
一种基于SVM的多特征参数清浊音判决算法
2016-09-13 09:13:15李克靖孙凤梅石乔林
电子设计工程 2016年5期
李克靖,孙凤梅,石乔林
(中国电子科技集团公司 第五十八研究所,江苏 无锡 214035)
一种基于SVM的多特征参数清浊音判决算法
李克靖,孙凤梅,石乔林
(中国电子科技集团公司 第五十八研究所,江苏 无锡214035)
为解决低速率声码器合成语音中,由于语音帧清浊判决不够准确而造成的偶发性嘶哑、机器音较重及变调等问题,提出一种基于支持向量机(Support Vector Machine,SVM)并结合多种语音特征参数的清浊音判决优化算法。实验结果显示,该算法能够有效降低清浊音的误判率,进而使合成语音的清晰度和自然度得到改善。将本算法应用到正弦激励线性预测算法中,在与相同码率的其他算法的比较实验中,得到较高的PESQ-MOS分,显示出一定的优势。关键词:声码器;清浊判决;支持向量机;特征参数
随着数字技术的发展,语音压缩编码技术在通信领域的应用越来越深入和广泛,同时,编码速率也在不断向低速化发展。然而,一些码率下的语音编码算法尽管已经具有良好的性能,但其合成语音多数面临着机器音较重、偶发性嘶哑及变调等问题。究其原因,主要在于清浊音判决不够准确以及基音周期的倍/半频错误。因此,可通过提高参数提取的精度来得到更高质量的合成语音。
清浊音判决是语音编码中的一个重要参数,常常关系到语音合成时所用激励的形式,对合成语音的质量有较大的影响。传统方法是通过提取语音帧的某些特征参数,然后进行线性处理并根据预定阈值来进行判断,阈值一般依靠经验来确定,其中较为经典的算法所使用的分类技术是一个贝叶斯决策过程[1],该方法简单、容易实现,然而无法保证判断结果的可靠性;随着人工智能技术的发展,许多学者将它引入到语音编码领域中,文献[2]介绍了一种应用不同特征参数和神经网络结构的判别方法,但是传统的人工神经网络(如BP神经网络)方法存在着训练速度慢、容易陷入局部极小值点等缺陷,而且这种经验非线性方法在网络结构的选择以及权重初值的设定方面往往需要依靠人工经验,缺乏统一的数学理论基础;文献[3]应用监督学习中的Fisher判决法,通过高维空间向一维空间投影,进而在一维空间进行判决,简化了分类界面的求取,提高了判决的准确度,然而,依然没有摆脱需要人工确定判决门限所带来的误差。
1 基于贝叶斯准则的清浊音判决
从本质上讲,清浊音判决是一个模式识别的问题,其目标是根据样本选取合适的参数得到最优划分,降低清浊音误判率。
1.1贝叶斯最小风险判决准则
传统清浊音判决方法一般采用最大短时自相关值作为语音特征值,通过贝叶斯最小风险判决准则,试图找到一个最佳判决阈值,使代价函数(1)的值达到最小[4]。
其中,r为最大短时自相关值,L1和L2分别表示清音误判为浊音和浊音误判为清音的代价因子,p1和p2分别为清音误判和浊音误判的概率,p(U)和p(V)则分别代表清音和浊音出现的概率。一般在声码器中,浊音误判为清音对合成语音质量带来的负面影响远远大于浊音误判为清音,因此代价因子L1<<L2。为使代价函数最小,常常需要牺牲清音判决的准确度来降低浊音误判率,实际应用中一般取0.6为阈值。

1.2贝叶斯准则误判分析
利用贝叶斯准则进行清浊音判决时,存在大量清音的误判,从而使合成语音浊音度过强、机器音较重,严重影响语音的自然度,并在一定程度上影响发音的清晰度,甚至造成部分语音变调。
另外,当静音段存在规律性的背景噪声时,会有较大的自相关值,极易被误判为浊音。基于贝叶斯准则的判决算法仅以最大自相关值为判据,数据量小,误判率高,需要引入其它语音特征参数以提高判决准确度。
2 基于SVM的清浊音判决
支持向量机是一种典型的监督学习方法,在小样本、非线性和高维模式识别中有着许多特有的优势[5]。本文算法利用带有清浊音标记的语音样本结合多个特征参数训练得到SVM分类器,然后以待分类语音帧的特征参数向量作为判据,通过分类器得到分类标签,实现语音帧的清浊判决。
2.1SVM原理简述
支持向量机最早是由Vapnik在1995年提出的,与传统分类器相比,该方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,能够根据有限的样本信息在模型学习能力和复杂性之间寻求最佳折衷。
假设有n个维训练样本(x1,y1),…,(xn,yn),xi∈Rk,yi∈{-1,1}是分类标签,SVM的目标是寻找一个间隔最大的最优超平面,即存在w和b组成超平面wTx+b=0可以将所有训练数据无错误地分开:
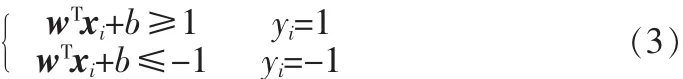
且离超平面最近的向量与超平面之间的间隔是所有可能情况中最大的。其中,使等号成立的那些样本就是支持向量(Supporting Vector)。
实际分类问题中往往不是线性可分的,这时可引入松弛变量ξi,通过求解以下优化问题得到超平面的参数w和b:
其中C>0为惩罚因子,它表示对错分样本的惩罚程度,C值越大表示对错误分类的惩罚越大。引入松弛变量用以实现最大分类间隔和最少错分样本之间的折衷,从而得到广义的最优分类面。
对线性不可分的问题,可以考虑通过某种非线性映射把训练数据映射到高维特征空间,然后利用支持向量在此空间中构造出分类超平面,用线性判别函数实现原始空间中的非线性判别函数。引入核函数后分类器的决策函数为:


进行SVM训练时,常常遇到样本数目不均衡的情况,此时,得到的分类面会偏向样本数较少的一类。这是由于在式(4)中使用了相同的惩罚因子C,从而使分类面偏向样本密度较小的一类。可以考虑对不同的类设置不同的惩罚因子C,这样能够有效地根据不同类别的错分代价进行超平面的优化,即构造如下二次规划问题[6]:
其中C+和C-分别为正样本和负样本的惩罚因子。
可以看出,支持向量机是将输入的样本空间升维,从而使原问题在高维空间中线性可分或接近线性可分。该方法之所以可行是因为空间升维后的算法复杂度并不随维数的增加而增加,同时,在高维空间中的推广能力也不受维数的影响,很好地避免了“维数灾难”的问题。
2.2语音特征参数选取
选取语音特征参数的原则是:参数要对不同模式的分类可靠有效,提取简单,参数的取值范围在各类别中的重叠较少,各参数可以从不同角度描述样本的特性,以提高分类的准确度。
文中算法采用最大自相关值(r)、过零率(z)、短时帧能量(e)和谱倾斜度(t)等4个特征参数作为判据,其定义如下[7]:

其中,s(i)为经过滤波后的语音信号,N为每帧样点数。4个参数组成特征向量X=(r,z,e,t)。
图1给出了一段语音“天安门广场”中前3个参数的变化与语音波形的对比图,可以较为明显地看出呈现如下规律:浊音段有较大的最大自相关值和短时帧能量,以及较小的过零率;清音段的最大自相关值和短时帧能量较小,而过零率较大。另外谱倾斜度与语音波形之间的联系虽然不是较为直观,但是作为一个重要的语音特征参数,可以在一定程度上提高训练所得分类器的分类准确度,实验过程中也证明了这一点。
2.3实验结果与分析
算法实验所用语音文件选自中国科学院声学研究所语音数据库,均为PCM格式,采样率8 000 Hz,16 bit。训练样本发音人为两男两女,帧长为25 ms,即200个样点。训练样本共有2 500帧,其中清音约占55%,浊音45%。训练样本的清浊音分类是通过观察语音帧时域波形、频域频谱特性并结合其实际对应的音素综合判定的。图2所示为“中”字的声母、韵母的部分波形,由于浊音具有明显的周期性且振幅较大,而清音波形类似于白噪声,振幅很小,没有明显的周期性,根据各帧波形及所属音素可以相当准确地判定其清浊类别。

图1 部分参数变化与语音波形对比图Fig.1 Change of some parameters compared with sound wave

图2 典型清浊音波形示意图Fig.2 Wave of typical voiced/unvoiced sound
首先进行算法判决的准确性测试,测试样本来自DVSI网站公布的原始语音,包括男声、女声和男女混声,共计2 000帧,由39%的浊音和61%的清音组成。同时对传统贝叶斯判决及文献[3]中Fisher判决方法进行了测试,实验结果如表1所示,可以看出本文算法的判决准确度明显高于其他两种算法,且对合成语音影响较大的浊音误判也保持有比较理想的比例。
将本文算法应用到正弦激励线性预测(SELP)编解码算法中进行测试,同时实现了美国政府标准MELPe算法以及传统的使用贝叶斯判决的SELP_B算法,各算法码率均为2.4 kb/s。对测试样本中部分语音文件进行测试,包括Female、Male和 Mix 3个文件。测试指标为平均意见得分(Mean Opinion Score,MOS),采用国际电信联盟(International Telecommunication Union,ITU)建议的P.862 MOS分测试软件,测试结果见表2。可见使用本文清浊音判决算法后,SELP编解码算法合成语音的PESQ-MOS分有一定的提高;另外,从安排多人进行试听的反映来看,由于清浊音误判而造成的偶发性嘶哑和变调问题相对于其他算法也有一定程度的改善,进一步证明了本文算法的有效性。

表1 算法误判率比较Tab.1 Justice error of the algorithms
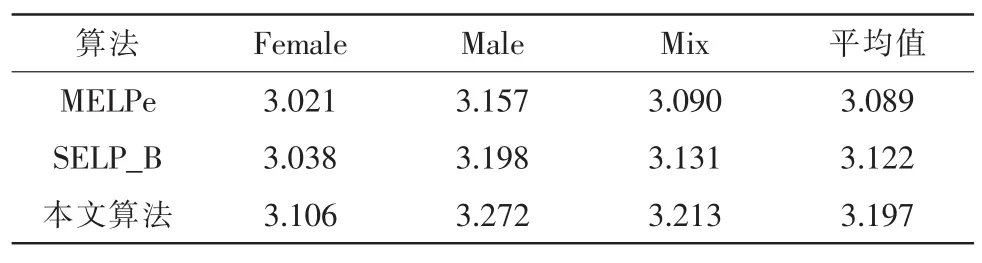
表2 算法PESQ-MOS分比较Tab.2 PESQ-MOS score of the algorithms
同时,笔者还将本文算法应用到其他码率(1200、600、300 bps)的SELP声码器中,所得合成语音的PESQ-MOS分相对于原对应码率的合成语音均有一定程度的提高。
3 结 论
本文将机器学习中支持向量机的方法应用于语音编解码中清浊音的判决,与传统方法相比,避免了人工设定经验阈值的局限性,且能够通过较小的训练样本集获得相当好的分类性能,提高了清浊音判决的可靠性。将其应用于SELP声码器中,对后续基音周期参数提取的准确度也有一定的提高,进而有效改善了合成语音的偶发性嘶哑和变调问题,提高了其PESQ-MOS分,同时,具有相当好的可懂度和自然度。
[1]Atal B,Rabiner L.A pattern recognition approach to voiced unvoiced-silence classification with applications to speech recognition[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1976,24(3):201-212.
[2]Qi Y,Hunt B R.Voiced-unvoiced-silence classification of speech using hybrid features and a network classifier[J]. IEEE Transactions on Speech and Audio Processing,1993,1(2):250-255.
[3]党晓妍,魏旋.声码器清浊音判决算法优化[J].清华大学学报,2008,48(7):1119-1122.
[4]Theodoridis S,Koutroumbas K.Pattern Recognition[M]. Beijing:Publishing House of Electronic Industry,2006.
[5]Vapnik Vladimir N.The Nature of Statistical Learning Theory[M].Berlin Heidelberg,New York:Springer2Verlag,2000.
[6]Veropoulos K,Cambell C,Cristianini N.Controlling the sensitivity of support vector machines[C].Proceedings of the International Joint Conference on AI,1999:55-60.
[7]计哲,李晔,崔慧娟.SELP声码器基音周期参数量化合成改进算法[J].高技术通讯,2010,20(1):45-48.
Voiced-unvoiced classification based on SVM and multi-parameter
LI Ke-jing,SUN Feng-mei,SHI Qiao-lin
(China Electronic Technlogy Group Corporation No.58 Research Institute,Wuxi 214035,China)
The composed voice of low bit rate vocoders usually have occasionally hoarseness,out-of-tone speech,caused by the low veracity of voiced-unvoiced classification.To solve the problem,a new improved algorithm based on Support Vector Machine combined with several characteristic parameters is proposed.Experimental results show that the algorithm greatly reduces the voiced-unvoiced classification error rate,and enhances the articulation and spontaneousness of the composed voices.Use this method in SELP(sinuous excitation linear prediction)vocoder,compared with other method with same bit rate,it has higher PESQ-MOS score,which shows its advantage.
vocoders;voiced-unvoiced classification;support vector machine;characteristic parameters
TN 912.32
A
1674-6236(2016)05-0184-03
2015-04-20稿件编号:201504217
李克靖(1989—),男,安徽太和人,硕士。研究方向:语音压缩编解码。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
制造技术与机床(2017年11期)2017-12-18 06:46:39
中国交通信息化(2017年8期)2017-06-06 07:16:45
上海公路(2017年4期)2017-03-01 07:04:27
中国水运(2016年11期)2017-01-04 12:26:47
软件导刊(2016年11期)2016-12-22 21:52:38
电子技术与软件工程(2016年20期)2016-12-21 10:21:33
价值工程(2016年32期)2016-12-20 20:36:43
价值工程(2016年29期)2016-11-14 00:13:35
