
基于基线分析的云计算资源自动分配技术
2016-09-20 02:47李梓萌谭丽丽潘叶匡华中国移动通讯集团广东有限公司信息系统部广州510623
现代计算机 2016年6期
李梓萌,谭丽丽,潘叶,匡华(中国移动通讯集团广东有限公司信息系统部,广州 510623)
基于基线分析的云计算资源自动分配技术
李梓萌,谭丽丽,潘叶,匡华
(中国移动通讯集团广东有限公司信息系统部,广州 510623)
0 引言
随着互联网与企业信息系统的迅速发展,其产生的数据也正在迅速膨胀。人们越来越多的认识到数据对企业的重要性,对这些数据进行分析挖掘能为企业的决策提供目的和资讯。通常企业创造的数据都是非结构化或者半结构化的数据,若将这些数据下载到关系型数据库来分析,会花费过多的时间与金钱。此时,一些如Map/Reduce这样的分布式计算框架应运而生。在将来,大型数据集的分析技术将会是企业必要的重要技术[1]。
1 项目背景和意义
2009-2011年,广东移动在新全球通移动信息化大厦建设过程中,通过结合VDI[2]桌面虚拟化技术与瘦终端技术,在新大厦内建立虚拟化办公桌面系统,实现员工在大厦内高效、安全、可控的移动办公。并在此基础上,实现应用虚拟化,增加了对移动办公和业务应用系统的“应用云”快速访问服务。最终构建了桌面虚拟化架构(VDI)与应用虚拟化结合的统一桌面云。
目前,统一桌面云每时每刻都在产生大量的运维数据。由于当前系统主要依靠人工运维,所以无法处理如此大量的数据。大部分的数据被直接丢弃而无法加以利用。因此,通过利用Hadoop大型数据并行处理系统对庞大的运维数据进行整理、分析、挖掘,对系统的性能状况做出评估[3],为运维决策提供数据支持。
2 项目的目标和范围
设计与实现一个较为完善的运维数据分析系统。该模块全自动运行,每天从监控服务器获取最新的运维数据,对数据进行格式化处理并加以分析,根据分析结果生成策略建议与运维脚本。
该数据分析模块采用分层设计,由Web界面,控制脚本,数据处理程序,Map/Reduce并行运算框架和HDFS分布式存储组成。Web界面负责分析结果与运维策略的呈现。控制脚本则负责按时将监控数据导入数据分析模块,定时启动数据处理程序和分析程序。数据处理程序负责利用Map/Reduce并行运算框架对数据进行整理和分析。HDFS分布式存储则提供高性能,高容量的数据存储支持。
3 技术与原理
本节将对项目设计与开发过程中使用到的一些技术和原理做简要的阐述。这些技术包括:Hadoop分布式系统,Map/Reduce并行计算框以及K-means聚类算法。
3.1Hadoop 分布式系统
(1)Hadoop的架构
Hadoop的核心由 Map/Reduce和 Hadoop Dis鄄tributed File System组成。其最低层是HDFS,它存储着Hadoop所有节点上的文件,由NameNode和DataNode组成。Map/Reduce是位于HDFS的上一层,由Job鄄Tracker和TaskTracker组成。如图1中的“Hadoop的简单架构”。

图1 Hadoop的简单架构
3.2k-means 算法
K-means算法[7]是最为经典的基于划分的聚类算法。该算法最大的优点在于简洁快速,并且通过简单地修改便可以应用在分布式计算框架上,成为大规模数据分析的有力工具。
(1)K-means算法
K-means算法输入为数值K和N个数据对象,然后对N个数据对象分成K个聚类,使获得的聚类满足以下条件:
①同一聚类中,数据对象相似度较高;
②不同聚类中,数据对象相似度较低;
每个聚类都有一个聚类中心,即每个聚类的质心,一般以各聚类中的数据对象均值来计算。聚类中心体现该聚类的特征。
K-means算法的基本思想是:设立K个中心点,计算对象与中心点的相似性,把与中心点相似性高的对象划为相应的类别,更新中心点直到得出较好的聚类结果。
具体算法流程:
输入K,data[n];
设定中心点c[0]~c[k-1]
对于data[0]~data[n-1],分别计算每个对象与c[0]~ c[k-1]之间的相似性dist[0]~dist[k-1]。取相似性最高的dist[i],即当前对象暂被划分为第i类。
计算所有被标记为第i类的对象的均值,作为最新的聚类中心c[i]。
重复(3)(4)直到c[i]的变化幅度小于阈值或已经达到最大迭代次数。
关于相似性计算,相似性计算函数对聚类结果有着较大的影响。常见的相似性度量有:欧氏距离、曼哈顿距离、切比雪夫距离、明考斯基[8]距离等。
(2)基于欧氏距离相似性度量
欧氏距离[9]是最易于理解的一种距离计算方式,源自偶是空间中两点之间的距离公式。采用欧式距离进行相似性度量时,先对数据对象转化为n维空间上的向量。如数据对象有3个数据值,则可以简单转化为3维空间上的向量。
当完成将实际数据对象转化为n维空间上向量的数学模型后,便可以套用公式(1)进行相似性计算。
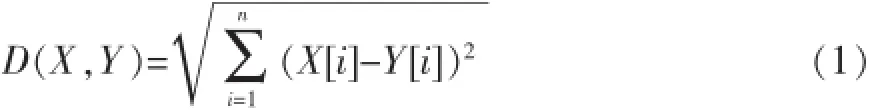
D(X,Y)表示数据对象X和Y之间的距离,当函数值越小,X和Y的相似度越高。基于欧氏距离相似性度量比较适合用于数据对象中各个数据值并没有严格的顺序关系。
(3)基于形状相似性度量
在计算负载曲线相似度时候,欧氏距离度量则显得不够科学。由于欧氏距离只考虑空间中点之间的距离,却没有考虑到各个维度的有着严格的顺序关系,如负载曲线是随着时间而变化的,如果采用欧氏距离计算负载曲线的相似度,必然会出现欧氏距离较小但曲线形状却不同的情况。
这里考虑采用数据对象间的协方差。假设n维向量X和Y(具有n个时间点的负载曲线),协方差则是衡量X和Y一起变化的尺度。如果X的最大值趋向于Y的最大值,并且X的最小值趋向于Y的最小值,则协方差将会是一个大正值。相反,协方差将会是一个负值。
设样本相关系数为P(X,Y),则样本相关系数[10]的公式见公式(2)。
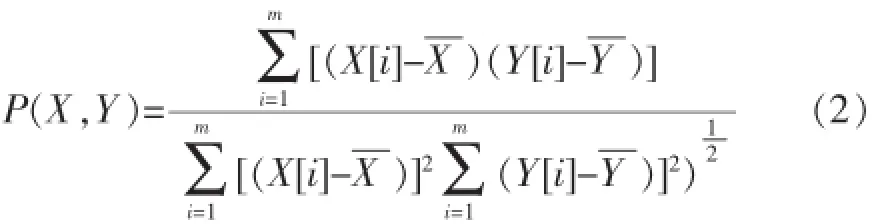
公式(2)中X和Y均表示数据对象样本均值。我们假设D(X,Y)表示负载曲线X和Y的相似度。最终基于形状相似性度量[11]如公式(3)计算。
D(X,Y)=1-P(X,Y)
4 需求建模
本节将对广东省移动统一桌面云现阶段使用状况以及现在所遇到的问题进行一个简单的描述。以解决问题为目标,对需求进行描述和建模。
4.1需求概述
当前广东移动的由桌面虚拟化架构(VDI)与应用虚拟化相结合的统一桌面云已经能够基本满足日常办公的需要。现有的系统已经提供基础设施资源的管理,调度和整合功能。
经调研,当前统一桌面云的需求如下:
(1)系统指标与用户体验量化评估。统一桌面云需要建立一套用于评估系统指标(性能、效率)和用户体验相关指标(响应时间)的方案。通过量化模型评估系统运行状况和用户体验。
(2)运维数据挖掘。需要对统一桌面云产生的日常运维数据进行整理、存储、挖掘分析,最终发现系统运行状态规律,并提供决策支持。
(3)自适应资源供给模型。根据统一桌面云系统特性建立自适应资源供给模型,系统根据该模型进行资源分配决策,能自动地对资源分配进行调整,以适应不同用户相应的资源消耗与业务需求。
(4)系统鲁棒性模型。统一桌面云需要建立一个系统鲁棒性模型,在系统部分硬件出现故障的时候,完成故障恢复,保证核心业务和关键业务的正常运作。
本项目中,笔者主要负责解决运维数据挖掘的需求,实现数据分析系统。数据分析系统可以分为三个模块:日志解析模块:主要负责数据上传、解析、格式化存储;数据分析模块,对格式化存储的日志数据进行整合、筛选,并加以分析,生成分析报告;决策支持模块:根据分析报告,生成资源调配脚本提供管理员应用和分析结果可视化。系统功能模块划分如图2所示:
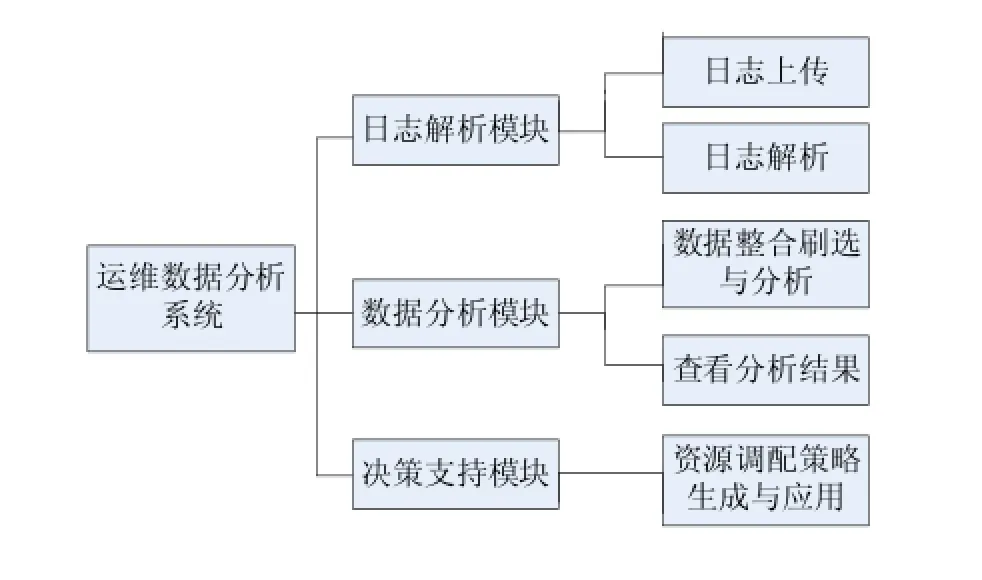
图2 系统功能模块划分
4.2领域模型
本系统主要涉及4个角色:用户、日志数据、分析报告和策略。其中用户可以用一份或多份日志数据进行分析,而日志数据可以由多个用户进行分析,日志与用户之间是多对多关系。用户可以使用一份或多份分析报告进行策略生成,而分析报告可以被0个或多个用户使用,因此分析报告与用户之间的关系是多对多关系。用户可以应用一个策略,而策略可以被0个或多个用户应用,因此用户与策略之间是多对一的关系。分析报告可以由多份日志数据分析而成,而一份日志数据可以生成多份分析报告,因此日志数据与分析报告是多对多关系。策略根据一份分析报告生成,而分析报告可以用于生成多份策略,因此策略与分析报告之间的关系是一对多的关系。
其领域模型如图3所示:

图3 领域模型
5 架构设计
本系统采用分层设计。第一层为Hadoop核心层,主要是由Map/Reduce和HDFS两部分组成。第二层为Hadoop分析层,利用基于Map/Reduce编程框架编写的分析程序对数据进行并行化分析。第三层为控制层,主要为终端或SSH。整个项目框架如图4所示:
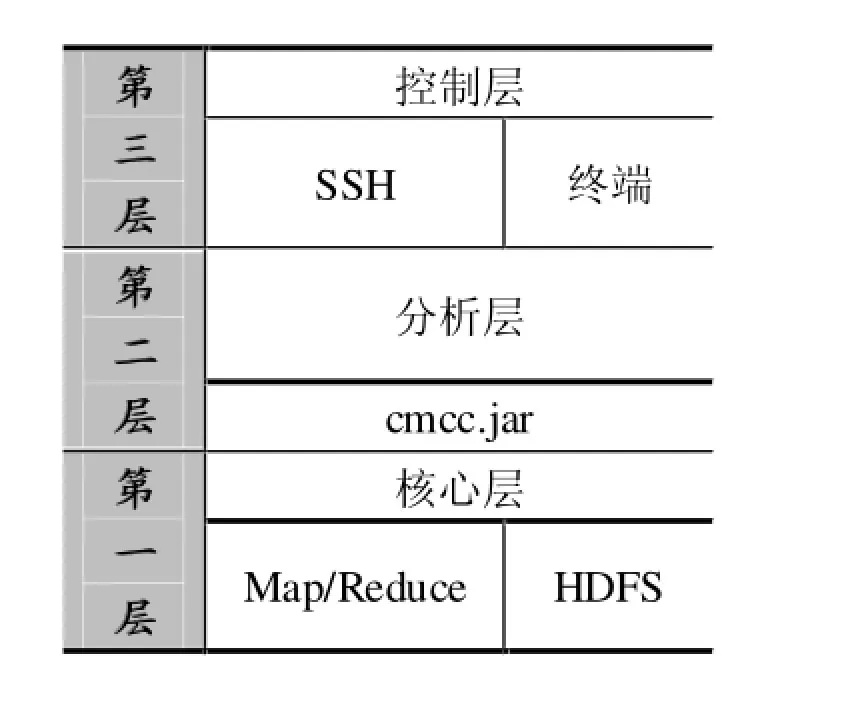
图4 系统架构
系统架构图的说明如下:
(1)用户和其他系统通过终端或SSH登录本系统;
(2)在SSH或终端上执行分析层代码包程序;
(3)分析程序通过调用核心层Map/Reduce计算框架执行;
(4)分析程序通过读取HDFS上的日志和数据并进行分析;
(5)分析结果生成在HDFS上,并显示在终端界面上;
(6)用户和其他系统通过执行命令,将结果从HDFS中取出。
6 模块设计
本章将主要阐述 “日志解析模块”、“数据分析模块”和“策略生成模块”三个模块的Map/Reduce设计以及数据模型和关键算法原理。
6.1日志解析模块
该模块主要功能是实现对非格式化日志数据进行解析并格式化存储。通过利用Map/Reduce编程框架进行并行化解析日志。在日志中提取出虚拟机性能数据(CPU、内存使用量)和虚拟机进程使用状况等数据,经过统计后按照一定的格式存储。
该模块采用Map/Reduce编程模型,Mapper负责读取日志并解析,生成易于读取的日志对象交给Re鄄ducer处理,Reducer负责将所有日志数据合并,并以固定格式输出到HDFS上。日志数据主要分为两类,一类是性能数据,即CPU、内存的负载;另一类是进程状态信息。其中进程状态信息数据获取非运行进程列表,通过与监控的进程列表对比,得出正在运行的进程。
6.2数据分析模块
数据分析模块主要有LogMerger和K-means两个类实现。LogMerger主要实现对所有的日志数据按照虚拟机名进行合并,合并方式采用求和平均方式。K-means主要实现对数据进行聚类分析,为了提高计算负载量和效率,利用了Map/Reduce编程框架对K-means实现并行化。
并行K-means算法流程描述:
(1)聚类中心文件Cluster_i加入分布式缓存;
(2)执行K-means Map/Reduce程序,生成新聚类中心文件Clusteri+1;
(3)迭代次数小于MAXITERATION,否则聚类结束。
(4)计算Cluster_i每一个中心与Cluster_i+1中的新中心的距离,如果距离大于THRESHOLD,则执行回到(1),否则聚类结束。
并行K-means算法流程活动图如图5所示。
数据分析流程描述:
(1)LogMerger对日志数据进行合并;
(2)截取出CPU负载数据,内存负载数据和进程使用频率数据分别存储在CPUDATA,MEMDATA和PROCDATA文件中;
(3)CPUDATA,MEMDATA,PROCDATA进行K-means算法,对CPU,内存负载数据采用基于形状相似性距离计算方法。而对进程使用频率数据采用欧氏距离计算方法;
(4)K-means算法结束后,以最后的聚类中心作为分组特征,得出CPUGROUP,MEMGROUP和PROC鄄GROUP,分别代表虚拟机的各个分组一天的CPU负载基线,内存负载基线和进程使用频率信息。
数据分析流程活动图如图6所示:

图5 并行K-means算法流程活动图
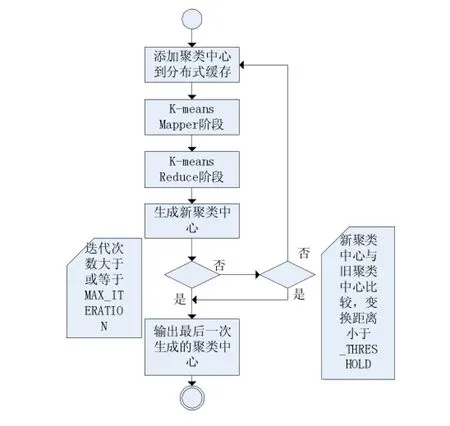
图6 数据分析流程活动图
7 部署与应用
通过对统一桌面云实际生产环境中,500台虚拟机两个星期的性能基线数据进行聚类分析,结果如下:
按照CPU性能基线聚类分析结果如图7所示。
通过观察CPU性能负载基线的分析结果,我们可以看到有3类用户,CPUGROUP2类别的用户对于CPU性能要求较高,而且负载相对较大,因此需要给予更多的CPU资源。而CPUGROUP0类别用户在早上的时候CPU负载较高,而下午的时候负载较低。CPU鄄GROUP1类用户则是下午的负载较高而早上相对较低。这些信息能提醒管理员,可以将CPUGROUP1和CPUGROUP0的虚拟机归为同一台物理机上,由于该两类虚拟机的负载高峰相反,因此可以放在同一台物理机上,达到资源利用的最大化和效益化。而CPU鄄GROUP2类别的用户由于长期高负载,因此需把该类用户与CPUGROUP0和CPUGROUP1类用户分开,以避免出现同时负载高峰引起计算资源紧张和不平衡分配。
8 结语
数据分析模型方面,我研究了层次聚类算法,K-means聚类算法及其变种,参考了前辈在负载基线分析方面的经验,通过总结和试验,逐渐建立了适用于统一桌面云运维数据的分析模型。在系统构建过程中,为了降低各个模块的耦合度,笔者编写了一些简单的接口,利用接口,工厂模式和动态绑定等方式来编写系统。系统主要分为日志解析、数据分析、策略生成三个部分。这三个部分可以分别独立运行也可以流水线运行。其中数据分析模块中的K-means算法也设计成可独立运作,方便以后扩展或者替换算法。
总体而言,本人通过这个系统在分布式计算领域和数据挖掘领域做了一次初步探索,效果还是不错,基本完成项目的需求。由于系统设计初期注重扩展性,系统能够方便地进行二次开发和扩展。在以后,笔者将继续改进算法,并增加更多数据分析流程,以便产生更多更有价值的数据分析报告,为自动化运维提供更多决策信息。
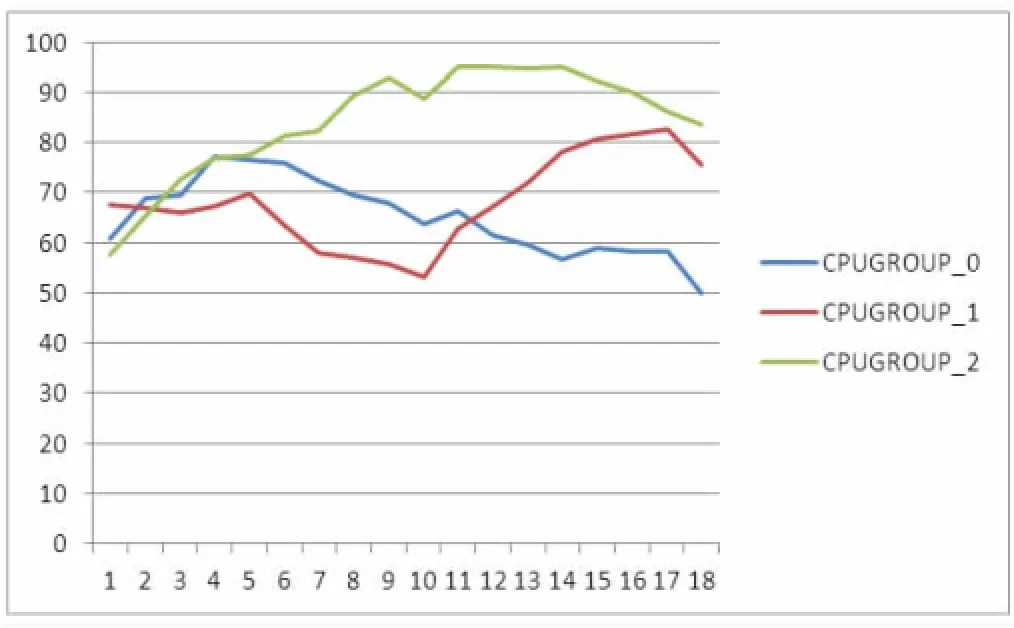
图6 CPU性能负载基线聚类分析结果
[1]王珊,王会举,覃雄派,周烜.架构大数据:挑战、现状与展望.计算机学报,34(10):1-12,2011.
[2]张庆萍.虚拟桌面基础架构(VDI)安全研究.计算机安全,72-74,2011.
[3]蒋超,张晨光.电力营业厅运维数据模型研究.见:2012年电力通信管理暨智能电网通信技术论坛论文集,2013,364-370.
[4]Tom White.Hadoop权威指南.清华大学出版社,2011.
[5]Dean J、Ghemawat S,Mapreduce:Simplified Data Processing on Large Clusters。Communications of ACM,2008,51(1):107-113.
[6]Borthakur D,The Hadoop Distributed File System:Architecture and Design.Apache Software Foundation,2007,3-14.
[7]周丽娟,王慧,王文伯,张宁.面向海量数据的并行KMeans算法.大学学报(自然科学版),2012,40:150-152.
[8]任福栋,孙菲,任福捷.基于距离和的数据挖掘技术在中考成绩处理中的应用.齐齐哈尔大学学报(自然科学版),2010,26(4):35-39.
[9]孟海东,张玉英,宋飞燕.一种基于加权欧氏距离聚类方法的研究.计算机应用,2006,26(2):152-153.
[10]严丽坤.相关系数与偏相关系数在相关分析中的应用.云南财贸学院学报,2003,19(3):78-80.
[11]苑津莎,李中.基于形状相似距离的K-means聚类算法.华北电力大学学报(自然科学版),2009,36(6):98-103.
谭丽丽,工学博士,高级工程师,从事领域为移动增值业务产品、移动互联网业务开发、运营工作
李梓萌,硕士,研究方向为管理信息化和云计算
匡华,硕士,工程师,研究方向为云计算
Hadoop;Map/Reduce;Data Analysis;Clustering Analysis
Cloud Computing Resource Allocation Based on Baseline Analysis
LI Zi-meng,TAN Li-li,PAN Ye,KUANG Hua
(The Information System Department of Gmcc,Guangzhou 510623)
1007-1423(2016)06-0019-07
10.3969/j.issn.1007-1423.2016.06.005
陈梓豪(1992-),男,广东广州人,在读研究生
2015-12-17
2016-02-10
广东省移动构建桌面虚拟化架构(VDI)与应用虚拟化结合的统一桌面云,实现员工在大厦内高效、安全、可控的移动办公。随着统一桌面云的进一步推广和应用,其日益增长的日志数据无法通过人工分析,为其运营维护提供决策支持。设计一个大数据分析系统,通过分布式并行计算框架分析统一桌面云所产生的大量数据,并最终生成决策建议。
Hadoop;Map/Reduce;数据分析;聚类算法
Guangdong Mobile to build a desktop virtualization infrastructure(VDI)and application virtualization combination of unified desktop cloud,employees inside the building efficient,safe,controllable mobile office.With the further promotion and application of unified desktop cloud,its growing log data cannot by manual analysis,decision support their operation and maintenance.The purpose is to design a data analysis system,distributed parallel computing framework to analyze large amounts of data generated by the unified desktop cloud,and the resulting policy recommendations.
猜你喜欢
中国交通信息化(2022年3期)2022-06-01
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
娃娃乐园·综合智能(2020年8期)2020-08-27
——2019(第十届)IT 运维大会特别报道
网络安全和信息化(2019年11期)2019-11-25
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
党的生活(黑龙江)(2017年10期)2017-11-09
山东工业技术(2016年15期)2016-12-01
电脑爱好者(2016年16期)2016-08-30
