
基于卷积神经网络的图像分类研究
2016-09-24 01:31:38杨莹张海仙四川大学软件学院成都610065
现代计算机 2016年5期
杨莹,张海仙(四川大学软件学院,成都 610065)
基于卷积神经网络的图像分类研究
杨莹,张海仙
(四川大学软件学院,成都610065)
0 引言
图像识别技术的基础是分析图像的主要特征,正如人类的图像识别过程,复杂图像的识别需要经过多个层次信息的整合以及加工,才能够将分散的对图像单个特征的认知识别进行整合,形成对图像的最终识别分类。相类似的,如何让计算机在进行数字图像处理时使用类似的特征提取机制,对于图像的关键特征进行提取之后再进行整合,从而达到最终的认知分类目的成为近年来图像识别研究的热点。
卷积神经网络(CNN)在诸如手写数字识别以及人脸识别方面都被证明有着非常出色的表现。如Ciresan 的Deep Neural Networks for Image Classification[1]证明了在NORB和CIFAR-10数据集上采用卷积神经网络进行分类的效果非常好,同时,Krizhevsky等人在2012 年ImageNet的卷积网络模型应用中取得16.4%的错误率更是吸引了全世界的瞩目。总的来说,卷积神经网络是深度神经网络的一种,它主要的训练方式同传统的深度神经网络(DNN)一样,都是通过前向计算输入与权值的内积得到输出,之后通过反向传播(Back Propagation,BP)算法不断迭代更新权值,结合梯度下降方法,最后得到能使整个网络最优的权值。除此之外,相比传统的DNN,卷积神经网络的局部感受野方法、权值共享以及下采样等手段,对图像的位移不变性、旋转不变性都有很大优势。首先,局部感受野方法很大程度上模拟了人的视觉神经系统,通过局部印象来形成最终对事物辨识认知的过程;权值共享让同一特征图下的连接边共享庞大的参数集合;而最具代表性的卷积和池化方法也使得提取的特征更加稳定,从而,最终的识别效果得到提升。本文将针对不同的数据集,通过建立三个卷积神经网络模型对数据集进行训练和识别,通过微调参数达到更好的识别效果。
1 实验设计
1.1模型设计
(1)LeNet-5
LeNet-5是Yann LeCun在1998年针对手写数字识别问题的解决时提出的一个深度卷积网络模型[2]。LeNet-5同其他的深度神经网络一样采用BP算法进行权值训练。
通常在LeNet中使用的激活函数为sigmoid函数,但是在本文使用的Caffe框架下,实验使用的是线性修正单元(Rectified Linear Units,ReLU)作为激活函数。在神经元的连接方式上,LeNet采用了CNN网络中所特有的局部连接、权值共享的网络构造方式。为了模仿生物视觉神经网络中先进行局部的物体感受分析,最后汇总形成认知的方式,LeNet采用了局部连接的方式,即一个隐层神经元并不连接全部输入层神经元而是连接部分输入层神经元,从而减少网络连接个数,具体连接方式如图1所示。
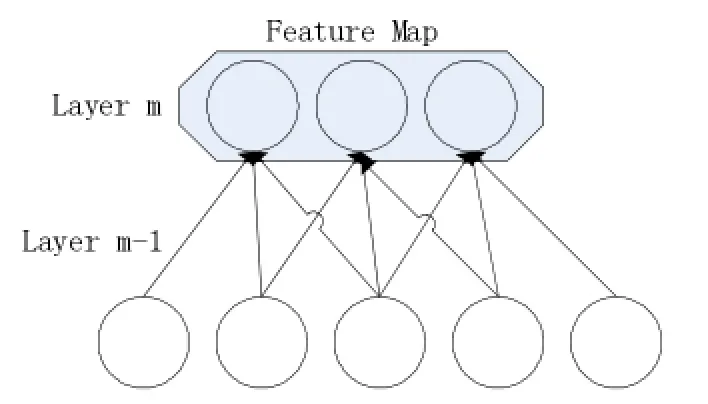
图1 局部连接图解
并且,在实验中卷积时需要提取多个特征,所以有多个特征维度(Feature Map),本文中因为采用了维度共享方式,所以每一个特征维度共享一组权值。
(2)AlexNet
AlexNet是多 伦多 大学 Alex Krizhevsky,Ilya Sutskever,Geoffrey E.Hinton在2012年参加ImageNet LSVRC比赛上提出的神经网络模型[3]。在结构上,AlexNet由5个卷积层、3个全连接层之后,再加上一个softmax分类器。相比于其他网络模型,AlexNet特点在于,首先,对于神经元的激活函数抛弃了tanh函数,采用了ReLU函数进行激活;其次,在部分神经网络层采用了局部响应归一化 (Local Response Normalization)、随机删除(dropout),还有重叠池化(Overlapping Pooling)的手段进行过拟合(over-fitting)问题的优化;在数据集方面,该网络采用了扩充(Augmentation)方式,在运行训练网络时采用了两个GPU并行训练策略,加快大图片集合下的训练速度,帮助提高最终的识别正确率。
本文中实验所使用的网络模型与原论文提出的AlexNet网络模型结构上大致一致,主要的不同点在于网络的归一化和池化顺序不同,附加的偏差值(bias)也与原论文不同,具体如下:
①采用ReLU函数进行激活:
一般网络中神经元的输出激活函数通常为sigmoid函数,或者是LeNet等网络中常见的tanh函数,但是出于训练时间的考虑,在AlexNet中采取非饱和非线性的函数ReLU,这种方法是由Nair与Hinton提出来的[4],它是一种线性修正的方式,通过强制某些数据为零,引导网络模型具有适度的稀疏性,在训练过程中更快的到达收敛点。
②局部响应归一化:通过对比实验能够证明,使用局部响应归一化函数可以提高准确率。
③重叠池化:卷积网络模型通常都会在卷积操作过后对图像进行池化(Pooling)操作,使图像在平移、旋转后特征有更好的稳定性。池化操作一般都不进行两个池化算子矩阵的交叉重叠,跨越的步长和算子大小通常是一致的。但是,在AlexNet中,设置跨越步长参数小于算子,通过重叠池化的方式能够避免过拟合。
1.2实验数据集
①MNIST数据集:经典的开源手写数字图片集合,共有0-9一共十个数字的手写图片分类,每个分类下有属于该分类的平均约1000张单个手写数字的图片,图片格式为jpeg格式、8位灰度图片,像素大小统一为28×28。
②Julia数据集:数据挖掘竞赛Kaggle的经典开源数据集之一,有EnglishImg和EndglishHnd两个大分类,EnglishImg分类的图片是截取自各个场景图片下的单个数字或者字母,包含了A-Z,a-z,0-9字母和数字的62个子分类图片,每个分类下有30-120张不等的字母或是数字图片,属于该分类的图片均为彩色png格式图像,图片大小的变化范围比较大,没有经过格式规范化处理,每张图片所呈现的字符或者数字都是其原有图片的分辨率。EnglishHnd图片集分类下的图片是背景均为白色的手写数字或是字母图片,包含了AZ,a-z,0-9字母和数字的62个子分类,每个子分类下均有55个手写数字、或字母样本图片,格式为png格式,图片大小为1200×900。
③Leaves数据集:Leaves数据集是来自于加州理工的一个开源树叶图片集,由Markus Weber在加州理工校园内和校园附近拍摄采集,共186张图片。图片集下一共三个子分类,每个子分类60张图片,格式为jpeg格式,大小896×592,图片背景不同。
④CalTech101数据集:来自加州理工的经典图片分类数据集,该数据集包含有101种不同的实物,有动物、植物、乐器、电子产品等子分类,每个子分类的图片数目从40-800张不等,图片格式均为jpeg格式,图片大小不固定,大致在300×200像素。
2 实验
实验环境为Caffe的Digits平台,实验过程通过将搜集的数据集分别输入网络模型训练,根据实验结果迭代调整相应的网络参数,并加入GoogleNet作为网络实验效果对比,得到不同网络针对不同数据集的识别效果横向比较结果。
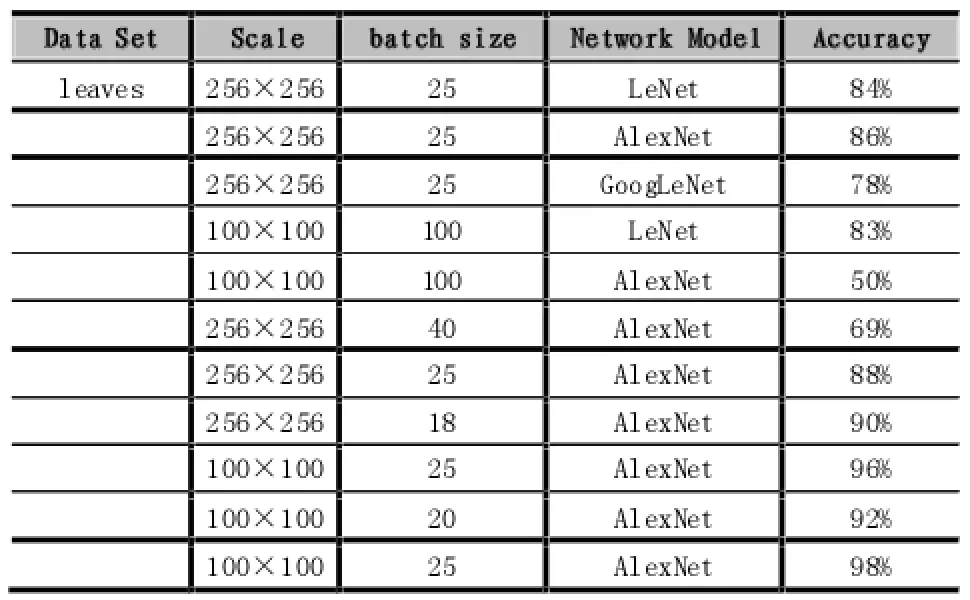
表1 Leaves分类实验结果
如图2所示,三个网络相比较之下,AlexNet网络模型相对适合Leaves数据集分类,而从数据集来说,Leaves树叶图片集中树叶形状轮廓分明,边界特征比较明显容易提取,待识别的树叶物体也多集中于图片的中央位置,且图片背景变化很小,大概一致,所以实验后期在已有AlexNet网络架构的基础上对原始图片进行了截取操作,让图片中心的树叶形状得到放大,减少背景部分的干扰噪声作用,而网络结构参数方面,同时处理的图片数据量(Batch size)适当减小,对第一层卷积的步长也进行减小,Batch size大小固定在25的时候,网络识别精确度保持在一个比较好的范围内,得到了最终98%的识别准确率。
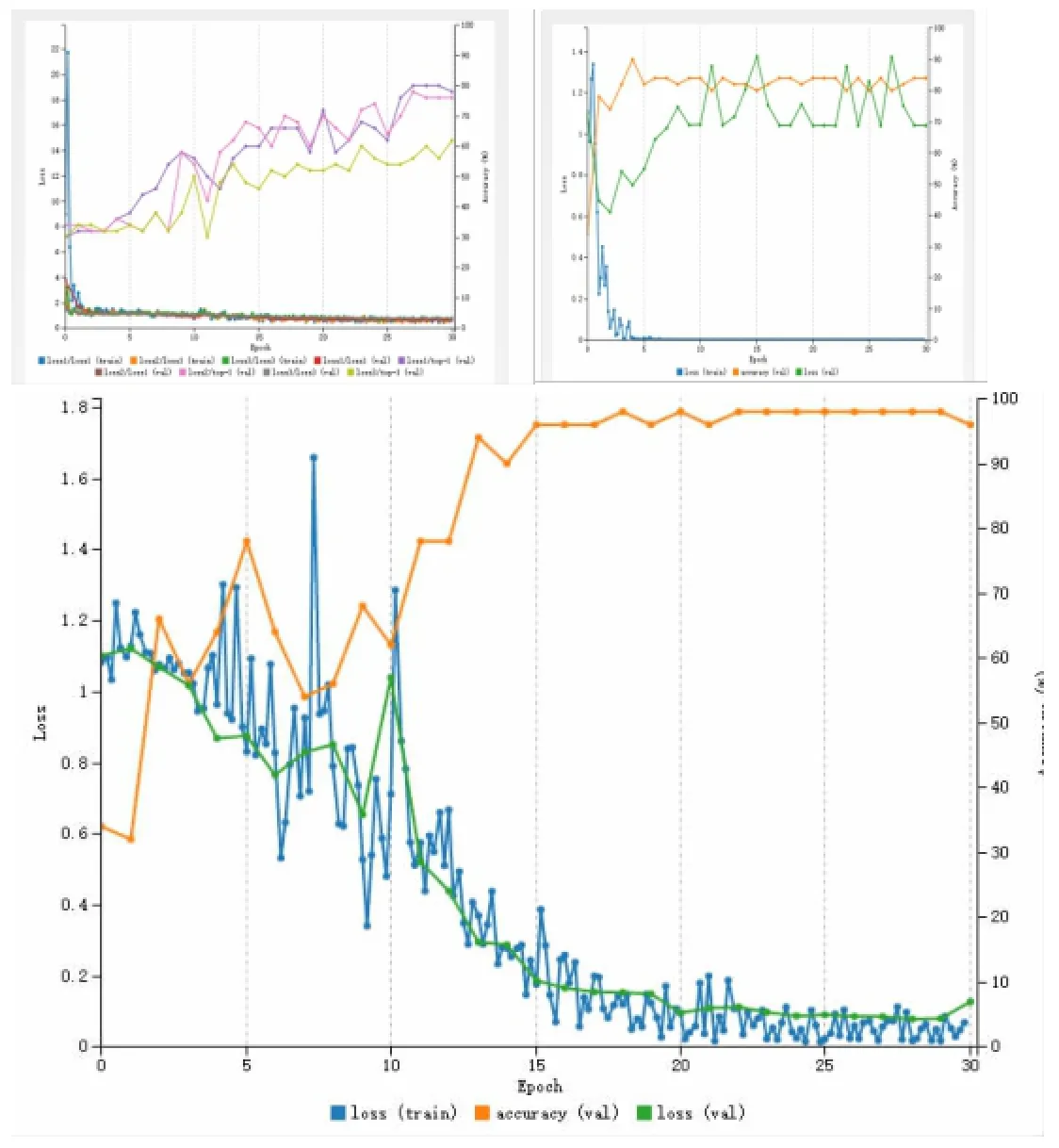
图2 Leaves数据集在三个网络模型上识别效果对比
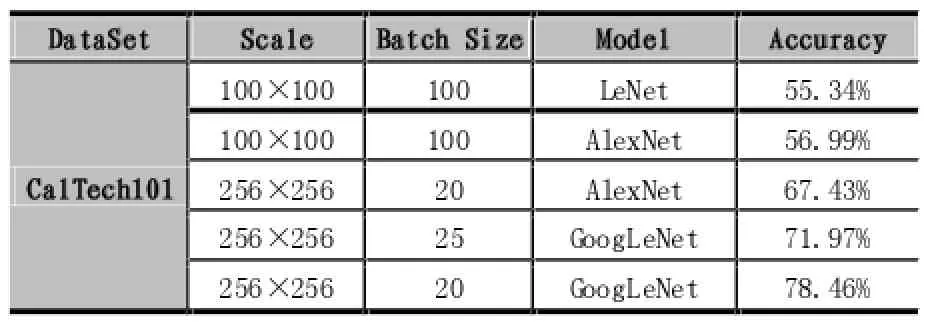
表2 CalTech分类实验结果
CalTech101在识别难度上具有很高的区分,首先,CalTech101下面有101个目录种类,并且种类之间的相关性并不强,这就对网络模型能够学习多个相关度不高的种类有很高要求。另外,每个子分类下面的训练图片尺寸和方向都不一致,图片背景多变,待识别物体的所处位置也很灵活,不集中于图片中心,这就加大了网络抽取图片特征的难度,通过实验分析也发现,原因主要在于处理背景单一。如图3所示,轮廓特征比较明显的字母识别上效率很高的LeNet对于CalTech101的识别效果并不明显,识别准确度 Accuracy只有55.34%,同时存在过拟合的状况。同样的,AlexNet表现也与LeNet近似,在调整batch size之后虽然AlexNet效果有改善,但是准确度仍然较低。但是,采用网络结构比较复杂的GoogleNet进行分类后,所得到的准确度有了比较明显的提升。通过实验结果可以看出GoogleNet对于特征复杂的CalTech101分类效果要好的多,相比LeNet准确率提高了近20%。
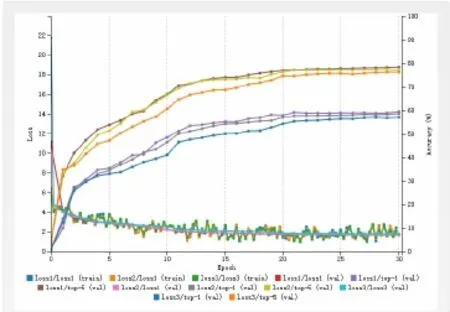
图3 CalTech数据集在GoogleNet网络模型上识别效果
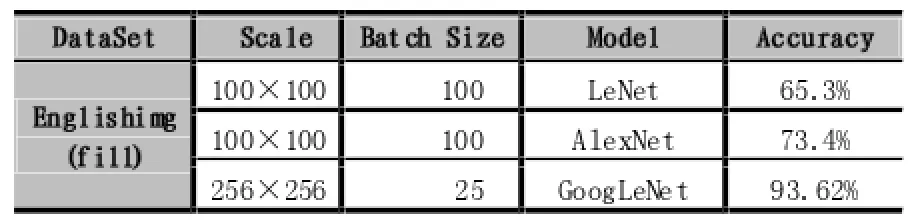
表3 Julia分类实验结果
Julia的EnglishImg数据集中,图片主要是针对单个的字母数字的,且没有经过统一的图片大小规范化,并且考虑到原始图片长宽比相差略大的情况,所以,在输入之前,对图片集统一进行了左右两侧填充噪声(fill)的处理,便于图片平衡长宽比,在输入网络时对图片矩阵处理过程中利于特征计算。如图4所示,LeNet 和AlexNet执行效果与GoogleNet相比较仍然差距比较大,GoogleNet通过实验在batch size为25的情况下,能够达到准确率93.62%的效果。
如图5所示,Mnist中的图片均是统一大小的8位灰度图像,分别用LeNet-5和AlexNet进行了实验,准确率都在99%左右。由于Mnist图片集中的图片特征与其他图片集相比起来较简单,需要的卷积提取过程不复杂;另一方面LeNet-5是针对于手写数字集设计的识别分类设计的网络,所以能够很好地提取图片特征达到较好的分类效果。
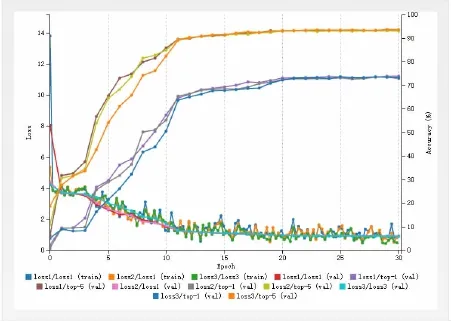
图4 Julia数据集在GoogleNet网络模型上识别效果
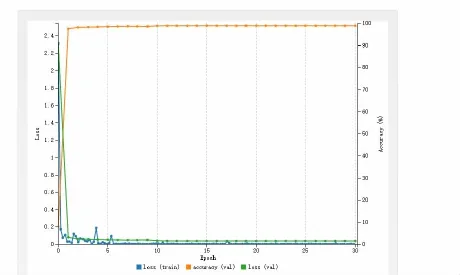
图5 MNIST数据集在LeNet网络模型上识别效果
3 结语
卷积神经网络是目前进行图像模式识别研究最有效的手段之一,随着近年来大数据概念的提出,以及硬件计算能力的不断增长,卷积神经网络的应用范围更加广泛,模型本身的强大特征识别能力也得到充分体现,而卷积神经网络的模型也更加复杂,卷积层数也不断叠加,以此来进行更复杂的图像特征抽取,完成更困难的分类任务。本文针对不同数据集,利用卷积神经网络进行图像分类实验的设计。实验结果显示了不同网络在不同数据集上分类性能的差异,以及实验参数的调整在提高分类正确率上的作用,对具体图像分类的研究及实验提供了理论与实践方面的参考。
[1]Ciresan,D.C.,Meier,J.,and Schmidhuber,J.Multicolumn.Deep Neural Networks for Image Classification[N].CVPR,2012.
[2]Y.LeCun,L.Bottou,Y.Bengio,P.Haffner.Gradient-based Learning Applied to Document Recognition[N].Proceedings of the IEEE, November,1998.
[3]Alex Krizhevsky Ilya Sutskever Geoffrey E.Hinton.ImageNet Classification with Deep Convolutional Neural Networks[N],2012.
[4]V.Nair,G.E.Hinton.Rectified Linear Units Improve Restricted Boltzmann Machines[N].In Proc.27th International Conference on Machine Learning,2010.
Deep Neural Network;Image Recognition;Convolutional Neural Network
Research on Image Classification Based on Convolutional Neural Networks
YANG Ying,ZHANG Hai-xian
(College of Software Engineering,Sichuan University,Chengdu 610065)
国家自然科学基金资助项目(61303015)、四川省科技计划项目(No.2014GZ0005-5)
1007-1423(2016)05-0067-05
10.3969/j.issn.1007-1423.2016.05.015
杨莹(1993-),女,云南大理人,本科,研究方向为机器智能
张海仙(1980-),女,河南邓州人,博士,副教授,研究方向为机器智能
2015-12-22
2016-01-15
利用卷积神经网络进行实验的分析设计,实现一类图像数据的分类研究。实验过程选取参考性较高的几个开源数据集,分别应用到具体的网络模型中进行识别和准确性对比,针对得到的实验结果,进行分析和改进,并给出具体的改进说明。
深度神经网络;图像模式识别;卷积神经网络
Focuses on image classification of certain datasets by using a convolutional neural network,analyzes the mathematical model on how to design the experiments,chooses several open source datasets,gives the experimental results and an accuracy comparison between models followed with some analysis.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
