
基于多尺度卷积神经网络的场景标记
2016-09-20 02:47:22尹蕊北京交通大学计算机与信息技术学院北京100044
现代计算机 2016年6期
尹蕊(北京交通大学计算机与信息技术学院,北京100044)
基于多尺度卷积神经网络的场景标记
尹蕊
(北京交通大学计算机与信息技术学院,北京100044)
0 引言
场景标记是一种非常具有广泛实用价值的应用。无论在体育直播视频中增加虚拟广告,还是在某影像当中检测与识别关键物体,场景标记都是这些应用的核心问题。解析图片的难点在于目标识别,也即在整个图片背景环境中将每个像素所属的景物标记出来。这一过程存在如下问题:如何准确地描述图像信息并被计算机识别,采用什么样的训练方式才能更加准确和高效地进行学习。针对以上问题,本文使用多尺度卷积神经网络来训练图像以提取图像特征并用于测试集。
我们有这样的经验,图像场景当中对象的结构尺度有大有小,若能在特征提取阶段从多尺度邻域中来提取,就会比从单一尺度当中提取到更多的视觉信息,有可能增加局部特征当中所带的上下文信息,从而增加了特征提取阶段对图像信息描述的准确度,如图1所示。
卷积神经网络是深度学习方法的一种,是当下图像识别的主要研究方法。其核心思想是将局部感受野、权值复制与空间子采样这三种结构结合起来获得某种程度上的位移、尺度和形变的不变性。在本质上,卷积神经网络是一种输入到输出的映射,它能够学习大量的输入和输出之间的映射关系,而并不需要任何输入和输出之间的精确数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。卷积网络实行的学习算法是有监督的,故其样本集的格式为(输入向量,理想输出向量)这样的向量对。开始训练前,所有的权都应该用一些不同的小随机数进行初始化。“小随机数”用来保证网络不会因权值过大而饱和,而导致训练失败;“不同”则用来保证网络的正常学习。

图1
1 相关工作
近些年,研究者采用过很多方法来解决图像解析问题。其中,许多方法依靠马尔科夫随机域 (MRFs,Markov Random Fields)、条件随机域 (CRFs,Condition鄄al Random Fields)或其他图像模型来保证对象标记的连续性和上下文的相关性。还有一些方法采用超像素或其他分割方法将图像预分割为候选碎片,并从每个碎片或其他相邻的碎片连接当中提取特征和类别。
Socher等人提出了一种方法:使用一种训练得到的评分函数以贪心的方式来然后聚合分割。这种方法的创新之处就在于两个连接分割的特征向量是由各自分割通过训练函数得到的特征向量计算得到的。他们也使用深度学习来得到特征提取部分,但其特征提取部分是在人工选取特征的基础上做的。人工选取特征的方法费时费力,而且选取特征时还需要专业知识,能否选取准确还需要经验和运气,因此还是需要由具有自动选取特征的深度学习方法来代替人工。
在机器视觉领域,为简化或改变图像的表示形式,使图像更易于分析,又产生了图像分割的做法,通常用于刻画图像中的物体和边界。图像分割(Segmentation)指的是图像被细分为若干图像子区域(也称超像素)的过程。更准确地来说,它是对图像中每个像素加标签(label)的过程。
图像分割使得具有相同标签的像素具有某种共同的视觉特性。因此,一些研究者利用各种图像分割(如分割树)方法,将原始像素聚合成超像素(superpixel)。如,Russell等人利用对已标记图片处理所得的分割树进行分割。Carreira等人则使用超像素对图片进行分割。
之前,D.Grangier等人在场景解析中使用过卷及神经网络。他们将未处理的原始像素作为输入进行训练,所得到的分类正确率还是令人满意的。但还能够综合各种方法的优势以提高对象识别的正确率。
2 多尺度预处理
特征提取阶段中以输入图像的视野(image patch)为单位对卷积神经网络进行输入,通过卷及神经网络完成转换 f:IRP→IRQ,使得图像视野与线性可分类的IRQ可形成映射。然而,这里有一些问题:由于景物的尺寸有大有小,同样大小的视野窗口很难提供充足的描述,使得学习器输入的信息不全。另外,若固定使用较大的视野窗口则会增加输入的维度,训练数据是有限的,因此就有必要增加学习算法当中的常量个数。通常,采用池化方法来达到这样的目的,但却会降低学习模型对景物的定位与描述,同时也会使得卷积神经网络的规模变得非常大。
故本文用高斯图像金字塔来进行多尺度处理来解决这些问题。各尺度输入共享有同样参数的卷积神经网络,这样保证图像视野窗口在大小一样的情况下,各像素包含的背景信息不同,达到更精细表示的效果。对于大小为w×i的图像I,高斯金字塔Gj由I的几个分辨率减小的高斯图像 Ii(i是下标,下同)组成,其中,i= {0,1,…,j}代表金字塔的层数。图像Ii的大小为(w/2i)× (h/2i)。图像Ii是通过对图像Ii-1进行隔行隔列采样而得到的图。获得高斯金子塔的过程如图2所示。

图2
3 卷积神经网络
特征提取由卷积(Convolutions)层完成,前一层输入的局部感受野与每个神经元相连,其特征被提取,而后与其他局部感受野的特征间的位置关系也随之相对独立的确定下来,采用卷积运算的一个重要原因就是它可增强原信号特征并降低噪音;特征映射由子采样(Subsampling)层完成,根据图像局部相关性原理,对图像进行子抽样,减少数据处理量的同时保留有用信息特征,特征映射平面有多个且各神经元权值均相等,这样减少了网络自由参数的个数,降低了网络参数选择的复杂度,简化了卷积网络。其过程如图3所示。

图3
将卷积层和子采样层放大来看,一个完整的卷积采样过程如下图4所示。其中,卷积的过程是使用一个可训练的滤波器fx卷积输入图像,再增加一个bx的偏置。子采样的过程与卷积类似,将每相邻的四个像素求和变为一个像素之后再通过权值Wx+1加权,加偏置bx+1,最后经过一个激活函数(一般是Sigmoid函数)进行激活。这样可以得到一个大小近似缩小到原先1/4的特征映射图Sx+1。最初的阶段是对输入图像做卷积,而后的卷积目标就变成了特征映射。子采样层可看作是一种模糊滤波器,起二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。
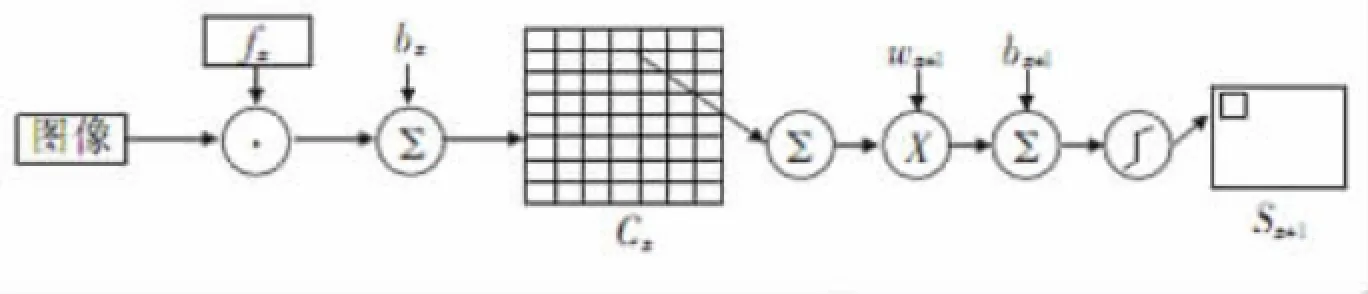
图4
4 实验及结果分析
本实验使用的数据是“Stanford Background”,它包含了715幅以室外为背景的图,其中共有9个类别需要标注出来,分别是天空、树木、道路、草坪、水域、建筑、山峦、前景物(因前景物种类太多,为避免训练时间成本,故统一归为前景物)和未知类。每幅图的尺寸都近似320×240个像素,且都至少有一个前景物。数据集使用三重交叉验证得到其中572个作为训练集图片,另外143个作为测试集图片。此实验当中有若干需要解释意义的参数如表1。
对于nhu,pools和conk三个参数的实验组合和结果如表2所示。
由实验结果说明:多尺度卷积神经网络能够提高场景解析的正确率,但并非网络深度越大,正确率就能越高,训练的正确率与具体问题的复杂程度和网络构造及参数设置都相关。

表1 实验参数意义
5 结语
场景解析的方法有很多,卷积神经网络作为深度学习的一种方法值得深入研究。但因其网络结构复杂、参数个数多、运算空间大,因此一直没有十分有效的训练方法。但就场景解析这一问题,提高正确率还有很多技巧可以增加,如景物分割等。
[1]C.Farabet,C.Couprie,L.Najman,Y.LeCun.Scene Parsing with Multiscale Feature Learning,Purity Trees,and Optimal Covers.Proc. Int'l Conf.Machine Learning,June 2012.
[2]王涛,查红彬.计算机视觉前沿与深度学习[J].中国计算机学会通讯,2015,4.
[3]R.Socher,C.C.Lin,A.Y.Ng,C.D Manning.Parsing Natural Scenes and Natural Language with Recursive Neural Networks.Proc.26th Int'l Conf.Machine Learning,2011.
Multiscale;Convolutional Networks;Scene Labeling;Deep Learning
Scene Labeling Based on Multiscale Convolutional Network
YIN Rui
(School of Computer and Information Technology,Beijing Jiaotong University,Beijing 100044)
1007-1423(2016)06-0048-04
10.3969/j.issn.1007-1423.2016.06.011
尹蕊(1990-),女,河南郑州人,硕士研究生,研究方向为深度学习
2015-12-17
2016-02-16
场景标记是将图片中的像素按照其所属景物的种类来识别并进行标记。传统学习算法将训练集图片和某种学习机制相结合,利用后者的特点来提高训练正确率。提出一种基于多尺度卷积神经网络训练已知图像及其标记的方法,用测试集图片来验证其标记正确率。通过在Ubuntu系统上搭建快速机器学习环境Torch7来实现图片像素的场景标记。
多尺度;卷积神经网络;场景标记;深度学习
Scene labeling is a method which we label each pixel in an image with the category of the object it belongs to.The traditional learning algorithms combine the family of images with some method which is used to improve accuracy of training.Presents a method that uses a multiscale convolution network trained from pixels with label known and gets verified by the test set of graph.The system is built on Ubuntu by Torch7 which is a kind of sharp environment for machine learning.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
中华养生保健(2020年7期)2020-11-16 01:14:26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
太空探索(2016年5期)2016-07-12 15:17:55
CHIP新电脑(2016年3期)2016-03-10 14:22:03
