
基于分步特征提取和组合分类器的电信客户流失预测模型
2016-08-04 02:07徐子伟王传启
网络安全与数据管理 2016年13期
徐子伟,王传启,王 鹏,黄 海
(中国科学技术大学 信息科学技术学院,安徽 合肥 230027)
基于分步特征提取和组合分类器的电信客户流失预测模型
徐子伟,王传启,王鹏,黄海
(中国科学技术大学 信息科学技术学院,安徽 合肥 230027)
摘要:针对电信客户流失数据集存在的数据维度过高及单一分类器预测效果较弱的问题,结合过滤式和封装式特征选择方法的优点及组合分类器的较高预测能力,提出了一种基于Fisher比率与预测风险准则的分步特征选择方法结合组合分类器的电信客户流失预测模型。首先,基于Fisher比率从原始特征集合中提取具有较高判别能力的特征;其次,采用预测风险准则进一步选取对分类模型预测效果影响较大的特征;最后,构建基于平均概率输出和加权概率输出的组合分类器,以进一步提高客户流失预测效果。实验结果表明,相对于单步特征提取和单分类器模型,该方法能够提高对客户流失预测的效果。
关键词:电信客户流失预测;分步特征提取;组合分类器
引用格式:徐子伟,王传启,王鹏,等. 基于分步特征提取和组合分类器的电信客户流失预测模型[J].微型机与应用,2016,35(13):51-54.
0引言
随着科学技术的快速革新,国内电信市场日趋饱和,竞争日益加剧。吸引新的客户和挽留已有客户成为电信行业客户关系管理的两个重要主题。据统计,吸引一个新客户的成本是挽留一个已有客户的5~6倍[1]。进行潜在流失客户的预测分析并制定有针对性的挽留策略,能够减少企业客户流失率和利润损失。因此,构建一个高效、准确的电信客户流失预测模型具有重大意义。
针对电信客户流失预测问题,国内外学者进行了广泛的研究,取得了丰富的研究成果。本文根据流失预测模型的构建策略,将这些文献粗略地分为基于单分类器和组合分类器的流失预测模型。例如,国内外学者分别构建了基于支持向量机(Support Vector Machine, SVM)[2]、决策树(Decision Tree, DT)[3-4]、逻辑斯蒂回归(Logistic Regression, LR)[3-4]、神经网络[5]、随机森林(Random Forest, RF)[6]、提升树[7]和朴素贝叶斯(Naive Bayes, NB)[8]分类算法的流失预测模型。相对于单分类器,组合分类器具有更好的预测性能。参考文献[9]针对移动和无线服务提供商中的流失预测问题,提出了一个基于RF、LR和DT的组合分类器。参考文献[10]提出了一个基于RF、旋转森林(Rotation Forest)和K-近邻的组合分类器进行潜在客户的流失预测分析,验证了组合分类器比单一分类器具有较好的预测性能。
然而,针对客户流失预测分析问题,很多学者重点关注于分类器的选择与调整,往往忽视了流失数据集中的维度过高问题。特征选择方法是一个解决高维度问题的有效方法,它能够从原始特征集合中选取重要特征,减少无用和噪声特征,提高分类器的预测准确性,减少计算资源的开销。在客户流失预测领域,基于专家经验知识和基本统计信息的特征选择是两种典型的特征选择方法。参考文献[6]采用最大相关和最小冗余算法选取与目标列具有较强相关性的特征集合,同时减少特征之间的冗余性。参考文献[11]提出一个基于专家经验知识和马尔科夫覆盖发现技术(Markov Blanket Discovery technique, MBD)的两步特征提取方法。
基于专家经验知识的特征选择方法往往具有主观性和片面性的缺点。基于统计信息的特征选择方法,即过滤式特征选择方法,采用特征列与目标列之间的统计信息构造相应指标以选取与目标列具有较强相关性的特征。该方法复杂度低,通用性强,可以快速去除不相关或相关度低的特征。然而,该方法的特征评估指标独立于分类算法,忽视了不同特征对分类器预测效果具有不同影响的问题。封装式特征选择方法根据分类器的评估指标对特征进行排序,如准确率、召回率或AUC等,能够详细评估每个特征对分类器预测效果的影响程度。
针对电信客户流失领域特征选择方法存在的上述问题和单分类器预测能力较弱的问题,本文结合过滤式和封装式特征选择方法的优点以及组合分类器较强的预测性能,提出了一种基于Fisher比率和预测风险(Prediction Risk, PR)准则的两步特征提取方法(本文命名为FP-PR算法),并结合组合分类器的电信客户流失预测模型。该模型首先采用Fisher比率从原始特征集合中选取具有较强判别能力的特征;在此基础上,结合预测风险准则,进一步提取对分类器预测效果影响较大的特征。然后,结合Spark大数据处理框架,采用NB、线性支持向量机(Linear Support Vector Machine, LSVM)、LR、DT和RF构建单分类器预测模型。最后,按照“优胜劣汰”原则,选取预测性能较好的3个分类器构建组合分类器,以提高流失预测准确率。
1前述方法描述
参考数据挖掘的一般流程,本文提出的电信客户流失预测模型的构建过程如图1所示。
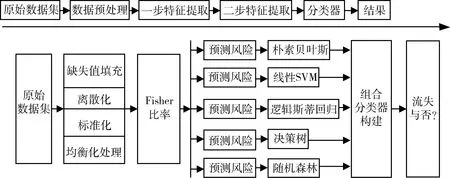
图1 客户流失预测模型构建流程
该过程包括基本数据预处理、两步特征提取和组合分类器构建3个关键环节。其中,基本数据预处理包括缺失值填充、标准化、离散化和类别不均衡问题处理。
1.1基本数据预处理
本文采用KDD竞赛Orange电信数据集进行实验分析与方法验证。该份数据集数据质量非常差,需要进行大量的数据预处理工作。数据预处理的目的是对原始数据集进行转换处理,以满足数据挖掘工具与算法的要求。本实验基本数据预处理包含缺失值填充、标准化、离散化和均衡化处理。此外,传统的分类算法包含类别样本近似均衡的假设条件。然而,电信客户流失数据集是一个典型的不均衡数据集,正负样本比例为1 ∶12.62。传统的数据不均衡问题处理方法主要有采样和调整分类算法参数估计方法。本实验为了避免随机抽样过程中随机因素导致的结果不稳定问题,采用过采样策略构建均衡样本数据集。
1.2两步特征提取方法
本文针对流失数据集中的维度较高以及该领域特征选择方法存在的上述问题,结合过滤式和嵌入式特征选择方法的优点,提出了基于Fisher比率和预测风险准则的两步特征提取方法,算法描述如下:
算法1:FR-PR算法
输入:训练数据集T={(x,y)},Fisher比率所选特征数为f1,预测风险所选特征数为f2,分类器C
输出:优化特征子集F_Optimal
(1)开始;
(2)根据Fisher比率公式计算特征i对应的Fisher比率Fi;
(3)根据Fi值降序排列所有特征,并选取前f1个特征作为一步特征提取的优化特征子集;
(4)根据步骤(3)选择的f1个特征,重新构建数据集T-temp;
(5)基于T-temp数据集和所有f1个特征,计算分类器C对应的AUC指标;
(6)将特征j对应的所有样本以特征j的样本均值替代,根据预测风险公式计算AUC(j)和R(j);
(7)根据R(j)值重新降序排列Fisher比率得到的f1个特征,并选择前f2个特征作为优化特征子集F_Optimal
(8)结束。
基于Fisher比率的特征选择是一种过滤式特征选择方法。结合每个类别对应样本的均值和方差,Fisher比例能够筛选出具有较强判别能力的特征。Fisher比率的公式如下:
(1)
其中,ui、σi是每个类别对应特征i样本的均值与方差。Fisher′s Ratio(i)代表特征i对应的Fisher比率,该值越大,说明特征i对目标列的判别能力越强。
预测风险准则是一种嵌入式特征选择方法,该方法通过将特征i的所有样本以该特征的均值代替,结合分类模型评估指标(本文取AUC)来判别特征i对分类器的影响程度。特征i对应的预测风险如下:
Ri=AUC-AUC(i)
(2)
其中,AUC指Fisher比率所选特征对应分类模型的评估指标,AUC(i)指将特征i所有样本以均值替代后的特征集合对应的分类模型评估指标。Ri为两者之差,代表特征i的预测风险。Ri大于0的程度越大,说明特征i对分类模型预测效果的影响越大。
1.3组合分类器构建
本实验结合大数据处理框架Spark,分别构建了基于NB、LSVM、LR、DT和RF分类算法的流失预测模型,并采用AUC评估指标来判别分类器预测性能的好坏。在此基础上,从5种分类模型中选取3个预测性能较好的分类器构建组合分类器。本文的组合分类器构建方法如下:
算法2:组合分类器构建方法
输入:分类器Ci,i=1,2,…,n
输出:组合分类器C及其预测概率输出
(1)开始;
(2)根据两步特征提取的优化特征子集训练n个分类器C1,C2,…,Cn,计算相应的分类评估指标AUC(i);
(3)根据各个分类器对应的AUC值,选取前m个预测性能较好的分类器Cj,j=1,2,…,m,对应预测概率输出为pj;
(4)依据如下策略构建组合分类器C,并计算组合分类器对应的预测概率输出p:
①组合分类器C的概率输出p取值为m个分类器的平均概率输出:
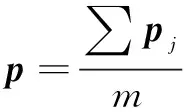
②组合分类器C的概率输出p取值为m个分类器的加权平均概率输出:
p=∑wj·pj,其中wj=AUC(j)/∑AUC(k),k=1,2,…,m
(5)结束。
组合分类器构建的两种主要方法是多数投票和组合概率输出。本文采用组合概率输出的方式构建组合分类器模型,并结合平均概率输出和加权平均概率输出的方式确定组合分类器的概率输出。平均概率输出组合分类器模型对各个分类器模型的概率输出进行平均化处理,而加权平均概率输出组合分类器模型对各个分类器模型的概率输出进行加权求和。其中,加权概率输出模型的权重由各个分类器的AUC指标进行单位化处理求得。
2实验结果及其分析
2.1数据集描述
Orange数据集包含230个特征(190个数值特征和40个类别特征)和50 000个样本(3 672个正类样本和4 6328个负类样本)。本实验将该数据集以7 ∶3的比例分割为训练集和测试集。训练集由前2 570个正类样本和前32 430个负类样本构成,测试集由其余样本构成。
2.2实验结果与分析
如前所述,本文客户流失预测模型构建过程包括基本数据预处理、两步特征提取(以One和Two表示)和组合分类器构建3个主要步骤。其中,基本数据预处理包含空值填充、离散化、标准化和均衡化(以Fill、Disc、Stan和Bal表示)。组合分类器的构建采用平均概率输出和加权概率输出两种策略(以Ens1和Ens2表示)。本文对每一步数据处理产生的实验结果进行展示和分析,如表1所示。
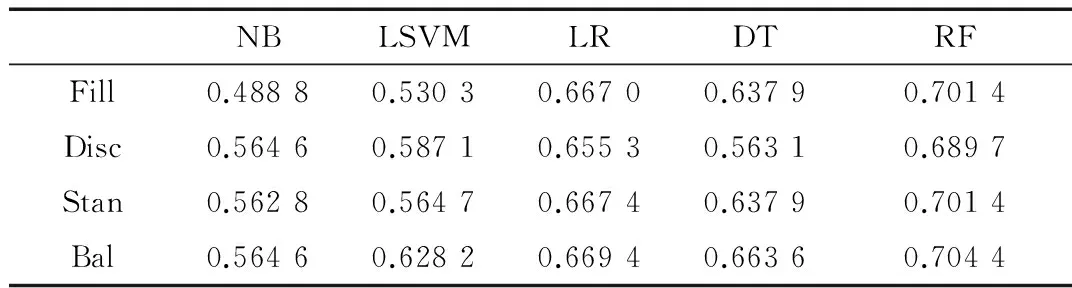
表1 基本数据预处理实验结果
如表1所示,离散化和标准化处理能够明显提升NB和LSVM的预测效果。然而,不合理的离散化方式降低了LR、DT和RF的预测效果。此外,均衡化数据处理能够提高各分类器的预测效果,这是由于传统的分类算法往往包含类别样本近似均衡的假设条件。分步特征提取对预测结果的影响如表2所示。
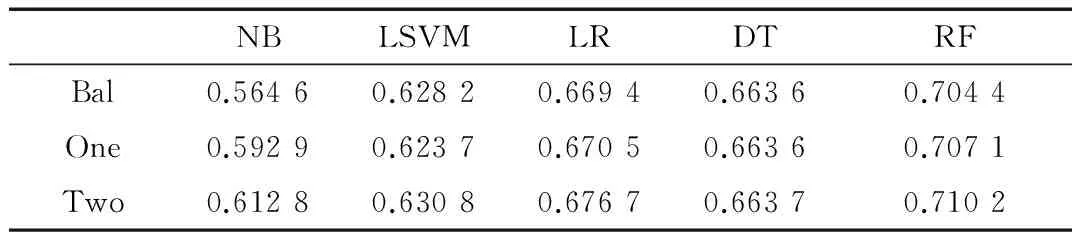
表2 一步和两步特征提取实验结果
如表2所示,特征提取能够提高分类器的预测效果。相比一步特征提取,本文提出的两步特征提取方法能够进一步提高分类器的预测性能。然而,由于基于基尼指数的特征选择方法所选的特征类似于两步特征选择方法提取的特征,决策树的预测效果变化不大,这也间接说明了决策树算法较强的鲁棒性。由表2得知,LR、DT和RF具有较强的预测性能,本文选取这三种分类算法构建组合分类器。其中,LR采用均值填充、均衡化处理和两步特征提取到的60个特征进行模型的构建;DT采用离散化、均衡化处理和两步特征提取到的90个特征进行模型的训练;而RF采用均值填充、均衡化处理和两步特征提取的70个特征进行模型的训练。如前所述,本文采用平均概率输出和加权概率输出的方式构建组合分类器。实验结果如表3所示。
如表3所示,基于组合分类器的客户流失预测模型预测效果优于单个分类器。基于加权平均概率输出的组合分类器预测效果优于基于平均概率输出的组合分类器,因为加权概率输出的策略提升了预测效果较好的单一分类器在组合分类器中的权重。本文提出的基于两步特征提取和加权组合分类器的电信客户流失预测模型取得了最优预测效果0.7201AUC。
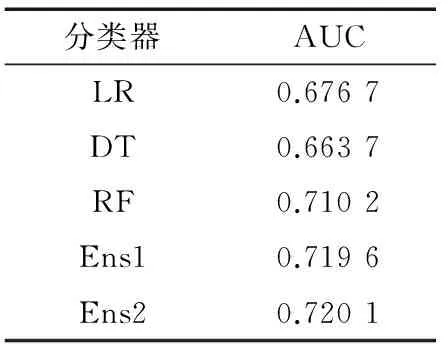
表3 3个最优分类器和
3结论
本文针对电信客户流失数据集中的维度较高和单一分类器预测效果较弱的问题,提出了基于两步特征提取和组合分类器的客户流失预测模型构建方法。结合过滤式特征选择和封装式特征选择方法的优点,构建了基于Fisher比例和预测风险的两步特征提取方法。该方法提取的优化特征子集具有较强的判别能力,同时对分类器的预测效果影响较大。此外,为了进一步提高分类器的预测效果,本文基于“优胜劣汰”的思想构建了组合分类器。实验结果表明,本文提出的两步特征提取和组合分类器的电信客户流失预测模型取得了较好的预测效果。然而,本文构建的两步特征选择方法仅采用了一种过滤式特征选择方法和一种嵌入式特征选择方法。在下一步研究中,将尝试更多的特征提取方法以寻求最优方法组合,同时探索更优的类别不均衡问题处理方法,以优化客户流失预测模型预测效果。
参考文献
[1] KOTLER P. Marketing management: analysis, planning, implementation, and control[J]. The Prentice-Hall Series in Marketing, 1988, 67(11):297-320.
[2] COUSSEMENT K, VAN DEN POEL D. Churn prediction in subscription services: an application of support vector machines while comparing two parameter-selection techniques[J]. Expert Systems with Applications, 2008, 34(1): 313-327.
[3] HUANG B Q, KECHADI M-T, BUCKLEY B. Customer churn prediction for broadband Internet services[C]. Data Warehousing and Knowledge Discovery, 11th International Conference, DaWaK 2009, Linz, Austria, 2009: 229-243.
[4] NIE G, ROWE W, ZHANG L, et al. Credit card churn forecasting by logistic regression and decision tree[J]. Expert Systems with Applications, 2011, 38(12): 15273-15285.
[5] TSAUI C F, LU Y H. Customer churn prediction by hybrid neural networks[J]. Expert Systems with Applications, 2009, 36(10): 12547-12553.
[6] IDRIS A, RIZWAN M, KHAN A. Churn prediction in telecom using Random Forest and PSO based data balancing in combination with various feature selection strategies[J]. Computers & Electrical Engineering, 2012, 38(6): 1808-1819.
[7] IDRIS A, KHAN A, LEE Y S. Genetic programming and adaboosting based churn prediction for telecom[C]. Systems Man and Cybernetics (SMC), 2012 IEEE International Conference on. IEEE, 2012: 1328-1332.
[8] HADDEN J, TIWARI A, ROY R, et al. Computer assisted customer churn management: State-of-the-art and future trends[J]. Computers & Operations Research, 2007, 34(10): 2902-2917.
[9] YABAS U, CANKAYA H C. Churn prediction in subscriber management for mobile and wireless communications servi-ces[C]. Globecom Workshops (GC Wkshps), 2013 IEEE. IEEE, 2013: 991-995.
[10] IDRIS A, KHAN A. Ensemble based efficient churn prediction model for telecom[C]. Frontiers of Information Technology (FIT), 2014 12th International Conference on. IEEE, 2014: 238-244.
[11] HONG, X, ZHANG Z G, ZHANG Y S. Churn prediction in telecom using a hybrid two-phase feature selection me-thod[C].Intelligent Information Technology Application, 2009. IITA 2009. Third International Symposium on. IEEE, 2009, 3: 576-579.
中图分类号:TP181
文献标识码:A
DOI:10.19358/j.issn.1674- 7720.2016.13.017
(收稿日期:2016-04-01)
作者简介:
徐子伟(1989-),男,硕士,主要研究方向:数据挖掘。
王传启(1993-),男,硕士,主要研究方向:数据挖掘。
王鹏(1988-),男,博士,博士后,主要研究方向:移动机器人导航与定位,数据挖掘。
A telecom customer churn prediction model based on two-stage feature selection method and ensemble classifier
Xu Ziwei,Wang Chuanqi,Wang Peng,Huang Hai
( School of Information Science and Technology, University of Science and Technology of China, Hefei 230027, China )
Abstract:To solve the high dimensionality problem in telecom dataset and the weak forecasting ability of single classifiers, this paper proposes a telecom churn prediction model based on two-stage feature selection method and ensemble classifier, taking advantages of filter and wrapper selection method and ensemble classifiers with better forecasting performance. The two-stage feature selection method is based on Fisher′s ratio and prediction risk. Firstly, features with high discriminative ability are selected by Fisher′s ratio. Then we use prediction risk to further select features that have great impacts on classifiers. Lastly, two ensemble classifiers based on the average probability and weighted average probability are constructed to further improve the forecasting performance. Experimental results verify that the proposed method can improve the forecasting performance compared to the model based on one-step feature selection method or single classifier.
Key words:telecom churn prediction; two-stage feature selection; ensemble classifier
