
加权网络中基于多路径节点相似性的链接预测
2016-08-04 07:05:36郭景峰刘苗苗
浙江大学学报(工学版) 2016年7期
郭景峰,刘苗苗,罗 旭
(1. 燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2. 东北石油大学 秦皇岛分校, 黑龙江 大庆 163318;3. 燕山大学 河北省虚拟技术与系统集成重点实验室,河北 秦皇岛 066004)
加权网络中基于多路径节点相似性的链接预测
郭景峰1,3,刘苗苗1,2,3,罗旭1,3
(1. 燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2. 东北石油大学 秦皇岛分校, 黑龙江 大庆 163318;3. 燕山大学 河北省虚拟技术与系统集成重点实验室,河北 秦皇岛 066004)
摘要:鉴于现有大多数链接预测算法仅考虑了图的局部或全局特性,在预测准确率和计算复杂度上难以均衡,且有关加权网络的链接预测研究相对较少,提出新的加权社会网络链接预测算法(STNMP).引入节点对边权强度的概念,用于度量邻居节点间的局部相似度.提出路径相似性贡献的概念,定义多路径传输节点相似性,用于描述步长为2和3的所有路径及这些路径上的中间节点对于所连接的两个节点的相似性总贡献.在多个真实网络中对算法的有效性进行验证,以AUC作为评价指标,与经典相似性算法CN、Jaccard、AA等进行预测准确率的对比分析.结果显示,针对小规模社会网络,STNMP算法的预测准确率高于现有算法.
关键词:链接预测;加权社会网络;边权强度;路径相似性贡献;多路径传输节点
社会网络是高度动态的,网络中实体之间的关系不断演化发展,链接预测成为了一项热门研究,在推荐系统、信息检索、社会网络结构动态演变分析[1]、符号网络中的节点分类[2]等众多领域有着广泛的研究和应用.链接预测指通过已知的网络结构信息预测网络中尚未产生连接边的两个节点间产生链接的可能性,分为未知链接预测和未来链接预测[3].未知链接预测是预测已经存在但尚未被发现的链接,是一种数据挖掘过程,在蛋白质相互作用网[4]这类生物学网络中有着重要的研究意义和应用价值.未来预测是对未来可能产生的连接边的预测,与网络结构的演化相关.本文关注未来预测的研究.
1相关研究
主流的链接预测算法是通过节点固有属性定义基于节点相似性的算法,即两个节点具有较多的共同特征,则两者的相似度较高.现有基于相似性的链接预测方法绝大多数都是针对无权网络,大体可以分为两类.一类是基于节点局部信息的相似性算法如CN指标[5]、Jaccard算法[6]、Adamic-Adar算法[7]和优先依附PA(preferentialattachment)算法[8]等.该类算法主要利用了节点及邻居节点的度的信息,思路简单,容易实现,计算复杂度较低且通常能够获得较好的预测结果.该类算法忽略了邻居节点间的联系,不能有效地挖掘网络拓扑信息对节点间相似性的影响.另一类是基于路径结构的相似性算法,如最短路径算法[9]、Katz指标[10]和局部路径算法(localpath,LP)[11]等.该类算法考虑连接节点对的全部或部分路径对于节点对的相似性贡献,但忽略了路径上传输节点的局部相似度对节点对的相似性影响,且计算两节间所有路径信息的复杂度较高.此外,Zhou等[12]研究9种著名的局部相似性指标,提出2种新的局部指标.Panagiotis等[13]提出FriendTNS(friendtransitivenodesimilarity)算法,利用最短路径上过渡节点局部相似度乘积来度量扩展后的相似度.李淑玲[14]提出CNBIEC(commonneighborsbasedonindividualeffectcoefficient)算法,利用公共邻居节点间的链接信息提高预测的准确率.李彦敏[15]提出基于链接间依赖程度的链接预测算法,重点研究各个链接之间的关系.加权网络的链接预测是一个重要的方向,然而目前相关的系统研究工作较少.涂一娜[16]引入节点权重和链路权重概念,提出基于时间感知的加权网络链接预测算法,获得了较好的效果.Lv等[17]使用局部相似性指标估计加权网络中链接存在的可能性,提出3种加权相似性指标,可以分别看作CN、AA和RA(resourceallocation)的变体,但这些加权指标在NetScience和USAirports网络中的实验结果不理想.
鉴于现有算法的局限性,本文提出新的链接预测算法STNMP,基于节点对间的多条路径以及路径上相邻传输节点间的局部相似性实现加权网络中的链接预测.
2STNMP算法核心思想
基于相似性的链接预测算法认为两节点间的相似性越高,两者建立链接的可能性越大.算法的关键是有效地捕获网络的局部和全局特性对节点相似性的影响,给出合理的相似性指标计算方法,提高算法的预测准确率和执行效率.
在度量节点局部属性对相似性的影响时,认为不是邻居的两节点间局部相似性为0.度数小的节点比度数大的节点对局部相似性的贡献大.权重表示两节点间连接的紧密程度,节点间的局部相似性应与权重有关.提出边权强度的概念,用于度量邻居节点间的局部相似性.
在度量路径信息对节点相似性的影响时,认为两节点间的距离越远,两者存在链接的可能性越小.节点对间长度较短的路径对于两节点的相似性贡献大于较长的路径.提出路径相似性贡献的概念,用于描述某条路径对连接的节点对的相似性贡献.基于路径步长这一概念,定义多路径传输节点的相似性,描述不同步长的所有路径对节点对相似性的总贡献.
将多路径传输节点的相似性作为节点对链接预测的分数,依据相似性定义公式计算网络图中所有尚未建立链接的节点对间的相似性得分,按降序排列,排在最前面的节点对建立链接的可能性最大.
3相关定义
为了准确描述算法中节点对的相似性定义,给出如下相关说明:加权社会网络图G=(V,E,W)、节点集V、边集E、边的权重集合W.w(vi,vj)为节点vi与vj连接边的权重.对于无权网络,所有边的权重默认为1.
定义1节点的强度设G=(V,E,W),vi∈V,{e(vi)}⊆E是所有连接vi的边的集合.定义节点vi的强度为
s(vi)=∑w(e(vi)).
(1)
使用节点的强度来度量某节点的边权比重在网络中的重要性,等于与该节点相连的所有边的权重之和.节点的强度越大,表明与该节点相连的边的权重之和在整个网络中所有边的权重之和中所占的比例越大.对于无权网络,节点的强度为节点的度.
定义2边权强度设G=(V,E,W),vi、vj∈V,定义节点对
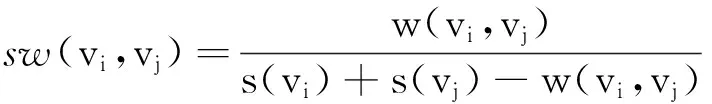
(2)
节点对
定义3路径相似性贡献设G=(V,E,W),vi、vj∈V,连接vi到 vj的第k条路径为lk(vi,vj)=vieikvk1ek1vk2…eknvj,定义路径lk对节点对
SLk(vi,vj)=lsim(vi,vk1)×lsim(vk1,vk2)×
…lsim(vkn,vj).
(3)
使用路径相似性贡献来度量连接节点对
定义4相似性贡献设G=(V,E,W),vi、vj∈V,连接vi到 vj的所有路径组成的集合为L={l1,l2,…,lp},定义连接vi到vj的所有路径对节点对
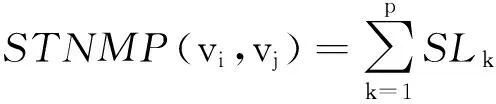
(4)
相似性贡献度量了连接vi与vj的所有路径对于节点对
定义5路径的步长设G=(V,E,W),vi、vj∈V,连接节点对
4算法实现步骤
输入:无向加权网络图G的邻接矩阵A.若节点vi与vj是邻居,则aij=w(vi,vj),否则aij=0.
输出:Topk个最可能建立链接的节点对.
算法的实现步骤如下.
1)根据定义3.2计算G中任意相邻节点对间基于边权强度的局部相似性得分lsim(vi,vj),并使用链表存储结果(vi,vj,lsim(vi,vj)).
2)任取vi、vj∈V,且e(vi, vj)∉E.根据定义3.3计算所有|l(vi,vj)|≤6的相似性贡献STNMP(vi,vj),并存储结果(vi,vj,STNMP(vi,vj)).
3)将STNMP(vi,vj)降序排序,取前k个节点对作为图G基于多路径传输节点相似性的链接预测结果.
5实验与分析
通过网络获得实验所需的数据集,划分出训练集和测试集.采用AUC[18]作为评价指标,与CN、Jaccard、AA以及FriendTNS算法在预测确率方面进行对比分析,验证了该算法的预测准确率总体高于现有算法.
5.1实验所用数据集
采用6个典型的真实数据集,代表不同的网络类型.前四个为加权网络,后两个为无权网络.所选的数据集拓扑结构信息如表1所示.
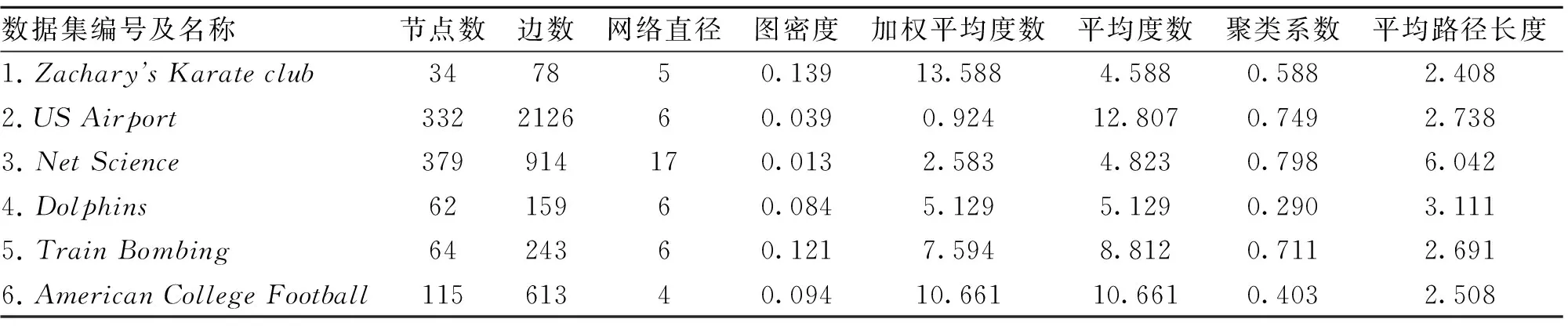
表1 数据集拓扑结构信息
5.2训练集与测试集的划分
为了衡量算法预测结果的准确率,将已知的边集E划分为训练集和测试集.常用的划分方法是将数据集随机分成10个子集,每次实验选择一个子集作为测试集,剩下的 9个子集组成的集合作为训练集.如此重复10次,保证10个子集都恰好被作为一次测试集,且所有样本数据既进行了训练,也进行了测试验证.
在实验中,针对每个数据集,随机从E中取10%的边作为测试集,记作ETe.剩下的90%的边作为训练集,记作ETr.满足E=ETe∪ETr且ETe∩ETr=∅,保证所得训练集中的边能够组成一个联通图.将训练集中的信息看作已知信息,测试集用来进行测试,验证算法预测的准确程度.
5.3评价指标
常用的链接预测准确度的评价指标有AUC、Precision和RankingScore3种.三者的侧重点不同:AUC从整体上衡量算法准确度;Precision只评价排在前L位链接的预测准确率,与实际实验中的L取值有很大关系;RankingScore侧重评价预测链接的排序情况[3].
鉴于AUC是目前被绝大部分链接预测算法广泛采用的综合性评价指标,本文使用AUC作为算法预测准确率的衡量指标.AUC可以理解为测试集中边的分数比随机选择的不存在的边的分数高的概率[18].每次随机从测试集中选取一条边与随机选择的不存在的边进行比较,若前者的分数大于后者,则加1分;若两个分数相等,则加0.5分.独立比较n次,若有n′次测试集中边的分数大于不存在的边的分数,有n″次两者分数相等,则AUC定义为:AUC=(n′+0.5n″)/n.若所有分数都是随机产生的,则AUC=0.5.AUC大于0.5的程度衡量了算法在多大程度上比随机选择的方法精确.在实验中,AUC指标中n设定为20 000.
5.4算法性能对比分析5.4.1步长的选择在最初的实验中,针对每个数据集随机抽取划分出训练集和测试集,计算了节点对间步长2≤|l|≤6的多路径传输节点相似性值.在相同的实验环境下,重复执行10次,得到AUC评价指标下基于不同步长的STNMP算法预测准确率(见表2)及算法运行消耗时间(见表3).表2、3中的第1列为实验所用的数据集,第2~5列分别为取步长2≤|l|≤6的不同路径时对应的预测准确率和运行时间,所得的数据是10次独立运行结果的平均值.
从表2、3的数据可知,随着步长的增大,运行时间显著增加,准确率下降.针对实验所用的数据集,取步长为2和3的所有路径相似性贡献时,所得的预测准确率均达到最高值.考虑到绝大多数网络的最短路径平均长度均约为3,且根据六度空间理论可知,社会网络中任意两节点均可以通过步长≤6的路径相连.基于此,为了避免计算两节点间步长≤6的所有路径相似性贡献带来的高计算复杂度,后期改进的STNMP算法将步长上限设置为3,将基于多路径节点的相似性定义为两节点间步长为2和3的所有路径的相似性贡献,在保证算法执行效率的前提下实现了更高的预测准确率.

表2 基于不同步长的STNMP算法预测准确率

表3 基于不同步长的STNMP算法运行消耗时间
5.4.2预测准确率 针对加权网络,将STNMP算法与Lv等[17]给出的加权CN、加权AA和加权Jaccard指标进行预测准确率的对比.针对无权网络,将STNMP指标与李淑玲[14]给出的CN、Jaccaard、AA以及FriendTNS[13]算法进行对比.图1、2分别给出针对不同的加权和无权网络数据集AUC评价指标下每种算法的预测准确率.
从图1、2可知,针对AUC评价指标, 6个网络中STNMP算法的预测准确率都是最高的.说明在该类节点平均度数较小、节点度及权重差异较小的网络中,基于边权强度的局部相似性定义达到了较好的效果.AUC指标结果显示,针对加权及无权网络中的链接预测,STNMP算法的准确率总体上优于现有算法,达到了较好的预测效果.
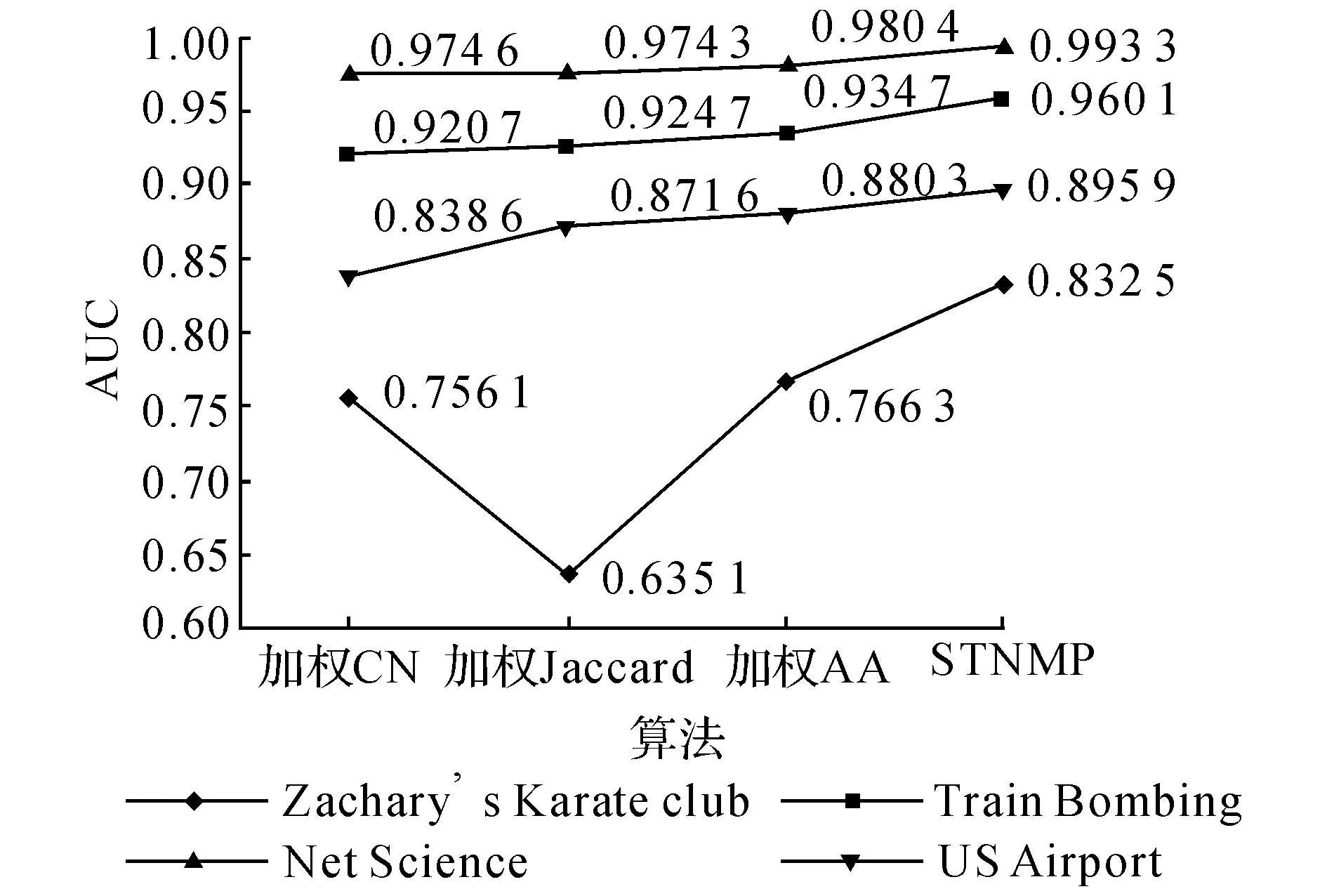
图1 加权网络中不同算法链接预测准确率对比Fig.1 Comparision of prediction accuracy of different algorithms in weighted networks
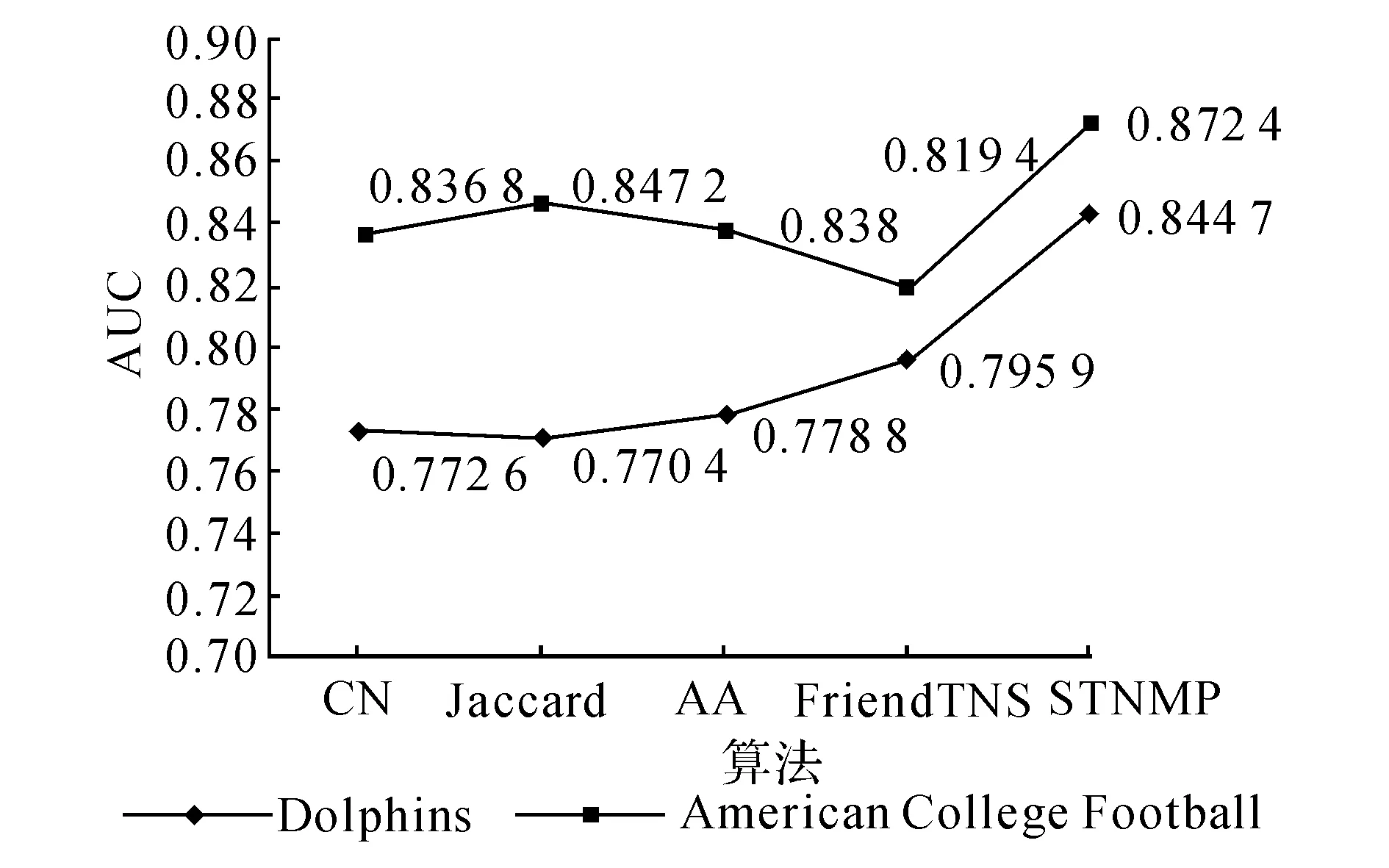
图2 无权网络中不同算法链接预测准确率对比Fig.2 Comparision of prediction accuracy of different algorithms in unweighted networks
5.4.3复杂度分析STNMP算法使用矩阵和链表存储图边关系和相似性,计算了连接两节点的步长为2和3的所有路径的相似性贡献.与其他几种算法相比,该算法的计算复杂度提高.对于小规模网络,该算法在达到较高预测准确率的前提下,仍可保证时间上的可行性和有效性.
6结语
本文提出链接预测算法STNMP,首先定义了边权强度和路径相似性贡献,在此基础上定义了节点对间步长为2和3的多路径传输节点相似性,用于加权社会网络中的链接预测.使用AUC作为评价指标,在多个真实数据集上进行实验,并与经典相似性链接预测算法进行性能对比.实验结果验证了该算法较高的预测准确率和良好的通用性.该算法有待在大规模真实网络中进一步验证,以改进相似性指标的定义,有效地提高算法执行效率.有关符号网络中的节点类型预测,并结合结构平衡理论分析预测产生的新链接对于网络结构整体平衡性的影响,是下一步的研究工作.
参考文献(References):
[1]KUMARR,NOVAKJ,TOMKINSA.Structureandevolutionofonlinesocialnetworks[C]∥ProceedingsoftheACMSIGKDD.NewYork:ACM, 2006: 611-617.
[2]GALLAGHERB,TONGH,ELIASSI-RADT,etal.Usingghostedgesforclassificationinsparselylabelednetworks[C]∥ProceedingsoftheACMSIGKDD.NewYork:ACM, 2008: 256-264.
[3] 吕琳媛. 复杂网络链路预测[J]. 电子科技大学学报, 2010, 39(5): 651-661.
LVLin-yuan.Linkpredictionofcomplexnetworks[J].JournalofUniversityofElectronicScienceandTechnologyofChina, 2010, 39(5): 651-661.[4]YUH,BRAUNP,YILDIRIMMA,etal.High-qualitybinaryproteininteractionmapoftheyeastinteractomenetwork[J].Science, 2008, 322(5898): 104-110.
[5]NEWMANM.Thestructureandfunctionofcomplexnetworks[J].SIAMReview, 2003, 45(2): 167-256.
[6] 张扬夫. 有向与加权网络的链路预测[D]. 湘潭:湘潭大学, 2011: 5-11.
ZHANGYang-fu.Linkpredictionindirectedandweightednetworks[D].Xiangtan:XiangtanUniversity, 2011: 5-11.
[7]ADAMICL,ADARE.Howtosearchasocialnetwork[J].SocialNetworks, 2005, 27 (3): 187-203.
[8]NEWMANM.Clusteringandpreferentialattachmentingrowingnetworks[J].PhysicalReviewE, 2001, 64(2): 025102-1-4.
[9] 姚尊强.加权复杂网络的分析和预测[D]. 青岛: 青岛理工大学, 2012: 35-43.
YAOZun-qiang.Theanalysisandpredictionofweightedcomplexnetworks[D].Qingdao:QingdaoTechnologicalUniversity, 2012: 35-43.
[10]KATZL.Anewstatusindexderivedfromsocialmetricanalysis[J].Psychometrika, 1953, 18(1): 39-43.
[11] 张珊靓, 周晏. 基于随机游走的时间加权社会网络链接预测算法[J].计算机应用与软件, 2014, 31(7): 28-30.
ZHANGShan-liang,ZHOUYan.Timeweightedsocialnetworkslinkpredictionalgorithmbasedonrandomwalk[J].ComputerApplicationandSoftware, 2014, 31(7): 28-30.
[12]ZHOUTao,LVLin-yuan,ZHANGYi-cheng.Predictingmissinglinksvialocalinformation[J].TheEuropeanPhysicalJournalB, 2009, 10(1140): 623-630.
[13]PANAGIOTISS,ELEFTHERIOST,YANNISM.Transitivenodesimilarityforlinkpredictioninsocialnetworkswithpositiveandnegativelinks[C]∥Proceedingsofthe4thACMConferenceonRecommenderSystem.Barcelona:ACM, 2010: 183-190.
[14] 李淑玲. 基于相似性的链接预测方法研究[D]. 哈尔滨:哈尔滨工程大学, 2012: 25-46.
LIShu-ling.Researchonlinkpredictionmethodsbasedonthesimilarity[D].Harbin:HarbinEngineeringUniversity, 2012: 25-46.
[15] 李彦敏.基于链接依赖度的链接预测[D].长春:吉林大学, 2013: 20-33.
LIYan-min.Linkpredictionbasedonlinkdependency[D].Changchun:JilinUniversity, 2013: 20-33.
[16] 涂一娜. 具有时间感知的加权网络链路预测研究[D]. 长沙: 中南大学, 2014: 20-43.
TUYi-na.Studyonlinkpredictionoftheweightednetworkswithtime-aware[D].Changsha:ZhongnanUniversity, 2014: 20-43.
[17]LVLin-yuan,ZHOUTao.Linkpredictioninweightednetworks:theroleofweakties[J].EurophysicsLetters, 2010, 89: 18001.
[18] 余宏俊. 基于符号网络的社群分析方法研究[D]. 武汉:华中科技大学, 2011: 31-32.
YUHong-jun.Theresearchofcommunityanalysisbasedonsignedsocialnetworks[D].Wuhan:HuazhongUniversityofScienceandTechnology, 2011: 31-32.
收稿日期:2015-10-17.浙江大学学报(工学版)网址: www.journals.zju.edu.cn/eng
基金项目:国家自然科学基金资助项目(61472340);河北省秦皇岛市科技支撑资助项目(201502A003).
作者简介:郭景峰(1962-),男,教授,博导,从事数据挖掘、社会网络分析研究. 通信联系人:刘苗苗,女,副教授.ORCID: 0000-0001-8569-0693. E-mail:liumiaomiao82@163.com
DOI:10.3785/j.issn.1008-973X.2016.07.017
中图分类号:TP 391
文献标志码:A
文章编号:1008-973X(2016)07-1347-06
Linkpredictionbasedonsimilarityofnodesofmultipathinweightedsocialnetworks
GUOJing-feng1,3,LIUMiao-miao1,2,3,LUOXu1,3
(1. College of Information Science and Engineering, Yanshan University, Qinhuangdao 066004, China;2. Qinhuangdao Branch,Northeast Petroleum University, Daqing 163318, China; 3. Key Laboratory for Computer Virtual Technology and System Integration of Hebei Province, Yanshan University,Qinhuangdao 066004, China)
Abstract:A novel algorithm similarity based on transmission nodes of multipath (STNMP) for link prediction in weighted social networks was proposed in view of the fact that most link prediction algorithms only considered local or global characteristics of the graph, which was difficult to achieve equilibrium in the prediction accuracy and the computational complexity, and researches on link prediction in weighted social networks were relatively less. The concept of the edge weight strength was introduced to measure the local similarity of neighbor node pairs. The similarity of transmission nodes of multipath was proposed and the definition of the path similarity contribution was given, which were used to describe the total contribution of all these paths of 2 and 3 paces to the similarity of node pairs. The effectiveness of the algorithm was verified through experiments on many real networks. The comparison and analysis on prediction accuracy of the algorithm were conducted with those classical link prediction algorithms based on the similarity index, such as common neighbor (CN), Jaccard and Adamic-Adar under the evaluation index of area under the receiver operating characteristic curve (AUC). Results showed the accuracy of STNMP algorithm was higher than those of existing algorithms for small scale of social network.
Key words:link prediction; weighted social network; edge weight strength; path similarity contribution; transmission nodes of multipath
