
近红外光谱与模型集群分析测定毛涤混纺织物成分含量
2016-09-13 03:24吴淑焕聂凤明梁逸曾3
中国测试 2016年8期
罗 峻,吴淑焕,聂凤明,许 敏,范 伟,梁逸曾3
(1.广州纤维产品检测研究院,国家纺织品服装服饰产品质量监督检验中心(广州),广东 广州 511447;2.湖南农业大学生物科学技术学院,湖南 长沙 410128;3.中南大学化学化工学院,湖南 长沙 410083)
近红外光谱与模型集群分析测定毛涤混纺织物成分含量
罗峻1,吴淑焕1,聂凤明1,许敏1,范伟2,梁逸曾3
(1.广州纤维产品检测研究院,国家纺织品服装服饰产品质量监督检验中心(广州),广东 广州 511447;2.湖南农业大学生物科学技术学院,湖南 长沙 410128;3.中南大学化学化工学院,湖南 长沙 410083)
将近红外光谱法和模型集群分析方法应用于毛涤混纺织物成分含量的快速无损测定。以近红外测量方法采集93个毛涤混纺织物的光谱信号,利用光谱预处理消除信号漂移的影响,在模型集群分析基础上,剔除异常样本,筛选出30个关键波长,采用偏最小二乘法(PLS)建立涤纶含量的预测模型。所建立模型的训练集相关系数r2为0.9827、交互验证均方误差(RMSECV)为3.26、预测均方根误差(RMSEP)为3.34,预测结果令人满意,适合于毛涤混纺织物中涤纶含量的快速、无损检测。
近红外光谱;模型集群分析;毛涤混纺织物;偏最小二乘法
0 引言
当前,我国的纺织品生产、出口和消费均居世界第一。所以无论是政府监管还是企业自检自控,纺织品成分检测的规模都非常巨大。然而,传统的纺织品成分检测方法如化学溶解法和显微镜法等,存在检测时间长,检测环境要求高、使用强酸强碱试剂,检测成本高,需破坏样品等缺点,无法满足各检验监督部门,包括生产企业对纺织品进行大量检测的需求[1-4]。在这种情况下,部分不法企业擅自降低混纺面料中某些纤维成分的含量,偷工减料,以次充好,牟取不当利润,造成不良影响。由近期全国各地公布的质量状况分析结果可看出,不合格纺织品中成分及含量与实际不符的问题最为严重[5]。
基于以上需求,研究和开发一种快速、无损、环境友好的检测方法具有很好的应用前景。近红外光谱(NIR)是一种无损分析技术[6],它将近红外光谱信号与化学分析数据,利用统计回归方法建立预测模型,然后测量未知样品的光谱来快速预测其成分含量[7-8]。质检部门可利用近红外快速检测技术进行初步筛查,对于快检不合格的情况,依法启动抽样检验程序,实现对纺织品企业、原材料加工厂、成衣加工厂以及批发零售终端等大批量的抽检,充分保证国内纺织品的质量[9-10]。
当前,已有关于近红外光谱技术应用于纺织品定量分析中的报道,但相关的研究主要集中在棉/涤、棉/氨等混纺织物[1,3,8-9],毛涤混纺织物报道较少。另外混纺织物近红外光谱检测的目标在于建立一个有效可靠的预测模型,实现对未知样本的含量预测。在实际工作中,这个模型的建立并不容易,由于模型完全未知,建模需要进行探索,并且需要解决异常样本、干扰信息等问题。传统的一次性建模思路容易陷入模型欠拟合与过拟合的状况。而新进发展的模型集群分析打破了传统一次性建模思路,力求最大限度地利用已有样本信息,通过随机采样,从样本空间、变量空间或是模型空间考察数据集的内在性质,基于所得结果的统计分析可进行异常样品的检测、关键波长的筛选和模型的评价等[11-12]。基于此,本研究共收集毛涤混纺织物样本共93个,建立了基于模型集群分析的毛涤混纺织物组分含量的近红外光谱快速无损检测方法。
1 材料与方法
1.1样本
本实验研究的毛涤混纺织物样本共计93个,均为市场购买成品样本。成分含量按照标准 FZ/T 01057系列进行定性鉴别,按照国家标准GB/T 2910系列进行成分含量定量分析。
1.2光谱信号的采集
信号采集来源为近红外光谱仪(ANTARIS II,Thermo fisher),样品采用漫反射方式测量,为保证样品信号的代表性,每个样品测量3次并取3次平均值作为其光谱信号数据,信号采集时室内温度为20℃,湿度为60%。
1.3方法与原理
模型集群分析。模型集群分析的算法框架主要包括3个基本要素:1)通过随机采样获取子数据集;2)针对每个子数据集,建立相应子模型;3)从样本空间、变量空间、参数空间或模型空间对所有建立的集群子模型的参数与结果进行统计分析,获取有用信息[13]。
应用该算法框架可以进行异常样品的检测、关键波长的筛选和模型的评价。基于模型集群分析的异常样本识别方法可克服不同异常样本的掩蔽效应,有效识别光谱信号及化学分析数据的异常值。具体算法如下:采用随机分组的方式,将样本集分为70%的训练集和30%的测试集。采用训练集样本建立回归模型并对测试集样本进行预测,重复该过程多次(本研究为3000次),可得每个样本预测误差的统计分布,计算每个样本的残差分布均值μ和标准偏差б并作图,预测误差分布的均值或偏差异常的样本即被识别为异常样本[14]。
基于模型集群分析的波长筛选方法可显著提高近红外分析预测的准确度。因为近红外光谱数据的共线性非常严重,其波长点数为几百个至上千个。如此多的波长点数不仅存在着信息的冗余,而且部分波长的信号可能为干扰信息,对预测不利。因此,在建立预测模型时也需要对近红外光信号进行波长的筛选。对于毛涤混纺织物的关键波长筛选,我们设计了一种基于模型集群分析的新方法:MPA-PSO方法。PSO(粒子群优化)是一种源于对鸟群捕食行为研究的进化计算技术[15]。是一种基于叠代的优化工具,系统初始化为一组随机解,在解空间通过叠代搜寻最优值。在PSO中,每个优化问题的潜在解都可以想象成D维搜索空间上的一个点,可称之为“粒子”,所有的粒子都有一个被目标函数决定的适应值,每个粒子还有一个速度决定他们飞翔的方向和距离,然后粒子们就追随当前的最优粒子在解空间中搜索。PSO方法实现较为简便,本研究基于模型集群分析框架,通过随机采样,获得不同的子数据集,然后对每个数据集进行PSO关键波长筛选,根据选出波长的频率来确定最终关键波长。
1.4数据处理
本文所采用的光谱信号处理及回归等程序均在Matlab R2015b环境下运行。
2 结果与分析
2.1样本的划分
在多元校正模型的建立及验证时,需要将数据样本划分为训练集和独立测试集。训练集用来优化参数建立模型,独立测试集不参与建模过程,仅用来验证模型的预测效果。本文采用Kenard-Stone样本选择方法,从总计93个毛涤织物样本中筛选出具有代表性的80个样本用于训练模型,13个样本用于测试模型。
2.2光谱的预处理
在进行混纺织物的近红外光谱检测时,一般采用积分球漫反射的模式测量。测量过程中虽然尽量保持了环境条件的一致,但是混纺织物其表面结构、平整性、厚度等不同因素会干扰光谱信息。从图1中亦可以看出,近红外信号的漂移非常严重,对近红外光信号进行适当预处理可以干扰因素引起的信号漂移及旋转等噪声,从而提高信噪比,为建立预测模型提供有效信息。在本研究中,选择5点2次多项式Savitsky-Golay一阶微分法进行处理,处理后光谱如图2所示。对比图1和图2可看出,经过预处理后,明显消除了信号的整体漂移,强化了谱带特征,处理后的光谱更适宜于预测模型的建立。
2.3异常样本的检测
依据模型集群分析的思路,为最大限度地利用已有训练集样本信息,可通过随机采样,从样本空间考察数据集的内在性质,根据所得结果的统计分析进行异常样品的检测。因此在本研究中,采用随机分组方法对训练集重复进行分组,每次取总数70%的样本来回归预测模型,30%进行测试。重复3000次,每个样本均得到多个预测值。计算多个预测值误差的平均值与标准方差并绘图,如图3所示。可以看出,有样本预测误差均值明显偏高,如13号样本。或是预测误差的方差较大,如34及77号样本。经验证,13号样本为机织黑色布料,其表面具有装饰嵌条,34号样本为混色格子布料,77号样本为呢料,表面起圈不平整。将此3个异常样本剔除后建立回归模型,并与全样本预测模型作了比较,剔除后,交互验证均方根误差(RMSECV)由全样本的5.27降低到4.62,预测的准确度明显提高。
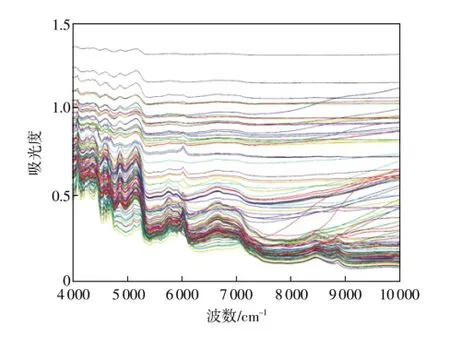
图1 毛涤混纺织物的近红外光谱图

图2 毛涤混纺织物的一阶微分光谱图
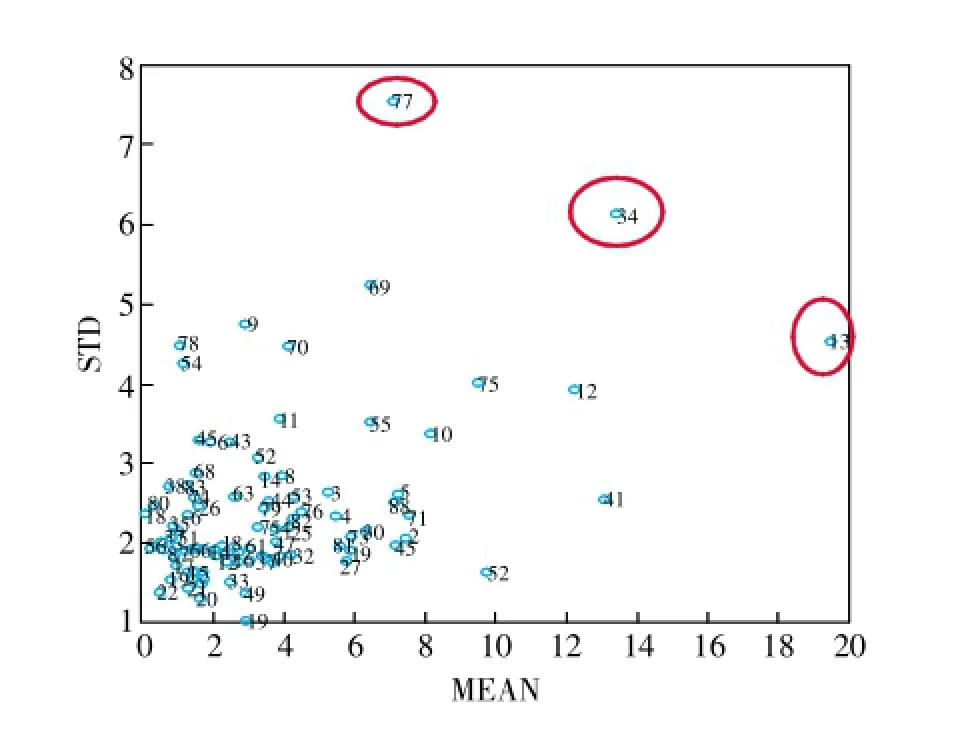
图3 均值―方差分布图
2.4关键波长优选
近红外光谱信号存在较为明显的信息冗余,因此通过优选波长可以提高模型的预测能力与适用性。本研究采用MPA-PSO法对毛涤混纺织物的关键波长进行筛选,PSO具有深刻的智能背景,同其他优化算法比较,PSO简单易实现且没有过多参数需要调整。运行时首先设置粒子群搜索参数:粒子种群大小为50,迭代次数为200,算法运行10次,以F=Q2作为适应度函数,Q2为交互验证预测值和量测值的相关系数。重复选择3000次后,对选出的波长进行统计分析,最终选择频率大于50%的30个波长作为其关键波长。30个关键波长具体为:4 034,4 177,4204,4 281,4 756,4 968,4 972,4 975,5 095,5 099,5 103,5 295,6 044,6 113,6 117,6 144,6 198,8 632,8 748,8 751,9 118,9 280,9 338,9 507,9 608,9635,9696,9700,9800,9812cm-1。
利用30个关键波长建立预测模型的结果表明,经过波长筛选后,预测误差有所降低,关键波长预测模型的交互验证均方差值为之前的70.4%。而且,波长数量由原始的1557个减少到30个,减少了数据处理的工作量,可见MPA-PSO法应用于波长筛选来处理近红外信号可有效简化模型并提高校正模型的预测能力。
2.5模型建立与预测
采用未参与模型建立的独立测试集样本对模型的预测效果进行测试和验证。首先采用预处理方法对样本信号进行处理,然后调用训练集样本建立PLS模型,并对未参与建模的独立测试集样本进行预测,回归模型的测试集相关系数为0.982 7,预测均方根误差为3.34,交互检验均方差为3.26,结果令人满意。近红外预测值与化学分析测定值之间的相关关系如图4所示。
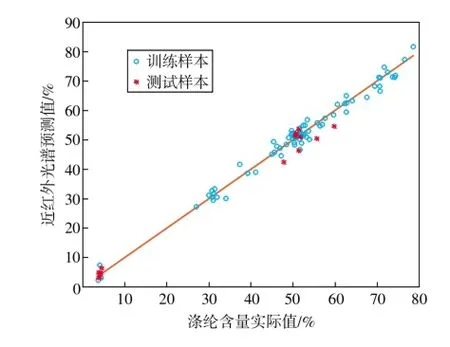
图4 真实值与近红外预测值之间的相关图
3 结束语
基于近红外光谱和模型集群分析对毛涤混纺织物中涤纶含量进行了快速无损检测研究,在模型集群分析框架下,剔除了一些异常样本,并筛选出了关键波长,利用关键波长进行偏最小二乘回归建模,预测误差较小,表明近红外光谱结合模型集群分析适合于毛涤混纺织物中纤维成分的快速、无损检测,而且能达到令人满意的检测精度,为今后混纺织物的快速无损检测提供了新的选择。
同时,在本研究中注意到混纺织物样品复杂度较大,成分含量跨度同样较大,下一步计划开展分段动态建模研究,以进一步提高预测准确率。
[1]桂家祥,耿响,要磊,等.基于近红外光谱法的棉/涤混纺纺织物中棉含量快速检测[J].纺织学报,2012,33(4):55-59.
[2]王京力,耿响,桂家祥.基于近红外光谱法快速检测涤氨织物的纤维含量[J].上海纺织科技,2013,41(5):45-48.
[3]钟浩,杨伟江.运用近红外光谱定量分析纺织面料成分的可行性探讨[J].中国纤检,2008(2):46-47.
[4]冯红年,甘彬,金尙忠.棉涤混合纺织面料含量的近红外光谱检测[J].激光与红外,2005,35(10):768-770.
[5]虞学锋.服装产品纤维成分含量项目质量状况分析[J].中国纤检,2014(10):28-29.
[6]陆婉珍.现代近红外光谱分析技术[M].北京:中国石化出版社,2006.
[7]梁逸曾.白灰黑复杂多组份分析体系及其化学计量学算法[M].长沙:湖南科学技术出版社,1996:32-36.
[8]王动民,金尙忠,陈华才,等.棉-涤混纺面料中棉含量的近红外光谱分析[J].光学精密工程,2008,16(11):2051-2054.
[9]朱洪亮,杨萌,张琦.棉/氨混纺织物氨纶含量快速分析方法研究[J].中国纤检,2011(24):54-58.
[10]耿响,桂家祥,要磊,等.近红外光谱快速检测技术在纺织领域的应用[J].上海纺织科技,2013,41(4):25-27.
[11]王京力,桂家祥,耿响,等.近红外光谱检测用纤维含量样品准确度研究[J].上海纺织科技,2013,41(9):51-54.
[12]柴金朝,金尙忠.光谱预处理对棉涤混纺面料近红外定量模型的影响[J].中国计量学院学报,2008,19(4):325-328.
[13]梁逸曾,许青松.复杂体系仪器分析-白灰黑分析体系及其多变量解析方法[M].北京:化学工业出版社,2012.
[14]CAO D S,LIANG Y Z,XU Q S.A new strategy of outlierdetection for QSAR/QSPR[J].Journal of Computational Chemistry,2009,31(3):592-602.
[15]KHAJEH A,MODARRESS H,ZEINODDINI-MEYMAND H.Application of modified particle swarm optimization as anefficient variable selection strategy in QSAR/QSPR studies[J].Journal of Chemometrics,2012,26(11-12):598 -603.
(编辑:徐柳)
Study on rapid determination of polyester content in polyester/wool based on near infrared spectroscopy and model population analysis
LUO Jun1,WU Shuhuan1,NIE Fengming1,XU Min1,FAN Wei2,LIANG Yizeng3
(1.Guangzhou Fibre Product Testing and Research Institute,Guangzhou 511447,China;2.College of Bioscience and Biotechnology,Hunan Agricultural University,Changsha 410128,China;3.College of Chemistry and Chemical Engineering,Central South University,Changsha 410083,China)
Near-infrared spectroscopy as a rapid,non-destructively testing technique,has been widely used in the fiber product testing field.93 polyester/wool samples were collected.Model population analysis method was employed to detect the outlier and select key variables after preprocessingthespectrabySavitsky-Golayderivativemethod.Partialleastsquares(PLS)calibration models were established by the optimal conditions to predict the content of polyester. Correlation coefficient of determination r2,root-mean-square error of cross-validation(RMSECV)and root-mean-square error of prediction(RMSEP)were used to evaluate the quality of the model. The best models showed satisfactory predictions as measured by the r2,RMSECV and RMSEP values:0.982 7,3.26 and 3.34.The prediction results were better than the whole spectra The results showed that the method was suitable for the fast and reliable determination of the content of polyester in polyester/wool product.
near-infrared spectroscopy;model population analysis;polyester/wool;PLS
A
1674-5124(2016)08-0044-04
10.11857/j.issn.1674-5124.2016.08.009
2015-12-28;
2016-02-19
国家自然科学基金项目(21275164);国家质检总局科技计划项目(2013QK290);广州市海珠区科技计划项目(2013-cg-08)
罗峻(1983-),男,广东广州市人,博士,主要从事纺织品检测新技术研发、新型检测仪器研发工作。
范伟(1983-),男,河北邢台市人,博士,主要从事光谱分析与化学计量学研究。
猜你喜欢
纺织学报(2021年11期)2021-11-29
毛纺科技(2021年8期)2021-10-14
阅读(科学探秘)(2021年8期)2021-09-01
纺织科技进展(2021年3期)2021-06-09
染整技术(2020年9期)2020-10-24
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
中南大学学报(自然科学版)(2016年2期)2017-01-19
