
空间数据挖掘的高效和有效的聚类方法
2016-09-20 02:47胡馨元殷守林刘杰沈阳师范大学科信软件学院沈阳110034
现代计算机 2016年6期
胡馨元,殷守林,刘杰(沈阳师范大学科信软件学院,沈阳 110034)
空间数据挖掘的高效和有效的聚类方法
胡馨元,殷守林,刘杰
(沈阳师范大学科信软件学院,沈阳110034)
0 引言
空间数据挖掘[1-2]是指从空间数据库中抽取没有清楚表现出来的隐含的知识和空间关系,并发现其中有用的特征和模式的理论、方法和技术。空间数据挖掘和知识发现的过程大致可分为以下多个步骤:数据准备、数据选择、数据预处理、数据缩减或者数据变换、确定数据挖掘目标、确定知识发现算法、数据挖掘、模式解释、知识评价等,而数据挖掘只是其中的一个关键步骤。但是为简便,人们常常用空间数据挖掘来代替空间数据挖掘和知识发现。
在空间数据处理过程中,采用所有的算法都会遇到两个问题:第一,用户和专家必须为算法提供空间层次概念结构,这可能并不在一些应用中使用;第二,两种算法进行空间探索主要通过在一定程度层次结构上以一个更大的地区在一个更高的水平合并区域。这两个问题对于很多应用来说,它很难知道一个先验的层次结构是否是最适合的。
在聚类分析中有两种著名的算法即围绕中心点的划分和大型应用中的聚类方法。
空间数据挖掘的两个主要算法SD(Clarans)和NSD(Clarans)[3-4]。
SD(Clarans):Spatial Dominant Approach空间占主导地位的方法。
NSD(Clarans):Non-Spatial Dominant Approach非空间占主导地位的方法。
为了解决这些问题,我们探索了聚类分析技术是否适用。在过去三十年中聚类分析一直是个被研究的对象,而且成功应用在很多领域上。对于空间数据挖掘,我们在这里使用的方法仅用于空间属性,那些自然相似概念的存在如欧几里得、曼哈顿距离。正如本篇文章所展示的,聚类分析对于空间数据挖掘非常有效,作为更有效的考虑,我们发展研究自己的聚类分析算法叫做CLARANS,它为了研究大数据集而被设计。
1 基于分割的聚类方法
1.1围绕中心点的划分方法(PAM)
它的基本思想:为找到k个集群,它的方法就是为每个集群确定一个代表对象。这个代表对象称为中心点它是最集中位于集群中的对象。一旦这个中心点被选中了,每一个非选择的最相似的对象以中心点归类[5-7]。假如Oj是一个非被选择的对象,Oi就是一个中心点,我们就说Oj属于由Oi代表的聚类。如果d(Oj,Oi)=minOed(Oj,Oe),其中minOe代表所有中心点Oe中的最小值。d(Oa,Ob)代表Oa到Ob的距离。
所有的相异点的值给出作为PAM的输入,最后聚类的效率由一个对象和一个中心点的平均值测出。为了寻找这个k个中心点,PAM以任意的一个k对象开始,在每一步中只要能够提高聚类的效率就进行Oi和Oh的互换,为了计算两者之间互换的影响,PAM对所有非选择性对象Oj计算Cjih的消耗。下面列出了Oj存在的几种情况:
(1)假设Oj属于Oi的聚类 ,让Oj比Oh更加相似于Oj2,也就是d(Oj,Oh)≥d(Oj,Oj2),Oj2更接近于Oj,因此,如果Oi被Oh取代了成为中心点,那么Oj属于Oj2的一个聚类。互换成本可以写成Cjih=d(Oj,Oj2)-d(Oj,Oi)。
(2)Oj比Oh并不相似于Oj2也就是d(Oj,Oh)<d (Oj,Oj2)。如果Oi被Oh取代了成为中心点,那么Oj属于Oh的一个聚类此时Cjih=d(Oj,Oi)-d(Oj,Oj2)。
(3)假设Oj接近于除了Oi展示的聚类 ,让Oj2接近于那个中心点,而且让Oj比Oh更接近于Oj2,因此,即使Oi被Oh取代了,Oj会一直听停留在Oj2的一个聚类中。互换成本可以写成Cjih=0。
(4)假设Oj属于Oj2的聚类 ,但是Oj比Oh并不接近于Oj2,用Oh取代Oi会引起Oj跳跃到Oh的一个聚类中,因此,如果Oi被Oh取代了成为中心点,那么Oj属于Oj2的一个聚类。互换成本可以写成Cjih=d(Oj,Oh)-d (Oj,Oj2)。
1.2围绕中心点的划分算法步骤
(1)任意选择k个代表对象。
(2)Oi被选定了,Oh没有被选中,计算所有的Oi消耗成本。
(3)选择Oi和Oj这一对中心点符合minOi,Oh,TCih如果最小值是负的就用Oh取代Oi并且回到第二步。
(4)否则,对于每一个非被选择的对象找到最相似的对象。
实验结果表明,PAM适合小的数据集而不适合大的。在第二第三步中一共有k(n-k)对Oi和Oh,对于每一对中心点,
计算TCih需要检查(n-k)个非选择点,那两步的时间复杂度是O(k(n-k)2),但是这样过于复杂,因此出现了CLARA(Clustering Large Applications,大型应用中的聚类方法)。
2 CLARA算法
①对于i=1,2,3,4,5重复以下步骤。
②从所有数据集中随机画一个40+2k对象的样本,让PAM算法找到k个中心点。
③对于所有数据集中的Oj对象,确定k个中心点哪一个更接近于Oj。
④计算包含在以上步骤中的相异聚类点的平均值,如果这个值小于目前的最小值用这个值取代那个最小值,保留在第二步中找到的k个中心点作为目前最好的一组中心点集。
⑤返回到第一步开始新的交互寻找。
PAM:时间复杂度是O(k(n-k)2)。
CLARA:时间复杂度是O(k(k+40)2+k(n-k))。
3 一种基于随机搜索的聚类算法——CLARANS

另外,令Sa是一组对象,子图GSa,k由子集合Sa构成。如果M原始图形Gn,k中的最小节点,而且M并不包含在GSa,k中,那么M永远不会在GSa,k的搜索中找到。
CLARA在搜索的开始,画了一个样本的节点,而CLARANS在每一个搜索的步骤中画了一个邻居的样本。
(1)分割聚类算法步骤
①输入参数numlocal(局部最小值),maxneighbor(局部最大值)初始化i=1,mincost为一个大数值;
②在Gn,k中设置一个任意节点current;
③令j=1;
⑤如果S有一个很低的消耗,令current=S,回到第三步;
⑥否则,j+1。如果j≤maxneighbor回到第四步;
⑦否则j>maxneighbor,让current和mincost的消耗做一个比较,如果current消耗少于mincost,令min鄄cost=current(cost消耗),并且令bestnode=current;
⑧i+1,如果i>numlocal,输出bestnode和halt,否则返回到第二步。
由以上可以看出,CLARANS有两个参数邻居的最大值和局部的最小值。局部最大值越高,CLARANS越接近PAM,每个局部最小值的搜索也越长。这样一个局部最小值更高的特性将会有更少的地方需要取得最小值。在CLARANS里面设置numlocal=2,maxneighbor设置成一个在250和k(n-k)的1.25%之间比较大的值。PAM和CLARANS的比较结果如图1所示。
CLARA产生聚类的特性,CLARANS进行了数值规范。随着k=5,10,20增大CLARA的误差也越来越大,而CLARANS方法的误差不变。如图2所示。

图1 PAM和CLARANS的比较结果
考虑到相同的时间,CLARANS在所有情况下很明显胜过CLARA。当k(聚类的个数)从5增加到20的时候二者之间的误差由4%到20%。随着k的增大它们之间的误差可以通过对二者彼此的复杂分析很好的被解释。
CLARA的时间复杂度是O(k3+nk)可以说明CLARA的有一个很大消耗。但是对象个数的越多二者之间的误差也就越小。总之,我们已经有实验表明CLARANS 比CLARA更有高效性。
4 结语
本文提出了一种基于随机搜索的聚类算法称为CLARANS,实验部分说明了此方法的有效性,比现有的数据挖掘算法能快速有效的发现新的数据,因此,CLARANS算法是一个非常有前途应用的算法,在数据挖掘方面将会起到很大的作用。
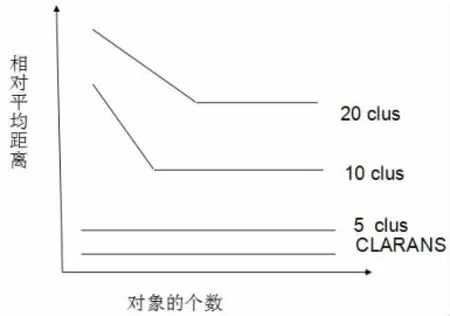
图2 CLARA和CLARANS误差比较
[1]周海燕.空间数据挖掘的研究[D].中国人民解放军信息工程大学,2003.
[2]王海起,王劲峰.空间数据挖掘技术研究进展[J].地理与地理信息科学,2005,04:6-10.
[3]孙志伟,赵政.SOFM神经网络在处理非空间属性中的应用[J].计算机应用,2006,11:2667-2669+2673.
[4]孙志伟,赵政.DBSCAN在非空间属性处理上的扩展[J].计算机应用,2005,06:1379-1381.
[5]吴文亮.聚类分析中K-均值与K-中心点算法的研究[D].华南理工大学,2011.
[6]Tianhua Liu,Shoulin Yin.An Improved K-means Clustering Algorithm for Kalman Filter[J].ICIC Express Letters Part B:Applications,2015,6(10):2687-2692.
[7]徐金宝.核函数在划分聚类中的应用与实现[J].电脑知识与技术,2013,27:6185-6188.
[8]殷守林,刘天华,李航.基于模拟退火算法的卡尔曼滤波在室内定位中的应用研究[J].沈阳师范大学学报(自然科学版),2015,01:86-90.
[9]李强,何衍,蒋静坪.一种基于随机游动的聚类算法[J].电子与信息学报,2009,03:523-526.
[10]陈东辉.基于目标函数的模糊聚类算法关键技术研究[D].西安电子科技大学,2012.
Spatial Data Mining;Partitioning Clustering Method;Random Search
Efficient and Effective Methods in Spatial Data Mining
HU Xin-yuan,YIN Shou-lin,LIU Jie
(Software College,Shenyang Normal University,Shenyang 110034)
1007-1423(2016)06-0015-04
10.3969/j.issn.1007-1423.2016.06.004
胡馨元(1990-),女,辽宁铁岭人,沈阳师范大学硕士研究生,研究方向为数据挖掘,企业信息化
殷守林(1990-),男,河南濮阳人,硕士研究生,研究方向为数据挖掘、网络安全。E-mail:910675024@qq.com
刘杰(1966-),男,博士,教授,辽宁沈阳人,沈阳师范大学硕士研究生导师,研究方向为数据挖掘,软件工程
2015-12-17
2016-02-15
空间数据挖掘可能隐式的存在于空间数据库中。探索聚类方法是否对于空间数据挖掘有一定的帮助。为此,提出一种基于随机搜索的新的聚类方法——分割聚类方法。使用分割聚类方法也研究出两种空间数据挖掘算法。经过分析与验证,在分割聚类方法的帮助下,这两种算法非常有效且会发现很难找到与当前空间数据挖掘算法有重复之处。再者,分割聚类方法和那些存在的聚类方法相比较,实验表明分割聚类方法具有高效性。
空间数据挖掘;分割聚类方法;随机搜索
Spatial data mining may be the implicit existence in spatial database.Explores that whether the clustering method is useful for spatial data mining,proposes a new clustering method based on random search named partition clustering method.Using partition clustering method also develops two kinds of spatial data mining algorithms.After analysis and validation,with the help of the partition clustering method,the two kinds of algorithm is very effective and it is difficult to find same parts with the current spatial data mining algorithm. Moreover,compared with the existing clustering methods,experiment results of partition clustering method show that clustering segmentation method is very effective.
猜你喜欢
昆钢科技(2022年1期)2022-04-19
现代装饰(2021年3期)2021-07-22
昆钢科技(2021年6期)2021-03-09
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
动漫界·幼教365(中班)(2020年3期)2020-04-20
电脑报(2019年4期)2019-09-10
长江丛刊(2018年8期)2018-11-14
英语学习(2016年1期)2016-09-10
大众摄影(2015年9期)2015-09-06
