
大数据系统开发中的构件自动选型与参数配置*
2016-09-20 09:00邱明明黄向东
计算机与生活 2016年9期
钟 雨,邱明明,黄向东
清华大学 软件学院,北京 100084
大数据系统开发中的构件自动选型与参数配置*
钟雨+,邱明明,黄向东
清华大学 软件学院,北京 100084
大数据应用系统包含数据的采集、存储、分析、挖掘、可视化等多个技术环节,各个环节都存在多种解决方案,涉及到的各类系统有数百种之多,且系统配置较为复杂,这给企业的大数据应用系统构建带来了极大的挑战。针对大数据应用系统开发中构件选型的难题,通过建立规范化的需求指标,并采用决策树模型实现了大数据构件的自动选型。从几个主流的分布式存储系统出发,以Cassandra为例,利用多元回归拟合的方法针对硬件参数建立相应的性能模型,将用户需求作为输入,利用性能模型进行系统硬件参数配置;通过研究系统原理、架构、特点及应用场景,构建软件参数配置知识库指导软件参数的配置,从而解决了大数据系统开发中的构件自动选型和参数配置问题。
大数据系统;构件选型;决策树模型;参数配置;性能模型
1 引言
随着互联网的高速发展和社会信息化步伐的加快,各行业的数据迅猛发展,人类已经步入大数据时代[1]。美国互联网数据中心指出,互联网上的数据每年将增长50%,每两年便将翻一番[2];IBM的研究称,“整个人类文明所获得的全部数据中,有90%是过去两年内产生的。而到了2020年,全世界所产生的数据规模将达到今天的44倍”。大数据最显著的特点是“4V”特征[3]:更大的规模、更高的多样性、更快的速度和更低的价值密度。大数据给人们描绘了一个美好的场景:基于对大数据的处理和分析,人们可以从中挖掘出有价值的信息,进而有效和高效地解决或者缓解本领域面临的问题。然而,大数据带来的不仅是机遇,还有一系列的困难和挑战。大数据的复杂性、动态性、弱关联和价值稀缺,导致目前尚未形成系统化的有效的大数据技术,以满足不同领域对大数据处理的需求。
针对不同的应用需求,如何选择和组合合适的大数据系统往往使用户困惑。目前市场上各类大数据系统呈现了百花齐放的态势,例如存储键值对的大数据系统Hbase、Cassandra、Redis、Memcached,存储文档数据的大数据系统MongoDB、CouchDB,面向图数据的大数据系统Neo4J、OrientDB,面向批处理的大数据系统Hadoop、Hive、Greenplum,面向交互式处理的大数据系统Dremel、Drill、Impala,面向实时处理的大数据系统Strom、S4、Puma等。这些功能相似的系统构件导致了在大数据应用系统开发选型时的困难。而不同应用又有不同的侧重点:首先需要考虑大数据应用中数据的分析类型是什么,需要实时处理还是批处理,这直接影响了是使用类似Hadoop MapReduce生态圈的大数据系统,还是类似Spark生态圈的大数据系统。再有,数据的处理方法是什么,例如预测模型、即席查询、报表生成、机器学习等,这直接决定了选用什么样的大数据工具作为整体解决方案的一部分。此外,数据的产生频率和大小、数据的类型、数据内容的格式、数据源、数据的消费者等都需要考虑。
除去大数据应用开发中构件选型的困难,系统参数配置同样是个棘手的问题。因为现有的大数据系统不仅种类繁多,而且配置较为复杂。首先是硬件参数的配置,对于用户给定的需求,应该配置硬件资源的数目,如服务器个数、CPU、内存、硬盘和网络等。对于用户来说,既要保证大数据系统各方面需求得到满足,又要保证在硬件上的花费尽可能少。此外,以Cassandra[4]为例,除去硬件选项,还有70余项可选的软件配置参数,而且各个参数之间相互影响。可以发现,参数配置对系统性能的影响具有致命的效果。更糟糕的是,在大数据系统中,任何一个配置参数的调整往往不能立即看到效果,而是当数据量达到一定规模的时候,其作用才能凸现出来。
云计算是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。云计算平台可以为用户提供廉价的大数据解决方案,简化了用户开发大数据应用的复杂度。本文研究了基于云计算技术的大数据应用系统开发运行一体化平台。该平台涵盖了大数据应用的全生命周期,简化了用户根据业务需求构建面向特定领域的大数据系统的过程,并且能够自动管理系统运行,为大数据应用系统开发提供软件工程方法、工具与平台。本文论述的内容是一体化平台研究工作中重要的一部分,即系统选型与参数配置。
本文通过调研、归纳与分析主流的大数据应用场景和需求以及包括Cassandra、HDFS、HBase、Map-Reduce、Spark、HIVE、Mahout和MLBase在内的主流大数据系统,建立了大数据构件资源库系统。该系统负责根据用户对大数据存储、计算和分析的需求自动选择合适的大数据存储系统、大数据计算系统、大数据分析系统,并且能够根据性能模型进行系统参数自动配置和优化。资源库中不仅囊括了大量现有的开源大数据系统,更重要的是保存并不断学习这些系统的应用知识,使其能够较为自动地为上层提供大数据系统的选型和参数配置的支持。该系统以OpenStack为支撑,通过OpenStack创建各种类型的Linux虚拟机,同时配置虚拟机的硬件和软件参数,自动启动虚拟机,进而在虚拟机上部署各种大数据构件,调整大数据构件参数,启动或停止大数据构件服务等。该系统根据用户的应用需求进行大数据构件的自动选型和参数配置,并生成集群的各种信息返回给用户。
本文通过建立规范化的需求指标,基于决策树模型实现了大数据构件的自动选型。从几个主流的分布式存储系统出发,以Cassandra为例,通过研究其系统原理、架构与特点,进行实验和测试,建立相应的性能模型。利用性能模型对应用需求进行分析,帮助用户进行系统选型、参数配置与调优,从而解决大数据应用中的选型和参数配置困难的问题。
本文组织结构如下:第2章介绍国内外的相关工作;第3章介绍大数据开发中的构件自动选型;第4章以Cassandra为例介绍大数据系统的参数配置问题;第5章给出基于Cassandra的参数配置实验结果与分析;第6章总结全文。
2 相关工作
2.1系统对比与自动选型
在大数据系统的构件自动选型方面,国内国际的研究几乎是一片空白。不过,很多学者已经对大数据应用中不同的数据库和数据存储系统从功能、特点、性能等方面进行了对比。Cattell对主流的NoSQL系统进行了分析[5],对比了这些系统中数据模型、一致性机制、存储机制,保证持久性、可用性、查询支持以及其他方面的不同点。Skerjanc和Li等人对众多SQL和NoSQL数据库的性能进行了对比,得出了几乎所有的NoSQL数据库在键值对存储的应用场景下都比SQL数据库性能更好的结论[6-7]。Florian 对Voldemort、Redis、Memcached、HBase、Cassandra、SimpleDB、MongoDB等众多NoSQL数据库在扩展性、多节点操作等方面进行了对比分析[8]。根据这些研究,可以知道不同的数据库有各自的优缺点,适用于不同的应用需求。因此,在大数据系统的构件自动选型中,应明确系统需求,确定数据的产生和使用方式,这样大数据系统的选型方案才能正确。
2.2性能模型
Herodotou对Hadoop的性能进行了建模[9],描述了一个MapReduce任务在Map、Reduce的每个流程中的数据流向和性能代价,该模型可以被用作估计MapReduce任务的执行性能以及找到任务运行的最优配置。Rabl等人研究了在一定的读写负载下的几种键值存储系统(HBase、Cassandra、Voldemort、Redis等)的性能,并给出了实验结果[10]。范剑波等人对分布式存储系统的性能进行了研究,建立了服务器性能的数据分布模式,有效地减少了客户请求的平均服务时间[11]。赵铁柱对分布式文件系统进行了性能建模,提出了一种能够预测Lustre和HDFS性能的预测模型,并对HDFS写操作进行了改进,实验结果表明,模型预测的误差在可接受的范围内[12]。陆承涛等人根据I/O负载的运行时特征,借助多元回归分析理论,在线提取系统的性能模型[13]。
2.3参数配置与性能优化
计算机系统性能调优问题因其重要的应用价值而一直为学术界和工业界所关注,目前已取得大量的研究成果,这些工作主要分布于数据库系统、Web服务等领域。长期以来,数据库系统都要求数据库管理员(database administrator,DBA)和应用开发人员做大量的人工调节,使得数据库的性能保持良好。而这些可调参数数目众多,性能原则难以理解,使得参数调整和性能优化工作成本较高。为了降低DBA的工作负担,减少DBMS(database management system)的维护费用,数据库自调优技术成为研究的热点之一。然而,数据库系统因其规模庞大,结构复杂,从而对性能调优的研究难以求全责备,现有的调优方法主要着重于对某个子问题的研究。
Chaudhuri等人设计了一个索引分析实用工具,该程序用来执行系统性能的what-if分析[14]。Debnath等人通过P&B(Placket&Burman)统计方法解决了不同参数对性能影响程度的排序问题[15]。Sulivan等人采用影响图模型,依据模型对BerkeleyDB系统的4个参数进行调整,但随着系统参数个数的增加,该方法的效率将变得较为低下[16]。Duan等人设计了一个数据库配置参数的自动性能调优工具iTuned,实现了调优实验的高效率、调优过程的低开销以及跨平台的可移植性[17]。Oracle11g数据库系统主要采用瓶颈消除和主动监视两种方法来调优性能[18],前者的重点在于消除资源瓶颈,而后者则采用比较方法,周期性地监视系统的运行时数据,并与历史行为数据进行比较,找出性能问题的根源,从而优化系统的性能。
来自澳大利亚墨尔本大学的Buyya教授领导团队开发了CloudSim[19]云计算仿真软件,其是在离散事件模拟包SimJava(http://www.dcs.ed.ac.uk/home/ hase/simjava/)上开发的函数库。该工具允许开发人员在单个物理计算节点上模拟大规模云计算基础设施。通过该平台,可以对参数配置进行建模,测试不同配置下的系统性能,从而得到满足应用需求和服务质量所需的云计算资源,方便用户之后将他们的云计算服务部署到真实的云计算环境中,如亚马逊的EC2和微软的Azure。
3 构件自动选型
此外,一个完整的大数据应用往往需要多个大数据系统的配合,比如使用NoSQL数据库作为分布式存储,使用Spark进行计算分析,使用Storm进行流程分发,使用Scribe收集系统日志等。因此不仅需要提供某一业务模块所匹配的大数据系统软件,还需要进行大数据系统软件栈的选择,使得整个业务流程中多个系统构件形成一个连通的有机整体。
大数据系统软件栈则分为大数据存储系统、大数据计算系统、大数据分析系统3个层次。本文通过总结多种应用场景的实践经验,将大数据应用的需求进行了详细的划分,从需求类型、数据类型、业务流程、性能指标等多个方面提取了17个需求指标,其中与选型相关的有10个,如表1所述。

Table 1 Big data application requirement norm 表1 大数据应用需求指标
本文采用决策树模型实现对大数据构件的自动选型。对于存储、计算、分析3种需求,分别构建决策树。以8种大数据系统为例,3个决策树的输入参数从10个选型需求参数中挑选相关的参数,输出则为选型结果,见表2。
存储层选型决策树的一部分如图1所示。

Table 2 Input and output of three-level decision tree表2 三层决策树的输入和输出

Fig.1 Decision tree图1 决策树示意图
本文采用C5.0算法构建决策树。构建决策树时,如算法1所示,使用一组先验知识,包括不同输入下的选型结果。系统内置了初始的知识,用以构建决策树;系统也支持用户增加新的知识,当用户对某一次的选型结果进行修改时,资源库会收到相应的反馈,一条新的知识将会添加到已有的知识中,并重建决策树,见算法2。因此,通过不断保存和学习新的大数据应用系统,获取其业务流程和应用模式下对应需求的选型数据来训练和优化决策树,以提供更好的构件自动选型方案。
算法1 构建决策树算法

算法2 更新决策树算法

根据用户对大数据存储、计算和分析的需求,自动选择合适的大数据存储系统、大数据计算系统、大数据分析系统。如果用户选择的是存储需求,则输出相应的存储系统,则同时需要存储层构件和计算层构件,应同时输出存储和计算系统的选型;同理,若用户选择的是分析需求,则同时输出存储、计算和分析系统的选型。算法3给出了构件选型流程的伪代码。
算法3 构件选型流程

4 参数配置
在大数据应用系统中,参数配置对系统性能的影响较大。大数据系统的参数包括硬件参数和软件参数。在进行参数配置时,除了要满足系统性能需求,还需要考虑系统资源的限制和经济上的因素。
本文实现了一种新的大数据系统的性能模型,能够进行系统参数自动配置和运行前优化。对每个大数据系统构件,通过网格搜索法分析、测试不同参数配置下大数据系统的性能指标,结合不同参数配置的成本因素、硬件资源,通过多元回归、主成分分析等方法,建立性能指标和系统参数的相关性模型,并能根据该模型计算出用户需求情况下最优的参数配置。
在本文分析的17个需求指标中,与参数配置相关的需求有7个,分别是数据量、数据日增量、读吞吐量、写吞吐量、读延迟、写延迟和最大客户端并发数
4.1硬件参数配置与性能模型
在系统参数配置中,硬件配置是决定大数据系统性能最根本、最主要的因素,受限于用户的基础条件和投资成本。本文以硬件配置为主,同时综合各种因素构建了一种适合参数配置的性能模型。
本文选取了节点数(记为N)、CPU核心数(记为C)、内存大小(记为M)、磁盘大小(记为D)共4个硬件参数。考虑到本平台选用OpenStack作为底层系统,而OpenStack无法配置位于多块物理磁盘上的多个虚拟磁盘,无法配置网络带宽,因此忽略磁盘个数、网络带宽因素。硬件参数的取值范围如表3所示。

Table 3 Range of hardware parameters表3 硬件参数的取值范围
本文以底层的大数据存储系统作为用户需求的基础进行参数初始配置,若存在计算和分析构件,则分析其性能是否满足要求,并调整配置。
在上文提及的参数配置相关的7个需求中,数据量与数据日增量是“容量型”指标,主要与磁盘大小相关,且系统存储的数据量越大,需要的磁盘空间也就更多。而读吞吐量(ReadThroughput)、写吞吐量(WriteThroughput)、读延迟(ReadLatency)、写延迟(WriteLatency)、客户端并发数(Concurrent)5个指标是“性能型”指标,主要由节点数、CPU核心数和内存大小3个因素决定。为得到它们之间的关系,本文对这5个性能指标与这3个硬件参数进行建模,通过使用多元回归的方法建立起5个性能模型,刻画参数配置与系统性能的关系。

式(1)表示读吞吐量的性能模型;式(2)表示写吞吐量的性能模型;式(3)表示读延迟的性能模型;式(4)表示写延迟的性能模型;式(5)表示客户端并发数的性能模型。
根据这些性能模型逆推,即通过求解性能模型方程,可以得到满足给定性能需求的最小参数配置。对于读吞吐量,即在给定的ReadThroughput值下,求解大于或等于该值时的硬件配置,如式(6)所示。写吞吐量与之类似,如式(7)所示。对于读延迟,则是在给定的需求值ReadLatency下,求解小于或等于该值的硬件配置,如式(8)所示。写延迟与读延迟一样,如式(9)所示。对于客户端并发数,则需要求解并发数大于或等于给定需求值的配置,如式(10)所示。

除了要满足性能要求,还需要最经济的解决方案,即价格最小化:

本文参考阿里云和亚马逊AWS等主流的云平台,使用如下的价格计算公式:

性能模型的正确性直接决定了最后结果的正确性,而多元回归的类型直接决定模型效果,本文目前采用的回归方法还有待进一步提升与优化。
4.2Cassandra性能模型实例
本文以Cassandra的写吞吐量性能建模为例,进行详细分析,其余4个性能指标采用类似的方法。在忽略其他次要因素的情况下,考虑一个服务器的内存大小为M(单位GB),CPU核心数为C,设部署在该服务器上的Cassandra写吞吐量(单位B/s)为:

因为Cassandra是一个分布式、P2P架构、高可扩展的数据存储系统,具有良好的水平可扩展性。根据水平可扩展性,具有N个机器的Cassandra集群的写吞吐量为:

对于 f(C,M),考虑到内存和CPU之间会互相影响,因此C和M存在相关性。对 f(C,M)进行线性估计,设:
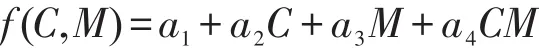
对 f(N)进行二次估计,设:

在第5章中,设计实验测试在不同的C、M、N 下Tw的值,进而通过回归的方法求出待定系数a1、a2、a3、a4、b1、b2、b3。若发现实验结果与分析得到的模型不符合,则需要对模型进行修正。
4.3软件参数配置
系统软件参数配置是指大数据系统运行时的参数配置,通常通过系统的配置文件进行修改。系统软件参数配置需要丰富的大数据系统专家知识,因此本文采用构建专家库的方法来构建软件参数配置知识库。下面以Cassandra的参数commitlog_sync为例进行分析与说明。
Cassandra是基于LSM(log-structure merge)树模型来进行内存数据的持久化管理,其最突出的特征是预写式日志(write-ahead log,WAL,在Cassandra被称为CommitLog即数据写到内存后,必须写到CommitLog中,才能够返回客户端写操作成功,但不需要马上写到数据文件中。这种模型使得其写吞吐量较关系数据库大大提升。写CommitLog时,采用了文件缓冲区机制,先将数据写到CommitLog内存缓冲区中,在合适的时机同步到硬盘上。Cassandra提供了两种同步机制,batch(批量)和periodic(周期)。两者都会每隔一段时间同步CommitLog到磁盘,但不同的是,Batch模式在完成同步之前,所有的写操作任务暂时不返回,直到一个batch的CommitLog全部刷到磁盘上时,再统一返回;而periodic模式则会在CommitLog写到缓冲区之后立即返回客户端,期间有可能CommitLog并没有完全写到磁盘上,如果系统发生故障,可能会丢失数据。
从上面的机制可以看出,periodic模式的吞吐量更高,但一致性较差,可能发生数据丢失的情况;相反,batch模式吞吐量相比略低,但会保证数据的持久化。因此,设置如下参数配置规则:
当数据一致性为强一致性时,设置commitlog_sync=batch,优先级为5,即必须满足;
当数据一致性为最终一致性,设置commitlog_sync=periodic,优先级为4。
相似地,本文总结了大约100条参数配置规则,每条规则有不同的优先级(1~5),若两条规则相互冲突,以优先级高者为准。以Cassandra为例,表4是一部分参数配置规则。依据参数配置规则知识库,就可以根据用户需求和硬件参数计算最优配置。

Table 4 Part of parameter configuration rules表4 部分参数配置规则
5 实验和分析
本文使用的实验环境为3台服务器组成的Open-Stack虚拟机环境。每台服务器的硬件配置为Intel Xeon E5-2609 CPU、64 GB内存、512 MB缓存的RAID5卡,服务器之间通过千兆以太网连接,并通过NTP(network time protocol)同步了系统时间。虚拟机安装的操作系统为Red Hat Enterprise Server 6.1。本文使用Cassandra作为参数配置实验的对象。客户端使用Yahoo的基准测试平台YCSB(https://github. com/brianfrankcooper/YCSB)模拟高并行的读写访问。客户端的硬件配置以及操作系统和服务器节点相同,均位于OpenStack平台上。
实验中,通过不断提高客户端线程数目,测试最高能达到的性能。测试采用每行10列,每列平均10个字符的数据。多节点环境下,采用单副本策略以测试其能够扩展的最大性能。在此基础上,考虑多副本对性能的影响。
针对上述5个性能指标,分别对3个参数共约60组不同组合进行实验。
本文以Cassandra的写吞吐量性能为例,如图2所示,横坐标为节点个数,纵坐标为吞吐量,一共3组结果,分别是1c2g(1核心CPU,2 GB内存,下同)、2c4g、4c8g。实验结果表明,当固定CPU核心数和内存大小两个配置,其写吞吐量随着节点个数的增加而增加。

Fig.2 Cassandra write throughput result when fixing CPU core number and memory size图2 固定CPU核心数和内存大小的Cassandra写吞吐量实验结果
图3为固定节点数为1的Cassandra写吞吐量实验结果。当固定节点数为1时,吞吐量随着分配核心数和内存的增加而增加。

Fig.3 Cassandra write throughput result when setting node number to 1图3 固定节点数为1的Cassandra写吞吐量实验结果
从实验结果可以看出,Cassandra的写吞吐量具有水平可扩展的特性,写吞吐量随节点数线性增加,证明了Tw(N,C,M)=f(C,M)×f(N)的正确性。而当固定节点数和CPU数目时,写吞吐量并不与内存大小M线性相关而是与其对数lbM线性相关,因此对模型进行修正:
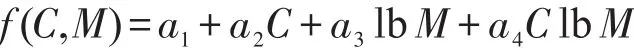

从而


根据所有的测试数据,对上面的关系式进行多元回归求解求出待定系数a1、a2、a3、a4、b1、b2、b3。得出如下的性能模型公式:
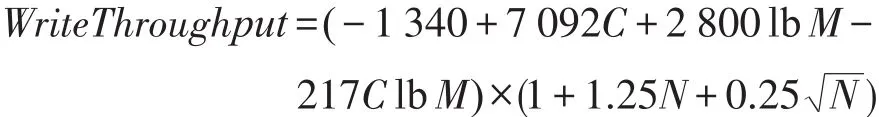
其中,N为服务器节点个数;C为CPU核心数;M为内存大小。
对回归得到的模型的预测值和真实值进行对比,评估其误差。表5是Cassandra写吞吐量实验的部分结果,Tw是实验值,T′w是模型的估计值。

Table 5 Part of Cassandra write throughput results表5 部分Cassandra写吞吐量结果
模型预测的平均误差为2%,说明该模型能够准确地表示Cassandra写吞吐量随节点数、CPU核心数和内存的变化情况,保证了硬件参数配置的正确性和可靠性。
6 结束语
本文针对大数据应用系统开发中构件选型的难题,通过建立规范化的需求指标,基于决策树模型、计算、分析3种需求,分别构建决策树,实现了大数据构件的自动选型。本文从几个主流的分布式存储系统出发,以Cassandra为例进行实验和测试,利用多元回归拟合的方法针对硬件参数建立相应的性能模型,将用户需求作为输入,利用性能模型进行系统硬件参数配置;通过研究其系统原理、架构、特点及应用场景,构建软件参数配置知识库指导软件参数的配置,从而解决了大数据应用中的选型、部署和参数配置困难的问题。
在今后的研究中,重点对更多的大数据系统进行实验和分析,进一步完善本平台的大数据构件。此外,还需要对求解性能模型的回归方法进行改进和优化,以期得到更好的性能模型。
References:
[1]Mayer-Schönberger V,Cukier K.Big data[M].Hangzhou: Zhejiang PeopleƳs Publishing House,2013.
[2]Gantz J,Reinsel D.The digital universe in 2020:big data, bigger digital shadows,and biggest growth in the far east [EB/OL].(2012)[2015-07-18].http://www.emc.com/leadership/digital-universe/2012iview/index.htm.
[3]Barwick H.The“four Vs”of big data:implementing information infrastructure symposium[EB/OL].(2011-08-05)[2015-07-18].http://www.computerworld.com.au/article/396198/iiis_ four_vs_big_data/.
[4]Lakshman A,Malik P.Cassandra:a decentralized structured storage system[J].ACM SIGOPS Operating Systems Review,2010,44(2):35-40.
[5]Cattell R.Scalable SQL and NoSQL data stores[J].ACM SIGMOD Record,2011,39(4):12-27.
[6]Škerjanc N.Performance comparison between NoSQL and relational database[D].Univerza v Ljubljani,2012.
[7]Li Yishan,Manoharan S.A performance comparison of SQL and NoSQL databases[C]//Proceedings of the 2013 IEEE Pacific Rim Conference on Communications,Computers and Signal Processing,Victoria,Canada,Aug 27-29,2013. Piscataway,USA:IEEE,2013:15-19.
[8]Eckerstorfer F.Performance of NoSQL databases[EB/OL].(2011-11-19)[2015-07-18].http://storage.braincrafted.com/ Eckerstorfer2011NoSQLPerformance.pdf.
[9]Herodotou H.Hadoop performance models,CS-2011-05[R]. Computer Science Department,Duke University.
[10]Rabl T,Gómez-Villamor S,Sadoghi M,et al.Solving big data challenges for enterprise application performance management[J].Proceedings of the VLDB Endowment,2012,5 (12):1724-1735.
[11]Fan Jianbo,Guo Jiankang.Establishment and application of performance model on distributed storage system[J].Computer Engineering andApplications,2001,37(13):89-91.
[12]Zhao Tiezhu.Research on performance modeling and application of distributed file system[D].Guangzhou:South China University of Technology,2011.
[13]Lu Chengtao,Feng Dan,Wang Fang,et al.Profile-based model extraction of storage systems and model applications[J]. Journal of Chinese Computer Systems,2010,31(12):2467-2471.
[14]Chaudhuri S,Narasayya V.AutoAdmin“what-if”index analysis utility[J].ACM SIGMOD Record,1998,27(2): 367-378.
[15]Debnath B K,Lilja D J,Mokbel M F.SARD:a statistical approach for ranking database tuning parameters[C]//Proceedings of the 24th IEEE International Conference on Data Engineering Workshop,Cancun,Mexico,Apr 7-12,2008. Piscataway,USA:IEEE,2008:11-18.
[16]Sulivan D G,Seltzer M I,Pfefer A.Using probabilistic reasoning to automate software tuning[C]//Proceedings of the 2004 Joint International Conference on Measurement and Modeling of Computer Systems,New York,USA,Jun 12-16,2004.New York,USA:ACM,2004:404-405.
[17]Duan Songyun,Thummala V,Babu S.Tuning database configuration parameters with iTuned[J].Proceedings of the VLDB Endowment,2009,2(1):1246-1257.
[18]Oracle Corporation.Oracle database 11g release 2 performance tuning tips&techniques[Z].2012.
[19]Calheiros R N,Ranjan R,Beloglazov A,et al.CloudSim:a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms[J].Software Practice and Experience,2011,41(1): 23-50.
附中文参考文献:
[1]迈尔-舍恩伯格,库克耶.大数据时代[M].盛杨燕,周涛, 译.杭州:浙江人民出版社,2013.
[11]范剑波,郭建康.分布式存储系统性能模型的建立与应用[J].计算机工程与应用,2001,37(13):89-91.
[12]赵铁柱.分布式文件系统性能建模及应用研究[D].广州:华南理工大学,2011.
[13]陆承涛,冯丹,王芳,等.一种存储系统性能模型的提取方法及模型应用[J].小型微型计算机系统,2010,31(12): 2467-2471.

ZHONG Yu was born in 1991.He is an M.S.candidate at School of Software,Tsinghua University.His research interests include big data systems and NoSQL systems,etc.
钟雨(1991—),男,山东高密人,清华大学软件学院硕士研究生,主要研究领域为大数据系统,NoSQL系统等。

QIU Mingming was born in 1993.He is an M.S.candidate at School of Software,Tsinghua University.His research interests include big data systems and machine learning,etc.
邱明明(1993—),男,江西九江人,清华大学软件学院硕士研究生,主要研究领域为大数据系统,机器学习等。

HUANG Xiangdong was born in 1989.He is a Ph.D.candidate at School of Software,Tsinghua University.His research interests include cloud data management,unstructured data management and distributed database system,etc.
黄向东(1989—),男,河南郑州人,清华大学软件学院博士研究生,主要研究领域为云数据管理,非结构化数据管理,分布式数据库系统等。
Automatic Component Selection and Parameter Configuration in Development of Big Data Systemƽ
ZHONG Yu+,QIU Mingming,HUANG Xiangdong
School of Software,Tsinghua University,Beijing 100084,China
+Corresponding author:E-mail:zhongyu8@gmail.com
ZHONG Yu,QIU Mingming,HUANG Xiangdong.Automatic component selection and parameter configuration in development of big data system.Journal of Frontiers of Computer Science and Technology,2016,10 (9):1211-1220.
Big data applications include data collection,storage,analysis,mining,visualization,and other technical aspects.Every aspect has a variety of solutions,involves several hundred application systems and the system configuration is complicated,which has brought great challenges for a company to construct big data applications.To solve the problem of component selection in the development of application system,this paper establishes standardized requirement norms and achieves automatic component selection by using the components selection decision tree.This paper embarks from the several mainstream distributed storage systems,takes Cassandra as an example,conducts experiments and uses multiple regression method to calculate the performance model for hardware parameters.Then,this paper uses the performance model to help user configure hardware parameters under the input of user’s requirements. Finally,this paper studies the system’s principle,structure and characteristics and constructs a knowledge base of software parameters configuration to help configure software parameters.In these ways the problem of component selection and parameter configuration in the development of big data system can be solved.
2015-09,Accepted 2015-12.
big data system;component selection;decision tree model;parameter configuration;performance model
*The Big Data Science and Technology Special Fund of the Tsinghua National Laboratory of Information Science and Technology(清华大学信息科学与技术国家实验室大数据科学与技术专项).
CNKI网络优先出版:2015-12-15,http://www.cnki.net/kcms/detail/11.5602.TP.20151215.1037.002.html
A
TP391
猜你喜欢
一重技术(2021年5期)2022-01-18
建材发展导向(2021年18期)2021-11-05
建材发展导向(2021年15期)2021-11-05
网络安全和信息化(2020年3期)2020-04-20
电子技术与软件工程(2018年8期)2018-12-25
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
软件(2016年5期)2016-08-30
科技与创新(2015年13期)2015-07-03
