
一种基于最优策略概率分布的POMDP值迭代算法
2016-09-02 08:08王崇骏
电子学报 2016年5期
刘 峰,王崇骏,骆 斌
(1.南京大学软件学院,江苏南京 210093;2.南京大学计算机科学与技术系,江苏南京 210093;3.南京大学软件新技术国家重点实验室,江苏南京 210093)
一种基于最优策略概率分布的POMDP值迭代算法
刘峰1,3,王崇骏2,3,骆斌1,3
(1.南京大学软件学院,江苏南京 210093;2.南京大学计算机科学与技术系,江苏南京 210093;3.南京大学软件新技术国家重点实验室,江苏南京 210093)
随着应用中POMDP问题的规模不断扩大,基于最优策略可达区域的启发式方法成为了目前的研究热点.然而目前已有的算法虽然保证了全局最优,但选择最优动作还不够精确,影响了算法的效率.本文提出一种基于最优策略概率的值迭代方法PBVIOP.该方法在深度优先的启发式探索中,根据各个动作值函数在其上界和下界之间的分布,用蒙特卡罗法计算动作最优的概率,选择概率最大的动作作为最优探索策略.在4个基准问题上的实验结果表明PBVIOP算法能够收敛到全局最优解,并明显提高了收敛效率.
部分可观测马尔科夫决策过程;基于最优策略概率的值迭代算法;蒙特卡罗法
1 引言
规划问题,即“设计合理的行动计划以达到个体目标”[1],是人工智能研究里的重要领域.序列决策问题(Sequential Decision Making)是规划问题的一个重要子领域.而动态不确定性环境下的行动规划是其中的热点,其动态性和不确定性是在这种环境下进行行动规划的主要难点.
部分可观察马氏决策过程(Partially Observable Markov Decision Process,POMDP)是一个强大的数学框架,可以用来描述并解决很多实际的不确定环境中序列决策问题,例如机器人探索任务[2]、口语对话管理[3]、服务漂移[4]、传感器调度[5]等.
精确求解POMDP问题计算复杂度过高,难以应用于实际问题,因此出现了各种近似算法如FIB[6]、MA-Q-learning[7]等等.其中基于点的值迭代方法在可达信念点集上进行迭代,通过增加迭代次数提升了整体效率,使得POMDP可以应用到较大规模的问题并在实际应用中取得了良好的效果.自从基于点的值迭代方法PBVI[8]提出之后,对探索信念点集的启发式探索方法成为了研究热点.PEMA[9]算法选取误差最大的后继点,使点迭代尽可能近似精确迭代;HSVI[10]、SARSOP[11]、GapMin[12]、PGVI[13]等算法根据最优值函数上界来选择最优动作探索最优可达信念点集,保证收敛到全局最优;AEMS[14]、HHOP[15]等算法构造启发式函数选择最优动作探索最优可达信念点集,提高了收敛效率.
为了解决较大规模的POMDP问题,近年来基于点的算法通过探索最优可达信念空间来提高算法的效率.为了保证值函数能够收敛到全局最优解,HSVI等算法在探索最优可达信念空间时,根据IE-MAX[16]原则选取值函数上界最大的动作.但值函数的上界通过线性规划等方法来计算,其收敛效率很低,而值函数下界基于贝尔曼方程进行迭代收敛效率较高.HSVI等算法虽然可以在理论上保证收敛,但在选择最优动作时仅以值函数上界为参照而完全不考虑值函数下界的取值情况,降低了值函数下界的迭代收敛效率,从而影响了算法的整体收敛效率.为保证高效地探索到全局最优解,HHOP算法设计了有前景的策略再结合最优值函数上界构造了两个独立的启发式搜索函数进行杂合以探索最优可达信念空间.本文提出基于最优策略概率的值迭代算法(Probability-based Value Iteration on Optimal Policy,PBVIOP)来提高全局最优解的收敛效率.在探索最优可达信念空间时,PBVIOP算法和HHOP算法一样都考虑了值函数的上界和下界,不同之处在于HHOP算法在每次探索时是把有前景的策略和值函数上界分隔开来各自考虑后再杂合;而PBVIOP算法在每次探索时先结合动作值函数的上界和下界来探索最优策略,再贪婪探索其不确定性最大的后继信念点,相比之下HHOP算法更为细致复杂.PBVIOP算法在探索最优可达信念空间方面有如下特点:首先,在寻找最优策略的过程中同时参考动作值函数的上界和下界,保证算法的收敛质量和效率;其次,把选择最优动作建模成基于各个动作值函数的分布求最大值函数的问题,以各个动作值函数最大的概率作为选择最优动作的标准,保证了算法的可靠性和稳定性;最后,引入蒙特卡罗方法来近似计算动作最优的概率,使得算法合理且高效.算法在选择最优动作时避免了局部化的干扰,可以稳定达到全局最优.试验结果表明PBVIOP算法优于HSVI和GapMin算法的性能,且随着POMDP问题规模的扩大其优势愈加显著.
2 背景和相关工作
2.1POMDP模型
POMDP模型可以表示为一个八元组(S,A,Z,b0,T,O,R,γ)[8].其中S是一个隐含状态的有限集合,表示了系统所有可能处于的状态;A是一个动作的有限集合,包括Agent能够采取的所有动作;Z是一个观察的有限集合,表示Agent所有可能的输入;b0是初始的状态分布,表示在初始时刻t0系统在状态集合S上的概率分布;T(s,a,s′)是状态到状态的转移概率,描述Agent在状态s采取动作a后到达状态s′的概率,表明了动作的随机效应;O(a,s′,z)是Agent采取动作a到达状态s′后且观察到z的概率,模拟了Agent部分可观测的特性;R(s,a)是在状态s时采取动作a所获得的回报值;γ∈(0,1)γ∈(0,1)是折扣因子.
在POMDP中,Agent不能直接获取自己的状态而只能从环境中获得观察信息作为状态的参照,所以它必须根据动作和观测的历史序列{a0,z1,a1,z2,a2,z3,…,at-1,zt}来决策下一个动作at.因此POMDP引入维持历史信息的充分统计量b来代替历史序列以计算其长远回报[17].b是一个代表状态上概率分布的向量:
bt(s)=P(st=s|zt,at-1,…,a0)
在POMDP中t时刻的信念点bt可以根据贝叶斯规则来更新,只涉及前一步的信念状态bt-1,最近采取的动作at-1和得到的观测zt,因而b的更新具有Markov性.
bt(s′)=τ(bt-1,at-1,zt)
2.2POMDP求解
POMDP中的策略是一个由信念到动作的映射:π(b)→a.Agent在策略π下的长远回报为:
POMDP的求解是指POMDP模型完全已知(状态集合、动作集合、转移函数、回报函数等)的情况下计算最优策略π*,它能够最大化长远回报的期望.最优策略可以由贝尔曼方程迭代获得.Q值函数Qt+1(b,a)是t步视野内在当前信念点b处执行动作a的回报值:
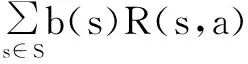
其对应的最优策略可以表示为:
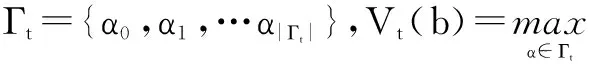
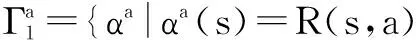
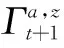
再将这些集合与一步回报集合笛卡尔和相加得到某一动作a所对应的向量:

其中笛卡尔和⊕定义为:

最后得到所有动作向量集合:
反复update至Гn收敛即可精确求解POMDP问题.每次update的计算复杂度近似为O(|S|2|A||Гt||Z|)[17],因而精确求解存在着历史灾和维度灾的问题.虽然Witness算法和增量裁剪算法等对精确算法有所改进,但在极端情况下计算复杂度还是不能降低.
2.3基于点的POMDP近似求解
对于大部分的POMDP问题,Agent所能到达的信念点集合B往往只是信念空间的一小部分,因此可以用基于点的算法来求得其误差在一定范围之内的近似解,避免精确求解中计算笛卡尔和的巨大计算量,通过增加迭代次数保证算法效果.
基于点进行backup和精确算法的update的比较如图1所示.精确求解算法在整个信念空间上进行,所以无法先行确定动作a之后各个观察下的最优向量,只能选取所有可能的向量作笛卡尔和,因而计算量很大.基于点的方法中,执行动作a之后的每个观察下的最优向量都可以先行确定,从而可以根据|Z|个观察所对应的最优向量计算出执行动作a的回报值,再比较得出回报值最高的最优动作,最后通过backup操作得到b在一次更新后的最优向量.
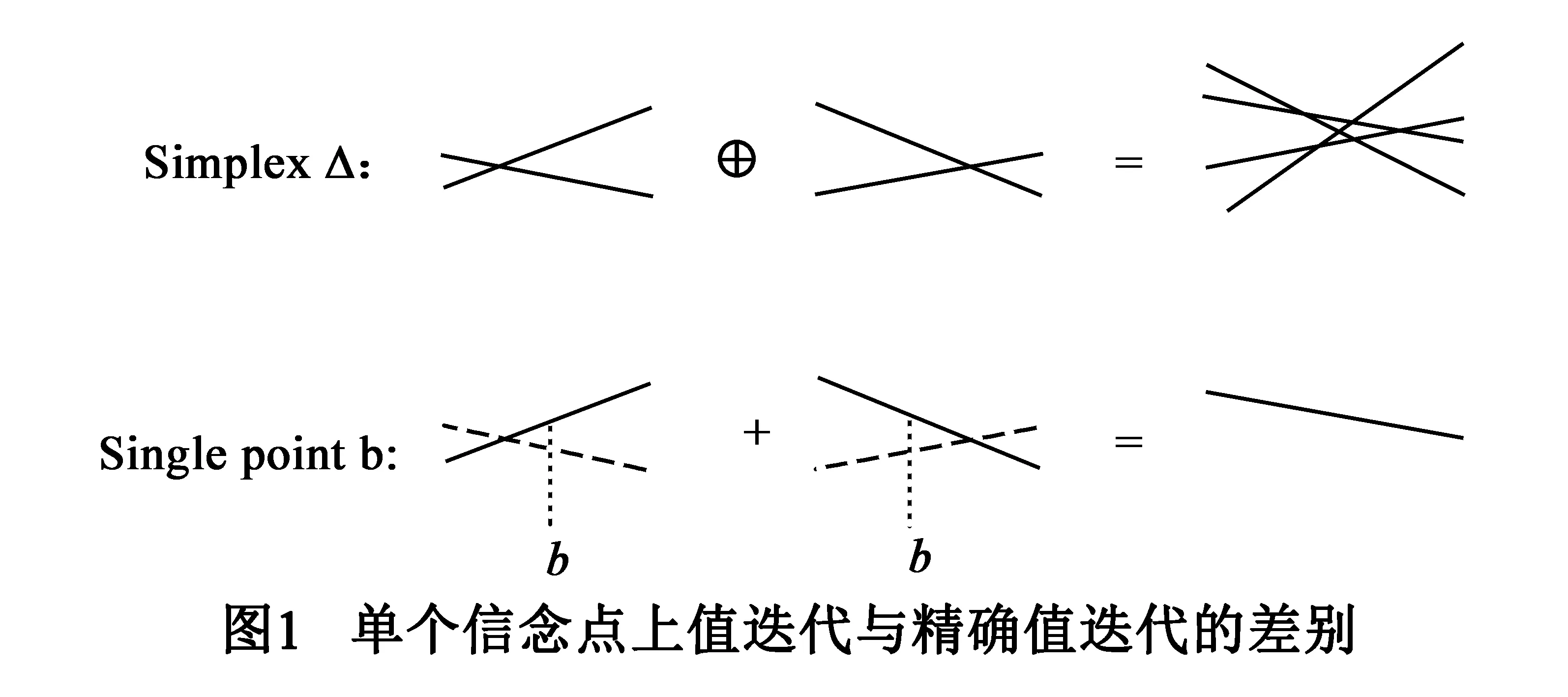
在点集B上由Гt构建Гt+1过程如下:
在点集B上进行一次backup的计算复杂度近似为O(|S|2|A||Z‖B|2).基于点的方法在达到终止条件之前反复执行两个步骤:探索新的信念点来扩张信念点集合B;在B上更新值函数Γ.各种基于点的值迭代方法的主要差别在于不同的信念点集探索方法[18].
2.4最优策略下的可达区域
基于点的算法的核心思想是可到达区域的概念.可到达区域R(b0)是从初始信念点b0经过任意动作和观察序列能够到达的信念点集合[8].但第t步时R(b0)中增加信念点的数量级为(|A‖Z|)t,随着步数t的增加R(b0)的规模也较为可观.R*(b0)是从b0开始按照最优策略所到达信念点的集合[19],第t步时R*(b0)中增加信念点的数量级为|Z|t.如图2所示,R*(b0)的规模远小于R(b0),因而在较大规模的问题中基于R*(b0)采样更加高效.
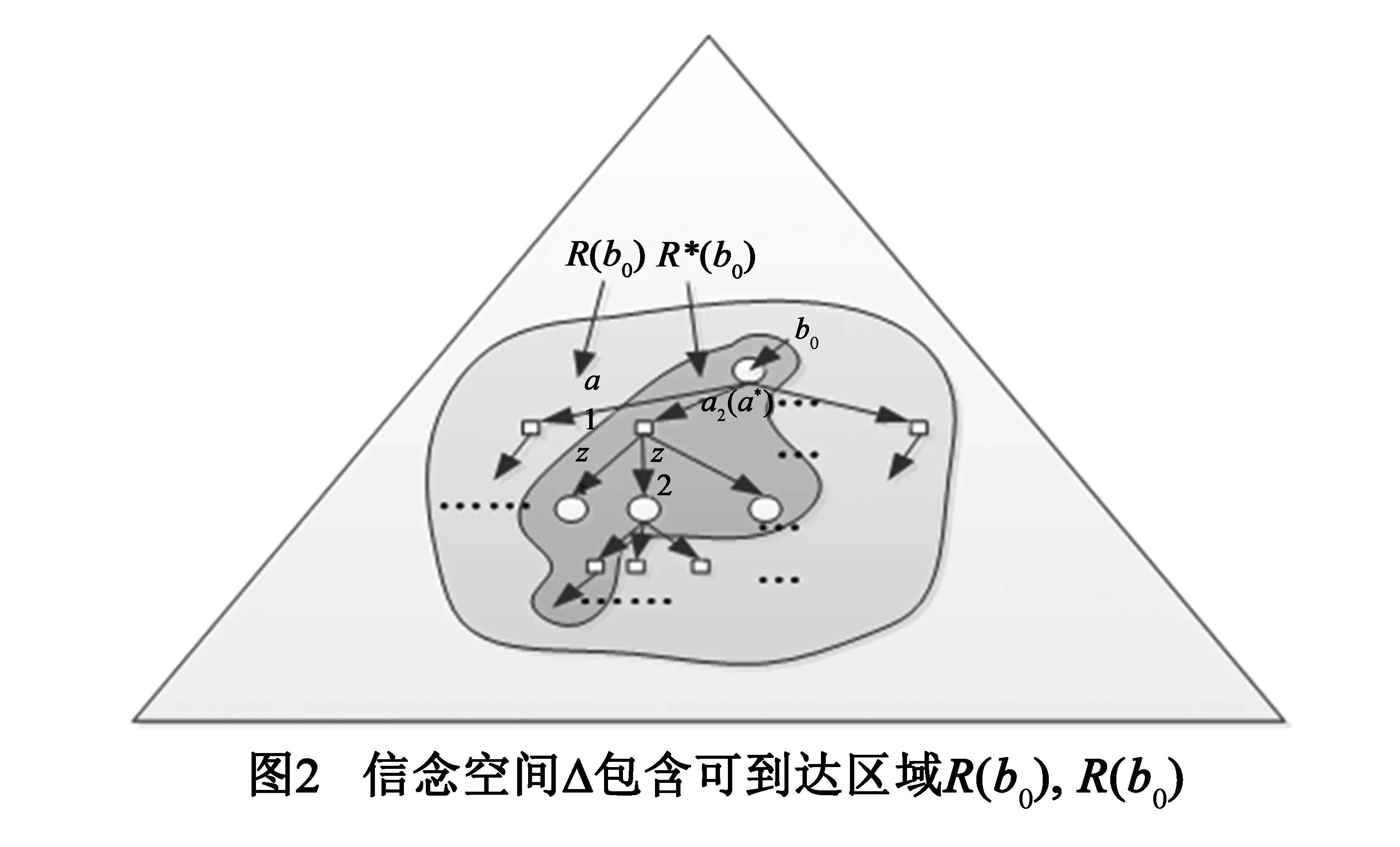
尽管R*(b0)规模相对较小,但足以用于计算出b0处的最优策略[19].然而最优策略无法预知,所以一般通过启发式的方法来对R*(b0)进行近似.
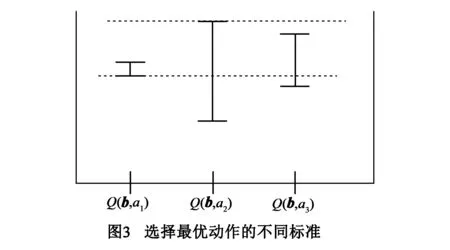
已有的基于点的近似算法在探索R*(b0)时尝试了不同的选择最优动作的标准.如图3所示,信念点b处有3个可供选择的动作a1、a2、a3,其动作值函数Q(b,ai)分别在各自的下界和上界之间取值.在此例中PEMA等算法根据动作值函数下界的最大值会选取动作a1作为最优策略;HSVI等算法根据动作值函数上界选择动作a2作为最优策略.
3 PBVIOP算法
3.1算法思想
目前已有的R*(b0)近似算法仍有改进的空间.PEMA算法仅根据值函数下界选取最优动作,则值函数下界取值较高的信念点更可能会被探索到,然后在该点上的backup操作又只会使得该点附近区域的值函数下界会有所提升而其他信念区域的值函数下界几乎没有提升,从而在下一次的探索中该点附近区域的信念点又会被优先探索到,因此算法不能保证值函数收敛到全局最优解.HSVI等算法根据IE-MAX原则只根据值函数上界值最大来选择动作,上界在更新中不断降低,因而即使在某次迭代中只是找到了次优动作也不会影响值函数最终能够收敛到全局最优.但值函数的上界通过线性规划或sawtooth算法[10]来近似计算,其收敛速度非常缓慢,HSVI等算法虽然在理论上保证收敛,但在选择最优动作时完全不考虑迭代收敛效率较高的值函数下界,影响了整个算法的收敛效率,不利其应用于大规模的POMDP问题.
事实上动作值函数在上界和下界之间取值,单单以上界或下界的值来评估动作值函数都是片面的.在图3的示例中,以Q(b,ai)的上界和下界为端点的整个线段反映了Q(b,ai)的取值情况,仅仅以线段的上端点或下端点来评价Q(b,ai)显然不够全面.事实上就整个线段比较而言,在图3的示例中可能选择a3作为最优动作更为合理,尽管Q(b,a3)的上界和下界都不是最大值,但是Q(b,a3)值最大的概率可能最大.
本文提出了选择最优动作的新标准:以所有动作的函数值在其上界和下界之间的概率分布为基础,计算每个动作的值函数取值最大的概率,再选择概率值最大的动作.基于新标准选择动作更加合理,可以更准确地探索到R*(b0)附近的区域,从而提高迭代效率.
3.2基于蒙特卡罗的概率计算
p(y)=p(x1,x2,…,xn)
其中y是一个n维向量:y=(x1,x2,…,xn)满足∮Ωp(x1,x2,…,xn)dx1dx2…dxn=1.其中
则动作ai的值函数的取值xi最大的概率为:
F*(ai)=P(xi>xj,∀j≠i)
=∮Ωip(x1,…,xn)dx1…dxn
Ωi=Ω∩{(x1,x2,…,xn)|xi>xj,∀j≠i}
由于Ωi是n维空间的一个封闭区域,F*(ai)的计算涉及高维积分.随着维数n的增加,计算难度和复杂度将大大增加,本文通过蒙特卡罗法来求其近似值.

证明:构造两个函数Qi(y)和Fi(y):
则:F*(ai)=∮ΩQi(y)dy=∮ΩFi(y)p(y)dy
由此F*(ai)即随机变量Fi(y)的数学期望值,由于y1,y2,…,ym为Ω上按概率密度p(y)选取的随机样点,可求Fi(y)的数学期望近似值.
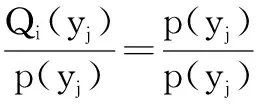
本文参照AEMS1算法[14]假定动作的最优值函数在上下界之间均匀分布,对动作值函数进行取样,并由此计算动作最优的概率.
3.3PBVIOP算法
PBVIOP算法(算法1)初始化值函数的上下界之后,反复调用子函数PBVIOPExplore从b0出发进行深度探索并更新值函数的上界和下界,直至b0处取值收敛为止.

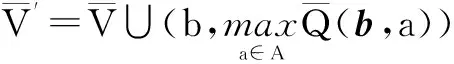

PBVIOP算法在选择最优动作时同时考虑了最优动作值函数的上界和下界.在迭代过程中下界持续上升而上界会持续下降,随着值函数上下界之差逐渐缩小,对各个动作最优概率的估算会更加精确,因而保证了值函数的收敛.因为算法同时更新值函数的上界和下界,并以值函数在上界和下界之间的分布来计算动作最优的概率,所以在信念点上更新值函数的上界和下界不会增加该点以后被探索到的可能性,故而算法会收敛到全局最优解.
4 实验
4.1实验设置
本文实验对比了PBVIOP算法、HSVI算法和GapMin算法运算情况,因为PBVIOP算法和HSVI算法的主要差别在于最优动作的选择,而GapMin算法是目前最高效的POMDP规划算法之一.本文在常见4个数据集上进行实验,其中Tiger、Hallway是早期的经典迷宫问题;RockSample模拟了Agent采样矿石的科学考察任务,是一个可扩展的问题[10].实验所用数据集的状态、动作和观察规模如下表:
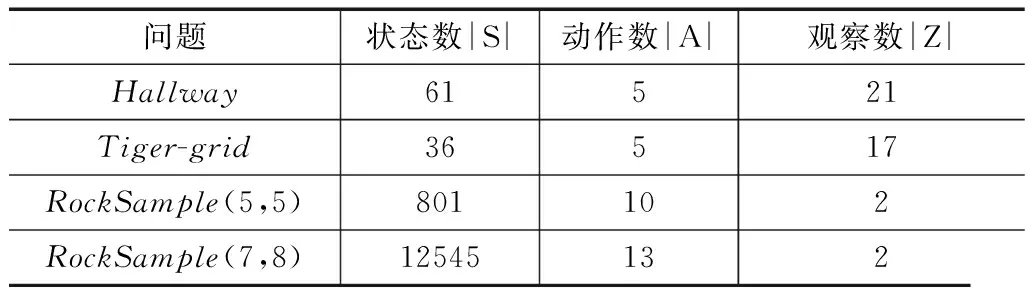
表1 POMDP标准数据集的规模
本文实验中复用了GuyShani教授提供的POMDPSolver部分代码.对每个问题设定折扣因子为0.95,分别用PBVIOP算法、HSVI算法和GapMin算法各做10次运算,再对10次运算的结果取平均值,选取运算时间和平均折扣回报值(AverageDiscountedReward,ADR)作为评价指标.平均折扣回报值表示了生成策略的质量,由生成的策略模拟运行100步计算得出折扣回报值,通过反复500次的模拟来计算平均折扣回报值.
4.2实验结果分析
实验结果如表2所示,可见大多数情况下PBVIOP算法有较好的收敛效果.
图4是HSVI、GapMin和PBVIOP在四个问题上实验结果的详细对比,表示了生成策略的平均折扣回报值的演变情况.图中横坐标为算法运行时间(s),纵坐标为ADR值;实线表示HSVI算法对应的结果,短划线表示GapMin算法对应的结果,圆点线表示PBVIOP算法对应的结果.
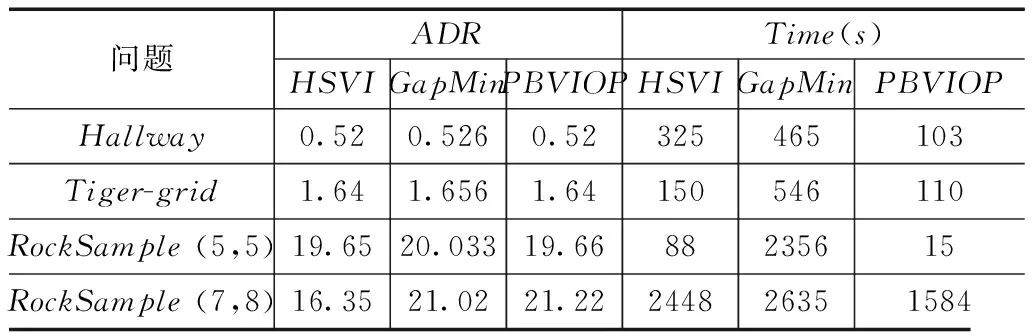
表2 实验结果数据
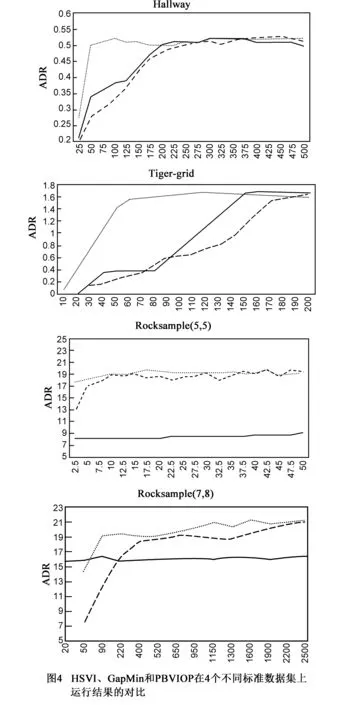
在求解Hallway和Tiger-grid问题的实验中,因为问题规模较小,PBVIOP算法和HSVI算法收敛到相同的ADR,GapMin算法的ADR略高一点.而PBVIOP算法的收敛效率明显较高,在Hallway问题求解中比HSVI算法快3.15倍,比GapMin算法快4.51倍;在Tiger-grid问题求解中比HSVI算法快1.36倍,比GapMin算法快4.96倍.
在求解RockSample(5,5)问题的实验中,PBVIOP算法收敛到的ADR比HSVI算法高出较多,收敛效率比HSVI算法快5.86倍.PBVIOP算法收敛到的ADR略低于GapMin算法,但其收敛效率比GapMin算法快157.06倍.
在求解RockSample(7,8)问题的实验中,PBVIOP算法和GapMin算法收敛到的ADR都比HSVI算法高出较多,且PBVIOP算法收敛到的ADR比GapMin算法略高.PBVIOP算法收敛效率比HSVI算法快1.54倍,比GapMin算法快1.66倍.
虽然GapMin算法和HSVI算法一样选择值函数上界最优的动作,但GapMin算法在每轮迭代中会探索所有Gap大于当前阈值的信念点,因而GapMin算法可以更加有效地降低上界值,在状态规模不太大的POMDP问题上找到全局最优解.但随着POMDP问题中状态数的增加,上界的下降效果变差,GapMin算法也难以有效地求解POMDP问题.另外由于GapMin算法多探索了许多信念点,其收敛效率受到较大影响.
实验结果表明PBVIOP算法比HSVI和GapMin算法有更高的收敛效率,并且随着POMDP问题规模的增加,其收敛到的ADR也会明显地优于HSVI算法,和GapMin算法相当.随着状态数目的增加,上界的下降速度会显著降低,因而HSVI和GapMin算法的收敛效率直接受到了影响.另一方面,随着动作数量的增加,PBVIOP算法探索的R*(b0)和HSVI算法探索的R*(b0)会有更大的差异,因而PBVIOP算法的效果会更优于HSVI算法.这说明与单纯利用上界相比而言,同时利用上下界能够更快更优地探索到R*(b0)附近的区域,对于算法性能和收敛质量的提升有很大的帮助.
5 结束语
本文提出了一种基于概率的最优策略值迭代方法PBVIOP,解决了启发式探索最优策略可达区域R*(b0)时需要保障值函数上下界收敛效率的问题.PBVIOP算法与现有基于点的值迭代算法不同之处在于使用一种有效的新方法来探索最优策略可达区域R*(b0).PBVIOP算法同时维持值函数的上界和下界,在启发式的深度探索中,用蒙特卡罗法估算各个动作值函数最优的概率,选择概率最大的动作为最优策略,再贪婪探索不确定性最大的后继信念点.实验结果表明,与HSVI和GapMin算法相比,PBVIOP算法在基准数据集上有更高的收敛效率并能够获得较优的策略.未来的工作一方面是在APPL平台上实现本算法,完善实验配置,尝试和HHOP等算法进行比较分析以完善本算法;另一方面是进一步优化值函数的概率分布模型和后继信念点的选择标准,并尝试每步探索多个有效的信念点来近似最优策略可达区域,从而进一步提高一次深度探索的效率.
[1]S Russell,PNorvig.Artificial Intelligence:A Modern Approach[M].Prentice-Hall,1995.
[2]T Smith.Probabilistic planning for robotic exploration[D].Massachusetts Institute of Technology,2007.
[3]J D Williams,S Young.Partially observable Markov decision processes for spoken dialog systems[J].Computer Speech & Language,Elsevier,2007,21(2):393-422.
[4]赵二虎,阳小龙,等.CPSM:一种增强IP网络生存性的客户端主动服务漂移模型[J].电子学报,2010,38(9):2134-2139.
Zhao Er-hu,Yang Xiao-long,et al.CPSM:Client-side proactive service migration model for enhancing IP network survivability[J].Acta Electronica Sinica,2010,38(9):2134-2139.(in Chinese)
[5]张子宁,单甘霖,段修生.基于部分可观马氏决策过程的多平台主被动传感器调度[J].电子学报,2014,42 (10):2104-2109.
Zhang Zi-ning,Shan Gan-lin,Duan Xiu-sheng.POMDP-based scheduling of active/passive sensors in multi-platform[J].Acta Electronica Sinica,2014,42(10):2104-2109.(in Chinese)
[6]M Hauskrecht.Value-function approximations for partially observable Markov decision processes[J].Journal of Artificial Intelligence Research,2000,13(1):33-94.
[7]刘海涛,洪炳熔,等.不确定性环境下基于进化算法的强化学习[J].电子学报,2006,34 (7):1356-1360.
Liu Hai-tao,Hong Bing-rong,et al.Evolutionary algorithm based reinforcement learning in the uncertain environments[J].Acta Electronica Sinica,2006,34(7):1356-1360.(in Chinese)
[8]Pineau J,Gordon G,Thrun S.Point-based value iteration:An anytime algorithm for POMDPs[A].International Joint Conference on Artificial Intelligence[C].Acapulco,Mexico:Morgan Kaufmann,2003.1025-1032.
[9]J Pineau,G Gordon.POMDP planning for robust robot control[A].International Symposium on Robotics Research[C].San Francisco,USA:Springer,2005,69-82.
[10]T Smith,R G Simmons.Point-based POMDP algorithms:Improved analysis and implementation[A].Conference on Uncertainty in Artificial Intelligence[C].Edinburgh,United kingdom:AUAI Press,2005,542-547.
[11]H Kurniawati,D Hsu,W S Lee.SARSOP:Efficient point-based POMDP planning by approximating optimally reachable belief spaces[A].Robotics:Science and Systems[C].Zurich,Switzerland:MIT Press,2008,65-72.
[12]P Poupart,K E Kim,D Kim.Closing the gap:Improved bounds on optimal POMDP solutions[A].International Conference on Planning and Scheduling[C].Freiburg,Germany:AAAI Press,2011.194-201.
[13]Z Zhang,D Hsu,W S Lee.Covering Number for Efficient Heuristic-based POMDP Planning[A].International Conference on Machine Learning[C].Beijing,China:International Machine Learning Society,2014.48-60.
[14]S Ross,B Chaib-Draa.AEMS:An anytime online search algorithm for approximate policy refinement in large POMDPs[A].International Joint Conference on Artificial Intelligence[C].Hyderabad,India:Morgan Kaufmann,2007.2592-2598.
[15]章宗长,陈小平.杂合启发式在线POMDP规划[J].软件学报,2013,24(7):1589-1600.
Zhang Zong-zhang,Chen Xiao-ping.Hybrid heuristic online planning for POMDPs[J].Journal of Software,2013,24(7):1589-1600.(in Chinese)
[16]L P Kaelbling.Learning in Embedded Systems[M].MIT Press,1993.
[17]R D Smallwood,E J Sondik.The optimal control of partially observable markov processes over a finite horizon[J].Operations Research,1973,21(5):1071-1088.
[18]G Shani,J Pineau,R Kaplow.A survey of point-based POMDP solvers[J].Autonomous Agents and Multi-Agent Systems,2013,27(1):1-51.
[19]D Hsu,W S Lee,N Rong.What makes some POMDP problems easy to approximate?[A].Advances in Neural Information Processing Systems[C].Vancouver,BC,Canada:Curran Associates Inc,2007.689-696.

刘峰男,1976年生于江苏泰州.南京大学软件学院讲师.研究方向为强化学习、智能规划.
E-mail:ufeng-nju@163.com

王崇骏男,1975年生于江苏盱眙,南京大学计算机科学与技术系教授,中国计算机学会高级会员.研究方向为Agent及多Agent系统、 复杂网络分析及智能应用系统.

骆斌男,1967年生,南京大学软件学院教授,博士生导师,中国计算机学会杰出会员.研究方向为软件工程、人工智能.
A Probability-Based Value Iteration on Optimal Policy Algorithm for POMDP
LIU Feng1,3,WANG Chong-jun2,3,LUO Bin1,3
(1.SoftwareInstitute,NanjingUniversity,Nanjing,Jiangsu210093,China;2.DepartmentofComputerScienceandTechnology,NanjingUniversity,Nanjing,Jiangsu210093,China;3.NationalKeyLaboratoryforNovelSoftwareTechnology,NanjingUniversity,Nanjing,Jiangsu210093,China)
With the enlargement of the scale of POMDP problems in applications,the research of heuristic methods for reachable area based on the optimal policy becomes current hotspot.However,the standard of existing algorithms about choosing the best action is not perfect enough thus the efficiency of the algorithms is affected.This paper proposes a new value iteration method PBVIOP (Probability-based Value Iteration on Optimal Policy).In depth-first heuristic exploration,this method uses the Monte Carlo algorithm to calculate the probability of each optimal action according to the distribution of each action′s Q function value between its upper and lower bounds,and chooses the maximum probability action.Experiment results of four benchmarks show that PBVIOP algorithm can obtain global optimal solution and significantly improve the convergence efficiency.
partially observable Markov decision process (POMDP);probability-based value iteration on optimal policy(PBVIOP);Monte Carlo method
2014-09-15;
2015-03-19;责任编辑:蓝红杰
国家自然科学基金(No.61375069);江苏省自然科学基金(No.BK20131277)
TP319
A
0372-2112 (2016)05-1078-07
电子学报URL:http://www.ejournal.org.cn10.3969/j.issn.0372-2112.2016.05.010
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
黄河之声(2021年9期)2021-07-21
乐山师范学院学报(2020年4期)2020-06-06
音乐天地(音乐创作版)(2020年2期)2020-04-18
福建中学数学(2018年7期)2018-12-24
民族音乐(2018年4期)2018-09-20
中学数学研究(江西)(2018年7期)2018-07-30
哈尔滨师范大学自然科学学报(2015年6期)2015-04-23
应用数学与计算数学学报(2014年1期)2014-09-26
