
基于移动端图像识别的题库采集模型实践研究
2016-09-10 07:22:44黄毅晟
中国信息技术教育 2016年12期
摘要:借助图像识别技术,我们不仅可以通过图片搜索更快地获取信息,还可以产生一种新的与外部世界交互的方式,甚至会让外部世界更加智能地运行。本文通过对题库建设中采集题库的现状进行分析,给出了基于移动端图像识别的题库建设方案。
关键词:图像识别;OCR;题库采集;移动终端;特征建模
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2016)12-0075-04
● 采集题库的现状
随着经济和社会的发展、“互联网+”的广泛应用及教育观念的更新,我们迫切需要科学、方便、完善的网络型题库管理系统。试题库建设是教育现代化的需要,是考教分离、最大限度提高办学效益的需要,因此,进行区域网络试题库系统的建设和研究具有十分重要的意义。
受限于教材版本和区域应用层面的需求,采购商业化的题库并不能完全满足教育教学的实际要求。手握大量纸质试卷的老师们,迫切需要一个录入神器,方便快捷地将其录入到题库系统里。
利用基于移动终端的图像文字识别技术将文字和图片迅速录入题库是我们在移动端系统开发的应用亮点。它能够大幅提高对质量不高图像的识别率,其关键算法对图像的噪声、亮度明暗不一致和规格凌乱的问题进行了很好的处理。它能够将图像上传到服务器进行在线识别,在识别过程中先对图像进行消噪,然后对亮度进行均衡处理及对图像阈值分割,提高了图像识别的成功率。
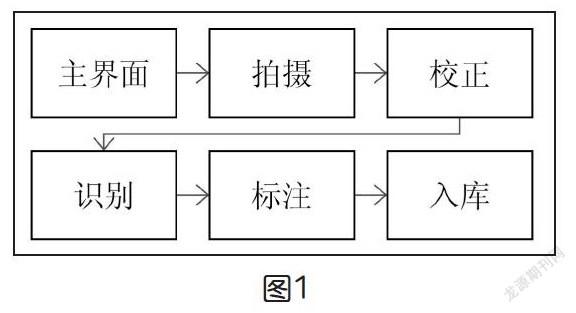
● 题库采集系统工作流程
题库采集主要分为图像采集、图像识别和标注三个过程。整体的工作流程包括:①系统启动,进入主界面,可选择开始拍摄阅卷或读取设备中已有的图像,如选择拍摄题目,进入图像采集模块,调用移动设备的摄像头进行拍摄,拍摄成功后,跳转至识别界面,如选择读取相册已有图像也跳转至识别界面。②在识别界面上显示出拍摄或者读取的相册图像,首先调用图像预处理模块对图像进行预处理,输出预处理后的图像,然后调用图像校正模块对预处理图像进行校正,输出校正图像,最后调用图像识别模块对校正图像进行识别,输出识别结果。③调用标注模块对识别结果进行分类管理,为题目添加系统属性,如学科、章节、知识点类目、题型、难度系数等标签。图1为题库采集系统工作流程示意图。
● OCR智能模型设计思路
在人工智能领域,模拟人类图像识别活动的计算机程序,人们提出了不同的图像识别模型——模板匹配模型。这种模型认为,识别某个图像,必须在过去的经验中有这个图像的记忆模式,又叫特征模型。当前的刺激如果能与大脑中的模型相匹配,这个图像也就被识别了。例如,有一个字母A,如果在脑中有个A模板,字母A的大小、方位、形状都与这个A模板完全一致,字母A就被识别了。图像识别中的模型识别(Pattern Recognition)利用计算机和数学推理的方法对形状、模式、曲线、数字、字符格式和图形自动完成识别、评价的过程。
那么如何通过模型的学习提高OCR的智能判断水平呢?我们主要从以下三个方面做了实践研究。
1.采集识别优化
(1)二值化处理
二值图像在数字图像处理中占重要地位,其在处理实际图像过程中地位更加突出。要应用二值图像,扫描文档之后的第一步就是对灰度图像根据所选阈值进行二值化处理。二值图像是像素值为0或255的像素点集合,如此一来,图像的数据量大大减少,但图像的基本轮廓信息得以保留。此项的关键是所选取的阈值是否得当,不当则会减弱二值图像的处理效果。常用的阈值选取方法有固定阈值法、平均阈值法、直方图法、Means法四种。
谷歌公司在HP公司Tesseract光学字符识别引擎的基础上做了深度加工,其中对阈值的自适应分类器和两步矫正法的应用大大提高了文本的识别效率。近几年来,百度针对商业运用开发了自然场景OCR API服务,依托百度的OCR算法,提供了整图文字检测、识别、整图文字识别、整图文字行定位和单字图像识别等功能。目前火热的作业帮APP就是基于百度识别API做的延伸产品(如图2)。
(2)图像去噪与矫正
任何一幅原始图像,在其获取和传输的过程中,都会受到各种噪声的干扰,使图像质量下降,淹没其特征,对图像分析非常不利。为抑制噪声、改善图像质量所进行的处理被称为图像平滑或去噪。

图像平滑是用于突出图像的宽大区域和主干部分(低频部分)或抑制图像噪声和干扰(高频部分),使图像平缓渐变,减小突变梯度,改善图像质量的图像处理方法。它属于图像增强的一部分,主要的图像平滑方法有均值滤波、中值滤波、灰度形态学滤波、小波滤波、高斯低通滤波以及统计方法滤波。
已获得的文本图像有些不可避免地会发生倾斜,这样会给后面文字的行切分和列切分以及文字的识别带来困难,所以需要对获取的图像进行倾斜校正。图像的倾斜校正最关键的是倾斜角的检测,我们主要采用平行四边形法进行文本图像的校正(如图3)。根据拍摄者给出的一系列文件位置点,用位置点的坐标结合模型拟合出文本线,根据文本线与水平线之间的差距进行精确恢复,以得到水平分布的文本行。
2.特征提取与建模
特征提取是图像识别的重要步骤,为了保证后续处理的质量,生成的特征要具备描述物体的典型特性,如独特性、完整性、几何变换下的不变性、灵敏性以及抽象性。我们设计的系统的特征模型包括文字特征、图片特征、公式特征等。
提取图像特征关系可以有两种方法:一是对图像进行合理地分割,划分出图像中所包含的对象或区域,然后根据这些区域提取图像特征,并建立索引;二是简单地将图像均匀地划分为若干规则子块,然后对每个图像子块提取特征,并建立索引。
图像特征建模的基本原则是根据图像的视觉内容和可获得的指导信息来确定对应的文本语义描述。在图像标注任务中会涉及两种不同的媒体:一是图像,二是文本。这两种媒体具有良好的互补性,可以协作传递信息,正所谓“图文并茂”。由这两种媒体可以产生4种关系,即图像间关系(IIR)、词间关系(WWR)、由图像到词的关系(IWR)和由词到图像的关系(IR)。
3.基于标注模型的学习与训练

我们通常采用两两图像之间的视觉相似性(pairwise similarity)来建立以图像为节点的相似图,但这种方式由于没有考虑到数据集或某个数据子集内的结构分布信息,效果不能令人满意。因此我们引入了第二个以词为节点的图学习过程,用来实现对图像标注的改善。
最常见的是属性相关性,如“李白”是“古诗文”的关系。除此之外,词汇之间还存在多种相关性,如“凸透镜”与“光”之间有着很强的联系,这种相关性不依赖于特定数据集,它是人们在生活中大量知识的积累和反映。当一幅图像已被标为“凸透镜”“光”等词汇后,初中物理作为该图像标注词汇的概率就会相应提升。为了获取这种相关信息,一种方法是从训练数据集中利用已标注词汇间的共生概率来计算词汇间的关系。该方法基于已标注信息,相对准确,但它不能反映更广义的人的知识。于是,我们可以采用另一种方法,利用具有大量词汇的、包含了人的知识的结构化电子词典来计算词汇间的关系。与统计方法相比,词典包括了更加完整的大数据关联信息。由此我们设计了基于标注的模型学习体系(如下页图4),通过提取题目图像的特征点绑定其隐形属性,再与拍摄者提供的显性属性做比对,进行数据建模,并引导系统修正其三大特征库(文字、图片、公式),实现自我学习。
需要注意的是,基于标注信息描述由图到标签的关系,更适合按照多标记分类(multilabel classification)问题来解决。具体而言,假设标注词汇服从多项式分布,由此将图像标注归为多类别分类问题,而题库的分类方式恰恰符合这样的多标记模型(相对固定是显性标签:学科、学段、知识点、章节、难度等)。
● 注意事项
1.基于API方式的接入能使产品得到快速开发
例如,当前百度通过专业服务分发平台APIStore开放百度文字识别技术,让开发者可以零成本使用基于移动应用的OCR技术,为开发者创新应用提供了更多的选择。
2.题库特征建模要考虑学科特征
实践证明,文科和理科的题目有着截然不同的特征属性,如语文更注重词汇与语法方面的训练,而数学包含了大量的公式和二维化的图像。往往数学在小学和中学阶段的题目也会表现出不同的特征属性,在建模的同时要注意抽取。
3.未来的方向是要构建基于题库图像模型的题库推送规则
当题库的建构达到一定数量之后,我们要将图像和翻译成的题目都保存下来,再根据拍摄者的需求做相关的推送,根据其使用的情况(如点击率、评价等)再对模型进行修正。
从目前的技术发展角度看,突破性来自于机器语言翻译方面的研究成果:通过一种递归神经网络(RNN)将一种语言的语句转换成向量表达,并采用第二个RNN将向量表达转换成目标语言的语句。而谷歌将以上过程中的第一种RNN用深度卷积神经网络CNN取代,这种网络可以用来识别图像中的物体。此种方法可以实现将图像中的对象转换成语句,对图像场景进行描述。概念虽然简单,但实现起来十分复杂,科学家表示,目前实验产生的语句合理性不错,但还远谈不上“完美”,这项研究目前还处于起步阶段。相信在不久的将来此项发明将应用于教学领域,那么基于云模式下的图像识别系统将得到一个质的飞跃,它也将使图像识别与深度学习更加紧密地联系在一起,最终实现系统对互联网上教育资源摘取和自学习的强大功能。
参考文献:
[1]黄明明.图像局部特征提取及应用研究[D].北京:北京科技大学,2016.
[2]刘淼,杨镇豪,谢韵玲,谢冬青,唐春明.Android图文同步识别系统的设计和实现[J].计算机工程与设计,2014(06).
[3]李龙卓.基于形状特征的图像检索技术研究[D].青岛:青岛科技大学,2015.
[4]付芦静,钱军浩,钟云飞.基于汉字连通分量的印刷图像版面分割方法[J].计算机工程与应用,2015(05).
[5]陈珍,夏靖波,柏骏,徐敏.基于进化深度学习的特征提取算法[J].计算机科学,2015(11).
作者简介:黄毅晟,教育信息化研究员,研究方向为教育应用系统开发、教育技术应用研究。
猜你喜欢
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2018年19期)2018-11-14 02:37:04
电子制作(2018年14期)2018-08-21 01:38:16
电子测试(2017年23期)2017-04-04 05:06:50
出版广角(2016年21期)2017-01-07 19:12:58
现代商贸工业(2016年25期)2016-12-26 14:40:05
黑龙江教育学院学报(2016年11期)2016-12-23 21:10:10
电子技术与软件工程(2016年20期)2016-12-21 11:03:45
人间(2016年27期)2016-11-11 17:32:55
