因此,原本6D的相机运动空间可以用3D的相机运动空间来近似。
因此,在非均匀去模糊中求解清晰图像是通过最小化如下能量函数得到:
(3)
其中,W代表权重wθ的集合。Φ(L)、Φ(W)分别代表L和W的先验知识。
1.2图像先验知识
为得到较好的去模糊效果,不仅需要准确估计出相机的抖动路径,还需要对清晰图像建立先验知识。由于相机抖动路径不可能被完美的求解得到,所以图像的先验知识在去模糊效果中也起到了关键作用。图像的梯度分布方法常被用于先验知识的构建,但并不适用于人脸图像的梯度分布。因为在自然图像进行去模糊处理中,梯度分布符合超拉普拉斯分布规律,然而人脸图像的梯度分布并不满足这一特性[15]。假设图像像素点的总个数为N,每个梯度幅值的个数为N,则自然图像与人脸图像梯度分布情况分别如图1中的(a)和(b)所示。
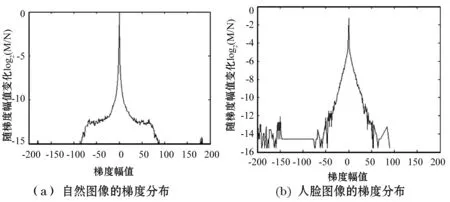
图1 自然图像与人脸图像梯度分布对比
从图1中可以看出,自然图像与人脸图像梯度分布存在一定的差异,利用自然图像的梯度分布对人脸图像建立先验会引起很大的误差。根据分析,本文对人脸图像需要建立一种新的稀疏先验,来达到清晰人脸的效果。
2 人脸图像去模糊模型
通过估计相机的抖动路径,并同时建立人脸的先验知识来达到人脸图像去模糊的效果,主要包括非均匀模糊核估计和人脸图像稀疏先验两部分,去模糊模型的步骤流程如图2所示。

图2 去模糊模型步骤流程图
2.1基于相机运动子空间的非均匀模糊核估计
首先对相机路径上所有姿势的权重进行初始化。定义T(θ,p)为在相机姿势θ下在像素位置p的变形函数,因此,在相机姿势θ下在像素位置p的模糊核可以表示为:
kθp=wθT(θ,p)
(4)
相机的整个路径在像素位置p噪声的模糊核则可表示为:
(5)
其中,S表示相机的整个路径,也即是相机姿势θ的集合。
首先利用均匀模糊的去除方法,在模糊图像上选取一些小的图像块来求出一些均匀的模糊核。本文中选取文献[1]的方法。根据求出的多个均匀模糊核,利用反向投影(BP)算法,可以得到投影值为:
(6)
其中,i代表模糊核kp的位置,Γ(θ)用来表明相机姿势θ是否起到作用,如果有,则Γ(θ)=1,反之Γ(θ)=0。因此,可以初始化相机姿势权重W为:
(7)
但由于估算的几个均匀模糊核并不准确,而且利用BP算法对这几个仅有的均匀模糊核进行非均匀模糊核重建必然会有很大的误差。同时,由于相机的抖动路径在运动空间是非常稀疏的,因此,可以进一步对相机姿势的权重利用下式进行初始估计:
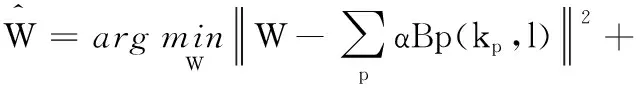
(8)
为得到更精确的权重W的估计,通过对权重W和图像L的迭代优化来得到更好的解。因为图像的导数在清晰图像估计中会起到积极的作用,可有效地去除环效应并且可以加速最优值的求解速度[16],因此本文利用图像的导数来求解清晰图像L和相机姿势权重W:

(9)
其中,▽∈{▽x,▽y,▽xx,▽xy,▽yy}代表图像L的一阶导数和二阶导数。从式(9)中可以看出,相机姿势的权重需要在整个运动空间S上进行优化,这样必然会引起计算速度大大的降低。但由于相机的运动路径应该是一个连续的一维路径,不应该是一个复杂的立体路径,如图3所示。

图3 相机的抖动路径
因此,需要将冗余的相机路径去除,在每次迭代过程中,将相机路径限制在一个运动子空间S′⊂S中。为了达到该目的,将每次迭代过程中得到的权重WS={w1,w2,…}按照降序排列,然后将末尾最小的m个权重取值为0,然后在剩余的权重对应的子空间{θ∈S′}中,重新对求解最有值:

(10)
s.t.Ws′≥0
2.2人脸图像先验
在每次的迭代过程中,当固定权重W后,需要对清晰图像L进行求解:
(11)
根据1.2节的分析,广泛应用的关于图像梯度分布的先验知识在人脸图像中并不适用,因此需要对人脸图像设计一个合适的先验知识。选取耶鲁人脸数据库中的部分图片用作训练集,该数据库分别对十个测试对象拍摄了不同的照片,选取其中5个对象的图片为训练集,其余部分用作测试集,通过训练集f={f1,f2,…,fn},来训练一个人脸的特殊字典D。
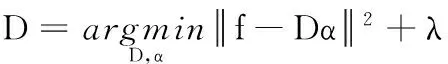
(12)
可以根据训练得到的人脸特殊字典,得到清晰人脸图像的先验知识:

(13)
其中,Ri代表提取图像L中的第i个图像块,选取图像块大小为8×8。字典大小为64×512。由于利用清晰的人脸图像进行了字典训练,因此在去模糊的过程中对人脸重建可以得到更加清晰的人脸图像。
3 实验结果与分析
实验选取耶鲁人脸数据库中三幅图像作为测试集的图片,并合成三个不同的三维空间的连续路径模糊核,根据三个清晰人脸图像分别合成三个不同模糊核的非均匀模糊人脸图片。实验通过三组图片展示本文提出的新模型的对模糊人脸图像的去模糊效果,并与文献[13]中Gupta等人提出的去模糊模型进行比较。
同时,实验采用的是评价效果较好的PSNR和MSSIM两种方法,峰值信噪比PSNR的计算公式为:
(14)
结构相似性MSSIM的计算公式为:
(15)
其中,式(15)中的SSIM是用来表示两幅不同图像的相似程度,表示公式如下:
(16)
其中,σx和σy代表图像x和y的方差。σxy是x和y的协方差。C1=(K1I)2,C2=(K2I)2,其中K1=0.01,K2=0.03,I代表图像灰度值的动态范围。计算结果的MSSIM值越大,越接近1,代表去模糊后的图像与原始无噪声图像的相似度越高,去模糊效果越好;而MSSIM值越小,则代表去模糊效果较差。
实验过程中,本文首先对模糊图像随机选取7个的小图像块用文献[1]求得7个均匀模糊核,利用反向投影法得到一个3D模糊核的初始值,然后进行后续的非均匀模糊核估计。测试图片选自耶鲁人脸数据库测试集中。对三张人脸图片分别用随机生成的3D模糊核进行模糊处理,然后用本文方法以及文献[2,13]的模型分别对测试图片进行去模糊并记录处理结果的PSNR值与MSSIM值,数值比较如表1所示。

表1 实验结果的PSNR与MSSIM的比较
从表1的结果可知,在三张测试图片中本文模型处理方法可以得到更高的PSNR和MSSIM值。在每张人脸图片的PSNR值平均比文献[13]可以提高2~3dB,MSSIM平均可以提高10%左右,比文献[2]可以提高1~2dB,MSSIM可以提高5%左右。因此,可以表明本文提出的方法比文献[2,13]可以得到更清晰的人脸图片。这不仅可以提高图片的视觉效果,而且也会在很大程度上提升后续对人脸图片的人脸识别等应用的准确性。
4 结 语
针对模糊人脸图片在均匀模糊的去处效果差的问题,提出了一种新的人脸去模糊方法。研究了图像的非均匀模糊的去除方法,并在现有的非均匀模糊方法上提出了改进,对相机的抖动空间进行了约束,使得本文模型可以得到更准确的相机抖动路径估计。另外,由于大部分的图像去模糊对图像的先验知识都是根据图像的梯度分布而建立的,但是该先验知识对于人脸图像却不适用。因此,提出了一种针对清晰人脸特有的属性,根据清晰人脸训练了人脸特有的稀疏字典,从而可以在去模糊的过程中可以得到更清晰的人脸图像。
[1]FergusR,SinghB,HertzmannA,etal,Removingcamerashakefromasinglephotograph[J].ACMTransactionsonGraphics,2009,25(3) 787-794.
[2]HirschM,SchulerC,HarmelingS,etal,Fastremovalofnon-uniformcamerashake[C]//IEEEICCV,2011:463-470.
[3] 范赐恩,陈曦,张立国,等.双CMOS成像系统中运动模糊图像的复原[J].光学精密工程,2012,20(6):1389-1397.
[4] 王敏,叶松,黄峰,等.基于突变粒子群算法的图像自适应增强[J].科学技术与工程,2012,12(26):6657-6660.
[5] 荆奇,宣士斌,吴瑞芳.基于侧抑制原理的局部分数阶微分图像增强[J].计算机工程与设计,2013,34(8):2826-2833.
[6] 黄晓生,黄萍,曹义亲,等.一种改进的基于K-SVD字典学习的运动目标检测算法[J].微电子学与计算机,2014,31(3):5-8,13.
[7] 许彬彬,戴清平,朱敏,等.基于哈夫曼编码的稀疏矩阵的存储与计算[J].计算机工程与科学,2013,35(11):134-138.
[8] 高薇,王珂,原发杰,等.基于不变矩的高分辨率遥感图像建筑物提取方法[J].计算机应用研究,2014,31(2):622-624.
[9] 朱珍,万志平,蒋鹏.改进单尺度Retinex的复杂光照人脸识别算法[J].计算机应用与软件,2014,31(3):246-249,262.
[10] 杨欣欣,王志明.改进的广义高斯分布与非局部均值图像去模糊[J].计算机应用研究,2012,29(5):1990-1992.
[11] 唐敏,彭国华.基于非均匀模糊核的RL改进算法[J].计算机工程与应用,2013,49(21):114-118.
[12]WhyteO,SivicJ,ZissermanA,etal.Non-uniformdeblurringforshakenimages[C]//IEEECVPR,2010:491-498.
[13]AnkitGupta,NJoshi,CZitnick,etal.Singleimagedeblurringusingmotiondensityfunctions[C]//IEEE,ECCV,2010:171-184.
[14] 刘京,孙哲南,谭铁牛.一种基于非局部正则化和可靠区域检测的虹膜图像去模糊算法[J].计算机科学,2014,41(1):54-58.
[15] 王国栋,徐洁,潘振宽,等.基于归一化超拉普拉斯先验项的运动模糊图像盲复原[J].光学精密工程,2013,21(5):1340-1348.
[16] 王国栋,潘振宽,刘存良,等.基于混合数据项的运动去模糊变分方法[J].仪器仪表学报,2013,34(7):1552-1558.
FACEIMAGENONUNIFORMDEBLURRINGBASEDONCAMERAMOTIONSUBSPACE
GuoXiaolei1CaoMengmeng1BoYihang2
1(School of Information Engineering,Kaifeng University,Kaifeng 475004,Henan,China)2(Department of Fine Art,Beijing Film Academy,Beijing 100088,China)
Sincethefacestobeshotbycamerawillusuallyhavebiggerblur,weproposedafaceimagedeblurringmethod,whichisbasedoncombiningthenonuniformdeblurringwithspecialfaceproperty,foreffectivelyremovingtheditheringblursonfaceimage.First,westudiedtheprincipleofnonuniformdeblurring,andproposedtoestimatetherelativemotionpathbetweencameraandfacebythemethodofconstrainingthesubspaceofcameramovement.Then,accordingtothespecialpropertyofface,weobtainedagroupofclearfacedictionarythroughtrainingclearfacesandestablishedtheprioriknowledgeoffaces.Finally,weemployedthederivednonuniformblurkernelandfacedictionaryforconvolutiononblurringfaceimage.Experimentalresultsindicatedthattheproposedmethodwasabletogetclearerfaceimagerelativetoexistingdeblurringalgorithm.Thisplaysagreatauxiliaryroleonsubsequentfacerecognition.
ImagedeblurringSparserepresentationFaceimageNonuniformblurCameramotionsubspace
2014-08-28。国家自然科学基金青年基金项目(61202 327)。郭晓磊,讲师,主研领域:计算机应用与人工智能。曹萌萌,讲师。薄一航,讲师。
TP391.41
ADOI:10.3969/j.issn.1000-386x.2016.03.045
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
文苑(2020年5期)2020-06-16
小学生学习指导(低年级)(2020年3期)2020-06-02
成都信息工程大学学报(2019年3期)2019-09-25
中国生殖健康(2019年10期)2019-01-07
动漫星空(2018年9期)2018-10-26
自动化学报(2017年5期)2017-05-14
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
