
基于社交网络大规模行为数据的用户关系研究
2016-08-05 07:58李石君
计算机应用与软件 2016年7期
刘 晶 李 琳 李石君
1(武汉大学计算机学院 湖北 武汉 430072)2(中南民族大学计算机科学学院 湖北 武汉 430074)3(武汉数字工程研究所 湖北 武汉 430074)
基于社交网络大规模行为数据的用户关系研究
刘晶1,2李琳3李石君1
1(武汉大学计算机学院湖北 武汉 430072)2(中南民族大学计算机科学学院湖北 武汉 430074)3(武汉数字工程研究所湖北 武汉 430074)
摘要用户关系是构成微博社会网络的基础。用户关系的分析可以帮助更好地研究社会网络的构成、消息传播模式等多个方面。对超过百万用户的海量微博数据进行分析处理,利用信息论理论分析比较用户微博行为的特点,构建用户活跃交互网络并观察交互网络的动态性,分析社交网络用户群体的在线行为模式及特点。实验表明在微博的交互活动中,用户的直接交互关系相对稳定,不因时间的变化而变化,而用户的转发对象会不断地变化,即用户实际关注的群体是动态变化的。
关键词社会网络用户行为微博交互
0引言
对用户行为数据进行收集并理解的研究可以追溯到1945年[1],美国学者Vannevar Bush提出了“Memex”设想,一个原始的用户行为记录系统。近十年来,在线社交网络取得飞速发展。国内各主流门户网站也纷纷推出各自的微博产品,微博在中国呈指数级扩张,用户数量与日俱增。在线社交网络已经成为连接物理社交世界和虚拟网络空间的桥梁。网络用户产生的信息和用户与用户之间的交互在社交网站上留下了各种足迹,直接促成了网络大数据时代的到来。如何从这些大数据中更好地理解用户和为用户服务是信息产业中的一个重要研究方向。
微博作为一种社会媒体不仅满足了用户的信息个性化发布、社会性传播和社交的需求,还改变了用户在网络上的交互方式。深入理解用户的在线交互模式可以为分析人类社会行为提供新的视角[2];帮助提高社交媒体和相关应用的设计元素,包括用户影响力度量[3,4]、消息传播路径[5]、朋友推荐[6-8]等。
针对社会网络的用户关系分析问题,学者们开展了大量的相关研究。其中,一些学者如Tang等[9,10]利用半监督学习方法来计算用户的关系强度,推断用户社会关系类型;Kahanda等[11]利用用户之间的交互性来度量用户关系强度;用户关系分析也经常被用于好友推荐[12]。
与传统的社交网络不同,微博是一个基于弱关系的信息分享、传播及获取平台。美国斯坦福大学的Mark教授提出了“弱连接威力”理论[13]:除了传统社会中的亲人、朋友、同事等十分稳定但传播范围有限的社会“强连接”关系,还存在另外一类更为广泛的社会关系,即所谓的“弱连接”。Mark的研究发现,在信息的扩散和传播上,弱连接关系其实比强连接关系发挥的作用更大。
本文借助微博开放平台,利用用户的公开行为数据来分析用户的交互行为及其背后蕴含的关系强度,从而更有针对性地为用户服务。本文以新浪微博用户为单位,定量对微博用户的微博行为进行深入分析,发现转发在微博活动中占主导地位。即使在单边通信关系中,人们也更愿意从其他人那里获取信息:用户更愿意作为信息接收者、传播者而不是信息发布者。本文还对新浪微博用户行为的细节和用户的交互随时间动态变化模式进行了研究,发现用户的直接交互关系相对稳定,不因时间的变化而变化,而用户的转发对象会不断地变化,即用户实际关注的群体是动态变化的。
1用户关系分析
1.1数据
根据新浪微博开放平台提供的应用程序接口(API)设计爬虫抓取用户基本信息,用户发表的微博和用户关注/粉丝关系网络。我们使用4台不同IP的机器,以2012年6月新浪微博人气总榜Top100用户为种子,通过粉丝/关注列表双向滚雪球式爬取粉丝数1000以上的用户及其2012年全年发表的微博。历时3个月爬回165 841 156条微博和8 386 628个用户信息。数据集包含三部分:用户基本信息、微博和关注/粉丝网络。
• 用户基本信息(User profile)
包含用户名、性别、帐号创建时间、位置信息(省/市)、已发表微博数、粉丝数、关注数、描述、认证信息。
• 微博(Tweets)
微博信息集包含:微博创建时间、转发数、评论数、被“赞”数、微博内容,如果该条微博是转发,则还包括被转微博的用户ID、被转微博ID、创建时间、微博内容。
• 关注/粉丝网络(following/followers)
新浪微博设置了三种用户关系网络:关注、双向关注和粉丝,其中,关注和粉丝是一对相互关系。如果A关注了B,则B在A的关注列表中,而A在B的粉丝列表中。如果A关注了B并且B也关注了A,则称A、B双向关注。双方互相出现在对方的关注和粉丝列表中。
本文主要研究用户的微博交互行为,因此对采集到的微博数据进行预处理,只考虑转发微博和包含提及的微博,即微博消息中包含了@[account]字段的微博。对微博文本进行解析,利用正则表达式提取出每条微博的提及对象:@[account]中的account,对每个用户u构造提及对象集mention(u)={ a| 用户a在u的微博中被提及}。
1.2用户模型
对于给定的用户集U中的任意一个用户u∈U,其用户信息包含3种属性:个人背景、社交关系和交互信息。因此用户u可以表示为模型M(u)={Info(u),Relation(u),Inter(u)}。具体说明如下:
1) Info(u) 表示u的个人描述信息,包括位置信息location、性别gender、个人描述describe、粉丝数量foNum、关注数量friNum、双向关注数量bifNum。用元组表示为Info(u)={location(u), gender(u), describe(u), foNum(u), friNum (u), bifNum (u)}。
2) Relation(u) 表示u的社交关系,包括关注向量friend(u)、粉丝向量follower(u)和双向关注向量bifollower(u)。因此Relation(u) = {friend(u),follower(u),bifollower(u)}。
3) Inter(u) 表示u的交互信息,包括转发向量retweet(u)、提及向量mention(u)和评论向量comment(u)。因此,u的交互模型可表示为Inter(u)={retweet(u), mention(u)}。
对整个用户集U中的每个用户从1开始依次编号,向量retweet(u)和 mention(u)中的第i个分量分别表示用户u转发、提及和评论用户i的次数。
1.3用户交互行为分析
对微博用户来说,他们的关注行为具有怎样的特点;是愿意仅与少部分人交流还是喜欢与更多的人交流;如果一个用户与其他很多用户都存在交互行为,他对每一个对象的关注度是否一样,即该用户是否平均分配时间给各个交互用户。为了研究这些问题,我们定义每个用户u的转发熵ERT如下:
(1)
其中,Su∈Inter(u). retweet(u),是用户u所有转发微博的来源用户集,pu(r)是u转发用户r的微博的频率。得到的转发熵矩阵ERT中,转发熵值越高,说明该用户越热衷于接收、传播来自不同用户的消息;反之,低转发熵表明该用户只转发来自少数特定用户的微博,转发来源可预测性高。
类似的,计算每个用户的提及熵EC如下:
(2)
其中,Nu∈Inter(u). mention (u)是用户u所有提及对象的集合,pu(n)是用户u提及用户n的次数占所有的提及微博的比例。评论熵矩阵EC中高熵值用户平均与其他用户的交互是均衡的;反之,用户更多的与少数“亲密”用户交流。
由于不同用户转发微博来源的规模亦不同,为了跨用户比较转发行为,归一化转发熵使之取值在[0,1]区间内:
E′(u)=E(u)/-0.5×|n|×log(|n|/2)
(3)
其中,|n|是用户u的交互(转发、提及)用户集规模。
对于微博用户行为分析的一个重要问题是:用户是否持续性的关注某一组特定用户?用户的转发和提及行为与用户的关联度是否会随着时间的变化而变化?为了找出答案,我们分别以一周和一个月为时间窗口,观察用户的转发和提及熵随时间的变化情况。把用户u在每个时间周期发表的微博作为一个集合ti,计算基于时间的转发熵和提及熵如下:
(4)
其中,r(v)是用户u的转发或提及的时间集合中v至少出现一次的概率,即包含v的ti占所有集合的比例。如果计算的是基于时间的转发熵,则Mu=Su;如果计算的是基于时间的提及熵,则Mu=Nu。同样地,为了使熵值落在区间[0,1]中,进行归一化处理:
E′(u)=E(u)/log(|n|)
(5)
在得到的用户—时间熵矩阵中,低熵值表示该用户一直与同样的用户群交互(转发或提及);反之,高熵值表示用户在不同时间段关注的用户群是变化的。
2实验分析
为了满足实验的大数据量运算,我们以高性能NF8560M2服务器为基础虚拟出10个主机节点,并以此为底层的分布式硬件环境。每个节点虚拟出一个XENO E7-4807的CPU和8 GB的内存,主机采用的是Windows Server 2008 R2操作系统,节点采用Ubuntu 12操作系统的Hadoop 0.20.2平台。
我们从用户个体的角度出发,统计了转发、提及微博占该用户所有微博行为的比重,图1以累计分布函数表示统计结果。
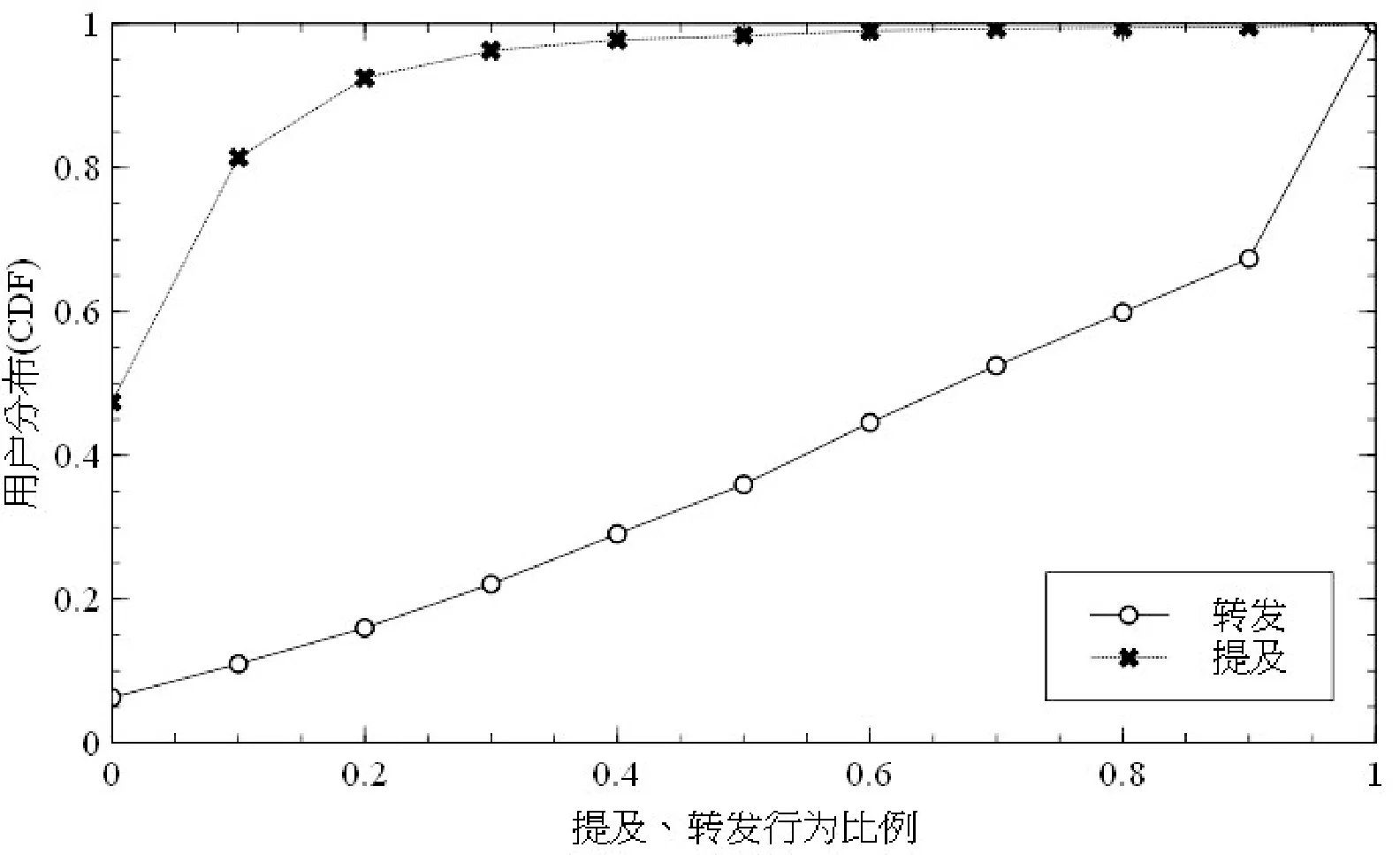
图1 用户转发、提及行为比重在[0,1]区间的用户分布
从图1提及曲线可以看出,49.3%的用户在微博中从未提及他人,有95.4%的用户在微博中提及他人的的行为比例小于30%。转发曲线显示51.7%的用户的转发行为占所有微博行为的73%,且这部分用户中,转发微博超过91.8%的用户有一个爆发式的增长。
分别计算每个用户的转发熵和提及熵,结果显示用户的平均提及熵为0.21,而平均转发熵为0.52。可以看出,提及是一种比较亲密的个人交互行为,更倾向于出现在小团体内部且相互间交互的更频繁,是强联系;而转发行为中用户的关注面更广,并且对转发来源的关注不像提及行为那样集中,是弱联系。图2显示了用户不同微博行为的熵值区间的分布情况。
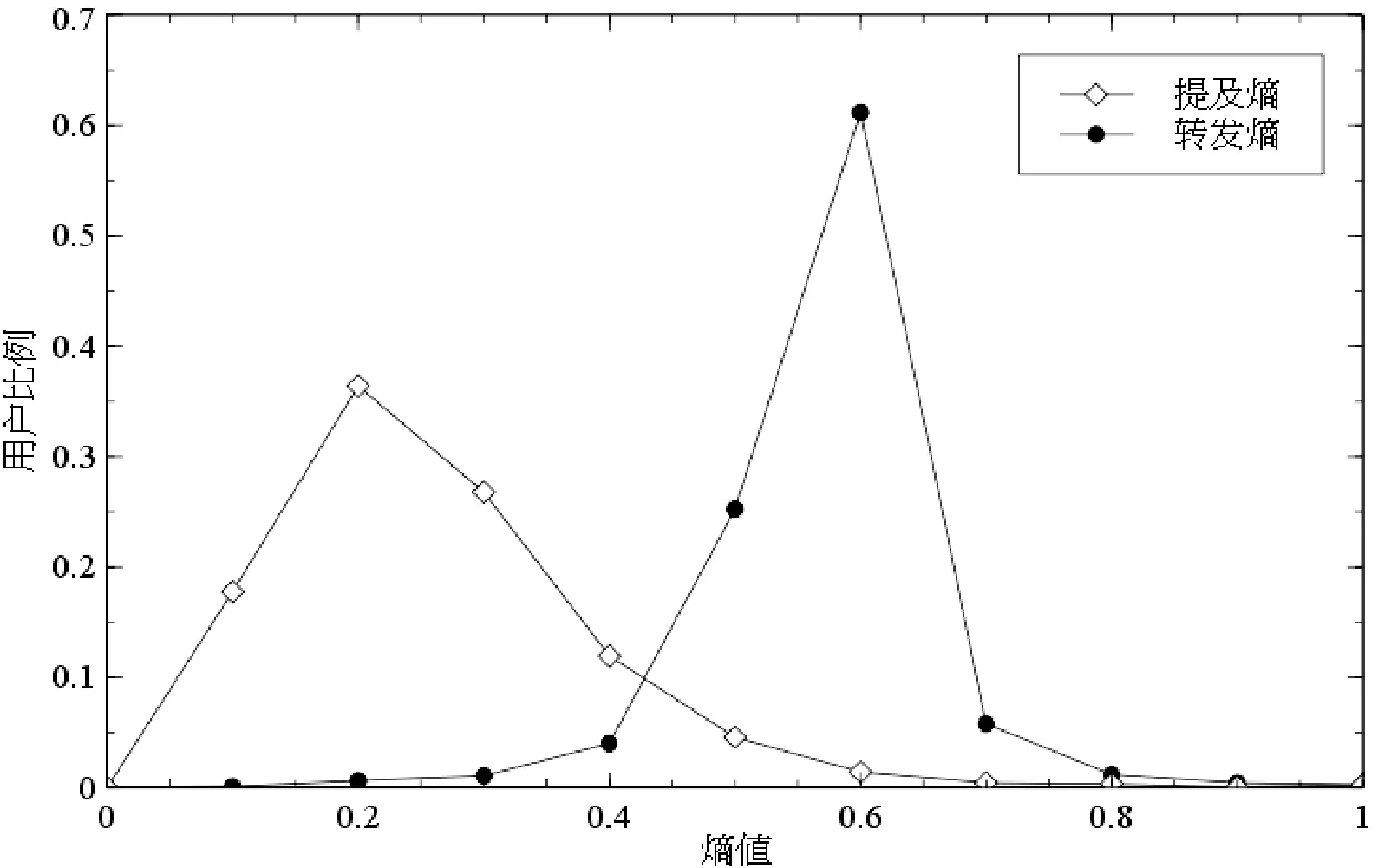
图2 用户在不同行为熵值区间的分布
从图2用户不同微博行为的熵值分布区间可以看出,用户的转发和提及行为具有明显区别。在转发行为中,用户峰值出现在0.5至0.6的熵值区间,而转发熵小于0.4的用户不到5%;在提及行为中,用户峰值出现在0.1至0.2的熵值区间,然后随着熵值的增大快速降低。这一现象说明用户的主要转发行为分布在较大的社区中,并且相对均匀的转发来自不同用户的微博,只有极少的用户只转发来自特定用户的微博。而大部分用户的提及行为集中在一个特定的小群体。
从图3可以看出,在用户的转发行为中,多数用户的不同时段的转发熵大于0.5,表明用户在不同时期频繁关注的用户集是变化的,用户在不断地寻求建立新的弱连接。而在用户的提及行为中,大部分用户的提及时间熵小于0.5,表明用户的直接交互关系相对稳定,不因时间的变化而变化。
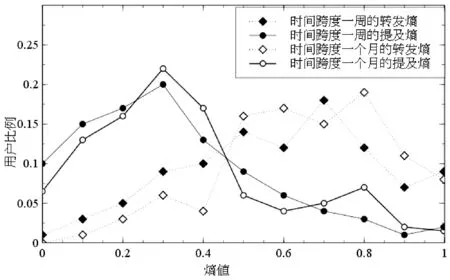
图3 用户转发、提及行为的动态性
表1给出了不同微博行为与社会网络的皮尔逊相关系数,以*表示p值(p-value)范围:p<0.005(***),p<0.05(**),p<0.1(*)。用户微博行为与其社会网络的皮尔逊积矩相关系数可以分析用户的微博交互行为和他的朋友数量,粉丝数量是否存在关联。

表1 微博行为与社会网络的皮尔逊相关系数
从表1可以看出用户发表微博的数量与用户的关注数量正相关(r=0.36)。而用户的转发和提及行为与粉丝/关注数量没有直接联系。微博数量和关注者的数量相关,但是用户间的交互与静态网络的规模无关。
3结语
在对社交网络的用户关系和交互的研究中,以用户为结点,用户间的关系为边的图模型是最常用的研究手段。然而随着社交网络规模的急剧膨胀,在有限的计算能力和存储空间的条件下分析用户交互行为是一个巨大的挑战。
本文以用户为单位,利用信息论理论对超过百万用户的海量微博数据进行建模和定量分析,通过交互之间的微博交互行为发现潜在的用户关系。文中的方法在分布式云计算平台实验环境下能大大提高对用户交互行为的分析效率。
实验表明在所有交互行为中,转发在微博活动中占主导地位。即使在单边通信关系中,微博用户更愿意从其他人那里获取信息:用户更愿意作信息接收者、传播者而不是信息发布者;我们发现用户发表的微博量与用户的关注数量正相关,而用户的粉丝数量对用户的微博交互行为几乎没有影响。本文还对新浪微博用户行为的细节和用户的交互随时间动态变化模式进行了研究,发现用户的转发对象会随着时间的推移而变化,而用户直接交流的用户集则相对稳定。在实验中还发现,用户间的关系强度会随着时间而变化,互相提及的用户关系的持久性更强。
在接下来的工作中,我们准备进一步完善用户的交互模型,分析交互行为相似用户的共有特点并利用该交互模型进行用户推荐以及用户在社区内的影响力排序。
参考文献
[1] 袁晶,谢幸.基于大规模行为数据的用户理解[J].中国计算机学会通讯,2014,10(5):14-17.
[2] Tiancheng L,Jie T,John H,et al.Learning to Predict Reciprocity and Triadic Closure in Social Networks[J].ACM Transactions on Knowledge Discovery from Data,2013,7(2):5.
[3] 肖宇,许炜,商召玺.微博用户区域影响力识别算法及分析[J].计算机科学,2012,39(9):38-42.
[4] Cha M,Haddadi H,Benecenuto F,et al.Measuring use rinfluence in twitter: The million follower fallacy[C]//ICWSM2010:Proceedings of International AAAI Conference on Weblogs and Social Media, Washington,DC,May 23-26, 2010 California:AAAI,2010.
[5] 曹玖,吴江林,石伟,等.新浪微博网信息传播分析与预测[J].计算机学报,2014,37(4):779-790.
[6] Hopcroft J,Lou T,Tang J.Who will follow you back? Reciprocal relationship prediction[C]//CIKM2011:Proceedings of the 20th ACM International Conference on Information and Knowledge Management,Scotland,UK,24th-28th October 2011.New York:ACM,2011:1137-1146.
[7] Tang J,Wu S,Sun J,et al.Cross-domain collaboration recommendation[C]//KDD2012:Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Beijing,August 12-16,2012.New York:ACM,2012.
[8] 郭磊,马军,陈竹敏.一种信任关系强度敏感的社会化推荐算法[J].计算机研究与发展,2013,50(9):1805-1813.
[9] Tang W,Zhuang H,Tang J.Learning to infer social ties in large networks[C]//ECML/PKDD2011:Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases,Athens,Greece,5-9 September,2011.Berlin:Springer,2011:381-397.
[10] Eric G,Karrie K.Predicting Tie Strength With Social Media[C]//CHI2009: Proceedings of the 27th International Conference on Human Factors in Computing Systems, Boston,4-9 April,2009.New York:ACM,2009.
[11] Kahanda I,Nevile J.Using transactional information to predict link strength in online social networks[C]//ICWSM2009:Proceedings of the 3rd International AAAI Conference on Weblogs and Social Media, San Jose, California, 17-20 May,2009.California:AAAI,2009.
[12] Hannon J,McCarthy K,Smyth B.Finding useful users on twitter:Twittomender the followee recommender[C]//ECIR2011:Proceedings of the 33rd European Conference on IR Research, Dublin, Ireland,18-21 April,2011.Berlin:Springer,2011.
[13] Mark S G.The Strength of Weak Ties[J].American Journal of Sociology,1973,78(6):1360-1380.
收稿日期:2015-02-15。国家自然科学基金项目(61272109);中央高校基本科研业务费专项资金项目(CZY15006)。刘晶,讲师,主研领域:社会媒休,数据挖掘。李琳,工程师。李石君,教授。
中图分类号TP393
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.009
ON USERS RELATIONSHIP BASED ON LARGE-SCALE BEHAVIOUR DATA IN SOCIAL NETWORKS
Liu Jing1,2Li Lin3Li Shijun1
1(SchoolofComputer,WuhanUniversity,Wuhan430072,Hubei,China)2(CollegeofComputerScience,South-CentralUniversityforNationalities,Wuhan430074,Hubei,China)
3(WuhanDigitalEngineeringResearchInstitute,Wuhan430074,Hubei,China)
AbstractUser relationship is the basis of microblogging social network formation. To analyse users relationship can help the better study in regard to the formation of social networks and the messages dissemination patterns, etc. In this paper we analyse and process massive microblogging data of more than one million users, and use information theory to analyse and compare the features of users microblogging behaviour, construct active users interaction network and observe its dynamics property, as well as analyse the online behaviour patterns and features of user groups in social networks. Experiments show that in microblogging interactions, direct interactive relationship between users are relatively stable and will not change along with the time going, while their forwarding objects are constantly change, that is, the groups actually concerned by the users are dynamically changing.
KeywordsSocial networkUser behaviourMicroblogInteraction
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
民用飞机设计与研究(2020年4期)2021-01-21
第一财经(2020年4期)2020-04-14
电子制作(2018年18期)2018-11-14
文苑(2018年17期)2018-11-09
商用汽车(2016年11期)2016-12-19
山东工业技术(2016年15期)2016-12-01
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
