
社交网络中基于情感模型的用户转发行为预测
2016-09-24 01:31:32汤小东钱进四川大学计算机学院成都60065重庆市通信服务产业有限公司移动服务分公司重庆40400
现代计算机 2016年5期
汤小东,钱进(.四川大学计算机学院,成都 60065;.重庆市通信服务产业有限公司移动服务分公司,重庆 40400)
社交网络中基于情感模型的用户转发行为预测
汤小东1,钱进2
(1.四川大学计算机学院,成都610065;2.重庆市通信服务产业有限公司移动服务分公司,重庆404100)
0 引言
随着互联网技术的快速革新,社交网络在信息传播中的作用越来越重要。社交网络为人们提供一个表达自己观点和通过一系列行为(例如发布、转发和点赞等行为方式)与他人建立沟通的平台。在这个过程中将产生巨大的信息,如何利用这些信息将成为大多数研究者关注的核心问题。现如今,已经有很多学者从事预测用户行为的研究工作。然而他们大多使用机器学习的方法进行分类或预测,很少会分析隐藏在用户微博中的情感特征。但是这确实是分析用户兴趣与观点的重要的因素。
Suh等人[1]使用Twitter的数据作为研究对象,他们分析了影响微博被转发的几种因素,结果表明微博是否包含了URL和话题标记对微博的转发率有直接的影响,而微博作者的粉丝数,关注数和注册时常对转发率有间接影响,但是微博作者的微博数和转发率基本无关。他没有分析用户对微博的主观看法对转发率的影响。Wu[2]介绍了一种信息扩散方式,并且实现了一种逻辑回归模型来预测用户转发行为,但是他也忽略了基于文本的情感因素对预测结果的影响。
Naveed[3]介绍了一种基于微博内容特征的预测模型,他分析了用户对微博内容的正向及负向态度对转发率的影响,并且他设计了一种回归模型来预测用户的转发。但是他却忽略了周围用户群对转发率的影响。Zaman[4]将微博与用户的固有特征抽离出来进行分析,提出了一种概率协同模型来计算用户转发一条微博的概率。但是他没有考虑用户兴趣与对应微博内容之间的联系。
本文针对用户对短文本内容的主观看法,建立基于情感分析方法的主观模型,并结合基于周围邻居对目标用户转发行为影响的用户适应性模型,提出一种新的用户转发预测模型——混合模型。并设计实验验证混合模型可极大提升预测准确度。本文的主要贡献如下所示:
(1)设计并实现周围邻居对目标用户转发行为影响的计算方法,并提出随时间变化的迭代算法。
(2)设计并实现了基于情感分析的用户对特定微博的话题相似度计算方法。
1 用户特征分析
在社会心理学分析中,一个人第一次所做的决定往往是在潜意识中完成的。然后会根据周围环境选择改变行为或决定。这就是所谓的适应性。因此预测用户在社交网络中的行为时我们应该考虑到个人潜意识下的决定和环境的改变两方面因素。我们做出以下假设:
假设1:用户在社交网络中的转帖行为只受个人选择和周边人群选择的影响;例如,在研究Twitter用户的转帖行为时,当用户u0发布帖子w,我们将预测用户u转发该帖子w的概率。
假设2:用户个人选择只受用户兴趣的影响;即用户与该微博的话题相似度。
为了测量用户个人选择对他的转帖行为的影响,我们基于假设2来建立用户主观模型;在主观模型中,我们考虑用户两方面因素来计算话题相似度pw(u):
(1)兴趣相似度DIu(w):我们将测量用户u对帖子w的兴趣相似度,因为只有用户感兴趣的话题才会被用户转发。
(2)观点相似度sim(u,w):我们将测量用户u对帖子w的观点持同意或反对态度。
结合兴趣相似度和观点相似度,我们将计算用户与该微博的话题相似度。
pw(u)=αDIu(w)+(1-α)sim(u,w)
其中:α(0<α<1)为两方面因素的权重。
假设3:用户转发的概率和周围用户群转发概率成单调递增关系;例如,当用户u周围用户转发w概率相当大时,即使用户u对该w话题相似度较低,用户u仍可能会在一段时间内转发w;
为了测量用户受周围人群的影响,我们根据假设3建立用户适应模型。
pw(u)t+1=BNw(u)+(1-B)pw(u)t
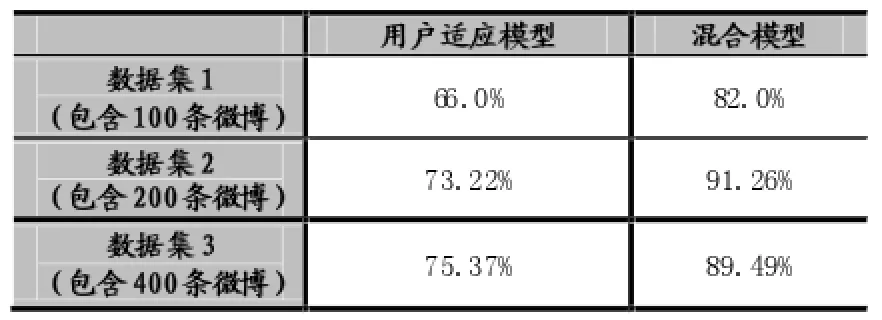
其中:B(0 2.1用户主观模型 在数据预处理阶段,对每一个用户u,我们收集用户u的50条微博作为单个用户数据集。使用Gensim工具[5]来提取每个用户话题集Tu。当计算用户u与帖子w的话题相似度时,我们从Tu中提取出k个与帖子w的相关度较高的话题组成一个新话题集T(u,m)={t1,t2,…,tk}。 用户u对帖子w的兴趣相似度。 其中:DRw(ti)表示帖子w与每个话题ti(ti∈Tu,m)的相关度。 其中νw表示帖子w中的单词,num(νw)表示单词νw在帖子w出现的个数。WPν(ti)表示单词νw在话题ti中的权重。DIu(ti)表示用户u对话题ti的兴趣度。 其中Wu(ti),Wu。Sω表示帖子w的情绪度。Sω=sp(w)+|sn(w)|.sp(w)表示帖子w的正向情绪度,sn(w)表示帖子w的负向情绪度。我们使用情绪检测工具SentiStrength[6]来测量话题w的正向情绪度sp(w)和负向情绪度sn(w)。 用户u对帖子w的观点相似度: 其中maxDist表示两个观点之间最大的不相关程度,在模型中我们定义maxDist=9。dist(u,w)定义为用户u对帖子w的观点与帖子w所表达的观点的不相关程度。为了计算用户关于帖子w的观点,我们引入情感度量标准。在此标准中,用户对观点的情感表示可分为10个级别,正向情感有(1,2,3,4,5)5个量度来表示,负向情感由(-1,-2,-3,-4,-5)5个量度来表示。 其中VPu(w)∈R10来衡量用户u关于帖子w的情感度,其中每一个分量都表示对应情感量度的权重。VPw∈R10表示帖子w的情感度。其计算方式如下: VPu(w)的计算方式如下: 其中VPu(ti)∈R10来衡量用户u关于观点ti的情感度,可以通过以下方式来计算: numu(ti)表示用户u转发与话题 ti相关的帖子个数。即就是满足DRw(ti)>0的帖子个数。numu(ti,s)表示满足DRw(ti)>0并且Sω=s。其中s的计算方式如下: 2.2用户适应模型 基于用户主观模型,我们使用用户适应模型来实时更新用户话题相似度pw(u): 其中Nw(u)t表示的在时刻t所有邻居的决定对用户u的影响。 其中v表示用户u的邻居用户。Nu(v)表示在时刻t用户v对用户u的影响。C定义为最大邻居个数。sim (u,v,w)表示用户v与用户u在帖子w上的观点相似度。 其中Pw(v)t表示在时刻 t下用户 v转发帖子 w的概率。Pwt-1表示在时刻t-1下所有用户转发帖子w的平均概率。pmaxwt-1表示在时刻t-1下所有用户转发帖子w的最大概率。 3.1数据预处理 本文利用Twitter API随机抽取约500名用户,并收集在2012年8月1日至10月30日之间这些用户的好友信息,发布或转发的微博信息,好友发布或转发的微博信息,微博信息之间的转发关系等组成原始数据集。本文将测试数据集定义在2012年8月1日至10 月1日之间。为了去除大量的无效信息及无效用户,本文定义一下约束: 在2012年8月1日至10月1日之间,一条去掉噪音和停用词之后至少包含10个实用词,并且被转发2次以上的微博可被定义为有效微博。 在2012年8月1日至10月1日之间,发布或者转发过至少200条微博,并且这些微博中至少有包含50条有效微博的用户可被定义为有效用户。 在2012年10月1日之后,一条去掉噪音和停用词之后至少包含5个实用词,并且被转发2次以上的微博可被定义为测试微博。随机提取出1000条有效微博,并随机收集200个发布或转发这些有效微博 本实验从原始数据集中提取有效用户建立用户训练集。并且从原始数据集中随机收集用户训练集中每一个用户发布或转发的50条有效微博,使用Gensim工具[5]将它们划分为最多5个话题集作为用户话题集。对原始数据集中的每一个微博,本文使用SentiStrength工具[6]对其进行情感分析,得出每条微博的正面情感值(在1到5之间)和负面情感值(在-1到-5之间)。本实验从原始数据集中分别提取出100条,200条,400条测试微博作为用户测试数据集。 3.2实验结果 表1 在三种数据集下两种模型的预测结果 图1 在不同时间段内微博平均转发次数的走向 考虑用户u在社交网络中的邻居对u的影响因素来预测测试集合中每条微博的转发情况:本实验实现用户适应模型算法,将每个用户u和每条被测试的微博的 pw(u)的初值设定为一个的随机小数d(0 综合考虑用户u对于微博的主观情感,以及 u在社交网络中的邻居对u的影响因素来预测测试集合中每条微博的转发情况:本实验实现混合模型算法,基于用户主观模型来计算每个用户u和每条被测试的微博,pw(u)的初值,迭代次数设置为10。 针对每一条测试微博,基于两种模型分别计算用户训练集中的每个用户的转发可能性 pw(u),并将实验结果排序,取其前2%的用户作为预测结果。预测结果如表1所示,将用户的主观情感加入社交网络中可以极大地提高预测的准确度。同时本文跟踪了数据集中的每一条微博,并统计每一条微博在不同时间段的平均转发次数。如图1所示。 社交网络的兴起,给研究社会影响现象提供了理想的实验平台。同时,对社会社交网络的研究又能对改进社交网站的某些应用起到帮助作用。我们对基于Twitter的社交平台中用户的潜意识的主观看法对其转帖行为影响的进行分析研究。发现用户潜意识的看法有助于提升预测其转帖行为的准确性。本文提出了基于情感分析的主观模型建模方法,和用户适应性模型的建模方法。这对于基于短文本信息的主题、情感、内容等语意信息对社会网络的影响提供了指导作用。而且这一方面的研究也使我们能够更好地分析和度量社会网络上用户的社会影响力。 [1]Suh,B,Lichan Hong,Pirolli,P.,Chi,Ed H.Want to Be Retweeted Large Scale Analytics on Factors Impacting Retweet in Twitter Network[C].2010 IEEE Second International Conference on Social Computing.Minneapolis:IEEE Computer Society,2010:177-184 [2]Wu K,Ji X,Liu C.Information Diffusion Model for Microblog[C].Software Engineering and Service Science(ICSESS),2013 4th IEEE International Conference on.IEEE,2013:212-215. [3]Naveed N,Gottron T,Kunegis J,et al.Bad News Travel Fast:A Content-Based Analysis of Interestingness on Twitter[J].uni,2011. [4]Zaman T R,Herbrich R,van Gael J,et al.Predicting Information Spreading in Twitter[C].Workshop on Computational Social Science and the Wisdom of Crowds.Whistler:NIPS,2010:17599-17601 [5]Khosrovian,Keyvan,Dietmar Pfahl,and Vahid Garousi.GENSIM 2.0:a Customizable Process Simulation Model for Software Process Evaluation.In:ICSP'08 Proceedings of the Software Process,2008 International Conference on Making Globally Distributed Software Development a Success sSory,pp.294-306 [6]Thelwall,Mike,Kevan Buckley,and Georgios Paltoglou.Sentiment Strength Detection for the Social Web.In:Journal of American Society for Information Science and Technology 63.1,pp.163-173 Twitter;Retweet Behavior;Sentiment Analysis;Social Network Prediction of User's Retweet Behavior Based on Sentiment Analysis in Social Network TANG Xiao-dong1,QIAN Jin2 (1.College of Computer Science,Sichuan University,Chengdu 610065;2.Chongqing Communication Services Company Limited,Chongqing404100) 1007-1423(2016)05-0033-05 10.3969/j.issn.1007-1423.2016.05.007 汤小东(1990-),男,陕西杨凌人,硕士,研究方向为机器学习、图形图像处理 2015-12-24 2016-01-23 基于Twitter的用户社会影响力的分析一直是社交网络分析的热点。然而很少有研究针对用户对微博的主题、情感、内容等语意信息的主观看法来预测用户的转贴行为。实现基于周围邻居对目标用户转发行为影响的用户适应性模型。并且实现基于语义分析的用户主观模型结合用户适应性模型的混合模型。设计实验证实用户对微博内容的主观看法极大影响预测结果。 Twitter;转贴行为;情感分析;社交网络 钱进(197l-),男,重庆人,本科,工程师,研究方向为通信传输 Retweeting behavior on Twitter is the behavior that user reposts comments from their friends.Few studies have investigated in combining a user's subjectivity motivation with his conformity to environment to predict a user's retweeting behavior.Based on the sentiment analysis,combines a user's subjectivity motivation with a designed adoption model which measures a user's neighbors'influences,and then establishes a mixture model with these two factors to do prediction.Evaluates the model in Twitter dataset to verify its prediction performance.2 用户转发行为建模
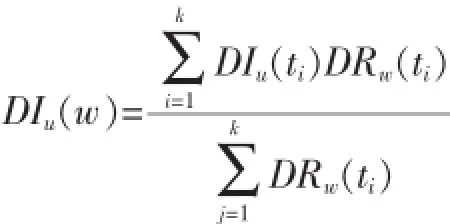
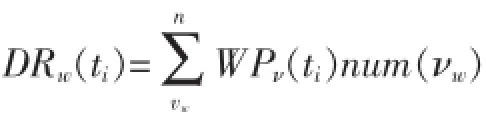

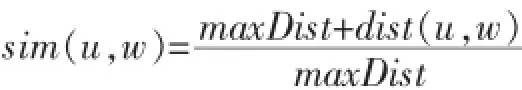
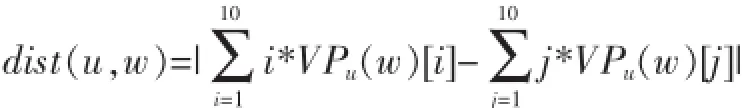


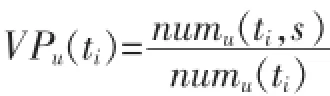
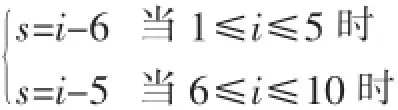
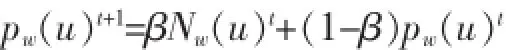
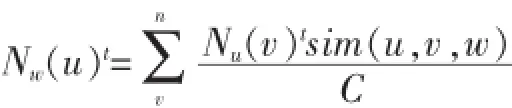
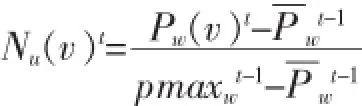
3 实验设计

4 结语
猜你喜欢
英语世界(2023年6期)2023-06-30 06:28:28意林彩版(2022年2期)2022-05-03 10:25:08中共云南省委党校学报(2022年1期)2022-04-26 13:55:44小学生优秀作文(低年级)(2020年4期)2020-07-24 08:31:16第一财经(2020年4期)2020-04-14 04:38:56文苑(2018年17期)2018-11-09 01:29:28法律方法(2018年2期)2018-07-13 03:22:06小雪花·成长指南(2016年11期)2016-12-07 06:14:37女性天地(2012年11期)2012-04-29 00:44:03小品文选刊(2009年7期)2009-05-25 09:59:52
