
ICIC_Target:目标节点的局部因果关系网络的发现算法
2016-08-01 06:18刘万伟张晓艳
计算机研究与发展 2016年7期
关键词:因果关系
李 岩 王 挺 刘万伟 张晓艳
1(国防科学技术大学计算机学院 长沙 410073)2 (国防科学技术大学人文与社会科学学院 长沙 410073)
ICIC_Target:目标节点的局部因果关系网络的发现算法
李岩1王挺1刘万伟1张晓艳2
1(国防科学技术大学计算机学院长沙410073)2(国防科学技术大学人文与社会科学学院长沙410073)
(liyannayil@nudt.edu.cn)
摘要因果关系的研究在于揭示自然规律的和人类社会发展本质及其规律,对人类长久以来的生产生活和科学研究有着非常重要的作用.目前,因果关系的研究受到前所未有的广泛关注,但仍存在诸多困难和挑战.致力于建立一个因果激励�抑制模型以抽象地表示和解释因果的作用机制,并在此基础上提出用于目标节点的局部因果关系网络的自动发现方法框架ICIC和算法ICIC_Target.该方法不预先设定因果结构(如设定为无圈、隐含结构),并根据对因果关系本质的认识,利用初始变量(exogenous variables)和初始团树(IClique)的概念,在判定边和方向之前对变量进行粗略地排序,从而提高了因果关系网络发现的性能.在4个不同类型的数据集上实现了与多种经典方法,如HITON,IC,PC,PCMB等的对比实验,实验结果表明ICIC_Target方法适用范围广,有较好的鲁棒性,同时,从理论上分析证实了ICIC_Target方法具有较好的稳定性和较低的复杂度.
关键词因果关系;因果关系网络;局部因果关系发现;激励因果;抑制因果
因果关系的研究在于揭示自然和人类社会发展本质及其规律,以解释现象、控制存在、预测未来,对人类的生产生活和科学研究有着非常重要的作用.因果关系的研究历史悠久,研究方法经历了“手工”、 “半自动”和“全自动”的发展过程.自20世纪80年代以来,许多数学理论和方法相继提出,因果关系研究正式成为可计算的研究领域.Pearl[1]和Spirtes等人[2]指出因(cause)和果(effect)可以是事件(event)、属性(feature)、物体(object)等多种类型的实体(entities).为采样的可行和计算的高效,该领域研究普遍使用不同类型的随机变量(variables)表示因果实体,变量的取值对应于实体的数值或状态值.概率统计和图模型普遍应用于发现和表示因果关系.因为概率可以很好地契合变量的随机性、因果关系发现过程的不确定性和因果断言的语义.有向无圈图(directed acyclic graph, DAG)或贝叶斯网络(Bayesian network)这种最常用的图模型,可以生动准确地表达因果关系结构,其中网络节点表示变量系统(简称系统),节点间的边表示因果关系的存在,边的方向表示因果关系的存在方式.但是贝叶斯网络无法表示多变量间循环作用(圈)或2个变量间相互作用(双向边)的因果关系,而这些因果关系是真实存在且常见的,因此本文采用可以包容圈和双向边的宽松结构(loose network)表示真实的因果关系网络.
因果关系网络结构的发现是因果关系研究的重要内容,即给定有限数量和范围的实体及其采样值,发现全局因果关系网络或关于目标实体的局部因果关系网络.大量真实环境下的因果关系发现问题(causal problem, CP)仅仅需要确定给定的目标变量周围的局部因果网络结构,还有许多问题涉及的全局网络结构过于庞大和复杂,全局网络结构的发现成了非常困难的任务.因此发现给定目标变量的若干层因果关系网络成为了因果关系发现的常见任务,记为CP(Vo,vt,D),即在已知数据集D上找出给定目标变量vt在可观测变量Vo中的父、子、配偶等变量以及这些变量之间的因果联系.
Pearl[1],Spirtes等人[2],Cooper等人[3-4]在各自经典著作中讨论了如何在不同的应用背景和数据类型下正确高效发现因果关系,其中最核心的理论部分是因果关系的定义(尤其是Granger[5]和Pearl[1]提出的定义)、Markov条件、d-割准则(d-separation criterion)和忠实性定理(faithfulness theorem).其中Markov条件独立是贝叶斯网络表示因果关系应满足的基本假设,也是本文提出的宽松结构在表示有向无圈的真实网络结构时应满足的假设.
目前,因果关系的研究受到广泛关注[1,6],但由于环境、人为因素的复杂多变并且不可控,真实环境下的因果关系发现仍存在诸多困难和挑战.这是因为:真实环境下因果关系发现获得的数据来自人们对可观测属性“静态”或“被动”的观测[4],是真实环境下随机因素与因果关系共同作用的结果,并按照某种方式在某些时刻采样获得,是关于真实世界的“静态”片段,因此无法像在实验室环境下通过干预(intervention或manipulation)某些属性的取值从而获得其他属性取值变化的“动态”数据,也无法像使用实验室数据那样可以根据先验知识对网络结构做出合理的假设并做出验证;真实环境下因果关系还可能受到若干不可观测因素(hidden features)的影响,仅考虑那些可观测属性(observational features)的因果关系网络则不能完全正确地反映真实因果(underlying causality mechanism).如何仅从“静态”观测数据还原真实的因果关系网络,且不做任何关于网络结构的先验假设,如是否存在圈或隐含变量的假设,是非常困难的,甚至被认为是在现有理论框架下不可能完成的任务.
针对以上问题,本文基于Pearl等人提出的因果关系经典理论和方法,通过分析因果关系发生和作用的本质特性,利用初始变量(exogenous or instr-umental variable)、初始团树(initial clique of an exo-genous variable, IClique)和Markov条件独立判定来解决真实环境下局部因果关系发现问题(详见2.1节),并提出了性能更高、鲁棒性更强的局部因果关系网络结构发现方法ICIC_Target(详见2.3节).该方法主要用于目标节点的因果关系网络的发现,同时针对二值数据系统区别了激励因果(stimulating causality)和抑制因果(inhibiting causality)两种因果模型,发现了一些新型的因果关系.不同于IC和PC等经典方法假设因果网络为无圈和无隐含变量(hidden variable),ICIC_Target方法不预先设定因果结构,从而提高了方法的性能和鲁棒性.ICIC_Target不仅在理论上具有可靠性、稳定性,在多数据集、多评估体系下与多种经典方法实验结果的比较同样具有优越的性能.另外,本文将因果研究常用的小品集LUCAS(lung cancer simple set)[7-8]作为应用样本以清晰展示ICIC_Target方法的细节.
1相关工作
因果关系研究正式成为可计算的研究领域后,各种因果表示模型、因果发现预测方法大量出现,并逐渐形成两大学派:以图灵奖获得者Pearl[1]为代表人物的UCLA & CMU学派和Cooper等人[9]为代表的Stanford学派,他们出版于1999年的专著为因果关系研究奠定了坚实基础.
1.1IC,PC,LCD和IC*,FCI方法
对于多变量系统,Pearl等人的研究思路是从找出条件独立的片断开始,最后将各个片断合成为全局的因果关系结构,最具代表性的经典方法有Pearl[1]的IC(inductive causation)方法和Spirtes等人[2]的PC方法.而Cooper等人[4,9]的研究思路是对于给定的数据和参数,先为一个贝叶斯网络(即候选因果网络)指派先验概率,然后根据因果关系网络与数据的拟合度打分,在可能的结构空间上搜索具有最大后验概率的结构,用于更新网络,以达到最优.Cooper等人[4]提出的LCD(local causal discovery)属于此类方法.该方法需要输入一个或多个初始变量作为因果网络结构的根节点,如性别、年龄等变量是研究疾病问题公认的初始变量.这样可以充分利用问题本身提供的关于网络结构的先验知识,实验证明初始变量有助于提高发现的准确性和效率[4],但对于大量无法预知初始变量的问题,LCD方法的局限性显而易见.Stanford学派的研究思路应用广泛,但Pearl[1]认为此类方法有很高的复杂性,事实上只能从局部到局部最优且不适用于小样本数据,不能灵活处理存在不确定、不可观测变量的情况,并且该研究思路假定参数独立.而Pearl等人的IC,PC方法复杂度相对较低,对样本数据大小要求不高.
以上方法均不适用于存在隐含变量的因果关系发现问题.因此,Pearl[1]和Spirtes等人[2]提出了IC*(inductive causation with latent variable)和FCI(fast causal inference algorithm)方法.隐含变量的存在导致可观测变量之间的因果关系发生不同程度的变化,因此在IC*和FCI方法中修改了边的方向表示,使用双向边、“*”或“o”等符号以增强边所能表达的语义.根据边的语义变化,IC*和FCI方法在IC和PC方法上调整了因果的判定规则并做了其他较大改进,以适应可能存在隐含变量的情况,同时改善了算法的性能.IC*和FCI方法与本文提出的ICIC_Target方法都适用于隐含变量因果关系发现问题,但IC*和FCI发现的网络结构的语义复杂、算法复杂度高.
1.2PCMB,IAMB,HITON系列方法
HITON-PC(HITON_parents & children)和HITON-MB(HITON_Markov blanket)方法是Aliferis等人[10]于2003年提出经典的特征选择方法,用于发现目标节点(target variable)的父子节点(记为PCset)和包含目标节点及其父子节点和配偶节点的Markov毯(Markov blanketboundary,MBset),这些节点对于预测目标节点的取值有着重要的作用,因此HITON也可看作是局部因果关系发现方法.2006年Tsamardinos等人[11]提出HITON等方法缺少“对称性校正(symmetry correction)”,在理论上不正确.但HITON-PC方法仍成为NIPS 2008举办的第2届Causality Challenge中LOCANET(uncover the local causal network around the target)任务的标准(state-of-the-art)因果发现算法,用以获得质量保证测试的基准结果(baseline results)[12].Aliferis等人[13]在2010年的综述文章中解释说HITON使用了启发式搜索方法作为后处理步骤(a wrapping post-processing),在原理上可以去掉错误的正例,因此未做对称性校正的HITON方法仍具有优越的性能.2007年Pea等人[14]提出了理论上正确的PCMB方法,用于发现PCset或MBset.Pea等人将PCMB方法与同样在理论上正确但数据低效(data inefficient)的IAMB方法进行了比较.
美国Vanderbilt大学的生物医学信息系开发的因果关系发现工具Causal Explorer library[15-16],用matlab实现了HITON,IAMB等多种经典方法.Pea用C++实现了PCMB和IAMB方法[17].然而这些方法的输出是PCset或MBset而非网络结构,因此无法表达更详细更准确的因果作用机制.
1.3GC系列方法
早在1969年,诺贝尔经济学奖获得者Granger[5]就给出了时序问题的因果关系(Granger causality,GC)定义:若用时间序列U的历史信息预测时序变量X好于在U中排除时序Y后的历史信息预测X的结果,则Y是X原因,记为Y→X.Granger认为“因”有助于提高对“果”预测的性能.GC含义明确、可操作性强,被时序问题研究领域的研究人员所接受,并在此基础上做了很多改进,取得了大量成果[18-20].其中具有代表性的是2004年东京大学的研究[18],将GC中的方差改进为转移熵(transfer entropy),并将因果关系描述为:Y是X的原因,若时序Y的历史信息为预测时序X提供了显著的帮助.这种改进的因果关系定义和GCTE方法可以帮助研究不同类型的时序变量间的因果关系.
但是“利于预测”并不是因果关系的本质,为此Pearl[1]反驳道GC应该归为统计学范畴而非因果关系.因为在不能明确时序时,满足GC的X和Y之间的方向不明确.即使Y→X,此时已知X的历史信息Y也会被更好地预测,即X→Y同样成立.
1.4其他方法
2006年Shimizu等人[21]提出了一种全新的因果关系发现方法LiNGAM(linear non-Gaussian acyclic model).该方法利用独立成份分析的方法估计方程组x=Ae中的混合矩阵A,以获得变量间相互作用的线性方程,其中x是各变量的观测值组成的矩阵,e由各变量自带的随机扰动(disturbance variables)组成.LiNGAM计算A使得e的分量尽可能满足两两独立,但前提是这些随机扰动是两两独立且服从非高斯分布,同时因果关系非循环(无圈结构)且满足线性方程,否则方法可能会产生错误结果.
SI(similarity index)是Arnhold等人[22]提出的另一类针对时序数据的因果关系发现方法,通过计算2个时间序列在同一起始时刻开始的相同长度片断上的平均相似程度来判断时序变量是否存在因果关系.我们认为该方法对于同步和异步变化的2个时间序列的相似判定都非常适用,但因果关系的方向难以判断,并且需要给定参数R,该参数与算法的性能和复杂度密切相关.文献[23]指出SI的最大缺点是很难判定弱因果结构和带噪音时序的因果.
2因果关系发现方法ICIC_Target
针对真实环境下局部因果关系发现,即未知真实网络是否存在隐含变量(IC,PC方法假设网络不含隐含变量)、是否是无圈网络(IC,PC,LiNGAM方法均假设网络为DAG)、是否存在初始变量(LCD方法不适用无初始变量的问题)、是否带噪音(LiNGAM方法假设噪音两两独立且服从非高斯分布,SI方法对带噪音时序的因果判定困难)等,为提高因果发现性能(GC方法易产生冗余关系,HITON等方法没有明确网络结构)、增强算法的鲁棒性(IC等方法适用于案例数据,GC和SI方法适用于时序数据),本节通过分析因果关系发生和作用的本质特性,利用初始变量和初始团树,提出了性能更高、鲁棒性更强的局部因果关系网络结构发现方法ICIC_Target,并形式化介绍该方法的框架和技术细节,包括方法涉及的理论基础、技术特点、方法流程、程序伪代码和因果关系分析.
2.1因果关系的本质和分类
因果关系的本质是因果关系研究的首要问题,所有因果发现方法都基于研究者对因果关系的理解.1999年Pearl[1]给出了经典的因果关系的描述:在某个相对稳定的系统中,重复控制并改变(inter-vention)其中的某个或某些变量X时,另一些变量Y总是随之发生变化,则X是Y的原因(前驱),Y是X的结果(后继),其中X和Y均表示变量集合.Pearl的描述符合人类对因果的认知,适用于不同领域,不针对特定数据,具有一般性,因此得到了广泛认可.但Pearl的描述只能为判定因果关系提供思路,在实际应用中可操作性不强.
基于Pearl的描述,我们对因果关系有着更深层次的认识:
1) 因果关系是客观存在的自然现象和事物间相互作用的约束规则,无需第三方的操控(intervention)因果也会发生.
2) 因果关系不能改变果变量Y的本质属性,但可以改变Y在这些属性上的概率,即Y从原有状态PY,t(时刻t时Y的概率分布)变化为PY,t′(时刻t′>t时Y的概率分布),因此只要变量X使得Y在若干属性(而不是全部属性)上的概率发生变化即可认为X,Y存在因果关系.与Pearl的基本思想吻合但略有不同,我们认为果变量取值的改变只是因果关系的表象,究其根本是因果关系导致果变量的概率分布的改变,这是真实环境下基于大量观测数据发现因果关系的基础.
3) 因果关系可分为2种基本类型:激励因果和抑制因果.因果关系使果变量Y的某些关注属性(focused features)发生的概率增加(我们称这样的因果关系为激励因果)或减少(称为抑制因果),同时在另一些属性上概率减少(称为因果关系对属性的抑制作用)或增加(称为激励作用).
4) 原始概率分布(original probability distribution)PX,O是一类最基本的原有状态,即变量X未受任何因果关系作用时的概率分布,我们称其为自由态下的概率分布,此时只有随机扰动和变量固有的概率分布决定变量的取值.

2.2基本符号和概念
2.2.1基本符号
一个因果关系系统(causality system, CS),如癌症预防与检测系统等,通常包含一个变量系统V和关于V的因果关系边集E⊆V×V.一个因果关系发现问题CP通常会给定可观测变量系统Vo⊆V、目标变量(target variable)vt∈Vo和Vo的一组采样数据D.常见任务是发现目标变量的3层因果关系网络,即vt的父、子、配偶变量以及这些变量之间的因果联系.在因果关系网络结构(causal network)中,点代表变量,边表示因果关系,边的方向是从因变量指向果变量.我们使用斜体小写字母,如a,b表示可观测变量.用小写字母,如a表示变量a的某个取值(或状态);对于二值系统,通常用a表示取值为1(或真),用a表示取值为0(或假),pa表示变量a取值为1的概率,pa|b表示条件概率P(a=1|b=1).若v∈V,则用Pred(v)表示v在V中的所有前驱(predecessor)节点集合,即E中存在从前驱节点到v的有向路径;Parents(v)表示v在V中的父节点集合,即v的直接前驱集合;用Descend(v)表示v的后继(descendant)节点集合;Children(v)表示v在V中的子节点集合,即v的直接后继集合.对于2节点a,b之间的无向边,我们用a—b表示;有向边则为a→b.
2.2.2数据集类型
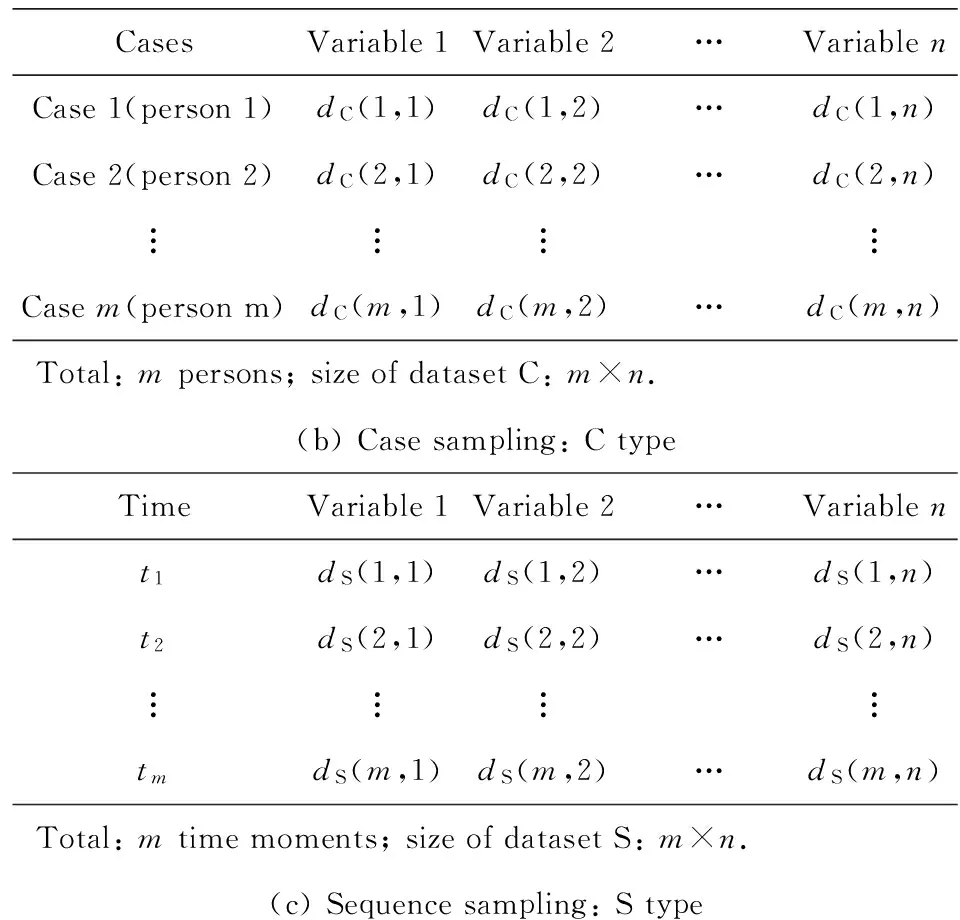
因果关系问题CP(Vo,D)的观测数据集D对因果关系发现十分重要.一般地,D以矩阵的形式呈现,列代表变量,行代表观测值,一行观测值也称为一个采样(sample).如图1所示,D的收集方式有2种:1)案例采样(case sampling),即从不同的个体上对相同的变量进行采样获得;2)序列采样(sequences ampling),即对指定个体上的变量在时间轴上进行持续采样.2种方式的采样获取的C型和S型数据有很大的差别.由于S型数据能够发现诸如某变量的历史信息影响自身或其他变量的当前状态的情况,网络结构中常常会出现自圈(self-loop)、双向边(bi-directed edge)甚至更大的圈(cycle).因此,预先限定因果关系问题的网络结构为有向无圈图(DAG)是不可行的.根据2.1节的描述,我们认为网络结构是有向图(directed graph, DG)更合理.本文的实验数据集包含C型、S型以及两者混合型M型(详见3.1.1节关于SIGNET数据集的介绍),那些预先设定网络结构为DAG的方法在S型和M型数据集上无法获得较好的实验结果.
(a) Feature choosing
CasesVariable1Variable2…VariablenCase1(person1)dC(1,1)dC(1,2)…dC(1,n)Case2(person2)dC(2,1)dC(2,2)…dC(2,n)︙︙︙︙Casem(personm)dC(m,1)dC(m,2)…dC(m,n)Total:mpersons;sizeofdatasetC:m×n.(b)Casesampling:CtypeTimeVariable1Variable2…Variablent1dS(1,1)dS(1,2)…dS(1,n)t2dS(2,1)dS(2,2)…dS(2,n)︙︙︙︙tmdS(m,1)dS(m,2)…dS(m,n)Total:mtimemoments;sizeofdatasetS:m×n.(c)Sequencesampling:Stype

Fig. 1The illustration of C type and S type of datasets from two processes of case sampling and sequence sampling.
图1C型和S型数据集示意图
2.2.3基本概念
给定一个因果关系系统(V,E)和其因果关系图G,我们将定义涉及ICIC_Target方法的若干重要概念.
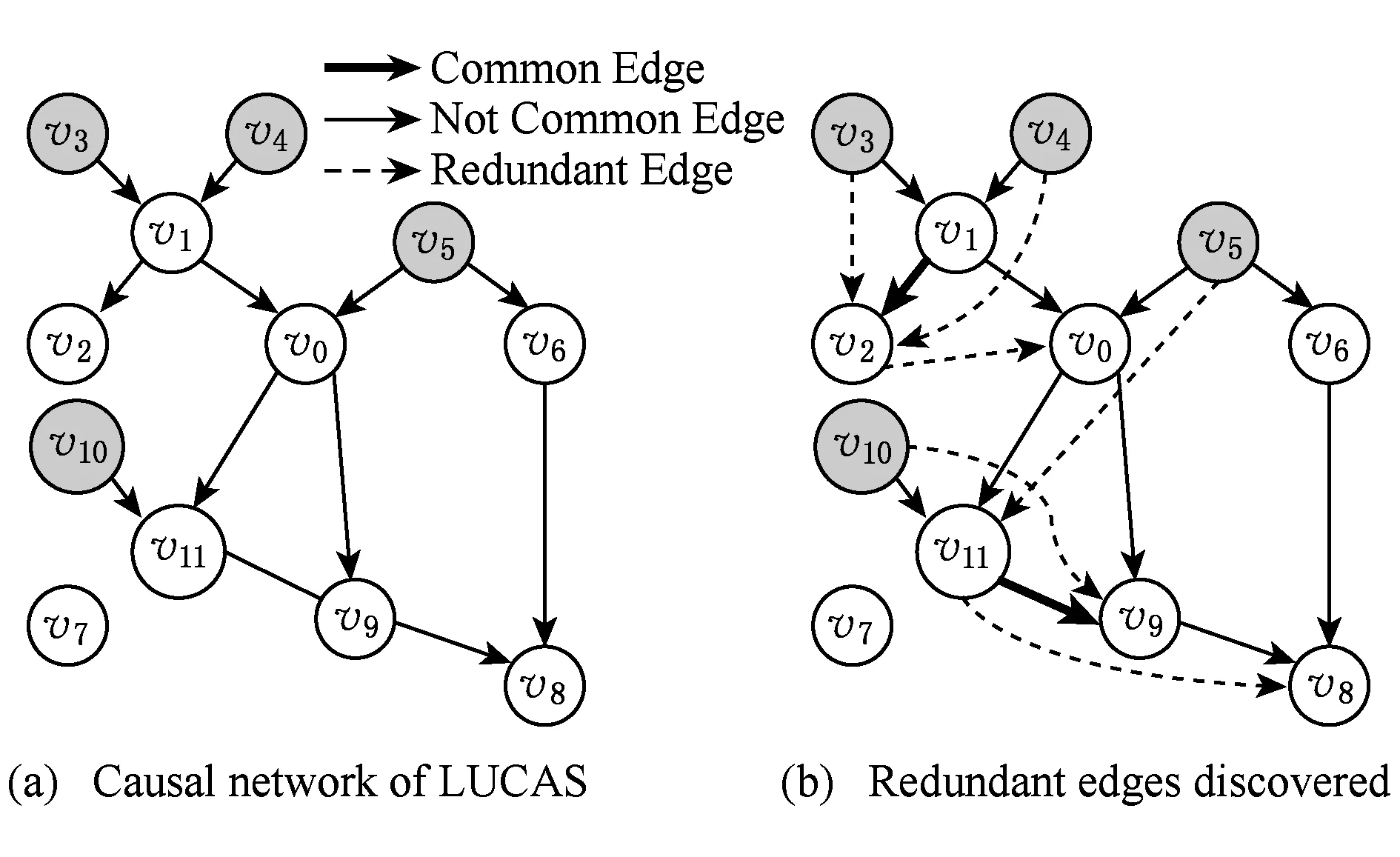
Fig. 2 Causal network of LUCAS and redundant edges ICIC discovered.图2 LUCAS的真实因果网络结构和ICIC发现的冗余边
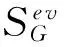
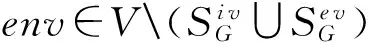
定义4. 初始模式(exogenous pattern, EVP).evpi(i=0,1,…,m)是初始模式当且仅当evp0=(v1,v2,…,vm),evpi=(v1,…vi-1,vi,vi+1,…,vm)1≤i≤m,其中,是初始变量个数.表示图G的所有初始模式的集合.图3(b)中evp0=(v3,v4,v5,v10),evp2=(v3,v4,v5,v10).
定义5. 模式(pattern).定义任意2个变量vi,vj∈V的模式为Patterni,j=(vi1,…,vi l,vj1,…,vjk),其中Parents(vi){vj}={vi1,vi2,…,vi l},Parents(vj){vi}={vj1,vj2,…,vjk}.图3(b)中,Pattern0,1=(v3,v4,v5).定义任意变量vi∈V的模式为Patterni=(vi1,vi2,…,vi l′),其中Parents(vi)={vi1,vi2,…,vi l′}.
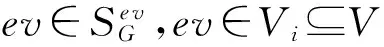
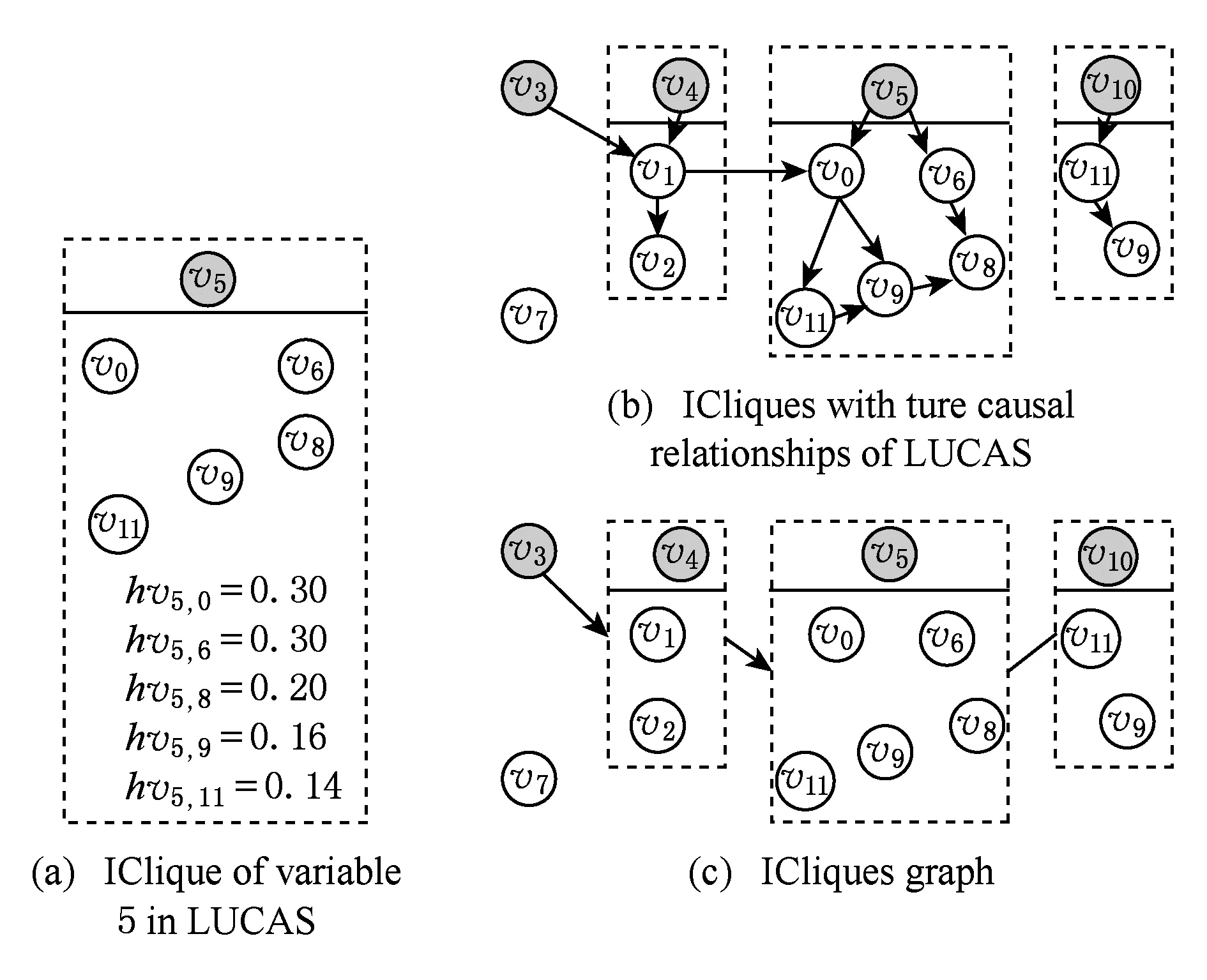
Fig. 3 ICliques and ICliques graph of LUCAS .图3 LUCAS的初始团树和初始团树图
2.3ICIC方法框架
为提高因果发现算法的鲁棒性,降低复杂性,ICIC方法框架在数据预处理之后包含5个核心步骤:1)确定初始变量;2)构建初始团树;3)发现无向图;4)添加方向;5)删除冗余边.
鉴于IC等经典方法生成v结构(v-structure)和添加方向规则造成的诸多问题,如算法复杂性高、鲁棒性低等,ICIC步骤1)、步骤2)通过发现初始变量和初始团树获取因果网络的大体分支和层次结构.实验和理论分析证明,这样可以在v结构形成之前获得关于方向的粗略信息,使得发现无向图和添加的方向更合理,算法运行速度也会明显提升.
ICIC步骤3)利用改进的d-割判定条件获得带有冗余边的无向图.以常见的二值离散变量系统为例,ICIC利用d-割判定公式获取d-割集,将判定条件由IC方法在各种取值组合下d-割判定公式(式(1))都成立更改为式(2)~(5)各式之一成立即可判定a,b之间无边.ICIC方法对二值离散变量系统区分生成激励和抑制因果无向图.我们通常认定对果变量1值的提升是激励因果关系,对1值的降低是抑制因果关系,这符合人们的习惯.对于多值变量系统,可以通过用户指定关注值获得激励和抑制因果结构.
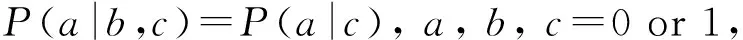
(1)
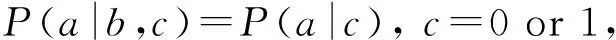
(2)
P(a|
(3)
P(a|b,c)=P(
(4)
P(a|b,c)=P(a|c),c=0 or 1.
(5)
ICIC步骤4)根据前3步的结果添加方向后,在步骤5)回溯所有可能的冗余边,确定为冗余后删除该边.我们遍历所有三角形结构中每一条非公共边作为可能的冗余边,见图2(b)所示,ICIC将保留那些至少2个三角形结构公有边(加粗实边),虚线边是判定为冗余的边,其作用可以由其他边替代.ICIC方法不预先限定因果关系网络结构,因此对存在双向边或圈等结构的真实网络的发现结果更有效.
2.4初始变量与初始团树
2.4.1初始变量的发现
初始变量的发现是ICIC方法框架的步骤1)和重要步骤.在Vo中寻找初始变量EV是二值分类问题,特征也看似很明显.但在大多数应用中,初始变量的发现并非易事.首先,所有变量的原有分布PZ,t未知;其次,在未知初始变量的前提下,任何变量之间的条件概率pa|b都不能轻易地认为等同于pa|do(b).因此本文初始变量的发现方法EVD主要基于2点:1)根据初始变量的基本性质,通过所有已知变量参与投票的方式找出最可能的初始变量;2)区分激励和抑制可以帮助化简初始变量的发现难度.EVD方法的具体实现见算法1,其中利用已发现的初始变量寻找其他初始变量的步骤需要计算初始团树(详见EVD的Step2.2),计算方法详见函数computeIClique(),其具体含义和解释则见2.4.2节.
算法1. EVD.
输入:变量集V、数据集D;
Step2. while (|currentV|的值减少)
Step2.1. if (vi∈currentV,vi是常量)R←R∪{vi};
else if (max(P1)≫min(P1))
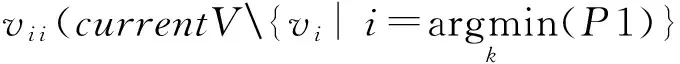
if (pvi i-min(P1)<β||
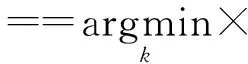
if (∃va(currentVs.t.
(|pvi i|va-pvi i|va|-|pva|vi i-
pva|vi i|)<β)
R←R∪{vi i,va};
endif
elseR←R∪{vi i};
endif
endfor
endif
else
P0←computeOneOne(currentV,
Step2.2. for ∀vi∈R
ICliquei{Vi,Hi}←
endfor
else
{ICliquei{Vi,Hi}};
endif
Step2.3.currentV←currentVVi;
Step3. if (|currentV|>0)
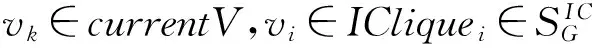
if ((pvk|vi-pvk|vi)≫0)
Vi←Vi∪{vk},
currentV←currentV{vk};
endif
endfor
endif
FunctioncomputeOneOne(currentV,P1,D)
Step1. 初始化P0←∅;
Step2. for ∀vi∈currentV
num←samples {v0,…,vi-1,vi,
p←num(|D|×pvi), where
pvi∈P1;P0←P0∪{p};
endfor
Step3. returnP0;
Step1. 初始化Vi←{vi},Hi←∅;
hvi j←pvj|evpi-pvj|evp0;
if (hvi j>β)Vi←Vi∪{vj},Hi←Hi∪{hvi j};
endif
endfor
Step3. returnICliquei{Vi,Hi};
以发现激励因果为例,对任意变量a:1)a=1(关注值)的概率pa越小,则a受激励的机会越小;2)vi∈V{a},|pa|vi-pa|vi||Q11iQ10i|越小,则a受V中其他变量激励的可能越小;3)∀b∈V{a},|pa|b-pa|b|≪|pb|a-pb|a|,则b越有可能受a激励,而非a受b激励.以上判断显示a有可能是激励因果网络的初始或孤立变量,如图4中的变量v5.还有一类变量b,尽管pb值足够小,但b存在已确定的因变量,因此不是初始变量,如图4中的变量v6.为了剔除这样的变量和孤立变量,本文EVD方法在确定某变量v是初始变量前计算该变量的ICliquev.若ICliquev只包含根v,则表明v是孤立变量;若ICliquev包含其他变量vi,则vi是v的后继,且算法将不再遍历vi,即当前活跃变量集currentV不再包含v和vi.另外,在数据集中取值为常数的变量也符合初始变量的特性.若因果关系网络不含初始变量,则该网络一定有圈.这种情况下,由若干概率值或以彼此作为条件的概率值较接近的变量形成的圈起到了初始变量的作用,这些变量的初始团树将包含圈内的邻接变量.当所有变量的概率值都非常接近时,我们比较这些变量的“非激励影响”,即变量取1而其他变量为0的概率,详见算法1的函数computeOneOne().拥有最小“非激励影响”的变量vj暂时加入初始变量集,计算获得其ICliquej,并依据Vj包含的非初始变量对currentV中剩余变量的“影响力”(详见算法1的Step3),判断哪些变量添加至ICliquej.重复以上过程,直到currentV为空.
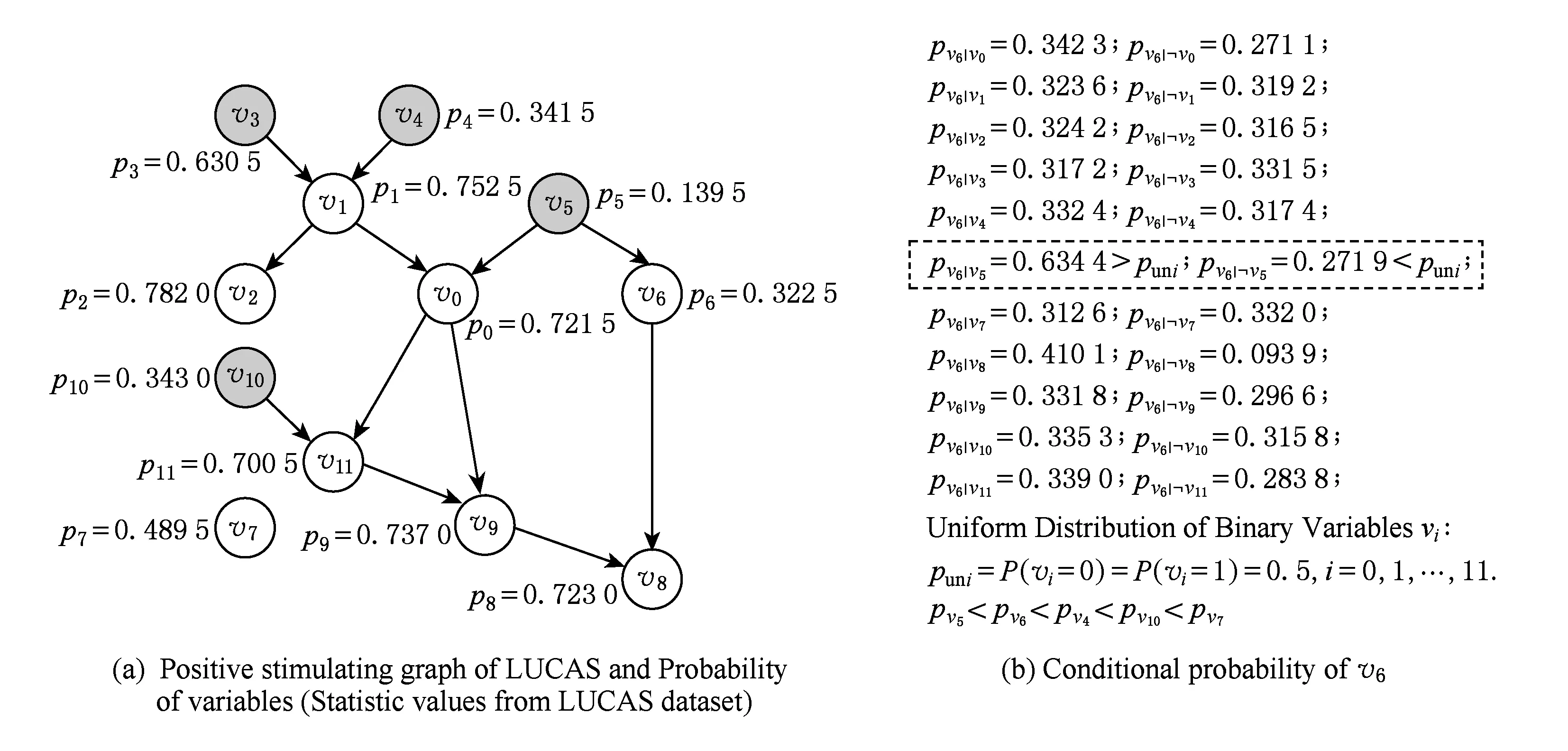
Fig. 4 Exogenous variables discovery for LUCAS.图4 LUCAS的初始变量发现示意图
2.4.2初始团树的计算
初始团树ICliqueev是以初始变量ev为根的分支,其非根节点都是ev的后继.初始团树的计算见EVD算法的函数computeIClique().在本文方法中,构建初始团树起到了3个作用:1)在初始变量发现过程中,帮助算法从currentV中排除非初始变量;2)区分初始变量和孤立变量;3)避免IC等经典方法生成v结构和添加方向规则造成的诸多问题,如算法复杂性高、鲁棒性低等,并利用初始团树获取因果网络的大体分支和层次结构.不仅如此,初始团树有很多性质(性质1~5),可以帮助我们更快地发现因果关系.
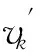
性质4. 若vi∈Vi{v1},v1是IClique1的初始变量,则v1∈Pred(vi).
性质5. 在不同初始团树中的同一条边有相容的方向,如图5(d)所示.
这些性质可以帮助快速确定边的方向和节点所在的分支,减少算法复杂度并提高准确性.性质1和性质2可由初始变量的定义推出.性质3是Markov链的性质.性质4描述了IClique1是初始变量v1在网络结构中的影响力范围.性质5中相容方向是指具有相同单方向的边.由初始变量和初始团树的计算可知,不同于IC等方法在确定v结构后再形成分支,ICIC方法在发现初始变量及其分支的过程中,自然形成各个分支的交汇点.3条规则可以从以上性质推导出来,能帮助添加方向和优化程序,如图6所示.
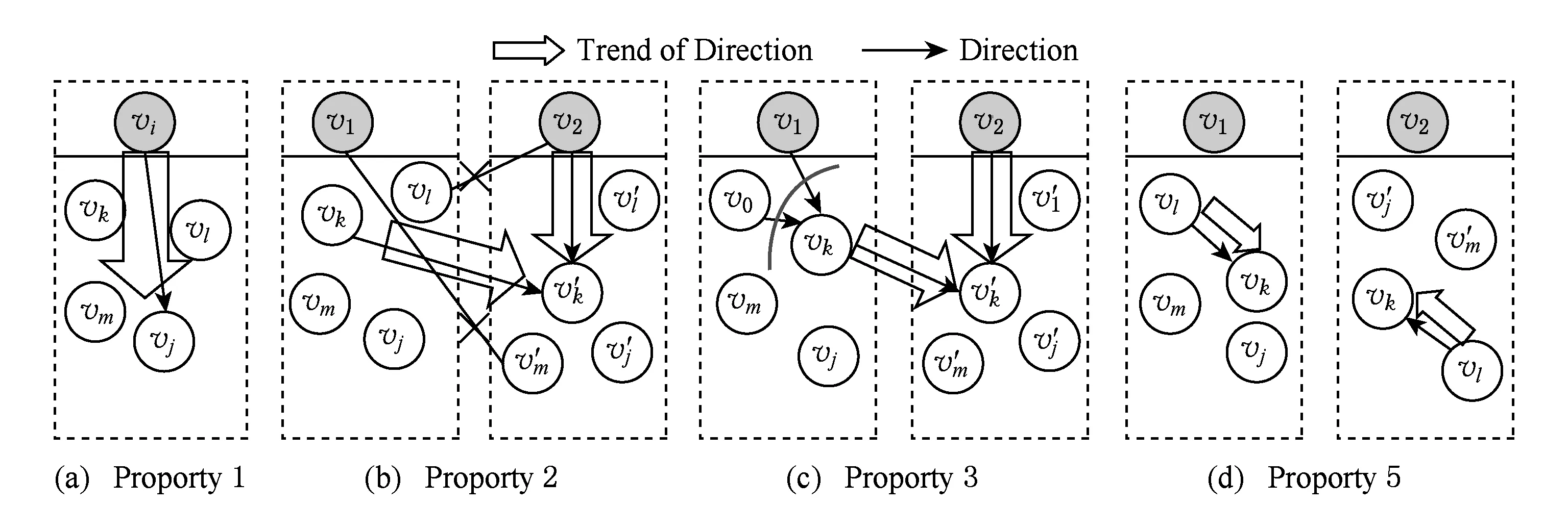
Fig. 5 Directions properties within IClique or between ICliques.图5 初始团树和初始团树间方向的性质
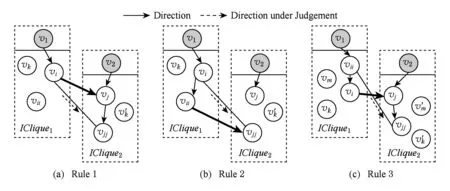
Fig. 6 Rules for directing edges quickly.图6 添加方向的优化规则
规则1. 若vi→vj,vi—vjj,hvj≫hvjj,其中vj,vjj∈V2{v2},V2是IClique2的节点集,则vi→vjj,如图6(a)所示.
规则2. 若vi i→vjj,vi—vjj,hvi≫hvi i,其中vi,vi i∈V1{v1},V1是IClique1的节点集,则vi→vjj,如图6(b)所示.
规则3. 若vi→vj,vi i—vjj,hvi i≥hvi,hvj≥hvjj,其中vi,vi i∈V1{v1},vj,vjj∈V2{v2},V1和V2是IClique1和IClique2的节点集,则vi i→vjj,如图6(c)所示.
2.5目标节点的因果网络发现算法ICIC_Target
本文针对目标变量(target variable)的网络结构发现提出了ICIC_Target算法,参见算法2.目标节点的因果关系网络发现问题CP(Vo,vt,D)中Vo一般十分庞大,极大地增加了计算复杂性,算法2的Step2对数据进行相关性分析,以适当地降维,尽早将无关变量限定在计算范围之外.其中ICIC_Structure函数可以用于全局因果关系发现算法,使用的不等式有:
(6)
(7)
P(b|a,Patternb)-P(b|
(8)
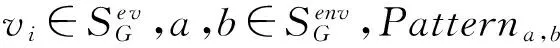
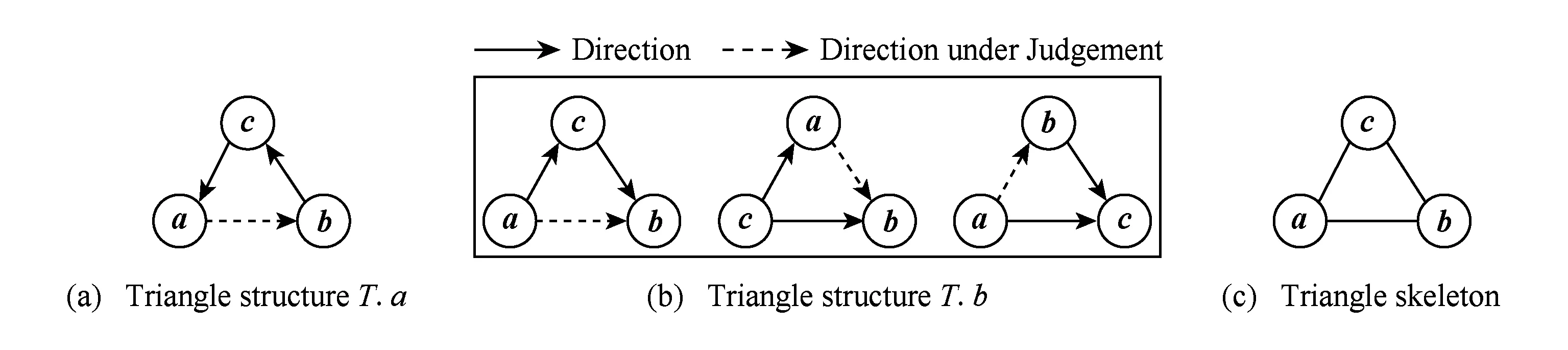
Fig. 7 Two shapes of triangle structure (a,b,c) T.a, T.b with one redundant edge a→b noted as dash arrow.图7 带圈三角形的集合T.a和非圈三角形集合T.b示意图
算法2. ICIC_Target.
输入:变量集V、目标变量vt、数据集D;
输出:G.
Step1. 初始化G←∅,Vt←{vt};
Step2. for ∀vi∈V{vt}
if((pvi|vt-pvi|vt)>β)Vt←Vt∪{vi};
endif
endfor
Step3. for ∀vj∈Vt{vt}
for ∀vk∈VVt
if ((pvk|(vj,vt)-pvk|vj)>β)
Vt←Vt∪{vk};
endif
endfor
endfor
Step4.G←ICIC_Structure(Vt,D);
Step5. returnG;
FunctionICIC_Structure(V,D)
Step1. 初始化G←complete graph;
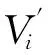
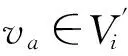
if(∃edgevi—va,vi是ICliquei的初始变量)
directvi→va根据Property 1,
endif
endfor
endfor
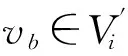
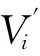
directva→vb根据式(6),(7);
endfor
if (所有va—vb添加方向为va→vb)
endif
endfor
Step5. forva—vb∈IClique
directva→vb根据式(6),(7);
endfor
Step6. for ∀va—vb不在一个IClique中
directva→vb根据式(7),Rule 1,2;
endfor
Step7. {T.a,T.b}←FindTriangle(G);
Step8. while (T.a≠∅)
for ∀d=(va→vb)∈t∈T.a
if(∃t1∈T.b, s.t.d∈t1)
continue;
endif
if (式(8)成立)
从G中删除d,更新T.a,T.b,
break;
endif
endfor
while (T.b≠∅)
for ∀d=(va→vb)∈t∈T.b
if (t1(T.b, s.t.d(t1)
continue;
endif
if (式(8)成立)
从G中删除d, 更新T.b,
break;
endif
endfor
Step9. returnG.
3实验结果与分析
本文从理论和实验2方面对ICIC方法进行了分析和验证.我们通过实验途径说明了ICIC_Target方法在不同实验数据上具有更好的性能和鲁棒性,并通过理论途径分析了ICIC_Target方法的稳定性和低复杂性.
3.1实验与分析
3.1.1实验设计
本文利用由WCCI 2008的“Causation and Predic-tion”竞赛[24]和NIPS 2008 Causality Workshop[6,12]正式发布的各领域的大小类型不同、或噪音、或操控的数据集(如表1所示,列出了数据集的性质),与多种有代表性的方法进行对比实验.根据数据集和算法的特点,我们选择可比较的部分组成相应的实验组.所有参与对比实验的算法已在本文第1节做了介绍.对比实验涉及10个分实验,如表2所示,说明了实验设计的情况.
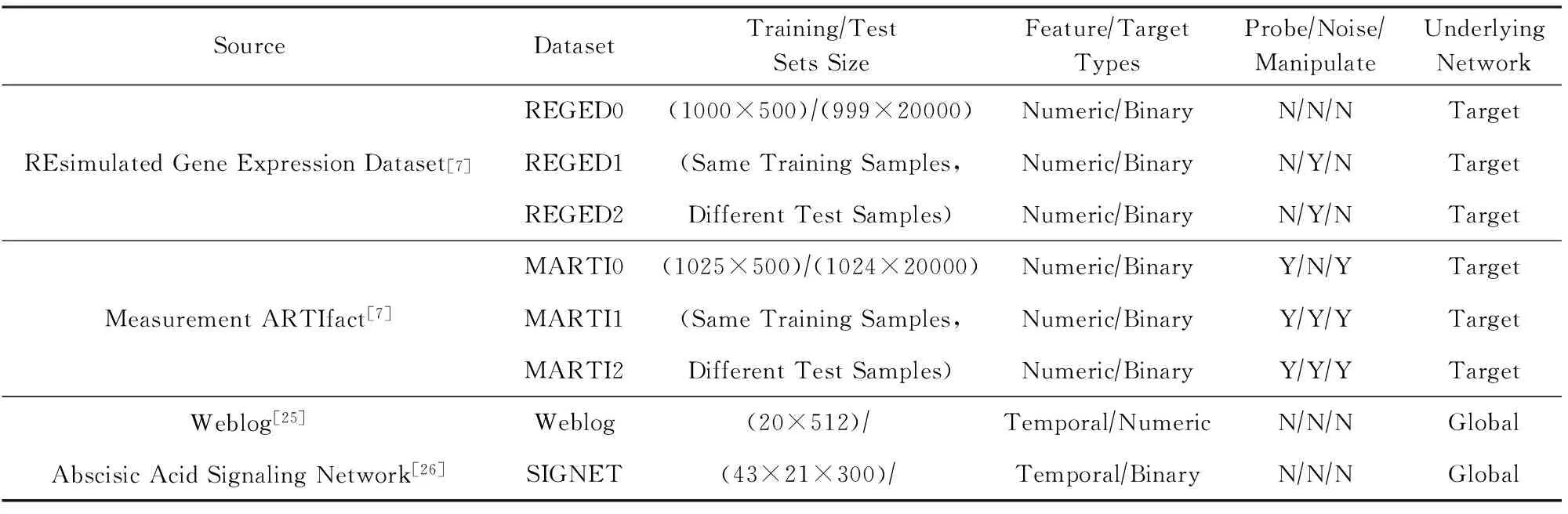
Table 1 Properties of Datasets Used in Experiments
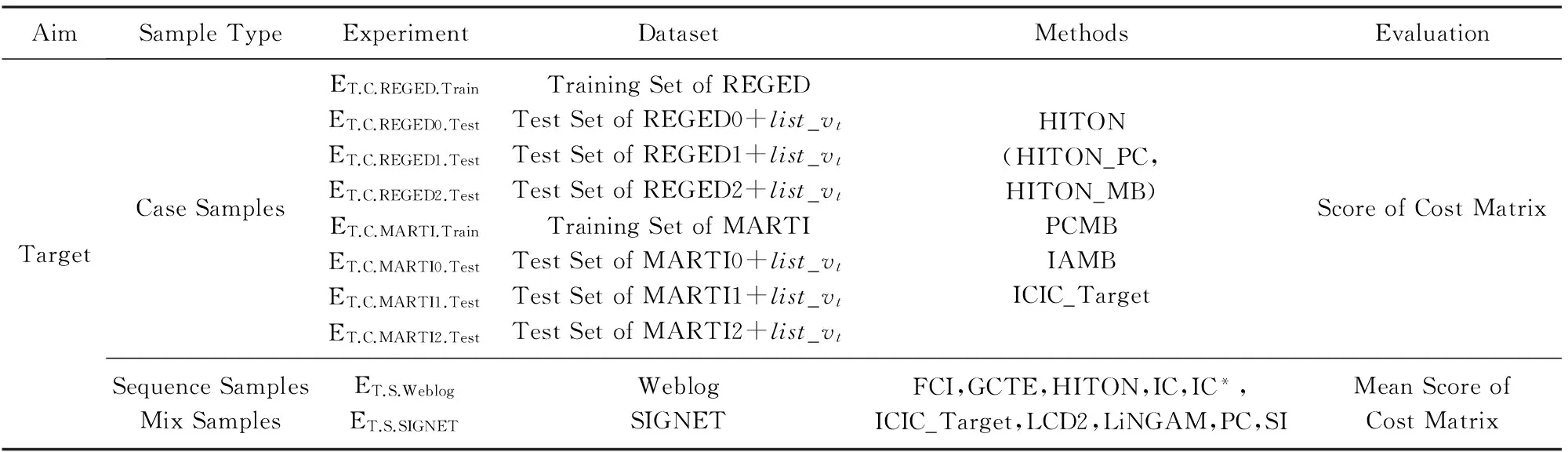
Table 2 Experiments Designed for Causality Discovery Research
REGED[7]数据集来自医学领域,目的是通过发现触发肺癌疾病的基因和肺癌造成改变的基因,预测肺癌的发病状况.REGED包含的基因表达量(gene expression data)数据由真实的DNA微阵列数据(DNA microarray data)训练出的模拟器生成.该数据集的3个子任务REGED0,REGED1,REGED2均有相同的1个目标变量和999个其他变量,其中REGED1和REGED2的测试数据中某些变量受到操控,以模拟药物或RNA抑制(RNA silencing)治疗的情况.MARTI[7,10]是REGED加入噪音的版本,有1024个变量,其中25个是校正变量,用于帮助剔除噪音影响.MARTI的因果网络结构与REGED相同.二者的设计初衷是检测目标变量(binary类型)预测算法的性能,本文的实验目的是检测因果关系结构发现算法的性能,因此在WCCI 和NIPS公布了REGED和MARTI所在系统的网络结构后,我们将它们的一个训练集和3个测试集都用来评估因果结构发现算法在有操控或有噪音的数据集上的性能.由于测试集的目标变量结果至今未公开,本文利用SimplePredict算法(见算法3)和已公布的网络结构将目标变量的值(即表2中list_vt)补充完整.
算法3. SimplePredict.
输入:目标变量vt、局部网络NL、测试数据集DT;
输出:目标结果值列表list_vt.
Step1. for ∀samplei∈DT
if(∃v∈Parents(vt) s.t.v=1 insamplei)
list_vt.add(1);
endif
list_vt.add(1);
endif
else
list_vt.add(-1);
endfor
Step2. returnlist_vt;
WebLog来自Grozea和Romania[25]设计的网页浏览实验的真实数据.在该实验中,有20个网页供人们浏览,每个网页有到另19个网页的链接.实验收集了512 d的浏览日志,将每一天每一个网页的浏览数统计出来作为WebLog数据集.实验作者发现某些网页可以激发人们去浏览某些其他网页,人们的这些行为被记录和统计下来,作为实验的真实因果网络结构.该结构存在双向边,这是因为一个网页pagea能激发人们浏览pageb, 同时pageb也能激发人们浏览pagea.Weblog的设计初衷是发现因果关系网络,因此该数据集无测试数据,SIGNET数据集亦是同样的情况,表1用空格表示.
SIGNET是模拟数据集,它的真实网络是一个生物信号网络的布尔模型.Jenkins和Soni[26]对43个生物信号变量进行了案例和序列2种方式的采样,变量中有38个可变变量、5个常数变量.该数据集总共300个序列采样组,每组包含21个序列采样,其中第1个采样由43个变量的初始值组成,其他20个采样是后续时间点上变量的变化情况.SIGNET对单纯的案例数据因果发现方法(如IC)和序列数据因果发现方法(如SI)都是较大的挑战.
我们参考NIPS 2008提出的代价矩阵得分(score of cost matrix)[12]作为实验结果的评估标准之一,其中代价矩阵的元素是局部网络结构中不同位置上出现错误变量的代价权重,具体取值如图8所示.变量在网络中的位置离正确位置越远,错误的代价越高;出错越多,代价累计值越高.因此该值越小,结果网络结构越相近正确.由于HITON,PCMB,IAMB方法输出的是PCset或MBset而非网络结构,无法直接计算PC和MB的代价矩阵得分,因此我们将PCset或MBset中包含的正确的父节点、子节点和配偶节点对应放置在目标节点的父节点、子节点和配偶节点位置上,集合中其余错误的节点均放在子节点位置,这样获得的网络结构是最接近正确答案的结构,由此计算的代价矩阵得分是HITON等方法的最小代价值,实际的代价值不会小于这个值,因此表3和表4中用“≥”表示HITON等方法的实验结果.
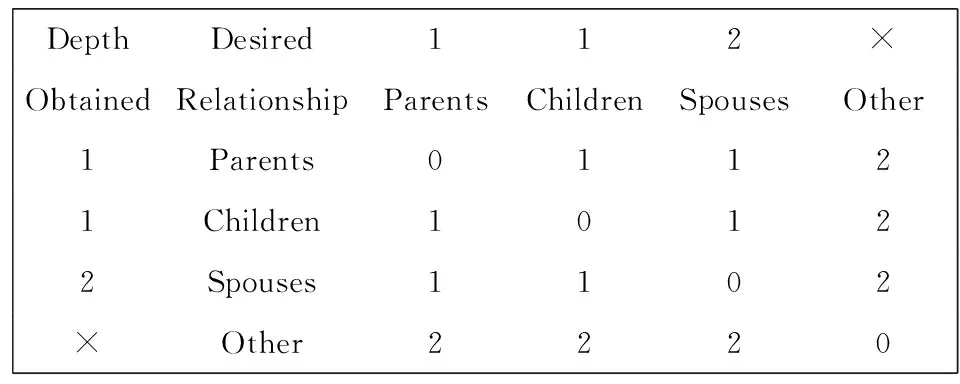
DepthDesired112×ObtainedRelationshipParentsChildrenSpousesOther1Parents01121Children10122Spouses1102×Other2220
Fig. 8The cost matrix of MB and PC.
图8MB和PC代价矩阵
在本文的实验结果评测中,对于IC
*
和FCI结果中存在带有标记的边,以及IC和ICIC_Target方法结果中不确定方向边(表示为无向边)或双向边,这些在NIPS 2008竞赛中未做明确规定的情况.在生成网络结构的邻接矩阵时,我们按3个原则处理:1)2个端点方向均明确者(如单向边和双向边),按原有方向处理.2)一端方向不明确者(如FCI方法标记为“o”的边(
a
o→
b
)则表明
a
端点方向尚不明确;IC
*
方法的有向边
a
→
b
意味着
a
到
b
方向已确定或
a
,
b
存在同一个隐含原因,因此
a
→
b
仍是
a
端方向不明确),该端按不存在该方向处理.3)2个端点方向均不明确者(如无向边),按2个端点均有方向处理.为适应实验结果存在双向、圈等网络结构的问题,关于代价矩阵得分的计算,我们采用4个原则处理:1)对NIPS2008提出的规定范围内的错误代价按原有代价矩阵中的值处理,如图8所示;2)对既在正确位置出现又在PC或MB中错误位置出现的变量,给予相应减半的惩罚;3)对未在正确位置出现、但多次在MB的其他位置出现的变量,给予累加惩罚;4)Weblog和SIGNET上的实验结果是以任意变量为目标计算的代价矩阵平均得分.

Table 3 Results of Score of Cost Matrix in REGED

Table 4 Results of Score of Cost Matrix in MARTI
3.1.2目标变量的网络发现实验结果及分析
本节将进一步说明在多数据集和多任务下的因果网络发现的实验细节和实验结果,得出分析结论.
本实验使用文献[27]提出的突发检测算法BSE,将连续数据转化为离散数据后再进行各算法结果的比较和评估.ICIC_Target方法多处涉及用χ2假设检验(或参数β)以判定显著差异、边的方向以及隐含因变量的存在.假设检验的置信水平越高或β值越大则意味着ICIC方法发现的因果关系越强.本文中设置α=0.05,β=0.1.参数ε0是足够小的正值,本文取值ε0=0.000 5.
我们对ICIC_Target与HITON,IC等方法在目标节点网络结构发现上的性能进行了比较,实验结果如表3~7所示.表中空白处对应任务上无实验结果的情况有2种可能的原因:1)方法未获得任何PC节点或MB节点(如表3和表4所示的PCMB方法在REGED和MARTI的测试集上得不出结果);2)方法不适用于该项任务(如表5和表6所示的LCD2方法,因为Weblog的网络结构中没有真正的初始变量,即Cooper[4]所指的instrumental variable,因此LCD2方法在实验ET.S.Weblog中无法获得有效结果).表3~6中粗体数字为同一评测标准下的最好成绩.以实验ET.C.REGED.Train(如表3所示)为例,ICIC_Target方法在父子网络结构(PC结构)和父子配偶网络结构(MB结构)发现2项任务中的代价矩阵得分(9.0和21.5)分别小于HITON_PC方法的得分(大于等于18.0)和HITON_MB方法的得分(大于等于40.0),因此本文方法在该实验中存在性能优势.在实验ET.S.Weblog和ET.M.SIGNET中,我们以每个变量为目标变量计算得到|V|个局部网络结构,并以代价矩阵得分的均值作为性能评估标准,实验结果如表5和表6所示.表7展示了本文方法在实验ET.M.SIGNET中发现的激励因果和抑制因果的情况,并与IC方法进行了比较.其中“×”表示算法发现的错误的因果关系,“√”表示正确的因果关系.表格上半部是存在抑制因果的等式,表格下半部是只有激励因果的等式,各等式等号右边变量为因变量,等号左边为果变量.
Table 5Results of Mean PC Score of Cost Matrix in Weblog and SIGNET Experiments
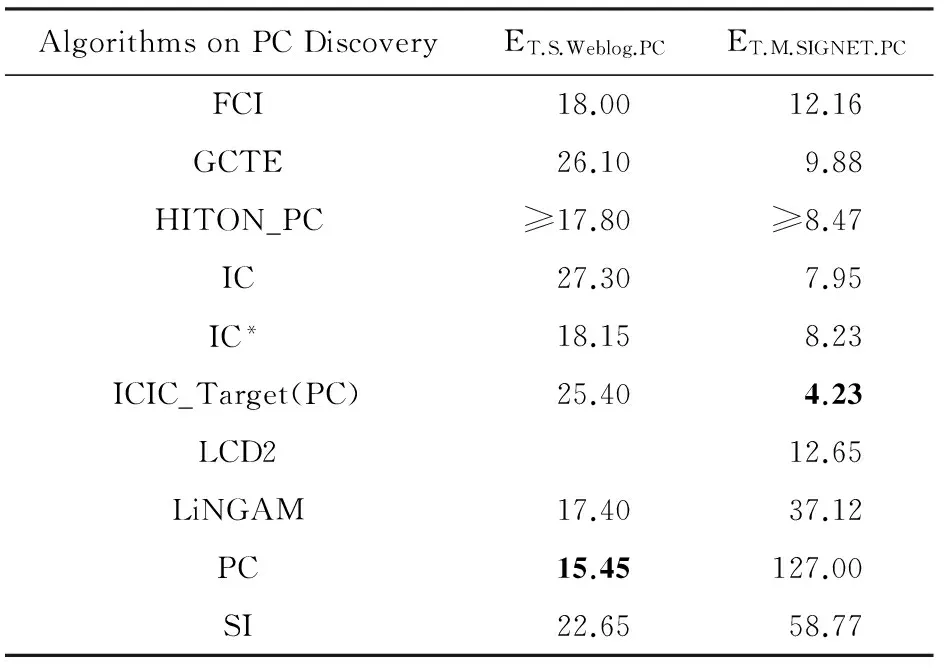
表5 Weblog和SIGNET的PC实验结果
Table 6Results of Mean MB Score of Cost Matrix in Weblog and SIGNET Experiments
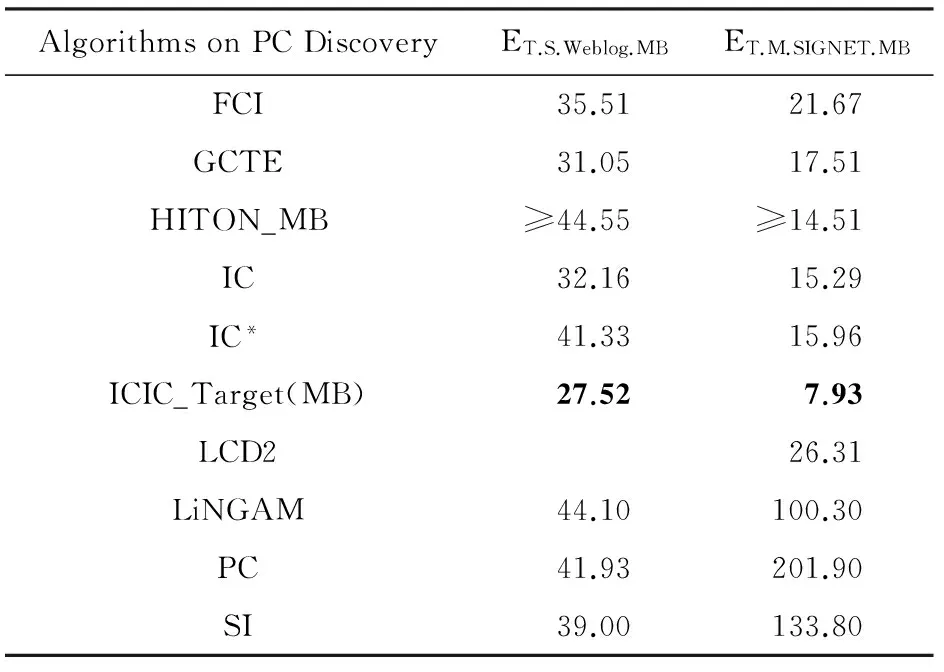
表6 Weblog和SIGNET的MB实验结果
Table 7 Comparison of Stimulating and Inhibiting Causalities Discovered by ICIC_Target and IC in ET.M.SIGNET
表7 ICIC_Target与IC的ET.M.SIGNET实验结果(激励抑制因果)对比

Table 7 Comparison of Stimulating and Inhibiting Causalities Discovered by ICIC_Target and IC in ET.M.SIGNET
TrueEquations(Boolean)ICIC_TargetICStimulatingInhibitingStimulatingInhibitingCAIM=ROSandnotDEPOLAR×CAIM=…andnotCLOSURE√CAIM=…andnotDEPOLARATRBOH=OSTandROP2andnotABI×CLOSUREHATPase=notPH√HATPase=…andnotPH×HATPase=…andnotCLOSUREActin=notRAC×Actin=…orCLOSURE√Actin=…ornotRACABI=notPAandnotROSKAP=notPH√KAP=…andnotPH×KAP=…andnotCLOSURECa=(CAIMorCIS)andnotCaATPaseAnionEM=notABIorCa×ATRBOHDEPOLAR=KEVorAnionEMornotHATPaseornotKOUTorCa×DEPOLAR=…orPH×DEPOLAR=…orCLOSURE×DEPOLAR=…orROS√DEPOLAR=…ornotHATPaseNO=NIA12andNOS×CaATPase×KEV,√NOSCLOSURE=(KOUTorKAP)andAnionEMandActin√CLOSURE=…orKOUT√CLOSURE=…orActin√CLOSURE=…andKAPcADPR=ADPRc√ADPRcIP6=InsPK√IP6=…orInsPK×IP6=…orCLOSURENIA12=RCN√NIA12=…orRCN×NIA12=…orCLOSUREROP2=PA×ATRBOHS1P=SPHK√S1P=…orSPHK
Note: Symbol “×” means wrong equation has been discovered by ICIC_Target or IC method, and “√” means right equation has been discovered.
本文10组对比实验的结果(如表3~7所示)展示了ICIC_Target方法良好的性能,该方法的准确性在大多数据集上领先.在实验过程中,该方法表现出了很好的鲁棒性和稳定性,能较好地处理不同类型和特性的数据,程序运行速度快,尤其表现在处理REGED和MARTI测试数据(涉及上千个变量和上万条采样记录)这样的大规模因果系统上,ICIC_Target方法平均耗时明显低于HITON方法,达到了150(相同的运算环境下,ICIC_Target方法耗时2~5 min,由Causal Explorer实现的HITON方法平均耗时达到2 h).另外,本文方法能更好地发现和区分激励因果和抑制因果,如表7所示,可以进一步为后续分析或应用提供更多有用的信息.
3.2算法的稳定性、复杂性分析
3.2.1稳定性分析
本文将分析算法2在输入有误差或错误时能否保持合理的可靠性.文献[2]提出了算法稳定性概念:若输入小错误产生了输出的大错误,则算法不稳定.
算法2首先通过判定V中与目标变量“相关”的变量子集对所有变量进行过滤.若该步骤将某个PC或MB变量排除在相关子集外,则该变量及其父子变量很难会对其他PC 或MB变量的判定产生影响,因此此类误差不会破坏算法的稳定性.然而,该步骤通常会将判定条件设定的非常宽松,这就在相关子集中引入了大量非PC或MB变量.对这类误差,后续步骤的目标就是逐步细化相关子集、缩小误差影响的过程,因此ICIC_Target算法的整体稳定性主要依赖ICIC_Structure方法.
ICIC_Target算法的核心ICIC_Structure函数的Step3(相当于IC算法[1]第1步或PC算法[2]的step A的功能)若存在小错误,则很可能是某些d-割关系被错误地包含或排除在下一步的输入中.本文2.3节已说明,该步可能产生冗余边,即确定2个节点间的d-割关系比确定二者d-connection更苛刻,因此ICIC_Structure在Step8回溯并删除冗余边.可见ICIC_Target算法能控制产生冗余边的问题,在最终输出时尽量减少错误.另一个可能的错误是ICIC_Structure的Step2输出时错误地包含或遗漏某些初始变量.被遗漏的初始变量会在后续程序中被逐渐找回,而包含伪初始变量的错误会在后续程序中被放大,因为错误的初始变量将影响一部分边的方向判定.为限制该类错误,EVD算法设计的尽可能严格地判定初始变量.其他步骤产生小错误或受小错误影响的情况有限,因此ICIC_Target方法具有较好的稳定性.
3.2.2复杂性分析
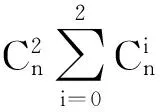
实际上,这些判定的平均数量还会远远小于该上限值,因为ICIC只需判定2个节点是否被d-割,无需知道谁d-割了它们(不同于PC需要知道d-割集Sepset(vi,vj),就要遍历完所有的变量和变量组合),因此最坏情况出现的概率远远小于PC等算法.另外,我们还可以通过优先遍历高度数节点优化算法.
ICIC_Target方法增加了初始变量的判定和IClique的计算,我们认为这些是在保证准确性、增强鲁棒性的前提下可以接受的代价.因为EVD极少得到比真实nev多的初始变量,因此最坏情况下以上2个步骤运算的次数是:nev和(n-nev)nev,且每个初始变量的判定都需要遍历数据集.因此EVD算法的复杂度为O((m+n)nev).在添加方向和删除冗余边的2个步骤中,考虑以下2种极端情况:1)若ICIC在条件独立判定步骤之后得到的无向图仍是完全无向图,则删边的复杂度可以忽略;2)若添加方向步骤后得到的有向图有最多的三角形结构、最少的初始变量、最少的公共边(同时处于至少2个三角形结构中的边),则删边步骤就遇到了最坏情况,此步的复杂度为O(n),与此同时添加方向步骤的复杂度为O(n).这2个步骤的最坏情况不会同时出现,因此复杂度上限为O(n2),更精确些为O(nk).此外,ICIC_Target判定相关子集的步骤还可以大大降低后续算法的复杂度.综上所述,算法的复杂度为O(n4+mnev).
4结束语
本文针对真实环境下局部因果关系发现问题,通过分析因果关系的作用机制,利用初始变量和初始团树,提出了性能更高、鲁棒性更强的局部因果关系网络发现方法ICIC_Target.实验和理论分析表明,该方法具有更好的稳定性、复杂度、鲁棒性.该方法克服了传统方法由于受限于边的不确定性、双向边、圈、v结构等不足,降低了复杂性,且无需基于过多的前提和先验知识,因此更加适用于真实环境下的因果关系发现.
下一步将改进或优化初始变量的发现算法以提高算法的准确率、降低复杂度,进一步开展因果关系发现后的因果关系分析,包括因果的演化模型、隐含变量发现与分析,以及因变量合作竞争机制、遗传机制等方面的研究.
参考文献
[1]Pearl J. Causality: Models, Reasoning, and Inference [M]. Cambridge, UK: Cambridge University Press, 1999
[2]Spirtes P, Glymour C, Scheines R. Causation, Prediction, and Search[M]. 2nd ed. Cambridge, MA: MIT Press, 2000
[3]Cooper G F, Herskovits E. A Bayesian method for the induction of probabilistic networks from data[J]. Machine Learning, 1992, 9(4): 309-347
[4]Mani S, Cooper G F. A study in causal discovery from population -based infant birth and death records[C]Proc of the American Medical Informatics Association (AMIA) Annual Fall Symp. Philadelphia, PA: AMIA, 1999: 315-319
[5]Granger C W J. Investigating causal relations by econometric models and cross-spectral methods[J]. Econometrica, 1969, 37(3): 424-438
[6]Guyon I. NIPS 2008 Workshop on Causality: Workshop Information Publishing[EBOL]. (2008-12-12)[2013-07-11]. http:www.clopinet.comisabelleProjectsNIPS2008
[7]The Causality Workbench Team of NIPS 2008. Challenges in machine learning—Causality challenge #1: Causation and prediction [EBOL]. (2008-12-12)[2013-07-11]. http:www.causality.inf.ethz.chchallenge.php?page=datasets
[8]The Causality Workbench Team of NIPS 2008. LUCAS and LUCAP are lung cancer toy datasets: Dataset Description[EBOL]. (2008-06-06)[2013-07-10]. http:www.causality.inf.ethz.chdataLUCAS.html
[9]Glymour C, Cooper G F. Computation, Causation, and Discovery [M]. Menlo Park, CA: AAAI Press, 1999
[10]Aliferis C F, Tsamardinos I, Statnikov A. HITON, a novel Markov blanket algorithm for optimal variable selection[C]Proc of the American Medical Informatics Association (AMIA) Annual Symp. Washington, DC: AMIA, 2003: 21-25
[11] Tsamardinos I, Brown L E, Aliferis C F. The max-min hill-climbing Bayesian network structure learning algorithm[J]. Machine Learning, 2006, 65(1): 31-78
[12] Guyon I, Aliferis C F, Cooper G F, et al. Design and analysis of the causation and prediction challenge[J]. Journal of Machine Learning Research: Workshop and Conf Proc, 2008, 3: 1-33
[13] Aliferis C F, Statnikov A, Tsamardinos I, et al. Local causal and Markov blanket induction for causal discovery and feature selection for classification part i: Algorithms and empirical evaluation[J]. Journal of Machine Learning Research, 2010, 11: 171-234
[15] Aliferis C F, Tsamardinos I, Statnikov A R. Causal explorer: A probabilistic network learning toolkit for biomedical discovery[C]Proc of Int Conf Mathematics and Engineering Techniques in Medicine and Biological Sciences (METMBS). Las Vegas: CSREA Press, 2003: 371-376
[16] Aliferis C F. Causal Explorer Download: Register Page[CPOL]. (2003-06-26)[ 2013-08-01]. http:www.dsl-lab.orgcausal_explorer
[18]Shibuya T, Harada T, Kuniyoshi Y. Causality quantification and its applications: Structuring and modeling of multivariate time series[C]Proc of the 15th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2009: 787-796
[19] Lozano A C, Abe N, Liu Yan. Grouped graphical Granger modeling methods for temporal causal modeling[C]Proc of the 15th ACM SIGKDD Int Conf Knowledge Discovery and Data Mining. New York: ACM, 2009: 577-586
[20] Ancona N, Marinazzo D, Stramaglia S. Radial basis function approach to nonlinear Granger causality of time series [J]. Physical Review E: Statistical Nonlinear and Soft Matter Physics, 2004, 70(5): 148-168
[21] Shimizu S, Hoyer P O, Hyvärinen A, et al. A linear non-Gaussian acyclic model for causal discovery [J]. Journal of Machine Learning Research, 2006, 7: 2003-2030
[22] Arnhold J, Grassberger P, Lehnertz K, et al. A robust method for detecting interdependences: Application to intracranially recorded EEG [J]. Physica D, 1999, 134(4): 419-430
[23] Lungarella M, Ishiguro K, Kuniyoshi Y. Methods for quantifying the causal structure of bivariate time series [J]. International Journal of Bifurcation and Chaos (IJBC), 2007, 17(3): 903-921
[24]The Causality Workbench Team of NIPS 2008. Home page of challenges in machine learning—Causality challenge #1: Causation and prediction [EBOL]. (2008-12-12) [2013-07-11]. http:www.causality.inf.ethz.chchallenge.php?page
[25] The Causality Workbench Team of NIPS 2008. The causal discovery in Web logs: Problem and datasdet[EBOL]. (2008-06-06) [2013-07-10]. http:www.phobos.rodataindex.html
[26]The Causality Workbench Team of NIPS 2008. SIGNET abscisic acid signaling network: Desciption of problem and dataset[EBOL]. (2008-06-06) [2013-09-23]. http:www.causality.inf.ethz.chrepository.php?id=5
[27]Sun Jing, Yin Jianping, Wang Ting, et al. A novel model of bursts in event sequences[C]Proc of the Int Conf on Consumer Electronics, Communications and Networks (CECNet). Piscataway, NJ: IEEE, 2012: 816-821

Li Yan, born in 1979. PhD. Her main research interests include text mining and natural language processing.

Wang Ting, born in 1967. Professor and PhD supervisor. His main research interests include artificial intelligence and computer software.

Liu Wanwei, born in 1980. PhD and associate professor. His main research interests include formal method and verification.

Zhang Xiaoyan, born in 1981. PhD and experimentalist. Her main research interests include text mining and natural language processing.
收稿日期:2014-11-14;修回日期:2015-09-06
基金项目:国家自然科学基金项目(61170287,60873097)
中图法分类号TP391
ICIC_Target: A Novel Discovery Algorithm for Local Causality Network of Target Variable
Li Yan1, Wang Ting1, Liu Wanwei1, and Zhang Xiaoyan2
1(CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073)2(CollegeofHumanitiesandSocialSciences,NationalUniversityofDefenseTechnology,Changsha410073)
AbstractCausality research aims to reveal the law of evolution of nature, society and human. Nowadays, the causality research receives widespread attention for its important applications of human life and science research, but there are still many difficulties and challenges. This paper presents a unified model to explain the stimulating and inhibiting causalities. Based on this model, we also present a framework ICIC and a novel algorithm ICIC_Target to infer the local causal structure of a target variable from observational data without any limitation of some assumptions, such as assumption of acyclic structure, hidden variables and so on. Following our descriptions of causality essence and properties, as well as several classical theories proposed by Judea Pearl, Gregory F. Cooper and so on, we introduce concepts of exogenous variable and clique-like structure (IClique) to get rough ordering of variables, which are necessary for revealing the causality accurately and efficiently. To evaluate our approach, several experiments compared with HITON, IC, PC, PCMB and several methods based on four datasets with different data types have been done. The results demonstrate the higher performance and stronger robustness of our algorithm ICIC_Target. In this paper, we also discuss the advantages of stability and complexity of ICIC_Target.
Key wordscausality; causal network; local causal network discovery; stimulating causality; inhibiting causality
This work was supported by the National Natural Science Foundation of China (61170287,60873097).
猜你喜欢
唐山学院学报(2021年4期)2021-11-20
南大法学(2021年6期)2021-04-19
医学与法学(2020年2期)2020-07-24
高中生·天天向上(2018年7期)2018-07-23
传播力研究(2018年14期)2018-03-27
职工法律天地(2017年12期)2017-01-26
湘江法律评论(2016年0期)2016-06-15
刑法论丛(2016年1期)2016-06-01
刑法论丛(2016年1期)2016-06-01
中国检察官(2015年12期)2015-02-27
