
网页分类中特征选择方法的研究
2016-09-13 09:27:42唐喆曹旭东
电子设计工程 2016年5期
唐喆,曹旭东
(中国石油大学(北京)地球物理与信息工程学院,北京 102249)
网页分类中特征选择方法的研究
唐喆,曹旭东
(中国石油大学(北京)地球物理与信息工程学院,北京102249)
准确的网络分类对于健康的网络环境至关重要,本文基于这样的目的,采用了效果理想SVM分类技术,考虑到不同的特征选择方法造成的分类结果的差异,分别在相同和不同的分类样本的条件下测试了4种特征选择方法,研究得出TFIDF方法的突出优点,并总结了合适的特征选择方法对于应用到不同的分类系统的重要性。
文本分类;SVM;特征选择;TFIDF
支持向量机SVM[1]是一种可训练的机器学习方法,它对小样本进行学习,得到一个分类函数,再将待测文本代入此分类函数中判定文本所属的类别。SVM的特点是:SVM可以通过映射把低维样本空间映射到高维特征空间中,成功地将非线性可分问题转化为线性可分的问题,并且在特征空间中构造线性函数,实现对文本的自动分类。SVM将非线性问题转化成线性可分问题,巧妙地解决维灾难和过学习现象。特征选择是整个分类模块中的重要部分,选择合适的特征提取方法对分类的效果有很大的影响。
1 分类算法比较
如表1,从表1的结果可以得出:选择每一种分类算法的时候要从样本量的大小、样本数据的维度、样本数据的线性可分情况3种情况来考虑,对不同形式的训练样本采用不同的分类算法会大大提高分类的效率和准确率,节省开销。
基于本论文所处理的分类数据是web文本,而SVM分类算法处理非线性和高维度的数据能力强,从样本量的大小和数据维度两方面来考虑,选择了SVM分类算法。
它具有以下3个特点:
第一,SVM可以避免“维数灾难”,其最终决策函数仅仅是由少数的支持向量来确定,它的计算困难程度由支持向量的数目决定,与样本空间特征的维数无关。
第二,SVM拥有“鲁棒”性,只需通过少数样本特征,即关键特征,来实现分类,所以“剔除”了大多数冗余样本信息。
第三,SVM拥有坚固的理论基础,通过新的高效的统计方法,来预测样本类别,使实现分类的原理和过程得到简化。

表1 5种分类算法优缺点比较Tab.1 The advantages and disadvantages compared five classification algorithm
2 文本预处理
文中选用了能够实现SVM算法的LABSVM软件平台,经过人工标注的样本数据不能满足LABSVM分类器的格式要求,样本数据不能识别,我们要通过样本的预处理将数据转化成分类器能识别的格式[2]。
2.1文本分词
分词方法因为语种的不同而不同,一般的分词方法有3种:基于理解的分词方法,基于词典的分词方法和基于统计的分词方法。
2.2特征选择
经过文本分词处理以后,要进行特征选择标记相关的文档。文本特征是指对文本主题归类贡献较大的具有实际意义的词。通过选取这些特征,可以构造出更精确的模型[3]。
特征选择方法有很多,譬如:TFIDF、信息增益、互信息,卡方等,其中最著名的是TFIDF算法。特征选择是网页分类过程中的关键技术。特征选择的过程实质上是一个从特征集合中选取特征子集的过程。
3 特征选择方法
3.1TFIDF
TF-IDF算法[4]是依据词或者短语在文本中出现的频率为测度,以此来判断该特征词区别不同类别文本的能力大小的一种方法。TF-IDF算法的假设基础:对区别文档作用比较大的特征词语应该是那些在分类文档中出现频率高,而在整个文档集合的其他文档中出现频率少的词语。
词频TF是指一个特征词在某个文档中出现的次数。

反向词频IDF是指在所有文本的集合中,特征词出现的次数。
TF-IDF方法的计算公式如下。
3.2信息增益
信息增益(IG)[5]是用来衡量某个文本中的某个词语是否被当选为特征项的标准。从信息论角度来讲,当用IG进行特征选择时,以各个特征项取值情况来划分学习样本空间,如果某个词出现对判断某个文本属于某个类别的信息量大,则该词就被选为特征项,否则不被当选为特征项。评价函数为:

其中,P(Ci|t)表示文本中出现某个特征t时,文本属于类别Ci的概率;表示文本中不出现某个特征t时,文本属于类别Ci的概率;P(Ci)表示类别出现的概率;P(t)表示特征t在整个训练文本集中出现的概率。
3.3互信息
互信息(MI)[6]:在进行特征选择时,互信息是用来衡量t特征和类别Ci之间的相关程度的。具有较高的互信息的特征项是在某个类别Ci中出现的概率高而在其它类别中出现概率低的特征t,其评价函数为:

但是互信息存在一个很大的缺点就是当两个词语具有相同的条件概率P(t|Ci)时,出现次数多的词语会比出现次数少的词语具有较小的MI值。
3.4卡方法
卡方(χ2)统计法[7]:在进行特征选择时,用χ2统计法来衡量词语与类别之间的相关性,它基于的假设如下:在某个类别中出现频率高的词语对判断该文本的类别有帮助。其评价函数为:

4 分类性能评估
在文本分类中如何对分类结果进行评价至关重要,对单个类的分类性能评估指标:对单个类的分类性能的评估中普遍使用的分类性能评估指标有召回率和查准率[8]。下面使用邻接表来表示准确率和召回率。如表2所示。
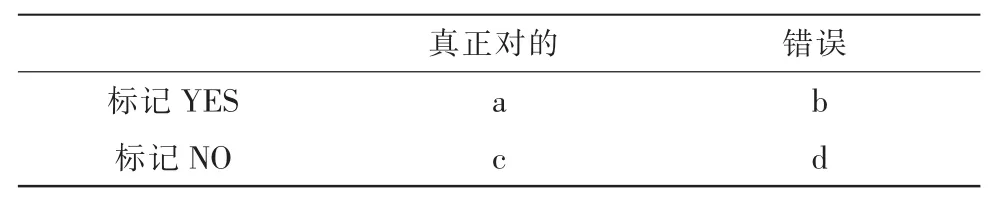
表2 二值分类邻接表Tab.2 Binary classification adjacency list
查准率用公式表示如下:
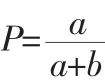
召回率用公式表示如下:

采用性能评价方法是Fβ,Fβ将召回率和查准率结合起来,其计算公式为:

其中,β一个调整召回率和查准率权重的参数,即当β=1时,召回率和查准率同等重要;
5 实验结果分析
我们从互联网抓取网页,实验将对于6个类别进行,保证训练集与测试集的样本不重叠。为了考察不同的特征选择方法对准确率的影响,我们观察对同一个类别的网页的分类准确率。实验条件见表3。
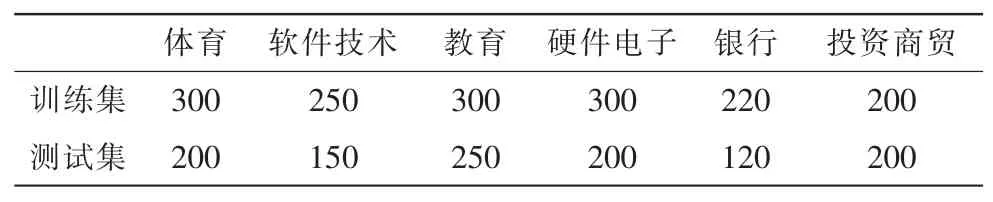
表3 各类文本分布表Tab.3 All kinds of text distribution table
实验方案:
1)对已经抽取的样本数据进行样本训练与分类预测。
2)在原有的训练集内增加1 000条人工标注的网页,其中体育类为50%,再对样本数据进行训练。
3)在第二次实验的基础上,在训练集内增加1 500条人工标注的网页,其中体育类占50%,再进行训练。
实验结果见表4,表5和表6。
从表4,表5和表6可以得出结论:
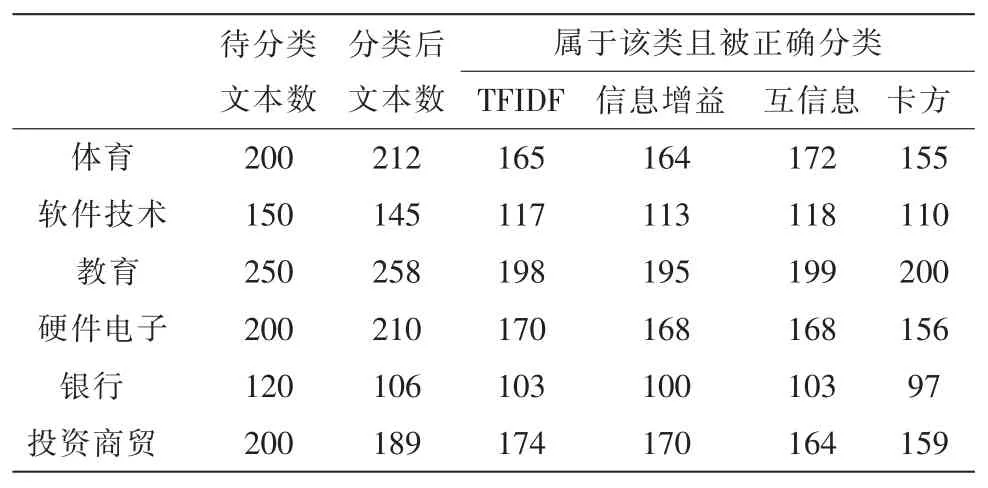
表4 方案1的分类结果Tab.4 Classification results of Plan 1
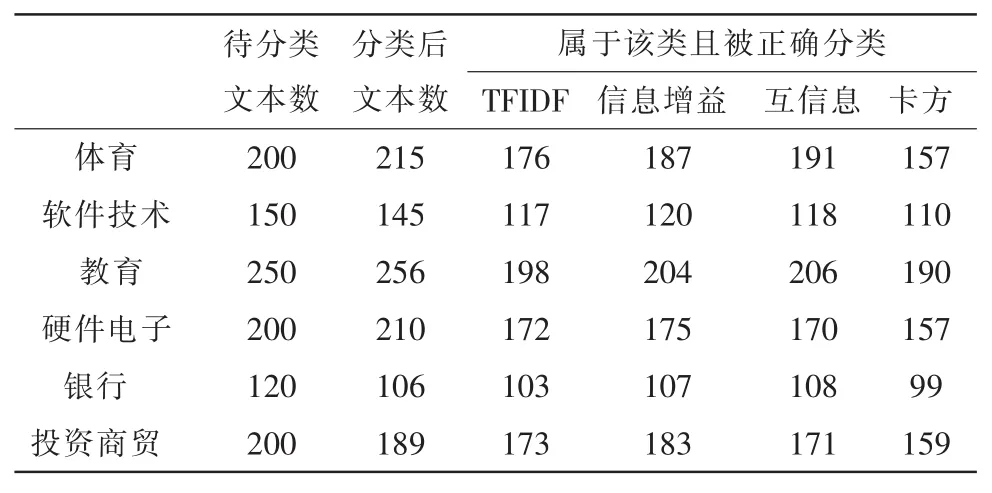
表5 方案2的分类结果Tab.5 Classification results of Plan 2
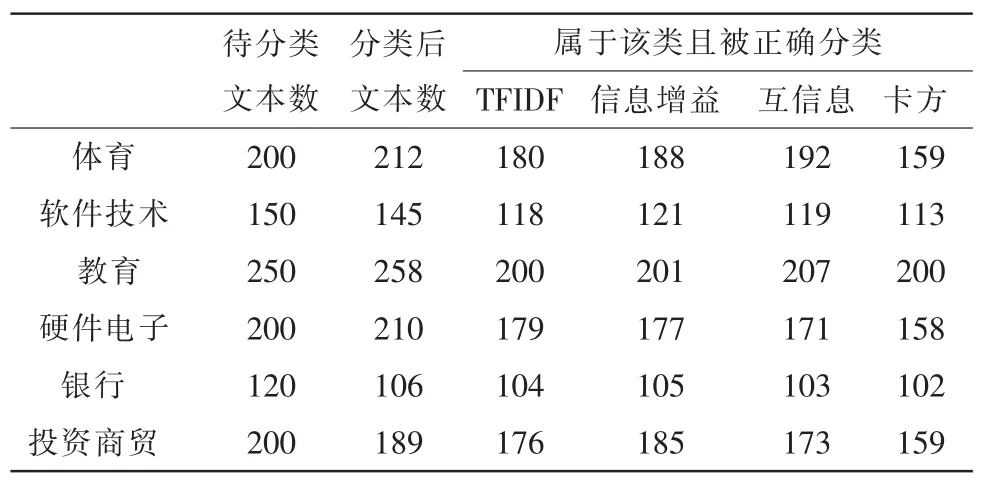
表6 方案3的分类结果Tab.6 Classification results of Plan 3
1)对样本量相对较小且样本特征不明显的样本可以选择TFIDF和卡方特征选择算法;
2)对样本量相对较大且样本特征较明显的样本可以选择互信息和信息增益特征选择算法;
3)对样本量较大且特征很明显的样本四组特征选择的算法都能提高分类的准确率;
6 结束语
通过对不同数量的测试文本集合进行分类训练,研究得出在文本分类方案的预处理过程中,可以针对样本的特征和样本量的大小来选择特征提取的算法,无论样本量的大小还是样本特征明显与否,TFIEF方法相较与其他3种常用分类方法更为适用。
[1]匡春临,夏清强.基于SVM—KNN的文本分类算法及其分析[J].计算机时代,2010(8):29-31.
[2]郝春风,王忠民.一种用于大规模文本分类的特征表示方法[J].计算机工程与应用,2007,43(15):170-172.
[3]陆景辉.基于信息理论的特征选择算法研究 [D].北京:北京交通大学,2007.
[4]许晓昕,李安贵.一种基于TFIDF的网络聊天关键词提取算法[J].计算机技术与发展,2006(3):122-123.
[5]秦进,陆汝占.文本分类中的特征提取[J].计算机应用,2003(2):45-46.
[6]王涛,何聚厚,张娇艳.Naive Bayes邮件过滤模型的特征词选取方法研究[J].航空计算技术,2008(2):131-134.
[7]张治国.中文文本分类反馈学习研究[D].西安:西安电子科技大学,2009.
[8]刘怀亮.基于SVM与KNN的中文文本分类比较实证研究[D].西安:西安电子科技大学,2008.
Research of feature selection methods of web page classification system
TANG Zhe,CAO Xu-dong
(The Earth Physics and Information Engineering Institute,China University of Petroleum(Beijing)Beijing 102249,China)
Accurate classification for a healthy network environment is of crucial importance.Based on the above background,we choose an ideal effect of the SVM classification technique.Considering the different feature selection methods of the classification results of difference,respectively under the condition of the same and different classification samples tested four feature selection methods,research the prominent importance of TFIDF.And we include that selecting the appropriate feature selection method for application to the different classification system is very important.
text classification;SVM;feature selection;TFIDF
TN91
A
1674-6236(2016)05-0120-03
2015-03-27稿件编号:201503391
唐 喆(1990—),女,江苏泰州人,硕士研究生。研究方向:信息安全,数据挖掘。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06 02:49:20
测控技术(2018年4期)2018-11-25 09:46:52
上海精神医学(2017年5期)2017-11-29 06:03:10
电子制作(2017年23期)2017-02-02 07:17:06
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
