
基于教育数据仓库查询日志的内容分析
2016-09-24 02:55:01汪政
湖南第一师范学院学报 2016年2期
汪政
(湖南第一师范学院 信息科学与工程学院,湖南 长沙410205)
基于教育数据仓库查询日志的内容分析
汪政
(湖南第一师范学院 信息科学与工程学院,湖南 长沙410205)
通过对于不同用户在一个教育数据仓库大量的SQL查询进行系统分析,可更好地发现用户兴趣所在,实现性能的改善。前期通过利用数据挖掘方法,之后的进一步研究,数据挖掘不再成为主要的研究手段。这里具体研究考虑的对象是教育数据仓库,教育数据仓库是一个已知的教育行业的数据仓库,它包括数以百万计的查询日志信息。
数据挖掘;数据仓库;教育数据挖掘;教育数据仓库
引言
教育数据仓库是数据仓库在垂直领域上的一个行业细分,通过使用数据仓库的技术汇集不同来源的各种教育数据资源,形成覆盖教育各领域的、综合的、面向各种教育主题的教育数据资源中心。教育数据仓库不只是具备数据仓库的面向主题、集成、非易失的和随时间变化这四个最重要的特征,还应该具备友好的表现形式。
(一)面向主题
它是对应应用的过程中某一个宏观分析领域所涉及的分析对象,是针对某一决策问题而设置的,采用了一种在较高层次上对分析对象数据的一个完整统一并一致的描述面向主题的数据组织方式。
(二)集成
原有各个系统中存储的数据经过提取、整合、计算、去噪(抛弃分析处理中不需要的数据项,消除不一致和错误之处)和补充(增加一些可能涉及的外部数据)。
(三)非易失
从数据仓库设计原理和访问的机制出发,数据一旦进入教育数据仓库,在数据没有转换成为历史数据的这一段时间间隔内是不会丢失的。
(四)随时间变化
数据随时间变化定期更新,也就是说在每隔一段固定的时间间隔后,会抽取运行各个系统中产生的数据,转换后集成到教育数据仓库中。而之前的数据会以过去的版本的形式仍然保留在数据仓库中;
(五)友好的表现形式
一个友好、方便的使用界面设计面向教育行政部门的管理人员也是非常重要的。查询是教育数据仓库服务的最基本、最主要的内容。教育数据仓库系统中每天产生着大量的查询日志,通过对查询日志的内容进行分析,可以得出各类用户的查询习惯、倾向,而使用者的这些特征决定了教育数据仓库的结构、算法是否合理,对于教育数据仓库(如图1)建设和维护有很强的指导作用。如何对大量的查询日志进行内容分析,目前比较有效地就是通过数据挖掘技术。
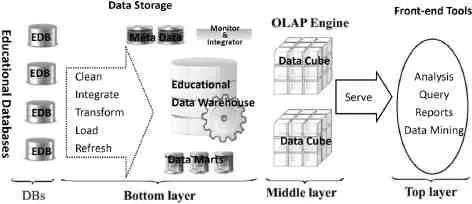
图1 教育数据仓库结构体系
一、查询日志的预处理
用户对于教育数据仓库的每一次查询都会被记录下来,记录的内容包括ID、URL、用户的IP地址、访问日期、时间、以及查询的类型等信息。随着数据技术的进一步发展和时间的积累,查询日志每时每刻都在迅速增大。如何充分的利用查询日志中记录的数据,从中发现用户的行为习惯、系统接受查询之后的反应效率、改进系统的设计也是一个新的研究领域。
数据预处理是日志挖掘中最重要阶段,是后续数据挖掘和分析能否顺利进行的前提和关键。数据预处理是为了将日志文件转换成数据库文件而进行的工作,其目的是把教育数据仓库的日志数据转换为适合进行数据挖掘的精确数据[2]。
用户查询教育数据仓库时会自动创建查询日志信息,包括各类日志等文件以微软的IIS产生的访问日志文件为例,其日志文件包含数据形式为:“2009-3-2 08:26:25 127.0.0.1 GET/vv/10 -01.xml 200”,其中以空格为分隔符标识,日志文件使用的是一种非关系模型的结构。首先对于日志文件进行预处理,才能进一步实现挖掘。查询日志源文件如图2所示。
目前,数据挖掘技术作为整个教育数据仓库挖掘过程的基础和实施有效挖掘算法的前提,数据预处理的目的就是将原始查询日志记录经过处理形成会话文件,为挖掘算法实施阶段作好数据准备。当前教育数据仓库查询日志的数据预处理一般包括以下3个阶段[3]:数据收集及数据清洗、用户识别、建立查询日志立方体。
1.数据收集及数据清洗
数据收集可以分为数据与管理层数据收集、OLAP与数据集市层数据收集。
图2 查询日志源文件
(1)数据与管理层数据收集:在数据与管理层查询日志中记录了每次查询教育数据仓库进行的每一次请求的信息,全面地记录用户的详细信息,比如:时间、日期、IP地址、访问的页面等等,并可通过记录Cookies和CGI的查询参数来描述各个不同用户的行为。使用数据与管理层查询日志来实现数据采集是有效的,能方便地分析出查询的行为习惯。
(2)OLAP与数据集市层数据收集:利用OLAP与数据集市层收集到的信息,系统管理员可以获取有价值的数据,从而有助于优化性能,有助于实现使用挖掘效率。
数据清洗是指根据需求对查询日志文件进行去噪处理,包括删除无关紧要的数据、合并某些记录、对用户请求页面时发生错误的记录进行适当的处理等等。
2.用户识别
用户识别,是从查询日志文件中的每一条记录中识别出查询的用户。一般通过三条规则,结合用户提交的查询信息便可以给不同的用户赋予不同的用户ID号。规则如下[4]:
(1)如果用户的IP地址不同,则认为是不同的用户;
(2)如果IP地址相同,而代理agent日志中表明用户的浏览器或操作系统改变了,则可以假设为两个不同的用户;
(3)将访问日志、引用日志和站点拓扑结构相结合构造用户的浏览路径。如果当前请求的页面同用户已浏览的页面间没有链接关系,则认为存在IP地址相同的多个用户。
通过对各种查询日志文件收集,之后进行清洗过滤,消除查询日志中冗余、不正确和无用的数据,整合成为关系数据模型(如表1所示)[5],到现在已经可以开始建立查询日志立方体。
3.建立查询日志立方体

表1 部分导入到关系数据模型的查询日志
查询日志立方体的核心是由事实表和维度表组成。事实表不只是可以使用数据的汇总,而且包括与相关联的维度表的外键;维度表通过不同角度观察分析事实表的记录来描叙事实表中记录的特性,如某一时间访问的次数、来至某域名的查询次数。查询日志立方体中主要参照以下4种维度:
(1)时间维:反映查询的日期和时间。
(2)页面维:反映查询了教育数据仓库中的哪些目录及页面
(3)用户维:反映查询的域名信息
(4)工具维:反映使用什么方式访问教育数据仓库。
查询日志立方体的结构如图3所示。
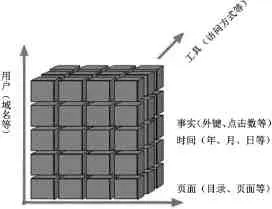
图3 查询日志立方体结构
二、教育数据仓库查询日志的内容分析
对于教育数据仓库查询日志立方体通过数据挖掘进行内容分析,能够发现隐藏在查询日志中的访问规律,了解使用者查询模式及行为模式,从而做出预测性分析,得到有价值的信息。数据挖掘阶段首先要根据内容分析的目标确定挖掘任务,根据内容分析的知识类型选择合适的挖掘算法,最后实施数据挖掘操作,运用选定的挖掘算法从查询日志立方体中抽取所需的知识。整个流程如图4所示。
查询日志立方体数据挖掘有3个问题需要关注:
(1)要针对查询和行为模式确定挖掘目标。对于过宽泛的群会使我们在庞杂的数据中,很难发现任何有价值的信息。
(2)要圈定合理的时间段和制定合理的数据规模,可以保证数据挖掘工作的顺利进行。过大和过小的数据量都不能使内容分析的结果接近正确值;过小的数据量很难说明普遍性的问题,容易使结果产生偏差;过大的数据量则会明显增加挖掘的难度,降低计算的效率。
(3)实际过程中可根据规则产生的实际数量和预定的目标对最小支持度和最小可信度标准作适当的调整,以界定边界规则的规模。
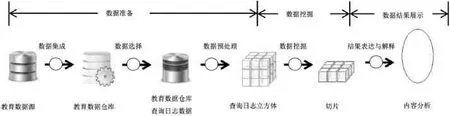
图4 查询日志内容分析的流程图
如对于使用者查询教育数据仓库的次序进行序列分析,预测今后的查询模式,进而对所需数据进行高速缓冲存储,以改善教育数据的流通状况等。挖掘的知识可通过规则、图表、图形等可视化的形式表现出来,还可对教育数据仓库查询日志中的数据进行分类、关联、比较、预测、聚类及时序分析等,下面就几种常用的分析加以简单地讨论[6]:
(1)时序分析侧重于分析数据间的前后关系,分析数据间的相似性、周期性。可以发现某一类教育数据的访问模式和访问趋势,进而调整教育数据仓库的存储结构和缓冲区域,以提高教育数据仓库查询的服务。对于教育数据仓库的查询日志而言,时间序列分析是最重要的一种分析方法,因为教育数据仓库的查询日志数据是根据查询时间来记录的。
(2)关联分析可挖掘出隐藏在查询日志数据间的相互关系。在查询日志立方体挖掘中,可以用来发现教育数据仓库上查询之间的相互关系,从而能合理安排教育数据仓库数据的优化,提高教育数据仓库的易用性和查询率.
(3)聚类分析是一种无指导的分类方法。在查询日志立方体挖掘中,可以根据查询日志寻找查询行为相似的簇组。教育数据仓库就能够为不同簇提供不同的定制内容,推荐个性化的查询服务,为教育领域整合、优化和完善更多的教育资源。
基于教育数据仓库查询日志的内容分析最终体现为对于挖掘结果的解释和评价:查询日志立方体内容分析即挖掘阶段发现的结果和解释,经过评估,可能存在冗余或无关的知识,这时需要将其剔除;也有可能结果和解释不能满足要求,需要重复上述挖掘过程重新进行挖掘。另外,基于教育数据仓库查询日志的内容分析最后可以使用可视化方式描述和展示,以易于理解。
结论
基于教育数据仓库查询日志的内容分析可以发现系统在使用的过程中的查询模式和查询喜好,同时,能够发现庞杂的查询日志数据中存在的隐含关系,将查询需求从定性分析上升到定量分析,这无疑对教育数据仓库的查询服务工作起到很好的指导作用。它不仅是教育数据仓库建设合理的教育资源保障体系的重要依据,也是教育数据仓库开展以查询需求为导向的各项服务工作的基础。
在教育数据资源数量和规模快速增长的情况下,把数据挖掘技术应用于教育数据仓库查询日志的内容分析是一项富有挑战性的研究任务。本文论述了利用数据挖掘技术对教育数据仓库查询日志进行方法和过程研究的同时,提出了关于查询日志的内容分析,设计和实现了一个查询日志立方体对教育数据仓库查询日志进行联机分析处理(OLAP)及数据挖掘,能够有效解决庞大的教育数据仓库查询日志的管理和分析处理问题,并对使用数据立方体对教育数据仓库查询日志进行挖掘进行了有益的探讨和研究。
数据挖掘(Data Mining—DM)技术就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的模式的过程。模式也就是所挖掘出的信息和知识[7]。本文中把查询日志看作是原始数据,查询日志是非结构化的,将来的研究可以把用户在查询时候的查询过程、查询结果等行为的流数据作为原始数据。基于教育数据仓库查询的内容分析在以日志作为基础的前提下,将来加入查询的流数据作为补充,内容分析的方法可以使数学的,也可以是非数学的;挖掘的方式可以是演绎的,也可以是归纳的。基于教育数据仓库查询的内容分析可以被用于数据的存储和管理、查询的优化、决策的支持以及过程的控制等,还可以用于教育数据自身的维护。借助查询的内容分析,可以及时发现查询中出现的问题,提高了教育数据仓库查询的效率和质量。同时借助教育数据仓库查询的各种日志记载每次查询性能及评价,方便日后的查阅及教育数据仓库状态的评估。
[1]张维明.数据仓库原理和应用[M].北京:电子工业出版社,2002:15.
[2]Wong J S K,Nayar R.A framework for a world wild web based data mining system[J2000(21):163-185.
[3]Ezeife,Lu Yi.Mining Web Log Sequential Patterns with Position Coded Pre-Order Linked WAP-Tree[J].2005(10):5 38.
[4]方杰,朱京红.日志挖掘中的数据预处理[J].,2010(20):18.
[5]席景科,张辰,谢红侠.基于数据仓库的Web日志挖掘技术研究[J].(24):5891-5892.
[6]宋爱波,胡孔发,董逸生.Web日志挖掘[J].东南大学学报,2002(1):15-18.
[7]毕长泉,曹健,王朝阳.基于高校图书馆流通日志的数据挖掘[Z].CHINA SCIENCE ANDTECHNOLOGY INFORMATION,2011(4):125.
[责任编辑:胡伟]
Content Analysis Based on Educational Data Warehouse Query Log
WANG Zheng
(School of Information and Engineering,Hunan First Normal University,Changsha,Hunan 410205)
The paper aims to analyze the SQL query to an educational data warehouse by individual users,and figure out the interest of the users and achieve improvement.Data excavation is employed in the former phase.Education data warehouse is a well-known database,which includes millions of query log information.
data excavation;data warehouse;educational data excavation;educational data warehouse
TP311.13
A
1674-831X(2016)02-0100-05
2015-11-12
汪政(1975-),男,湖南益阳人,硕士,湖南第一师范学院教师,主要从事大数据研究。
猜你喜欢
科普童话·学霸日记(2023年7期)2023-08-21 09:49:46
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
自然资源信息化(2019年4期)2019-03-29 03:20:48
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
中学生天地(A版)(2017年6期)2017-06-23 18:32:36
电子制作(2016年15期)2017-01-15 13:39:15
山东工业技术(2016年15期)2016-12-01 05:31:24
太空探索(2016年9期)2016-07-12 09:59:53
小学生导刊(低年级)(2016年6期)2016-07-02 22:22:15
