
一种基于胶质细胞链的改进深度信念网络模型
2016-08-22 09:55:10耿志强张怡康
自动化学报 2016年6期
耿志强 张怡康
一种基于胶质细胞链的改进深度信念网络模型
耿志强1张怡康1
深度信念网络(Deep belief network,DBN)是一种从无标签数据学习特征的多层结构模型.在同一层单元间缺少连接,导致数据中的深度关联特征难以提取.受到人脑中胶质神经细胞机制的启示,提出一种基于胶质细胞链的改进DBN模型及其学习算法,以提取更多数据信息.在标准图像分类数据集上的实验结果表明,与其他几种模型相比,本文提出的改进DBN模型可以提取更为优秀的图像特征,提高分类准确率.
深度信念网络,胶质细胞,无监督学习,特征提取
引用格式耿志强,张怡康.一种基于胶质细胞链的改进深度信念网络模型.自动化学报,2016,42(6):943-952
近年来,使用深度学习方法,建立多层网络模型,尝试在样本数据上逐层提取高级特征已成为机器学习、模式识别、特征提取与数据挖掘等领域的一个重要研究方向.神经科学研究表明人类大脑是一个由神经元组成的深度结构,对大脑皮层不同区域输入信息的多级抽象,可以使人脑完成复杂的物体识别任务[1].因此,深度学习相关研究专注于模拟人类大脑的多层结构以获取更好的学习性能.
深度信念网络(Deep belief network,DBN)是一种由多层非线性变量连接组成的生成式模型[2]. DBN可以看作由多个受限玻尔兹曼机(Restricted Boltzmann machine,RBM)层叠构成,其中前一个RBM的隐含层将作为下一个RBM的可视层.组成DBN的每一个RBM都可以使用上一层的输出单独训练,因此与传统的神经网络相比,DBN的训练过程将会变得简单.这种训练方法也有助于从无标签数据获取高级特征.
随着深度学习方向研究的深入与发展,人们已提出多种改进的DBN模型.通过补充先验方式,Hinton等导出一种快速的逐层贪婪算法可用于深度信念网络的训练[3].该算法应用于一个预训练过程,使用对比形式的Wake-sleep算法对RBM权值调优.在此之后,所有RBM组成的DBN生成式模型获得了比判别式学习算法更优秀的手写字符分类效果.然而,这种方法由于设计为使用二值图像数据并且缺少系统的方法处理感知不变性而存在一定局限性.Bengio等进一步研究了这种算法,将其成功地扩展到输入为连续值或输入分布的结构并不能完全确定的情况,省去了有监督学习中对其状态的预测过程[4].实验结果表明,这种贪婪逐层训练策略有助于优化深层网络,同时也证明每一层的无监督训练方式也十分重要.Lee等提出了一种称为卷积深度信念网络的层次生成模型,可用于全尺寸的图像数据处理[5].这种DBN模型的关键方法是用概率的最大汇总将更高层的表示做压缩,可使模型具有平移不变性,从而能支持高效率的自底向上和自顶向下概率推断.Huang等也对卷积DBN进行研究并将其用于学习人脸识别的高分辨率图像特征,提出了一种全新的局部卷积RBM模型,来获取额外的特征表示并应用到人工图像描述符如LBP(Local binary patterns)中.相关实验证明权值的学习不仅对于获得良好的多层特征十分重要,同时也提供了选择网络参数的健壮性方法[6].在此基础上,一种面部表情识别模型BDBN(Boosted deep belief network)被提出,这种模型通过三个阶段的迭代来进行训练[7],能够学习到一组可有效描述表情相关的面部外形特征并用统计方法构建增强分类器.在手写文字识别方面,Roy等提出了一种使用DBN的词语假设查找改进方法[8],将DBN提取的有效区分性特征与基于递归神经网络的序列分类器组合,以进一步提高识别性能.在语音识别领域,Mohamed等用DBN替代高斯混合模型,在TIMIT数据集上获得了更好的音素识别效果[9].这种DBN首先在没有区分信息的情况下预训练,然后使用反向传播的方法微调.为了完全利用DBN的生成性特征,Kang等提出了对语音参数如频谱和F0等建模,然后在语音合成功能的DBN中同步生成这些参数[10].这种DBN可以构建出优于HMM(Hidden Markov model)模型的频谱,同时拥有更少的失真.
尽管DBN在众多应用领域都获得了更好的结果,在隐含层缺少约束的DBN可能会产生非结构化的权值模式.本文尝试在神经科学研究中寻找解决方法.除一般神经元外,在人脑中还有另一种神经细胞称为胶质细胞(Glia cell).在近期的神经科学研究中,胶质细胞已成为了解人脑工作机制的中心课题[11].胶质细胞可以用离子作为传递信号的媒介,如Ca2+、GLU(Glutamate)、ATP(Adenosine triphosphate)等.在这些离子中,Ca2+十分特殊,可以改变神经元的膜电位和相邻胶质细胞的状态.一些研究人员已注意到这种生物作用机制,并将其应用于人工神经网络[12].这项研究提出了一种改进的多层感知器(Multilayer perceptron,MLP),在隐含层中包含了多个胶质细胞.这些胶质细胞与MLP中的神经元相连并能被神经元的输出激活,同时已激活的胶质细胞将向相邻的胶质细胞传递信号.这种改进MLP模型能够获取有助于优化其学习过程的隐含层神经元关联信息.
与上述情况相似,DBN同层单元间也没有连接,因此本文提出了一种基于与胶质细胞链连接的受限玻尔兹曼机的DBN模型及改进的DBN逐层训练方法,以提高训练效率,抽取更多有效信息.在RBM的训练过程中,胶质细胞能够调整隐含层单元的激活概率并向其他胶质细胞发出信号.在标准图像数据集上的实验结果显示,与传统DBN以及其他几种模型相比,这种改进的DBN模型可以获取更具抽象性的特征,同时提高分类准确率.
1 DBN和RBM
DBN是一种由多个隐含层组成的概率模型.每个隐含层在训练中都可以获得比上一层更高级的数据特征.DBN可以通过堆叠多个受限玻尔兹曼机(RBM)来构建.
1.1RBM
RBM是一种二部无向图模型[13].如图1所示,RBM由两层结构组成:可视层和隐含层.D维的可视层单元和K维隐含层单元间通过对称的权值矩阵WD×K连接.在可视层单元间及隐含层单元间并不存在连接.

图1 RBM结构示意图Fig.1 The structure of RBM
可视层单元和隐含层单元上的联合概率分布可定义为:
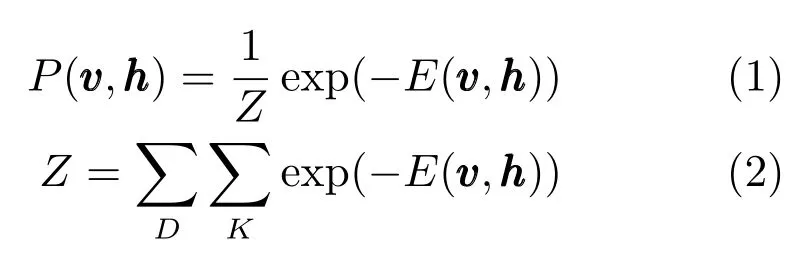
RBM的权值和偏置定义了隐含层单元和可视层单元的一种可能状态下的能量.如果可视层单元为二值形式,则能量函数可定义为:
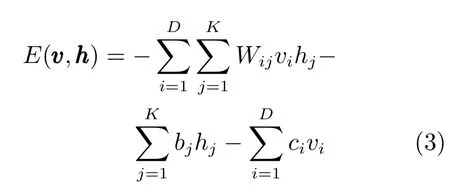
其中bj和ci分别为隐含层单元和可视层单元的偏置,Wij为隐含层单元和可视层单元间的权值.如果可视层单元为实值,则能量函数定义为以下形式:
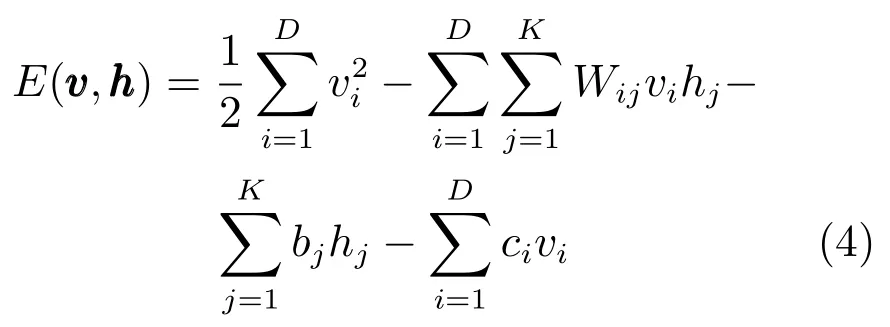
从能量函数可以看出,给定可视层单元的状态,隐含层单元彼此相互独立.同样,给定隐含层单元的状态,可视层单元也相互独立.根据条件概率分布定义,对于隐含层,每个隐含单元的二进制状态hj在下式情形可设置为1:
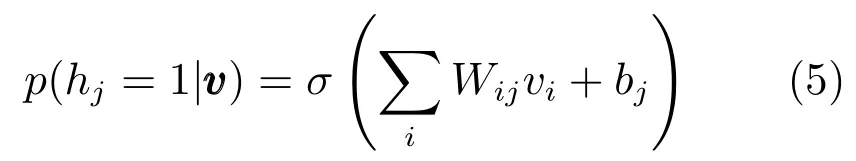
其中σ(s)=1/(1+exp(-s))为sigmoid函数.与此类似,如果可视层是二值的,则可视层单元状态依赖于隐含层单元,其状态vi在下式情形为1:
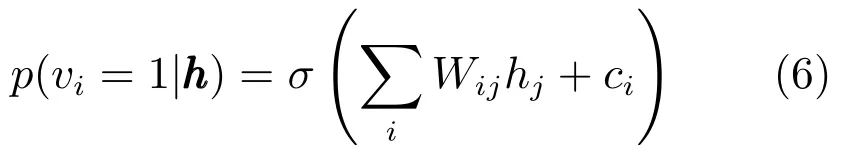
如果可视层为实值,可视层单元是有对角协方差的独立高斯变量:
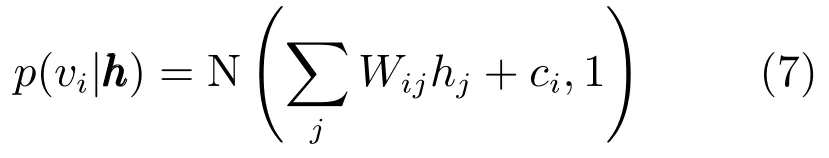
其中N(·,·)是高斯分布函数.
由于计算准确的梯度十分困难,因此RBM训练时常采用一种近似算法,称为对比散度算法(Contrastive divergence,CD).
1.2对比散度算法
基于对数似然函数logP(v vv)的梯度,可以导出RBM的权值更新规则,如下式所示:
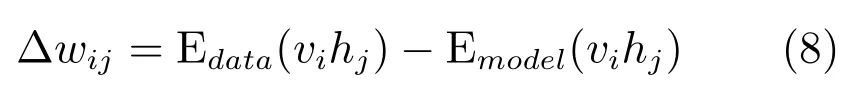
其中,Edata(vihj)是训练数据观测的期望,Emodel(vihj)是由模型定义分布下的期望[14].由于难以计算,因此常用近似算法为对比散度(CD)[15].通过单步或多步吉布斯采样,上述两个期望将会更新.对于单步采样的CD-1算法,其过程可简述如下:
CD算法的细节将在第2.2节详述.对于多步采样,其过程如图2所示.

图2 多步采样的CD算法过程Fig.2 Multistep sampling in CD algorithm
DBN网络的训练可采用一种贪婪逐层算法[16].首先,最底层RBM使用原始训练数据,通过CD算法训练.然后其参数将会保存,推断出隐含层单元状态作为下一层RBM的输入,下一层RBM继续训练,直到训练成完整的深层结构.
2 以胶质细胞链改进的RBM和DBN
胶质细胞是人脑中一种特殊的神经细胞,可向神经元和其他胶质细胞传递信号.研究人员已开始关注胶质细胞的特性,并将其应用于人工神经网络的训练过程.Ikuta等提出了一种用胶质细胞改进的多层感知器模型[17].在这种模型的训练中,胶质细胞能够产生脉冲信号并在神经网络中传递.实验结果表明与传统多层感知器相比,该模型拥有更好的学习性能.
同样,DBN可看作一种称为预训练深度神经网络(Pre-trained deep neural network)的结构[18].这类模型使用无监督的预训练方式来促进后续的区分性微调过程.受上述模型的启发,本文认为胶质细胞有助于RBM的训练,可学习到RBM同一层内单元间的关联信息.本文简化了胶质细胞的定义,使之适合RBM的结构.以这种方式改进的RBM及组成的DBN结构如图3所示.
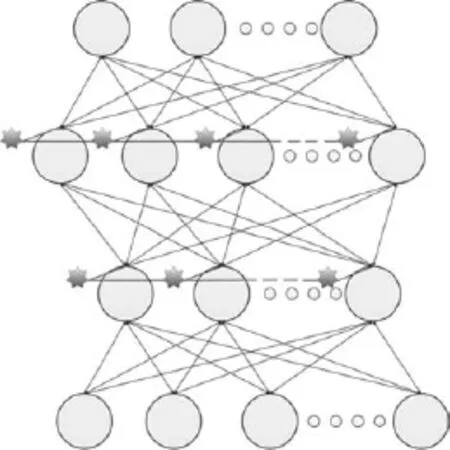
图3 胶质细胞链改进的RBM及其组成的DBN模型Fig.3 Improved RBMs based on glia chains and a DBN composed of these RBMs
在图3中,除了RBM的两层单元,还有一组胶质细胞以星形表示,连接成链式结构.此外,每个胶质细胞还与RBM隐含层对应位置的一个隐含单元相连.在本文提出模型中,胶质细胞与所对应的隐含单元间没有权值,训练过程中所有胶质细胞的效果都能直接作用于隐含层单元,调整隐含单元的输出.通过胶质细胞间的连接,每个胶质细胞也能够向其他胶质细胞传递信号,调整其他胶质细胞的胶质效果.
2.1改进RBM隐含层单元输出更新规则
在以胶质细胞链改进的RBM训练中,隐含层单元的输出将会被与之相连的处于激活状态的胶质细胞调整,然后这个胶质细胞会将激活信号向其他胶质细胞传递.例如,如果某个隐含单元h1的输出高于指定的阈值,胶质细胞g1将会被激活,之后产生一个信号传递给胶质细胞g2.当此信号传递到g2时,即使隐含单元h2的输出没有达到阈值,胶质细胞g2依然会激活,然后产生第二个信号向下传递,而第一个信号也会继续传播.在本文中,为了简化计算,所有信号定义为单向传播,即从链上第一个胶质细胞传向最后一个.
隐含层单元输出更新规则具体定义如下:
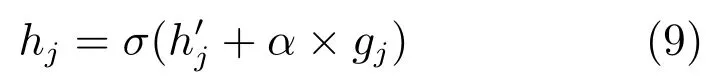
其中,hj是更新后的输出,σ是sigmoid函数,gj是胶质效果值,α是胶质效果的权重.胶质效果权重α是一个需人工设置的参数,设置此参数的目的是控制胶质效果对RBM隐含层单元输出调整作用的大小,胶质效果将作为新的隐含层单元输出的一部分,胶质效果权重值越大,对隐含层单元输出的调整作用就越明显.隐含层单元的原始输出h′j可由下式计算:
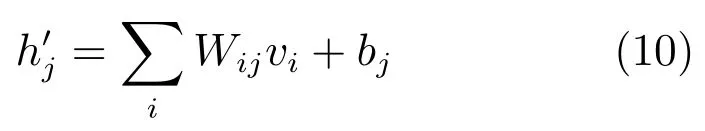
其中,Wij是连接到隐含层单元的权值,vi是可视层单元的状态,bj是隐含层单元的偏置.本文直接使用激活概率作为输出而非对每个隐含层单元状态随机采样,可以减少采样的噪声,加快学习速度[19].胶质效果值gj定义为:

其中,θ是指定的阈值,T是激活后的不响应时间,β是衰减因子.在本文中,已激活胶质细胞产生的信号每次前进到下一个胶质细胞,一个胶质细胞的激活将取决于所连接的隐含层单元输出是否达到了指定阈值,或前一个胶质细胞是否给它传递了信号,并且它的上次激活距离当前时刻差值必须大于不响应时间T.如果此胶质细胞激活,它将向下一个胶质细胞传递信号,否则不会产生信号并且其胶质效果将逐渐衰减.
2.2改进RBM及DBN的学习算法
在加入胶质细胞机制后,RBM的学习算法得到改进:训练中每次计算隐含层单元输出后,胶质细胞链会根据之前状态调整隐含层输出,并且保存下一次的胶质效果.改进的RBM训练算法伪码如下:
输出:权值矩阵W,隐含层偏置向量 b ,可视层偏置向量 c
训练阶段:
2:for j=1,2,···,m(对所有隐含单元)
5:end for
6:for i=1,2,···,n(对所有可见单元)
9:end for
12:for j=1,2,···,m(对所有隐含单元)
14:end for
按下式更新参数:
由多个RBM组成的DBN训练包含两个部分:预训练过程和微调过程.在预训练中,组成DBN的所有RBM自底向上依次训练.当某个RBM用改进的CD算法训练完成后,学习到的参数被保存,其隐含层输出将作为下层RBM的输入,下层RBM继续使用该算法训练,直到所有RBM训练完成.在微调阶段,所有RBM组成的网络用反向传播方式训练,进一步调整模型参数,直至收敛.在本文中,胶质细胞机制仅作用于预训练过程.DBN的训练过程如图4所示.
3 实验结果
为了验证本文所提出模型的学习性能,本文在三个图像分类数据集上进行实验:MNIST数据集[20]、CIFAR-10数据集[21]、Rectangles images数据集[22].改进的RBM(DBN)模型与其他几种模型结果做了比较:传统RBM、稀疏自动编码器(Sparse auto-encoder)[23]、BP神经网络(Backpropagation neural network)[24].实验的硬件平台为:CPU i5-3210M,2.50GHz,RAM 8GB.使用的深度学习框架为DeepLearnToolbox,运行的软件环境为Matlab2012.对于多分类数据(MNIST及CIFAR-10),本文在实验中选取了所有类别的数据进行训练,最终给出所有类的平均错误率.由于硬件条件有限,本文没有选取深度学习中的另一图像数据集ImageNet,而采用了矩形图像数据集Rectangles images,来测试模型在二分类数据上的性能,并且进行更多实验讨论模型关键参数的选择情况.为了提高学习效率,本文使用了分批训练方式,训练数据分为多个批次,在每批数据训练后更新模型参数.
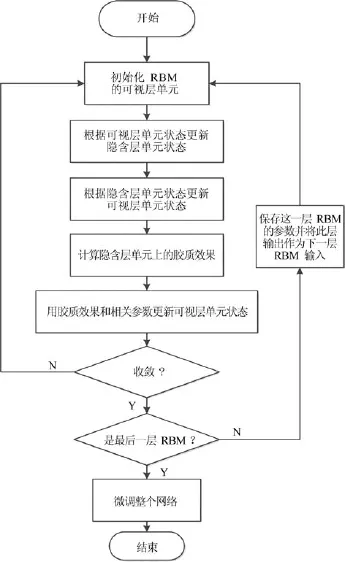
图4 改进DBN的训练过程Fig.4 Training process of the improved DBN
3.1MNIST数据集
MNIST数据集(Mixed National Institute of Standards and Technology dataset)是广泛应用于机器学习领域的一个大型手写数字数据集[25].该数据集包含60000张训练图像和10000张测试图像,每张图像都是一个0到9的手写数字,大小为28像素×28像素.
首先本文分别训练了改进RBM和传统RBM,结构均为784个可视层单元和100个隐含层单元,模型训练所学习到的特征可视化后如图5所示.
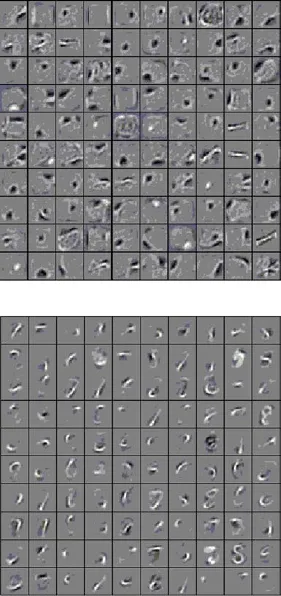
图5 RBM(上)和胶质细胞链改进的RBM(下)学习特征的可视化Fig.5 Visualization of features learned by RBM(above)and improved RBM(below)
从图5可以看出,传统RBM学习到的特征多为模糊的块状区域,少量为字符的笔画,而改进RBM学习到的特征多为更清晰的字符笔画,更有区分性和局部性.
之后本文在此数据集上训练了几种不同模型:RBM、改进RBM、稀疏自动编码器、BP神经网络.这几种模型的算法程序均在DeepLearnToolbox基础上实现,其共同拥有的可调参数如学习率等均调整并设为相同值,隐含层单元均设置为从200逐渐增加到500,并比较它们在测试数据上的分类错误率及运行收敛时间,结果如表1所示.
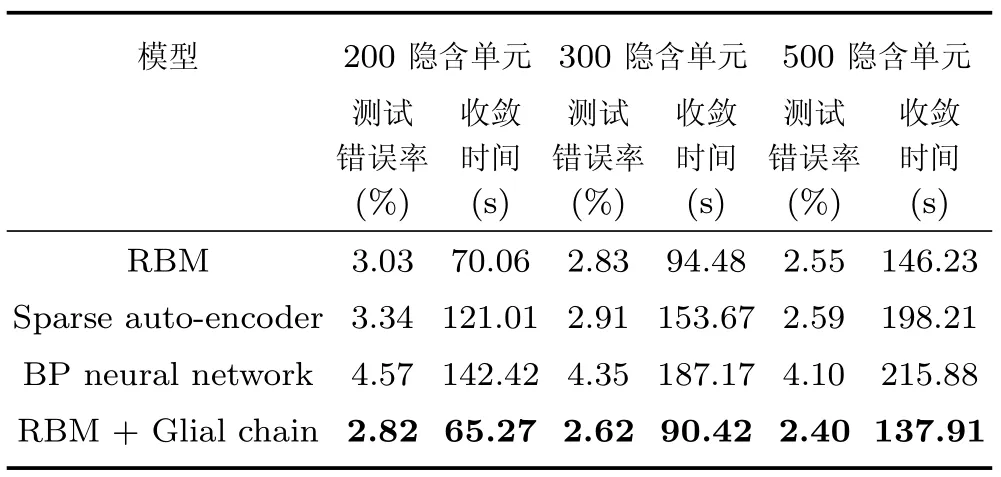
表1 MNIST数据集上不同模型的测试结果Table 1 Testing results of different models on MNIST dataset
表1结果显示,与传统RBM及其他几种模型相比,以胶质细胞链改进的RBM拥有更好的分类性能.随着隐含层单元数量的增加,所有模型的分类错误率都在不同程度上下降,但改进RBM始终保持最低的错误率,并且具有更快的收敛速度.由此可以推断,改进RBM模型可学习到更优更具区分性的特征.
为了进一步研究多隐含层结构模型的学习性能,本文分别训练了DBN和胶质细胞链改进DBN模型,均包含两个隐含层,单元数为第一层500,第二层200.这两种DBN共同具有的参数如学习率和动量等均设置为相同值.表2显示了这两种模型的训练和测试分类错误率、收敛时间.为了更详细地显示出两种模型的分类情况,本文统计了两种DBN模型在前三个类别的False positive(FP)及False negative(FN)数据,如表3所示.

表2 MNIST数据集上传统DBN及改进DBN的训练及测试错误率及收敛时间Table 2 Training,testing error rate and convergence time of DBN and improved DBN on MNIST dataset
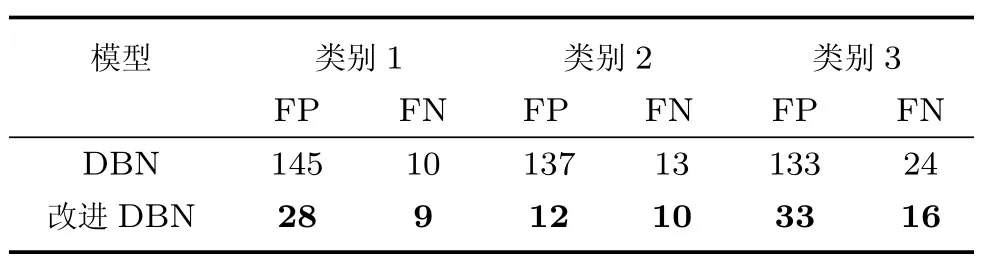
表3 MNIST 数据集上传统DBN 及改进DBN 的FP 及FN 数据Table 3 FP and FN data of DBN and improved DBN on MNIST dataset
表2和表3可以看出,当采用多隐含层结构时,改进DBN的分类错误率依然低于传统DBN,收敛速度更快,并且在三种具体类别的图像数据分类中,产生的FP和FN数据均较少,说明其分类效果更为优秀.这进一步验证了增加的胶质细胞链能够改进深层结构的学习性能.在胶质细胞链的调整效果下,DBN能够获取同一隐含层单元间的关联信息,并且隐含层单元间可以通过胶质细胞传递信息.
为了测试改进DBN的最优性能,本文训练了包含三个隐含层的网络,其结构(包含输入)为784-500-500-2000,在每个隐含层内还连接相同数量的胶质细胞.在将参数调整后,改进DBN模型获得了在MNIST数据集上,本文所有实验的最低错误率,并与此数据集已记录模型的结果相比,如表4所示.
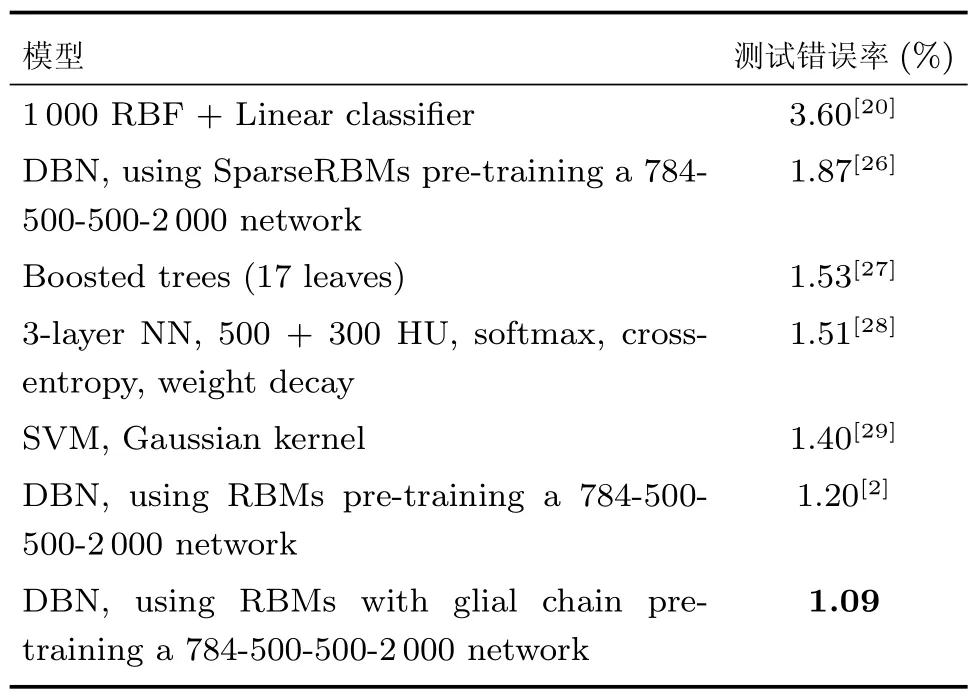
表4 MNIST数据集上改进DBN取得的最优结果与其他模型已有结果的比较Table 4 Comparison of DBN and other models′best results on MNIST dataset
3.2CIFAR-10数据集
CIFAR-10数据集包含60000张32×32大小的彩色图像,共有10类.每张图像中都包含一类物体,这些类别是完全独立的.与MNIST数据集相比,CIFAR-10数据集更为复杂,彩色图像数据维度更高,因此识别难度将会更大.
与之前实验类似,本文训练了RBM和改进RBM,其隐含层单元数从600逐步增加到1000.
模型训练后的分类错误率如图6所示.从图中可以看出,在CIFAR-10数据集上,改进RBM的分类错误率依然低于传统RBM,尽管输入数据维数更高、内容更复杂,胶质细胞链改进的RBM仍能学习到更优的图像特征.
同样,两种DBN模型也在此数据上训练,两个隐含层单元数分别为1000和500,训练和测试错误率如表5所示.可以看出,改进的DBN模型在CIFAR-10数据集也获得了更低的训练错误、更高的测试分类准确率和更快的收敛速度.
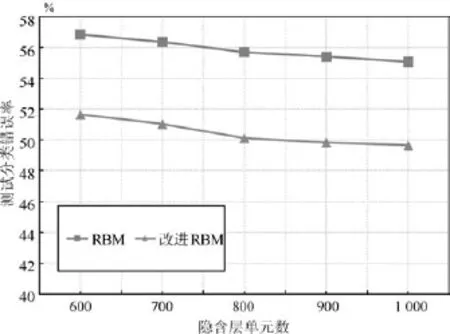
图6 RBM及胶质细胞改进RBM在CIFAR-10数据集上的测试分类错误率Fig.6 Test error rate of RBM and RBM with glia chain on CIFAR-10 dataset
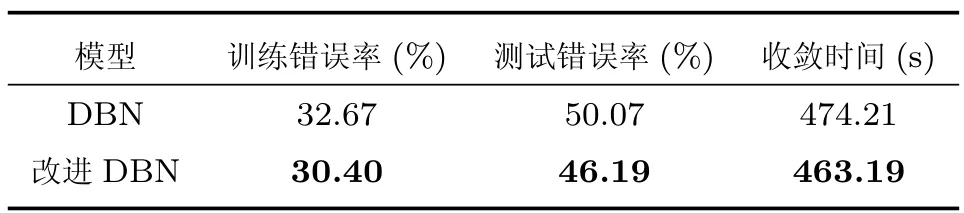
表5 CIFAR-10数据集上DBN及胶质细胞改进DBN的训练和测试分类错误率及收敛时间Table 5 Training,testing error rate and convergence time of DBN and improved DBN on CIFAR-10 dataset
表6为在“Airplane”“Automobile”“Bird”这三类图像数据中,DBN和改进DBN的FP和FN数据.其结果显示出改进DBN在识别这三类图像中的物体时,仍然具有更少的误分类,达到了更高的准确度.
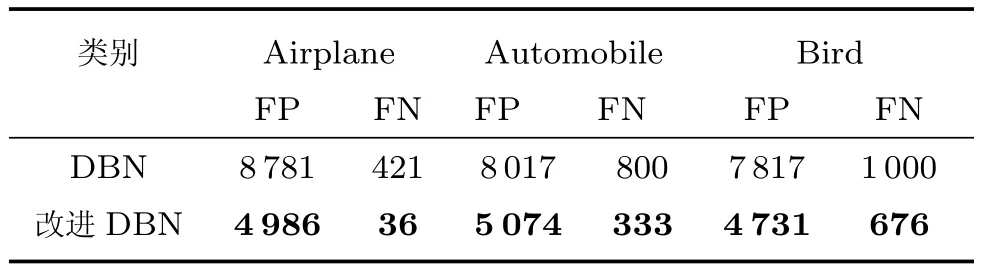
表6 CIFAR-10数据集上DBN及胶质细胞改进DBN的FP和FN数据Table 6 FP and FN data of DBN and improved DBN on CIFAR-10 dataset
3.3Rectangles images数据集
Rectangle images数据集包含62000张28×28的图像数据,每张图像中均有一个矩形图形,其高度和宽度不等.在此数据集上的分类任务为识别矩形的高度和宽度中的较大值,而矩形的位置并不固定.
与之前两个数据上实验相同,本文首先训练了不同隐含层单元数的RBM和改进RBM,其分类结果如图7所示.

图7 Rectangles images数据集上RBM及胶质细胞改进RBM的测试分类错误率Fig.7 Test error rate of RBM and RBM with glia chain on Rectangles images dataset
由图7可以看到,当隐含层单元数逐渐增加时,改进RBM获得了更低的测试分类错误率,在隐含单元数为200时最为明显,并且在隐含层单元增加的过程中,改进RBM的错误率下降趋势更大,说明改进RBM更适于多隐含层单元的模型,适合较复杂的图像数据的分类.
对于两个隐含层的DBN和改进DBN,其隐含单元数均设置为500和200.表7显示了两种模型的测试错误率、收敛时间、FP和FN数据.从结果可以看出,改进的RBM和DBN模型仍然具有更优秀的学习性能.
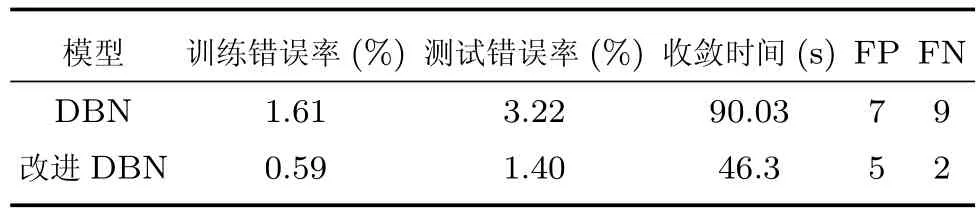
表7 Rectangles images数据集上DBN及胶质细胞改进DBN的训练和测试错误率、收敛时间、FP和FN数据Table 7 Training,testing error rate,convergence time,and FP,FN data of DBN and improved DBN on Rectangles images dataset
3.4参数选择
本文提出的改进DBN模型包含三个重要参数:胶质效果权重、衰减因子、胶质细胞阈值.这三个参数将决定胶质细胞对DBN的作用,进而影响训练模型的整体性能.由于在目前的改进DBN模型的定义中尚无这三个参数的自适应调整方法,因此现阶段胶质细胞参数的调整需通过人工设置及实验结果验证.在本节中,本文在Rectangles images数据集上重点考察了当这三个胶质细胞参数取值为0到1区间内间隔为0.05的20个不同值时,对模型测试分类错误率的影响,在每个参数不同取值下,本文均进行了30次实验,取测试分类错误率的平均值作为最终结果,希望能在结果中探讨参数的合理取值区间,为改进DBN模型的应用提供一定的参考.
本文将测试单隐含层和双隐含层的改进DBN模型,其隐含单元数设置为:第一隐含层500,第二隐含层200.首先测试胶质效果权重不同取值下改进DBN模型在数据上的测试分类错误率,如图8所示.
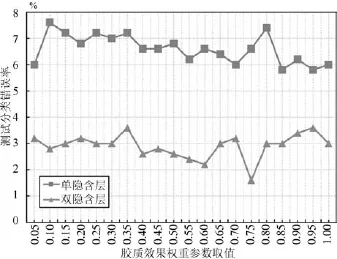
图8 胶质效果权重参数不同取值下改进DBN模型的测试分类错误率Fig.8 Testing error rate of improved DBN with different values of glia effect weight
从图8可以看出,当胶质效果权重取值在0.05 到1的区间时,两种结构的改进DBN模型获得的错误率均在不断波动.但是可以明显看出,当权重取值靠近区间边缘时(单隐含层取值0.1,双隐含层取值0.95),都会出现较高的错误率,因此胶质效果权重不应设置过小或过大.另一方面,当权重分别设置为0.85和0.75时,都获得了最低的错误率,但是其相邻取值时的错误率均出现了较高的点,并没有一定规律.经过比较,可以看到权重取值为0.5左右时,结果的变动较小,并且错误率相对较低,因此在此取值范围内,胶质效果适中,对DBN模型的影响较好.
图9显示了衰减因子参数为不同取值时的情况.最高错误率出现在0.55(单隐含层模型)及0.95(双隐含层模型),而最低错误率分别出现在取值为1.00 和0.05.对于单隐含层模型,随着衰减因子逐渐增大,其分类错误率有下降趋势,而双隐含层模型的分类错误率则总体略有上升.因此改进DBN的衰减因子参数取值较大时对单隐含层模型较为适合,而取值较小时,对于双隐含层模型较适合.
图10为胶质细胞的阈值参数不同取值时两种结构改进DBN模型的分类错误率变化情况.其中胶质细胞阈值的取值在0.40和0.45时,单隐含层模型分别获得了最低和最高的错误率.当取值为0.15和0.20时,双隐含层模型拥有最高和最低的错误率.这两种取值都较为接近,并且没有一定的规律.但是可以看到,在0.80至0.90的区间内,两种结构的改进DBN模型的分类错误率均为较低水平,并且变化较小.因此这个区间对胶质细胞阈值是一个较合理的取值区间.这可以在一定程度上说明较高的胶质细胞阈值决定了只有少数的胶质细胞能够激活,也只有少数的DBN隐含层单元获得更高的胶质效果,因此更有利于DBN模型的训练.
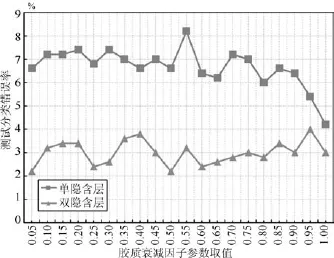
图9 胶质衰减因子参数不同取值下改进DBN模型的测试分类错误率Fig.9 Testing error rate of improved DBN with different values of attenuation factor
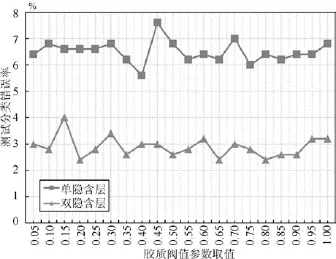
图10 胶质阈值参数不同取值下改进DBN模型的测试分类错误率Fig.10 Testing error rate of improved DBN with different values of glia threshold
4 结论
本文提出了一种基于人脑胶质细胞和神经元交互机制的改进DBN模型,其中胶质细胞组成的链式结构与DBN的隐含层相连.在此结构基础上,提出一种改进的DBN训练算法,以提取更优的数据特征.在组成DBN的RBM训练过程中,胶质细胞能够调整隐含层单元的输出并向其他胶质细胞传递相关信息.为了验证模型的学习性能,本文在MNIST、CIFAR-10、Rectangles images数据集上进行实验.与其他几种模型相比,改进的DBN能够提取更加适于图像分类任务的特征.但目前本文提出的模型仍有不足之处,由于胶质细胞机制的引入,增加了需要调整的参数,增大了训练模型时寻找最优参数的难度.在今后的工作中,我们将会进一步研究提高算法的运行效率以及胶质细胞参数的自适应调整方法.
References
1 Kruger N,Janssen P,Kalkan S,Lappe M,Leonardis A,Piater J,Rodriguez-Sanchez A J,Wiskott L.Deep hierarchies in the primate visual cortex:what can we learn for computer vision.IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1847-1871
2 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5786):504-507
3 Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.Neural Computation,2006,18(7):1527-1554
4 Bengio Y,Lamblin P,Popovici D,Larochelle H.Greedy layer-wise training of deep networks.In:Proceedings of Advances in Neural Information Processing Systems 19.Cambridge:MIT Press,2007.153-160
5 Lee H,Grosse R,Ranganath R,Ng A Y.Unsupervised learning of hierarchical representations with convolutional deep belief networks.Communications of the ACM,2011,54(10):95-103
6 Huang G B,Lee H,Learned-Miller E.Learning hierarchical representations for face verification with convolutional deep belief networks.In:Proceedings of the 2012 IEEE Conference on Computer Vision&Pattern Recognition.Providence,RI:IEEE,2012.2518-2525
7 Liu P,Han S Z,Meng Z B,Tong Y.Facial expression recognition via a boosted deep belief network.In:Proceedings of the 2014 IEEE Conference on Computer Vision&Pattern Recognition.Columbus,OH:IEEE,2014.1805-1812
8 Roy P P,Chherawala Y,Cheriet M.Deep-belief-network based rescoring approach for handwritten word recognition. In:Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition.Heraklion:IEEE,2014.506-511
9 Mohamed A R,Dahl G E,Hinton G.Acoustic modeling using deep belief networks.IEEE Transactions on Audio,Speech,&Language Processing,2012,20(1):14-22
10 Kang S Y,Qian X J,Meng H L.Multi-distribution deep belief network for speech synthesis.In:Proceedings of the 2013 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Vancouver,BC:IEEE,2013. 8012-8016
11 Haydon P G.GLIA:listening and talking to the synapse. Nature Reviews Neuroscience,2001,2(3):185-193
12 Ikuta C,Uwate Y,Nishio Y.Investigation of multi-layer perceptron with pulse glial chain.IEICE Technical Report Nonlinear Problems,2011,111(62):45-48(in Japanese)
13 Fischer A,Igel C.An introduction to restricted Boltzmann machines.In:Proceedings of the 17th Iberoamerican Congress on Progress in Pattern Recognition,Image Analysis,Computer Vision,and Applications.Lecture Notes in Computer Science.Buenos Aires,Argentina:Springer,2012. 14-36
14 Deng L,Yu D.Deep learning:methods and applications. Foundations&Trends®in Signal Processing,2013,7(3-4):197-387
15 Hinton G E.Training products of experts by minimizing contrastive divergence.Neural Computation,2002,14(8):1771-1800
16 Bengio Y.Learning deep architectures for AI.Foundations &Trends®in Machine Learning,2009,2(1):1-127
17 Ikuta C,Uwate Y,Nishio Y.Multi-layer perceptron with positive and negative pulse glial chain for solving two-spirals problem.In:Proceedings of the 2012 International Joint Conference on Neural Networks.Brisbane,QLD:IEEE,2012.1-6
18 Hinton G,Deng L,Yu D,Dahl G E,Mohamed A R,Jaitly N,Senior A,Vanhoucke V,Nguyen P,Sainath T N,Kingsbury B.Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups.IEEE Signal Processing Magazine,2012,29(6):82-97
19 Hinton G E.A practical guide to training restricted Boltzmann machines.Neural Networks:Tricks of the Trade(2nd edition).Berlin Heidelberg:Springer,2012.599-619
20 Lecun Y,Bottou L,Bengio Y,Haffner P.Gradient-based learning applied to document recognition.Proceedings of the IEEE,1998,86(11):2278-2324
21 Krizhevsky A,Hinton G.Learning Multiple Layers of Features from Tiny Images,Technical Report,University of Toronto,Canada,2009.
22 Larochelle H,Erhan D,Courville A,Bergstra J,Bengio Y,Ghahramani Z.An empirical evaluation of deep architectures on problems with many factors of variation.In:Proceedings of the 24th International Conference on Machine Learning.Oregon,USA:ICML,2007.473-480
23 Luo Y X,Wan Y.A novel efficient method for training sparse auto-encoders.In:Proceedings of the 6th International Congress on Image&Signal Processing.Hangzhou,China:IEEE,2013.1019-1023
24 Rumelhart D E,Hinton G E,Williams R J.Learning internal representations by error propagation.Neurocomputing:Foundations of Research.Cambridge:MIT Press,1988. 673-695
25 Platt J C.Using analytic Qp and sparseness to speed training of support vector machines.In:Proceedings of Advances in Neural Information Processing Systems 11.Cambridge:MIT Press,1999.557-563
26 Swersky K,Chen B,Marlin B,de Freitas N.A tutorial on stochastic approximation algorithms for training restricted Boltzmann machines and deep belief nets.In:Proceedings of the 2010 Information Theory and Applications Workshop (ITA).San Diego,USA:IEEE,2010.1-10
27 K´egl B,Busa-Fekete R.Boosting products of base classifiers. In:Proceedings of the 26th International Conference on Machine Learning.Montreal,Canada:ACM,2009.497-504
28 Hinton G E.What kind of a graphical model is the brain. In:Proceedings of the 19th International Joint Conference on Artificial Intelligence.San Francisco,CA,USA:Morgan Kaufmann Publishers Inc.,2005.1765-1775
29 Cortes C,Vapnik V.Support-vector networks.Machine Learning,1995,20(3):273-297

耿志强北京化工大学信息科学与技术学院教授.主要研究方向为神经网络,数据挖掘,过程建模与系统优化.本文通信作者.
E-mail:gengzhiqiang@mail.buct.edu.cn (GENGZhi-QiangProfessor at theCollegeofInformationScience and Technology,Beijing University of Chemical Technology.His research interest covers neural networks,data mining,process modeling and system optimization.Corresponding author of this paper.)

张怡康北京化工大学信息科学与技术学院硕士研究生.主要研究方向为神经网络,深度学习.
E-mail:zykh11@163.com
(ZHANG Yi-KangMaster student at the College of Information Science and Technology,Beijing University of Chemical Technology.His research interest covers neural networks and deep learning.)
An Improved Deep Belief Network Inspired by Glia Chains
GENG Zhi-Qiang1ZHANG Yi-Kang1
Deep belief network(DBN)is a hierarchical model for learning feature representations from unlabeled data. However,there are no interconnections among the neural units in the same layer and the mutual information of different neural units may be ignored.Inspired by functions of glia cells in the neural network structure of human brain,we propose a variant structure of DBN and an improved learning algorithm to extract more information of the data.Experimental results based on benchmark image datasets have shown that the proposed DBN model can acquire better features and achieve lower error rates than a traditional DBN and other compared learning algorithms.
Deep belief network(DBN),glia cells,unsupervised learning,feature extraction
10.16383/j.aas.2016.c150727
Geng Zhi-Qiang,Zhang Yi-Kang.An improved deep belief network inspired by glia chains.Acta Automatica Sinica,2016,42(6):943-952
2015-10-31录用日期2016-05-03
Manuscript received October 31,2015;accepted May 3,2016
国家自然科学基金(61374166),教育部博士点基金(20120010110 010),北京市自然科学基金(4162045)资助
Supported by National Natural Science Foundation of China (61374166),Ph.D.Programs Foundation of Ministry of Education of China(20120010110010),and Natural Science Foundation of Beijing(4162045)
本文责任编委柯登峰
Recommended by Associate Editor KE Deng-Feng
1.北京化工大学信息科学与技术学院北京100029
1.College of Information Science and Technology,Beijing University of Chemical Technology,Beijing 100029
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
神经损伤与功能重建(2020年11期)2020-12-01 05:01:54
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
教师·中(2017年3期)2017-04-20 21:49:49
湖南中医药大学学报(2016年1期)2016-12-01 04:08:21
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
磁共振成像(2015年1期)2015-12-23 08:52:21
教学研究与管理(2014年4期)2014-05-16 22:44:12
