
基于外观和深度信息的视觉跟踪算法研究
2016-09-21 06:19刘学戚文静
山东建筑大学学报 2016年2期
刘学 ,戚文静
(1.山东电子职业技术学院 计算机科学系, 山东 济南 250200;2.泰华智慧产业集团股份有限公司博士后工作站,山东 济南 250101;3.山东建筑大学 计算机学院,山东 济南 250101)
基于外观和深度信息的视觉跟踪算法研究
刘学1,戚文静2,3
(1.山东电子职业技术学院 计算机科学系, 山东 济南 250200;2.泰华智慧产业集团股份有限公司博士后工作站,山东 济南 250101;3.山东建筑大学 计算机学院,山东 济南 250101)
能够实现视觉导航的自主移动机器人具有很好的应用前景,而场景变化、目标运动、障碍、遮档等是自主机器人视觉导航过程经常遇到的问题,结合外观特征和深度信息的目标检测和跟踪算法是提高自主机器人对目标及环境变化适应能力的重要途径。文章结合人类在跟踪和定位目标时既利用颜色、亮度、形状、纹理等外观特征,又利用物体间距离、深度信息的特点,提出了结合外观特征和深度信息的目标跟踪算法并通过实验验证了该算法对视角、运动、遮挡等因素所引起变化的适应能力,且利用定量的方法对算法的性能进行了评价。
视觉导航;目标跟踪;外观特征;深度信息
0 引言
能够实现视觉导航的自主移动机器人具有很好的应用前景,尤其是在危险工作及战争环境中具有非同寻常的意义。机器人导航大体上可分成两类,一类是需要预先了解整个环境的基于地图的导航,另一类是无地图的边导航边感知环境的模式[1]。视觉导航是典型的无地图导航模式,由于对环境的适应性高而具有广泛的应用价值。视觉导航中最关键的问题是实现对目标的精确跟踪和定位,主要包括三类方法:通过检测进行跟踪的方法[2](如MIL算法)、利用立体或RGB-D摄像机进行跟踪的方法[3]和利用平面视图进行跟踪的方法[4]。通过检测进行跟踪的方法从第一帧中对目标进行一次性学习,然后根据后续的跟踪结果在线更新目标特征,来适应目标的外观变化[2]。研究者针对MIL的不足,给出了改进方案[5-7]。其中,WMIL算法在强分类器更新时使用的弱分类器选择标准进行了一阶泰勒展开,减小了计算量;同时为正样本赋予一个权重,在一定程度上提高了学习的准确性[6]。彭爽等在更新强分类器时采用了一种精简的选择策略,从而提高了算法的效率[7]。Gu提出的跟踪框架通过结合特征袋NN分类、有效子窗口搜索和新特征选择及裁剪等方法,在跟踪外观变化大的目标时获得稳定性和可塑性[8-9]。上述方法主要依赖于物体的外观特征,适用于没有突然产生显著外观变化的情况。
近期研究文献显示利用立体或RGB-D摄像机[3,13]能够提高跟踪和检测的健壮性。Ess和David等描述了利用立体视觉为移动机器人或汽车建立动态障碍图的系统,认为利用稀疏三维结构可以有效提高行人的检测和跟踪效果[10-11]。Shotto等提出了一种能够从深度图像中快速准确地预测身体关节3D位置的方法[12]。平面视图(plan-view map)是通过将组成物体的3D点垂直投影到地平面产生的,在早期的研究中多用于人的检测和轨迹估计[3,14]。文章与使用平面视图的方法不同,一方面,使用平面视图方法目标跟踪仅基于平面视图,当物体距离很近或者轨迹交叉时容易出现跟踪错误,而文章将平面视图与RGB图像相结合,通过外观特征纠正可能的位置错误;另一方面,使用平面视图方法以很多的假设为基础,如已知环境、固定摄像机、目标匀速运动、在相继的帧中没有太大的姿态变化和遮挡变化[14]。文章的方法没有此类约束,尤其适用于机器人和移动设备在未知环境中的导航任务。
如上所述,机器人视觉跟踪面临着主要难题包括:(1) 如何理解在运动过程中产生的目标尺度和视角上的变化;(2) 如何适应环境的动态变化、准确避开突然出现在视野中的物体;(3) 如何精确跟踪和定位目标,实现动态规划路径。为解决这些问题,文章结合人类在跟踪和定位目标时既利用颜色、亮度、形状、纹理等外观特征,又利用物体间距离、深度信息的特点,提出结合外观特征和深度信息的目标跟踪方法。机器人的视觉系统是一个Kinect摄像机[2],从Kinect摄像机可以获得场景的RGB图像和深度信息;从RGB图像提取目标的外观特征信息;从深度信息创建反映物体空间分布层次的平面视图[3,14],利用平面视图以及机器人运动参数预测目标可能的位置及尺度;最后,结合外观特征、位置及尺度信息快速和准确地检测和跟踪目标。
1 结合外观和深度信息的视觉跟踪的方法概况
1.1平面视图的构建
从Kinect摄像机得到的深度信息可以恢复机器人所看的物体的3D点云。参照文献[16]的方法构建平面视图方法如下:(1) 找到地平面;(2) 将地平面的点移除;(3) 把剩下的3D点投影到地面上。一个RGB图像和它对应的平面视图如图1所示。可观察到在图1(a)中许多家具是互相遮挡,但在图1(b)所示的平面视图中,它们能够清楚地分开。平面视图提供了物体的层次和位置信息,可以用来提高跟踪的健壮性。

图1 RGB图像和对应的平面视图(a)RGB图像 ;(b)平面视图
物体在RGB图像和平面视图中的对应关系如图2所示。平面视图中的每个十字表示一个检测到的物体,RGB图像上显示了包围物体凸壳,部分物体在平面视图和RGB图像中的对应关系在图中由箭头指出。有了这个对应关系,在RGB图像中搜索目标时,就只需要用预测窗口在对应的凸壳周围的一定范围内进行搜索,提高检测效率和跟踪的健壮性。

图2 平面视图和RGB图像中物体的对应关系图
1.2外观模型及在线更新
文章采用的是基于检测的跟踪方法,使用一次性学习和在线更新机制产生一个累积的外观模型[8]。初始外观模型由第一帧中目标的特征组成,用后续帧中检测到的目标对模型进行更新,这样既保留了初始的特征,又增加了视角、尺度和其它变化产生的新特征。选取的特征描述符为dense-SIFT[15],它在预定义的网格点上对图像特征进行无偏地采样,可以避免关键点SIFT由于解析度、光照问题引起特征丢失的问题。
在第一帧中,手工标注目标物体的矩形围盒,用Λrect表示围盒中采样点的坐标集合,围盒中所有采样点特征的集合作为目标物体特征,构成初始模型O1。围盒外所有采样点的特征构成背景模型B1。用f(x,y)表示采样点(x,y)处的特征。初始的目标和背景外观模型由式(1)和式(2)定义为
O1={f(x,y)|(x,y)∈Λrect}
(1)
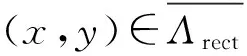
(2)
在后续帧中检测到目标后,按式(3)的定义,用目标围盒中与模型匹配的采样点的特征更新目标模型(匹配函数将在1.4部分描述);按式(4)的定义,用目标围盒外的采样点特征更新背景模型。
O1=Ok-1∪{f(x,y)|(x,y)∈Λk_matched⊂Λk_bdbox}
(3)

(4)
式中:Λk_bdbox为第k帧中目标围盒中的采样点集;Λk_matched为第k帧中与模型Ok-1匹配的采样点集。考虑稳定性与可塑性平衡,目标累积模型只保留第一帧和M个最近邻帧的特征,即,模型k是由来自于1,k-M+1,…,k(k≥M)各帧的特征组成。背景模型仅使用当前帧中的特征,以适应背景的变化。
1.3平面视图上的运动模型
平面视图中的坐标系以机器人的位置为原点,x轴自左向右,y轴自底向上。利用目标的当前位置及摄像机参数来预测下一帧中目标的可能位置及尺度。假设(pxi,pyi)是目标在第i个平面视图中的位置坐标,机器人转过一个α角并向目标移动距离d,则在i+1个平面视图中的位置可由式(5)表示为
(5)

图3 在平面视图中进行目标位置预测图(a)目标预测位置和实际位置; (b)出现目标的概率
在图3(a)所示的平面视图中,红十字代表检测到物体的位置,蓝星号为目标物体的实际位置,绿圆点表示预测的目标位置。从图中可看到由于运动参数测量不准确造成预测位置与实际位置有一定偏差。若目标邻近处有其它物体时,可能会产生错误的预测。另外,若机器人跟踪的是移动的目标,目标会产生一个主动的预测偏差。为了解决这个问题,提出自适应的位置预测方法,即平面视图某一位置(px,py)出现目标的概率可用式(6)表示为
(6)
式中:(pxd,pyd)为预测的目标位置;σ为可调参数,用于适应具体的运动情况,如果目标运动快,则σ可设为较大的值,反之,σ设为较小的值。在实验中我们采用了各向异性高分布来适应物体不同方向的运动。图3(b)显示平面图中每一位置出现目标的概率分布,红十字处坐标为(pxd,pyd)。
预测出物体的位置后,还可以根据小孔成像的原理来预测目标的大小。Hk和Hk+1分别表示第k和第k+1帧中目标的大小,Dk和Dk+1表示第k和第k+1帧中摄像机和目标间的距离,则有第k+1帧中目标的大小可用式(7)进行估计为
(7)
在RGB图像中检测目标时,直接使用估算的目标尺度作为搜索子窗口大小。
1.4目标检测
首先,在第k+1帧中,确定每个采样点特征属于背景还是属于目标。在背景模型和目标模型中分别找出该采样点的N个最近邻特征,用Lb、Lo表示采样点与背景模型Bk和目标模型Ok的N最近邻的平均距离。对于每一采样点(xi,yi)用式(8)进行评分为
(8)
式中:threshold为衡量背景特征和目标特征差异的统计参数。Lo/Lb≤threshold表示与目标模型匹配,赋为正值a。对于与目标不匹配的点,赋惩罚值-a/c,a>0,c>0。
然后,对于所有可能包括目标的子窗口wj∈W,外观分数用式(9)定义为
(9)
最后,将子窗口wj的外观分数与位置因子相乘,最终检测目标为乘积最大的子窗口wi,用式(10)确定为
wt=warg maxj(Swj×F(pxj,pyj,pxd,pyd))
(10)
2 实验验证及算法性能评价
2.1实验验证
通过结合来自RGB图像的外观特征和来自平面视图的位置和尺度信息,机器人在目标跟踪方面显示了很高的健壮性。在文章提供的实验结果中,机器人进行了17次导航试验,跟踪8个不同的目标,包括3个椅子、1个垃圾箱、2个桌子和2个箱子;经验参数a=2,c=100及threshold=1.5。在图6~8显示的跟踪结果中,红色围盒为文章的检测结果;青色、黄色和蓝色围盒依次为是MIL[2]、WMIL[7]、nntracker[8]的跟踪结果。
2.1.1适应外观变化的能力
图4显示了一种非常苛刻的情形,在机器人行走的过程中,不断地改变目标物体的角度,并一直向前移动目标,实验结果显示文章方法对于跟踪外观变化及运动的目标具有较高的健壮性。

图4 跟踪外观变化的目标图
2.1.2适应遮挡的能力
如图5所示,在第一帧中有意遮挡了目标的一部分。由于第一次学习的目标外观模型中包括了一些噪声特征,使得仅依赖于外观的跟踪方法面临较大的困难,由图可以看出nntracker在第三帧、第四帧中一度完全偏离了目标。在第五帧中移动白色椅子再次遮住目标的一部分。在此过程中,尽管使用了反复的遮挡和移动,但我们使用的位置信息有效地纠正了外观噪声的干扰,对目标的跟踪非常稳定和精确。

图5 遮挡情况下的跟踪图
2.1.3抵抗错误的能力
文章方法的另一个优势是它具有很高的抵抗错误的能力,而仅依赖外观进行目标检测的方法有错误积累和放大的趋势。以nntracker[8]为例,在图6的第二个图像中,发生了检测错误,青色围盒偏离了目标,在更新目标外观模型更新时,就会有一些不属于实际目标的“脏特征”被更新到目标模型中,在下一次会产生更大的错误,如此反复,使检测的结果完全偏离目标。而文章的方法由于加入位置和尺度的约束,能保持正确的检测结果。

图6 抵抗错误的能力图
2.2算法性能评价
文章使用了二种方法来评价跟踪的效果,并将文章中方法与MIL[2]、WMIL[7]和nntracker[8]的跟踪结果。进行了比较。
第一种方法是评价跟踪效果常用的平均距离误差方法[9],由式(11)表示为
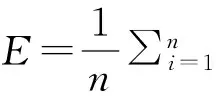
(11)
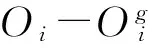
文章方法是一种基于目标检测的方法,目标检测的正确性直接影响跟踪的效果,目标检测的精确度由式(12)表示为
(12)
式中:A(·)为一个区域的面积;Rgt为实际目标所在的区域;Rdet为检测到的目标区域。
在所有17次试验检测中,平均精确度(AP)和平均距离误差(AE)如表1所示。
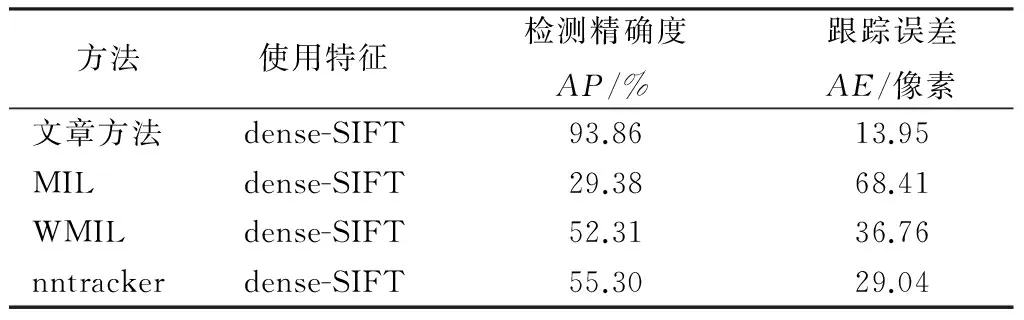
表1 目标检测和跟踪性能评价
3 结语
文章研究在机器人视觉导航中结合外观特征和深度信息实现目标跟踪。机器人每走一步前都要重新感知环境、跟踪定位目标和规划路径,以适应动态变化的环境。由于拍摄图像不连续、机器人的运动、目标的移动等因素,引起视角、尺度和遮挡方面出现不可预测的变化,使目标跟踪任务比通常的视频跟踪任务更加困难。文章利用Kinect摄像机作为机器人的视觉系统,通过深度信息获得反映物体空间分布的层次的平面视图,利用平面视图及摄像机运动参数推断目标的位置,将位置信息与RGB图像中提取的外观特征相结合,取得很好的跟踪效果。另外,通过平面视图还可以确定RGB图像中包围物体的凸壳和目标的尺度信息,结合这两个信息可以有效地减小搜索目标空间,提高检测速度,对于实时的机器人导航具有现实意义的。
[1]Francisco B., Alberto O. ,Gabriel O..Visual navigation for mobile robots: A survey[J].Journal of Intelligent and Robotic Systems, 2008, 53(3):263-296.
[2]Babenko M., Yang H., Belongie S.. Robust object tracking with online multiple instance learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011,33(8):1619-1632.
[3]Peter H., Michael K., Evan H.,etal.. Dieter RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments[J]. The International Journal of Robotics Research,2012, 31(5):647-663,
[4]Rafael M.,Yeguas B. L. ,Díaz M.,etal.. Shape from pairwise silhouettes for plan-view map generation[J]. Image and Vision Computing, 2012, 30(2) :122-133.
[5]尚晓清,宋宜美.一种基于扩散映射的非线性降维算法[J]. 西安电子科技大学学报,2010,37(1):130-135.
[6]夏鲁瑞,胡茑庆,秦国军.基于流形学习的涡轮泵海量数据异常识别算法[J]. 航空动力海报,2011,26(3):689-703.
[7]彭爽,彭晓明. 基于高效多示例学习的目标跟踪[J].计算机应用,2015,35(2):466-469,475.
[8]Gu.S., Zheng. Y., Tomasi C.. Efficient Visual Object Tracking with Online Nearest Neighbor Classifier[C].Proceedings of the 10 the Asia conference on compuler vision,Durham:Doke University,2011.
[9]Lampert H., Blaschko B., Hofmann T.. Efficient subwindow search: A branch and bound framework for object localization [J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12):2129-2142.
[10]Ess A., Leibe B. Gool L.. Depth and Appearance for Mobile Scene Analysis[J].Communication in Complater & Information Science,2012,7:110-118.
[11]David, G.,Antonio L.,Angel D.etal. Survey of pedestrian detection for advanced driver assistance systems[J]. Pattern Analysis & Machine Intelligence, 2010,32(7):1239-1258.
[12]Shotton J., Fitzgibbon A.. Real-time Human Pose Recognition in Parts From Single Depth Images[J].Aisa Journal, 2011, 92:1297-1304.
[13]基于RGB-D的在线多示例学习目标跟踪算法[J]. 计算机工程与设计, 2015(7):1865-1870.
[14]Bonin F., Ortiz A., Oliver G.. People detection and tracking using stereo vision and color[J].Image and Vision Computing, 2007, 25(6):995-1007.
[15]Liu C., Yuen J., Torralba A.,etal.. SIFT Flow: Dense Correspondence Across Different Scenes [C].European Conference on Computer Vision, London: The Thomson Corporation,2008.
[16]Burschka D., Hager G.. Stereo-Based Obstacle Avoidance in Indoor Environments with Active Sensor Re-Calibration[J]. Autonoraovs Robots,2002,2:2066-2072.
(学科责编:李雪蕾)
Visual tracking algorithm based on appearance feature and depth information
Liu Xue1, Qi Wenjing2,3
(1.Department of Computer Science, Shandong College of Electronic Technology, Jinan 250200, China; 2. Shandong Taihua Telecommunication Co.,,Ltd, Jinan 250101,China; 3. School of Computer Science, Shandong Jianzhu University, Jinan 250101, China)
Challenges that robot faces in vision-based navigation include scene change, appearance change, obstacle, occlusion etc. Imitating human vision perception, an object detection and tracking algorithm that combines appearance feature and depth information is proposed. First, RGB image and depth information are captured by the Kinect camera that works as the vision system of robot. Then, an appearance model is created with features extracted from RGB image. A motion model is created on plan-view map produced from depth information and camera parameters, and the estimation of object position and scale is performed on the motion model. Finally, appearance features are combined with position and scale information to track the target. Experimental result show the robustness of our object detection and tracking method to appearance changes arose from view, motion and occlusion factors. It also shows that the object detection efficiency and object tracking accuracy are improved greatly compared with the method that only employ the appearance features.
vision-based navigation; object tracking; appearance feature; depth information
2015-11-24
山东省自然科学基金(ZR2013FL024);山东建筑大学博士科研基金(XNBS1261)
刘学(1971-),男, 副教授,硕士,主要从事软件工程,图像处理等方面的研究.E-mail:liuxe@sdcet.cn
1673-7644(2016)02-0177-06
TP391.4
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
阅读(快乐英语高年级)(2022年6期)2022-06-17
家庭影院技术(2021年10期)2021-11-20
中学生数理化·高一版(2020年1期)2020-02-20
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
紫禁城(2017年6期)2017-08-07
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
