
基于VFP技术的选择题选答率算法
2016-08-31 12:23黄涛
中国现代教育装备 2016年14期
黄 涛
基于VFP技术的选择题选答率算法
黄 涛
目前,许多学校通过光电机进行计算机读取机读卡识别选择题。光电机所带软件不能完成满足学校的一些需求,这就需要通过光电机读取出来的数据,再具体分析自身所需。结合VFP技术给出一类选择题选答率的算法,用于实现计算机自动核算选择题的选答率,该算法具有速度快、易于实现、随机性通用性强的特点。
光电机;VFP技术;读卡识别
一、问题描述
(1)光电机所读出来的数据是一串字符串,如“A 卷 CCCCBABBBABBBAC”,怎样把这一串字符串中对应某一小题的某一个字符提取出来,是核算选答率的前提。
(2)如何设置数据库中的表,使得算法更为速度快,简洁。VFP数据库技术必须要有各班每题的答题率数据库,而数据库里面的表如何设置,将会影响整个算法速度、简洁,不会造成混乱。
(3)怎样使得算法更具通用性。一个算法不是针对一个问题,而是针对一类问题,如果很好地处理通用性的问题,将会使算法得到广泛的应用,可以为不同数目选择题的各科目服务。
(4)算法中涉及的选择和循环结构,该如何处理。涉及的每道题目选项不止一个,要对每一个人的每一道题逐一的判断,这就要涉及选择。而且每个考生都进行相同的操作,这就要涉及循环。
二、问题模型
学校举行一次英语单科的测试,学校考生总人数为zr,每班人数为br。班级总数为bj,选择题共有t道。每道有“A,B,C,D”4个选项,正确答案在d(t)这个数组里。光电机读出来的数据存在dbf表cj里,临时dbf表cjd。找出每班每道选择题各选项的人数及班级和年级答对率,最后导入每班一张Excel表格。
三、解决问题
结合问题描述和问题的模型,对算法中所遇到的难题,做以下分析解答。
(1)光电机所读出来的数据存在字段为“da”的dbf表里。在VFP中,对字符串操作的函数有很多。在这里,选用SUBSTR(da,l1+4,1)这个函数,该函数主要用于字符串的提取。参数da是整个字符串,l1+4是指向字符串的指针,加4是因为“A卷 ”占用了4个字符。1是从第l1+4个开始在字符串里提取字符的个数。如果l1等于10的话,那么就会从da这个字符串里面提取了第10题选择题选项值。同理正确答案也可以通过该方法提取出来,放入数组d(t)里。
(2)因为该算法涉及数据库,因此该算法将主要是对表的操作。事先对相应表进行一些设置,是整个算法的前提,决定整个算法的速度及简洁。设要操作的表名为答对率,前面的模型里提到,共有t道选择题,共有bj个班级,所以在该表中包含的记录有t×bj条,其中包含的必要字段有,班级、题号、班级答对率、年级答对率、A人数、B人数、C人数、D人数,如图1所示。

图1
一开始就把表里所有的记录都清除,在要对某一班某一题赋值时,可以使用append blank命令,添加空记录。再把对应的值赋入,这样可以使数据更为准确,不会存在将上次考试的数据误认为这次的数据。
(3)通用性对于一个算法来说,是成与败的至关重要条件,是得到别人认可的关键。针对问题的模型,我们知道每一次考试的科目、每科目的选择题数、每一年级的班级数可能不尽相同。解决这一问题最好的方法,是在算法中引入input命令,每次考试都重新输入科目代表的数字、该科目的选择题数、该年级的班级数。这样,就会很好地解决通用性的问题,以后每次考试都可以用相同的程序。
(4)选择结构和循环结构对于整个算法来说是不可避免,对于全年级的考生,循环结构就显得重要。在这里选用最简单最好用的循环结构,即for循环对每个考生进行相同操作。每个考生又有4个选项判断,选择较多,就用do case选择结构来处理。如下:

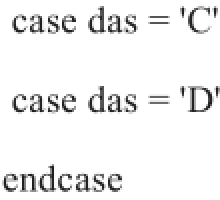
das为提取出来的选项值。case结构语句无疑是整个算法最好的选择。
四、结束语
根据选择题处理分析的现状,对于选择题选答率算法的实现,将会为各学校提供便利。特别是对于各学校来说,选择题选答率算法的实现对教师起到了很大的作用。可以很直观地体现出哪道题目答对的人少,哪个选项选择的人较多,学生对相应知识点的掌握情况。教师在评讲试卷时,可以根据该算法得到的结果,有针对性地重点讲解相应的题目,相应的知识点,直接提高了课堂效率。
作者信息
黄涛,本科,中教一级。湖北省大冶市第一中学,435100
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
无线互联科技(2020年11期)2020-12-01
中学生数理化(高中版.高考数学)(2020年5期)2020-06-02
铁道学报(2018年5期)2018-06-21
中国铸造装备与技术(2017年3期)2017-06-21
中国高新技术企业(2017年1期)2017-03-24
科教导刊·电子版(2016年30期)2016-12-26
试题与研究·中考化学(2016年1期)2016-09-30
中国信息技术教育(2015年21期)2015-09-10
