
基于维基百科的领域本体自动构建方法研究
2016-08-05 07:58吴洁明刘雁昆段建勇
计算机应用与软件 2016年7期
吴洁明 刘雁昆 段建勇
(北方工业大学计算机学院 北京 100144)
基于维基百科的领域本体自动构建方法研究
吴洁明刘雁昆段建勇
(北方工业大学计算机学院北京 100144)
摘要随着互联网的发展,本体被广泛应用于知识工程、信息检索等领域。传统的本体构建方法无法满足日益增长的需求,提出一种基于维基百科的领域本体构建方法。通过提取维基百科的知识体系和知识属性,实现原始领域本体的自动化构建。提出的一种与路径无关的矢量方差方法,通过计算领域中每一个分类和条目的所属度,选择所属度大于阈值的分类和条目作为领域本体的内容,然后挖掘每个信息盒的内容来获取实体的属性。最后通过人工识别的方式验证提取的分类和条目的有效性,以及所构建的本体的准确性。
关键词本体维基百科有效性自动构建
0引言
本体一词源自西方哲学,在计算机领域中由Gruber定义:“本体是概念模型的明确规范说明”[1]。本体将现实中某个知识领域抽象成一组概念及概念之间的关系,并以计算机可认知的形式化语言来描述,目的是解决人与机器以及异构知识之间信息交流的障碍。随着互联网发展,本体被广泛用于知识工程、语言工程、信息检索以及数字图书馆等领域。
目前本体的构建主要依靠人工手动构建,虽然某些领域实现了半自动化构建,其面向领域专业性较强,如:医学、军事工业等,需要耗费大量的人力,且需要领域专家参与[2]。随着各领域信息化的推进,通用的本体自动构建方法成为当前的研究热点。Maedche等提出了需要人工参与的半自动化本体构建框架[3],将稳定协作模型的范例用于构建本体。文献[4]提供了一种mashup服务描述本体构建方法,这种方法利用开发者为mashup服务提供的标签构建本体,以WordNet作为知识库。但是,这种方法的前提是预定足够丰富且明确的领域知识分类结构,通过概念学习来实现本体构建。Zhong等提出了面向特定领域的本体构建过程[5],运用知识挖掘技术分阶段实现本体构建。在文献[6]中,提出了以面向Web内容的本体自动化构建,通过挖掘网页中的概念,运用贝叶斯分类器来构建本体。然而这种方法并不能准确定义概念群的所属类别名称,另外网页中的知识准确率不够高,其构建的专业领域本体利用价值不大。
本体构建自动化,首先需要一个涉及各个领域的信息库作为本体的知识源。维基百科作为当前最大的网络知识库,其拥有知识量巨大且不断增长、知识内容能够自我修正和完善等特点,引起了研究者的广泛关注。维基百科具有面向普通用户编辑的知识构建模式,包含了各领域专业知识。可以通过充分挖掘维基百科中分类、词条之间的语义关系、以及词条内容来构建某一领域的原始本体,为其后的本体学习和应用提供一个基本架构。在文献[7]中提出了基于维基百科知识库的构建方法,但是并没有认识到维基百科知识分类系统主要是为便于用户查询而做的知识导航,其分类结构与学术定义存在偏差,另外这种方法并没实现本体属性提取。
本文研究内容与现有自动构建方法不同之处主要包括以下两点:
1) 基于维基百科分类和词条的链接关系,通过改进的VVG(Variance-based Vector Generation)方法提取有效的领域本体知识结构;
2) 通过挖掘维基百科词条内容,获取领域本体的实体属性和概念属性,使领域本体的描述更为完整。
1数据分析
维基百科是一个数据开放的网络知识库,它的所有分类和条目都是由普通网络用户自由编辑的,并且以MySql数据表和XML文件形式提供给用户。通过研究维基百科数据的表结构,发现在’page’、’redirect’与’categoryLinks’三张表中包含了知识的分类和页面的重定向。
1) page表存储了维基百科的页面信息。本研究使用其中id(页面编号)、title(页面标题)、namespace(命名空间)字段,并且提取命名空间为0(表示为知识条目页面)和14(表示为分类页面)的数据。
2) redirect表存储了维基百科页面的重定向信息。本研究使用其中re_from(重定向页面id)、rd_title(目标页面title)、rd_namespace(重定向页面的命名空间)字段。
3) categorylinks表存储了维基百科知识的分类结构。本研究使用其中cl_from(子分类或条目的页面id)、cl_to(父分类页面id)字段。
维基百科条目页面中通常包含实体的基本概念解析、组成元素或属性等内容,这些可以构成本体的中的概念、属性和实例。维基百科词条可以通过内部链接与其他实体相关联,通过这些超链接可以挖掘本体中概念与概念、概念与属性之间的关系。
在本体存储形式上可选用OWL(Ontology Web Language)文档来表示构建的本体。网络本体语言OWL是由W3C制定的一种本体形式化语言,旨在促进由XML、RDF(S)支持的网络资源的互操作性[8]。因此,基于维基百科的本体构建可以转换为构建OWL文档,其实质就是通过挖掘维基百科中实体之间的关系,用OWL语言描述。OWL通过以下内容描述类和个体之间的关系。
1) subClassOf表示类之间的上下层关系,即父类与子类关系;
2) sameAs表示等价的分类或者实体;
3) ObjectProperty对象属性定义;
4) DatatypeProperty值属性定义。
通过处理维基百科提供的结构化数据,提取可由OWL描述的语义关系,转化为上段所示OWL关系定义。
2方法概述
通过提取维基百科数据,挖掘数据中的语义关系构建领域本体的架构,具体方法是:① 根据领域名称通过分类关系抽取所有的维基百科分类和知识条目;② 使用与祖先路径无关的矢量方差方法计算抽取数据中所有分类和条目的领域所属度l,提取那些所属度l大于一定阈值的分类和条目作为本体的分类和概念;③ 通过识别每个条目中的信息盒(Infobox)这种特殊结构抽取知识的属性;④ 将分类、概念和属性转换为OWL文档。其过程如图1所示。

图1 基于维基百科的领域本体自动构建过程
2.1维基百科中有效分类结构的提取
在维基百科的分类结构中包含了导航、主题索引、科学目录分类等内容,以方便用户查找、编辑和阅读,所以该分类结构并不是完整的科学分类结构。在维基百科中很多类别和条目都属于多个父类别,如图2所示(C表示一个分类,T表示一个条目)。为了提高领域本体准确性,需要消除无效的、与指定领域关联性较小的分类和条目。在此引入Masumi Shirakawa等提出的基于矢量方差方法VVG[9]。该方法通过计算某个条目或者概念对于某个类别的所属度来判断该概念是否属于这个类别。

图2 维基百科知识结构示例
我们定义V表示条目(概念)和分类的集合,E表示一个分类结构中的链接。整个维基百科知识结构可以表示为一个有向无环图G={V,E},V表示点的集合,E表示边的集合,E的方向是从子类别或者条目指向父类别。假设节点vm是我们需要建立本体的领域节点,节点vi表示根据维基百科分类结构中vm下的一个子分类,定义P={p1,p2,…,pn}表示从节点vi到节点vM所有路径的集合;定义节点vi的出度等于其父节点的个数,用n表示。在一个维基百科分类结构图G中一个条目或者分类vi对于vM的所属度I(vivM)由以下公式求得:
I(vi,vM)=∑pl∈Pc(pl)
(1)
c(pl)=∏eh∈plb(eh)
(2)
(3)
式中,b(eh)表示一个有向边eh的权重,其值取起始点出度n的倒数;c(pi)表示一条由节点vi通往节点vM的路径pl的权重,其值等于这条路径上所有e权值的乘积;那么一个vi对于vM的所属度I(vi,vM)即为所有连通这两个节点路径权重的和。
在上述基于矢量方差方法(VVG)中,计算每一个节点的所属度需要向上回溯整个路径。这就需要先抽取出领域的整个结构图,然后计算各节点的所属度。在知识点较多的知识领域中,该方法的计算量会非常大。为了便于计算I(vi,vM),可将式(1)-式(3)作出如下改进:
(4)
(5)
式(4)中Vfather表示与vM存在路径的vi父节点集合;n表示vi出度,即它的所有父节点个数;eh表示vi指向vk的边。设定当k=M时I(vk,vM)=1,即起始节点的所属度为1。式(5)表明一个节点的所属度等于其所有父节点所属度之和乘以出度的倒数,与路径无关。例如,图2中各个节点的所属度如表1所示。

表1 图2中各节点所属度
由式(5)可知,求取每个节点的所属度是一个对维基百科分类结构逐层递归的过程,在抽取知识结构的同时计算出每个节点的所属度。这不同于VVG方法需要抽取出整个领域的知识结构,才能计算各节点所属度,用这种方法降低了计算的复杂度。与路径无关的矢量方差方法可以由如下算法表示:
名称:从维基百科中提取领域知识结构提取递归算法。
输入:分类节点vfather以及它的所属度Ifather。
输出:指定领域的知识结构以及每个节点的所属度I。
起始输入:要研究的领域vM以及它的所属度IM=1。
结束条件:每个分支遇到条目节点结束递归,直至遍历领域M下的所有节点。
1查询出节点vfather的所有子节点,存入sonList;
2foreach sonList do
3获取子节点vson的所有父节点数n;
4if vson已被访问 then
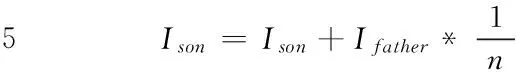
6else

8end
9存储Ison;
10if vson是一个分类(category) then
11递归;
12end
依据上述算法,训练数据集可以获得一个阈值a,将所属度小于a的节点及其所在的边从图中删除,得到一个简化过的图G′∈G,在G′中所有分类和条目均被认为是有效的。
2.2属性挖掘
在OWL中,ObjectProperty表示对象属性,表示两个类的实体之间的非分类关系;datatypeproperties表示数据类型属性,表示个体与数据类型的关联。如:“程序员从事程序开发”,其中“程序员”和“程序”为两个不同类别的实体;程序员有一个“年龄”属性,年龄的类型为整数型数据。用OWL可以表示为:
在维基百科知识条目中,有很多包含信息盒这种特殊结构,以半结构化形式出现在条目的XML文档中[10]。利用信息盒的这种结构关系可以非常准确地识别维基百科概念的属性,可转换为本体中的实体属性。如图3所示条目“Python”的信息盒,我们非常容易识别,每一个‘|’后面的字段表示一个属性,‘=’号后面表示这个属性的值,双括号‘[[’、‘]]’之间的词是一个维基百科内部词条。由此可通过正则表达式获取属性的名称和属性的值,从而创建实体属性(ObjectProperty)和数据类型属性(DatatypeProperty)。

图3 信息盒实例
2.3本体的自动构建
根据上述论述,可将维基百科知识快速构建由OWL文档表示的领域本体,构建过程如下:
1) 从维基百科网站中下载上文所需数据;
2) 根据维基百科知识分类结构,求取出指定领域VM下的所有分类和条目,构成知识结构图G,同时计算出这些分类对于的所属度;
3) 根据阈值对2)所形成的知识结构图G简化,删除无效的分类和条目,形成图G′;
4) 将图G′描述的知识之间的关系转换成OWL文本,转换关系如表2所示;

表2 维基百科知识结构到OWL的映射表
5) 对于包含信息盒的条目,构建对应的实体属性和值属性。
3实验与评估
3.1实验参数
实验使用的数据是维基百科2014年8月23日提供的中文数据,包括categorylinks、page、redirect三张数据表和zhwiki-20140826-pages-meta-current.xml.bz2文件包。实验选择“软件工程”为目标本体领域,抽取其下的所有分类(category)、条目(title)、重定向页面(redirect)。实验使用protégé-owl工具将抽取的知识转换成OWL文档。
3.2实验结果
根据维基百科的分类结构,实验中提取出属于软件工程领域分类186个、条目1396个,这其中包括很多编程语言、代码库和游戏等不属于软件工程的知识分类和条目。通过计算这些条目对于软件工程领域的所属度I提取软件工程领域的分类和条目,如表3所示。
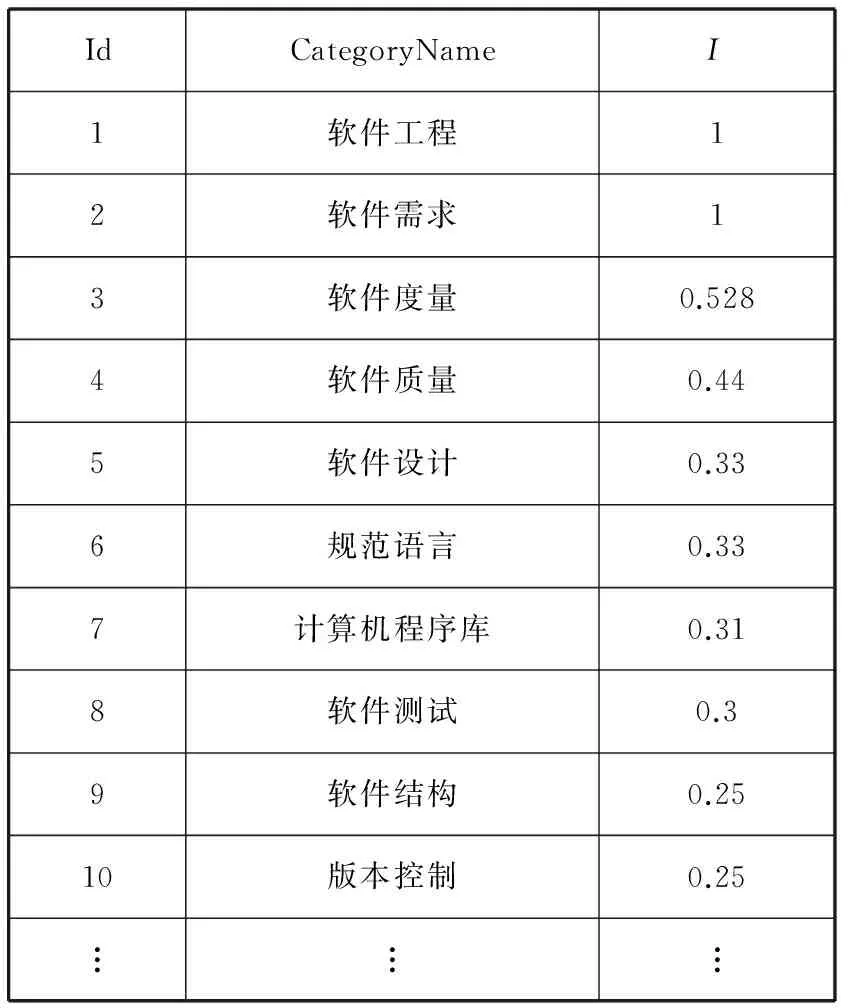
表3 所属度计算结果
分别选取阈值为 0.5、0.1、0.08,通过人工识别方式统计其对应的准确率(precision)和召回率(recall),如表4所示。

表4 所属度算法结果评价
通过综合比较看到当选取a=0.1为阈值,所有I<0.1的分类和条目可认为不属于软件工程领域的知识。
将上面提取的知识结构转换成OWL文档,并提取条目中的属性,就构建出了一个软件工程领域原始本体。为检验本体构建的正确性,将上述形成的OWL文档导入protégé中,可以看到软件工程本体结构与真实软件工程领域的知识结构基本相符,如图4所示为软件工程领域本体部分结构图。
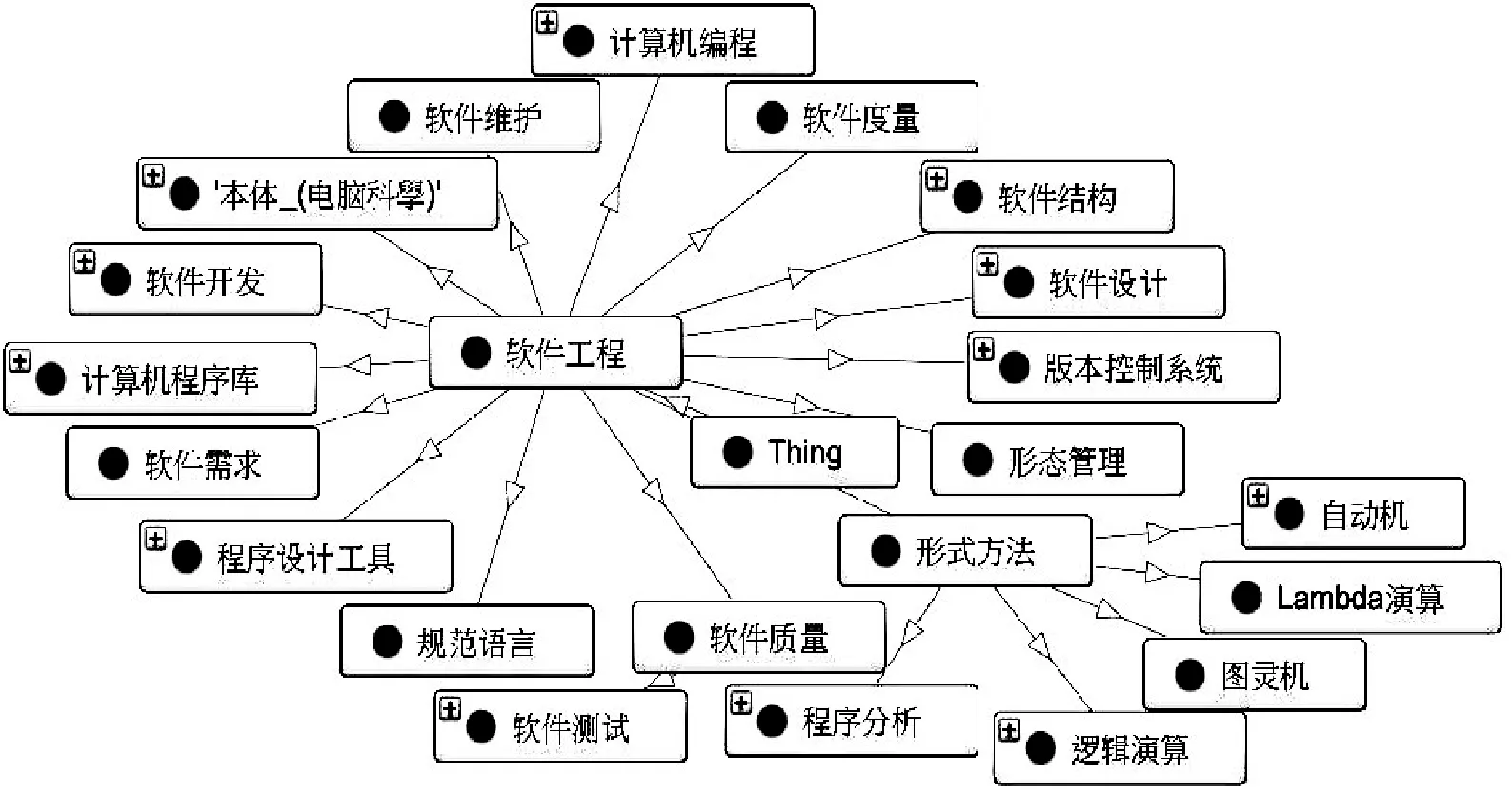
图4 软件工程领域本体部分结构图
4结语
本文提出了一种基于维基百科本体构建方法,通过挖掘维基百科中条目分类结构和条目内容获取本体的基本要素,并将其转换成OWL文档,实现领域本体的自动化构建。通过改进的矢量方差方法(VVG)识别有效分类和条目,这种方法提高了条目所属度的计算效率。本文还提出了基于信息盒的本体属性提取方法,这一方法简单有效且正确率高。
本体的构建是一个不断更新、学习、进化的循环过程,本文所提方法可以构造的是一个原始本体,其包含了一个领域主要的知识点和知识结构,可以作为本体学习和本体进化的原始数据。另外本文所提本体属性挖掘方法仍然有一定的局限性,随着中文自然语言处理技术的不断提高,我们能够从文本中提取出更加准确的属性模板,那么本体属性提取的数据源将不再局限于信息盒。
参考文献
[1] 胡兆芹.本体与知识组织[M].中国文史出版社,2014.
[2] 王磊,周宽久,仇鹏.领域本体自动构建研究[J].情报学报,2010,29(1):45-52.
[3] Maeduche A,Staab S.Ontology Learning for the Semantic Web[J].IEEE Intelligent Systems,2011,16(2):72-79.
[4] Li S,Li B,Pan W,et al.Approach for building mashup service description ontology automatically[J].Journal of Chinese Computer Systems,2011,32(9):1747-1752.
[5] Zhong N,Yao Y,Kakenoto Y.Automatic Construction of ontology from Text Databases[J].Data Mining,2011(2):173-180.
[6] 金鑫.面向Web信息资源的领域本体模型自动构建机制的研究[J].计算机科学,2012(6):213-216.
[7] 王磊,顾大权,侯太平,等.基于维基百科的气象本体的自动构建[J].计算机与现代化,2014(6):129-131.
[8] Allemang D,Hendler J.Semantic Web for the Working Ontologist-Effective Modeling in RDFS and OWL[M].Elsevier (Singapore) Pte Ltd,2009.
[9] Shirakawa M,Nakayama K,Hara K,et al.Concept vector extraction from Wikipedia category network[C]//Proceedings of the 3rdInternational Conference on ubiquitous Information Management and Communication (2009).New York,USA:ACM,2009:71-79.
[10] 余传明,张小青.从Wikipedia中获取本体:原理与方法研究[J].情报学报,2011(3):244-252.
收稿日期:2015-01-19。国家自然科学基金项目(61103112);国家科技支撑计划项目(2012BA H04F01,2012BAH04F03);北京市科技创新平台基金项目(PXM2013_014212_000011);北京市属高等学校创新团队建设与教师职业发展计划项目(IDHT20130502)。吴洁明,教授,主研领域:软件工程,面向对象技术。刘雁昆,硕士生。段建勇,教授。
中图分类号TP391.1
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.017
ON WIKIPEDIA-BASED AUTOMATIC DOMAIN ONTOLOGY CONSTRUCTION METHOD
Wu JiemingLiu YankunDuan Jianyong
(SchoolofComputerScience,NorthChinaUniversityofTechnology,Beijing100144,China)
AbstractWith the development of the Internet, ontology has been widely used in knowledge engineering, information retrieval and other fields. Traditional ontology construction method can’t satisfy the growing demand. This paper proposes a Wikipedia-based domain ontology construction method. By extracting the knowledge systems and knowledge attributes of Wikipedia, it realises the automated construction of original domain ontology. In this paper we introduces a path-independent vector variance method, by calculating the belongingness degree of each classification and entry in the field, it chooses those classifications and entries with the belongingness degrees greater than the threshold as the contents of domain ontology, and then mines the contents of each message box to get the attributes of the entity. In end of the paper, through artificial identification way we verify the effectiveness of the extracted classifications and entries and the accuracy of the constructed ontology.
KeywordsOntologyWikipediaEffectivenessAutomated construction
猜你喜欢
英语文摘(2021年8期)2021-11-02
哈哈画报(2021年10期)2021-02-28
物理之友(2020年12期)2020-07-16
法大研究生(2019年2期)2019-11-16
中学生数理化(高中版.高考数学)(2018年12期)2019-01-17
制造业自动化(2017年2期)2017-03-20
现代远程教育研究(2015年1期)2016-01-15
读者·原创版(2015年11期)2015-03-01
意林(2014年2期)2014-02-11
图书与情报(2013年1期)2013-11-16
