PLUFS: 一种开销敏感的周期任务在线多处理器节能实时调度算法
2016-08-01 06:18张冬松赵志峰
计算机研究与发展 2016年7期
张冬松 王 珏 赵志峰 吴 飞
1(镇江船艇学院 江苏镇江 212001)2 (上海工程技术大学电子电气工程学院 上海 201620)
PLUFS: 一种开销敏感的周期任务在线多处理器节能实时调度算法
张冬松1王珏1赵志峰1吴飞2
1(镇江船艇学院江苏镇江212001)2(上海工程技术大学电子电气工程学院上海201620)
(dszhang@nudt.edu.cn)
摘要现有周期任务多处理器节能调度算法虽然在考虑处理器实际开销情况下可以实现较好的节能效果,但仍不能保证最优可调度性.针对嵌入式实时系统中不可忽视的状态切换开销,提出一种开销敏感的周期任务在线多处理器节能实时调度算法PLUFS.该算法通过TL面流调度模型与处理器实际切换开销模型相结合,在每个TL面的初始时刻、任务结束执行时刻实现节能调度,在不违反周期任务集最优可调度性的前提下,达到实时约束与能耗节余的合理折中.经过理论证明和模拟实验,结果表明:PLUFS算法不仅保证了周期任务集的最优可调度性,而且节能效果整体优于现有算法,能耗节余比现有算法提高约10%~20%.
关键词开销;多处理器系统;节能调度;周期任务;实时系统
随着多核芯片和片上多处理器系统的不断推出,多处理器平台变得更加普遍,已经越来越多地被应用于各类实时系统领域.能耗管理已经成为嵌入式系统和服务器系统中一个重要的系统设计问题,可以用于延长电池使用寿命或降低用电成本.
在嵌入式实时系统中,基于动态电压频率调节(DVFS)技术[1]和动态功耗管理(DPM)技术[2]的节能实时调度已经被广泛研究.节能实时调度就是在满足实时约束下实现节能.许多研究者都在关注多处理器系统的实时节能调度问题,但很多研究成果都是在划分法调度的基础上针对周期或基于帧的任务模型而提出多处理器系统节能实时调度算法[3-4].文献[3]首次提出一种基于划分法的实时节能调度方法,指出多核系统中周期任务节能调度是一个NP-hard问题;文献[4]通过研究多核处理器系统中各种硬件节能技术特点,指出不存在一种算法能够满足所有的情况和约束,各种节能调度算法都有其不同的适用条件,还有一些研究成果提出基于全局调度法的DVFS节能调度技术[5-7];文献[5]针对同构多处理器系统,使用全局EDF离线节能调度算法解决了周期性实时任务的系统级节能问题,但是仅仅通过离线统一分配任务执行速度来实现节能,没有实现任务集的最优可调度性;文献[6]针对周期任务集,基于一种最优全局实时调度算法LLREF[8],提出多处理器最优离线节能调度方法,这种最优性未考虑转换开销;文献[7]针对基于帧的任务模型,提出一种最优的节能实时调度算法LTF-M,该算法在考虑开销的实际环境中不是最优的[9].
但是以上这些算法大多集中于各种开销可以忽视的理想DVFS处理器,没有考虑实际DVFS处理器具有的频率更改开销和状态切换开销等物理限制.对于许多硬实时应用来说,是否考虑开销、考虑哪些开销对节能实时调度可能产生较大影响,忽视这些细节可能会得到次最优甚至是无效的结果.例如如果状态切换的能耗开销大于能耗节余,那么显然把处理器转入睡眠状态很可能不会节能[9].
面对越来越不容忽视的开销问题,很多研究者已经开始关注具有处理器实际开销限制的节能实时调度问题.文献[10]根据工作负载确定活跃处理器的个数,并结合实际处理器具有的状态切换开销提出节能实时调度算法;文献[11]则进一步考虑具有离散速度的系统,针对有向无环图任务模型,提出启发式节能实时调度算法;而文献[9]通过说明关键速度的非最优性以及负载均衡的非最优性,针对基于帧的任务模型和周期任务模型,提出了一种考虑状态切换开销的节能实时调度算法,该算法显著地优于原有未考虑开销情况下的近似算法[12];文献[13]基于划分调度方法,提出一种考虑实际处理器状态切换开销的在线节能实时调度算法.虽然现有的周期任务多处理器节能调度算法在考虑处理器实际开销情况下可以实现较好的节能效果,但不能保证最优可调度性.
为此,本文针对具有独立DVFS和DPM技术的多处理器系统,在考虑处理器状态切换开销情况下,提出一种基于切换开销的周期任务在线节能实时调度算法PLUFS(periodic tasks with largest utilization first based on switching overhead),该算法首先利用流调度模型将所有任务实例的绝对截止期在时间轴上表示为若干个两两相连且不重叠的TL(time local)面,然后在每个TL面的初始时刻,采用最大任务利用率优先策略和处理器切换开销模型来确定每个TL面内所有周期任务的最优执行速度和最优可用处理器个数,接下来确定TL面内所有任务的调度过程;最后在TL面内任务结束执行时刻,通过维护TL面内任务调度序列和处理器状态切换,在保证周期任务集的最优可调度性下实现节能.
本文的主要贡献如下:
1) 针对常见的周期任务模型,将TL面流调度思想与考虑切换开销的最优节能策略有机结合起来,提出一种开销敏感的在线多处理器节能实时调度算法PLUFS,在满足硬实时约束的条件下获得了合理的能量节余.
2) 经过系统的理论分析以及大量的模拟实验,既给出了所提PLUFS算法的最优可调度性证明,又验证了PLUFS的节能效果整体优于现有算法,接近于理论最优值.
1系统模型与问题定义
1.1处理器模型
本文假设多处理器系统由m个同构处理器构成,m为常数,处理器命名为{cpu1,cpu2,…,cpum}.处理器cpuk以速度(或称为频率)s运行时的功耗Pk(s)=α×s3+β[14],α>0,β≥0.这种功耗模型适用于多种具有DVFS和DPM技术的处理器,例如Intel Xscale处理器[14].显然,Pk(s)是严格凸函数和递增函数.假设同构多处理器可以在最低处理器速度smin和最高处理器速度smax之间连续调节.
处理器以速度s执行一个时钟周期的能耗为P(s)s=α×s2+βs.P(s)s是凸函数[15],使得该函数具有最小值的速度即是关键速度s*.这里关键速度定义为处理器执行一个时钟周期所用能耗最小时的速度[7,9].显然,s*满足如下性质[9,14]:∀s,smin≤s≤smax,P(s*)s*≤P(s)s.
处理器有2种状态:睡眠状态和活跃状态.当处理器处于睡眠状态时,DPM技术可以关闭处理器时钟,将处理器电压降低到非常低的水平,以至于处理器功耗可以忽略不计,近似为0[9].执行任务的处理器则处于活跃状态.由于睡眠状态中处理器上下文等信息不被保存,所以返回活跃状态需要一定的时间和能量开销[9].不妨定义处理器状态切换的时间开销为tsw,处理器状态切换的能量开销为Esw,处理器从活跃状态转入睡眠状态的break-even时间为tθ.当处理器的空闲时间大于break-even时间时,将处理器转入睡眠状态是节能的.通常假设break-even时间tθ为状态切换能耗开销Esw与处理器空闲时功耗Pidle之比,并且大于状态切换时间开销tsw[9].这里空闲功耗Pidle为常量,且不小于处理器在最低速度时的功耗P(smin),即Pidle≥P(smin).此外,处理器的状态切换时间开销是毫秒级,而频率更改时间开销是微秒级,状态切换时间开销远大于频率更改时间开销[9].
1.2任务模型
本文考虑多处理器DVFS系统中周期实时任务集T={τ1,τ2,…,τn},任务τi用二元组(pi,Ci)表示,其中:pi是周期,Ci是任务τi在最高频率下的最坏情况执行时间或执行时钟数.所有周期实时任务具有相同的初始释放时间.每个周期任务具有无穷序列的任务实例τi j∈{τi1,τi2,…},又称为作业.任务τi的每个任务实例都按照相同周期释放.任务τi的相对截止期等于周期,任务实例τi,k的绝对截止期di,k=k×pi,其释放时间ri,k=(k-1)×pi.任务τi的利用率为ui=Cipi,任务集的总利用率为ui,τi∈T.任务τi在最高处理器速度下的最坏情况执行时间Ci是预先已知的.假设所有的任务都是独立的,允许在任意时刻在多处理器之间抢占和迁移.
为保证周期任务集的最优可调度性,任务调度算法借鉴基于TL面的流调度思想[8],以一个时间片(即TL面)为单位,通过与节能策略相结合,实现实时任务节能调度算法.简单地说,TL面是一个二维平面,水平轴表示时间,垂直轴表示任务的局部剩余执行时间(local remaining execution time).TL面之间相互连续且互不重叠[8].在TL面内任意时刻t,每个任务τi均有一个局部剩余执行时间li,t≥0.如果在TL面的结束时刻,所有任务的局部剩余执行时间均为0,则称所有任务是局部可调度的[8].
1.3问题定义
考虑一个独立周期任务集T在m个同构多处理器上节能调度执行.每个处理器具有相同的功耗函数P(s)=α×s3+β,α,β≥0.每个处理器的执行速度均在smin和smax之间.每个周期任务具有最坏情况执行时间或执行时钟数和周期,且相对截止期等于周期.处理器从睡眠状态转入活跃状态的切换能耗开销为Esw,同时时间开销为tsw≤EswP(smin).本文目标在于考虑处理器切换开销条件下保证周期任务集的最优可调度性的同时尽可能地降低系统能耗.
2PLUFS算法
2.1基本思想
尽管研究者已经提出了不少多处理器节能实时调度算法,但是这些算法大多考虑的是没有考虑开销的理想情况.对于越来越不容忽视的处理器开销问题,虽然已有研究者提出了针对周期任务模型的开销敏感多处理器节能实时调度算法,但是该算法只能在低负载情况下获得较好的节能效果,无法保证在高负载情况下任务的可调度性.针对基于帧的实时任务模型,我们之前的研究成果已提出考虑实际切换开销情况下的多处理器最优节能实时调度算法LUF-SO[16].试想,能否考虑把LUF-SO算法直接应用到周期任务集呢?答案是否定的.原因在于周期任务集中所有任务都具有的相同周期应该是超周期,但在超周期内每个任务具有多个任务实例,这些任务实例的绝对截止期又不相同,所以直接应用LUF-SO算法得到的调度序列无法保证周期任务集的可调度性.
接下来,通过对2种基于TL面的周期任务最优多处理器实时调度LLREF[8]算法和LRE-TL算法[17](这里将周期任务看作是偶发任务的特例)分析可知,如果在每个TL面的初始时刻为每个任务分配与任务利用率成比例的局部剩余执行时间,并且要求在TL面的结束时刻之前所有任务必须完成其局部剩余执行时间,那么每个TL面的结束时刻可以作为TL面所有任务的局部截止期.显然,每个TL面内具备局部剩余执行时间的所有任务具有相同的局部截止期,这一特性符合基于帧的实时任务模型的要求.因此,本文将LUF-SO中离线节能调节策略与TL面中在线实时调度相结合,提出一种针对周期任务集的开销敏感在线节能实时调度算法PLUFS.
PLUFS算法采用最大任务利用率优先策略[16],在考虑处理器实际状态切换开销情况下,在每个TL面的初始时刻计算最坏情况下周期任务集的最优可用处理器个数和任务的最优执行速度,从而确定所有任务在每个TL面内的节能实时调度序列.在每个TL面边界上,PLUFS算法将初始化TL面;在每个TL面内,PLUFS算法处理所有的任务结束执行事件.TL面初始化程序会根据当前TL面的时间长度,为新的TL面重新计算所有的参数,确定任务的调度过程和处理器的执行速度.任务结束执行事件处理程序用于维护TL面内任务调度过程的正确性和处理器状态切换.一旦初始化或任务结束执行事件处理程序被完成,PLUFS算法将指导每个处理器按照分配的频率来执行被指派的任务.
2.2主程序描述
PLUFS算法由3个程序构成,主程序描述如算法1所示.PLUFS首先初始化参数,令当前时刻tc和当前TL面的结束时刻tf均为0(见算法1中行①),然后在每个TL面初始时刻,PLUFS将调用TL面初始化程序(见行③~⑤),计算每个TL面内周期任务集在考虑切换开销情况下最优的可用处理器个数和每个任务的执行速度,在线调节所有任务的调度序列,实现TL面中节能实时调度.在每个TL面内任意时刻,一旦某个处理器上发生任务结束执行事件,PLUFS将调用任务结束执行事件处理程序(见行⑥~⑧),确保TL面内任务调度过程和处理器状态切换的正确性.一旦初始化或事件被完成,PLUFS会循环等待直到下一个初始化或事件发生(见行②~⑧).
算法1. PLUFS.
①tc←0,tf←0;
② while TRUE do
③ iftc=tfthen
④PLUFS_TL_Initialize();
⑤ endif
⑥ if 处理器cpuk上任务τi在当前时刻tc结束执行 then
⑦Upon_Task_End_Execution(τi,tc,k);
⑧ endif
本文采用与文献[8]相同的方法来划分TL面,每个任务实例的绝对截止期就是一个TL面的结束时刻.显然,对于任意TL面σ和任一任务τi,τi中最多有一个任务实例与TL面σ重叠.因为所有的实时调度策略都是基于一个TL面而产生的,所以只有与当前TL面重叠的任务实例才会被调度.
2.3TL面初始化
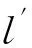
算法2.PLUFS_TL_Initialize().
① for 所有在当前时刻tc到达的任务τido
② ifHD.find_key(tc+pi)=NULL then
③HD.insert(tc+pi);
④ endif
⑤ endfor
⑥tf←HD.extract_min();
⑦D←tf-tc;
⑧ 按照任务利用率ui的非递增顺序排列所有任务τi∈T;
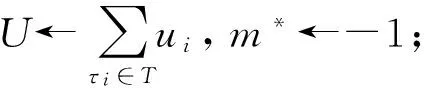
⑩ ifU>mor ∃τi∈Tsuch thatui>1 then

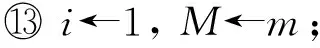
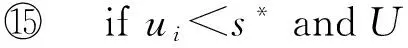
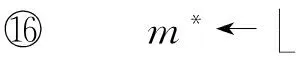
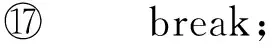
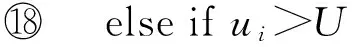

andi←i+1;


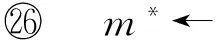

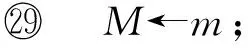

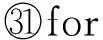


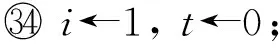
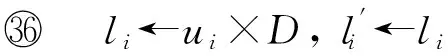



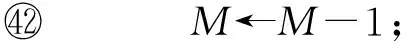


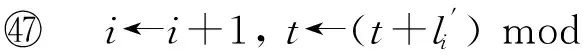
PLUFS算法使用一个HD堆结构来保存当前所有任务的绝对截止期.HD堆结构包含3种方法.其中,如果关键字等于k的对象在HD堆中存在,则HD.find_key(k)返回该对象的指针,否则返回为空;HD.insert(I)方法将关键字I插入到HD堆中;HD.extract_min()方法从HD堆中删除具有最小关键字的对象.这3种方法的计算复杂度均为O(log(HD堆大小)).
算法2的具体思想如下:

2) 当ui≥s*时,如果ui>UM,则说明任务τi是重任务(heavy),需要单独在一个处理器上执行,它的速度τi.speed为ui,更新参数U和M之后继续后续任务的判断(见行);否则,说明当前未分配速度的所有任务利用率均不大于任务集的平均速度,这些任务∀τj∈{τi,τi+1,…,τ|T|}都是轻任务(light),其速度τj.speed均为UM(见行).
3) 当ui 一旦确定每个TL面的时间长度D和每个任务的局部剩余执行时间li=ui×D,PLUFS算法就可以采用与原有LUF-SO相同的方法,基于任务的最坏情况执行时间确定TL面初始时刻的任务调度序列.但由于每个TL面的时间长度各不相同,使得任务集在每个TL面内具有不同的任务调度序列和执行速度,所以PLUFS属于在线算法. 定理1. 在每个TL面初始时刻t0,如果PLUFS算法通过算法2来确定周期任务集T在TL面[t0,tf]内的任务调度序列,则该任务调度序列可以保证T中所有任务在当前TL面的结束时刻tf之前完成其局部剩余执行时间. 证毕. 2.4任务结束执行事件 算法3. Upon_Task_End_Execution(τi,tc,k). ① if 在处理器cpuk上没有任务等待执行 then ② iftf-tc>tθthen ③ 将处理器cpuk转入睡眠状态; ④ else ⑤ iftf>tcthen ⑥ 将处理器cpuk转入空闲状态; ⑦ endif ⑧ endif ⑨ else ⑩ 处理器cpuk继续以τi.speed×smax为速度值,按照TL面初始化分配的时间间隔来调度执行后续任务; 定理2. 如果PLUFS算法通过算法3来处理每个TL面内任务结束执行事件,那么对该事件的处理不会影响到TL面初始时刻所确定的任务调度序列. 证明. 由算法3易知,当周期任务τi在某个处理器cpuk上结束执行时,如果处理器cpuk上没有任务等待执行,那么算法3只是根据此时所产生的静态松弛时间大小判断是否将该处理器转入睡眠状态或者空闲状态,并没有涉及到对其他处理器上任务的处理.而如果处理器cpuk上任务队列不为空,还有后续任务等待执行,那么算法3不会改变算法2为后续任务分配的开始执行时间与结束执行时间,后续任务在处理器cpuk上的执行序列和执行速度没有变化.得证. 证毕. 3算法分析 3.1可调度性分析 由于不考虑周期任务集为不可调度的情况,如不做特殊说明,本文均假设周期任务集T满足U≤m,且∀τi∈T,ui≤1. 定理3. 如果周期任务集T使用PLUFS算法调度执行,则T中所有任务在每个TL面内是局部可调度的. 证明. 反证法.所有任务在TL面内具有局部可调度性的定义是指在TL面的结束时刻所有任务的局部剩余执行时间均为0.如果周期任务集T在某个TL面内是局部不可调度的,那么在该TL面的结束时刻一定存在某个任务τi的局部剩余执行时间不为0.已知每个周期任务在PLUFS算法下只能在每个TL面内初始时刻、任务结束执行时刻被调度执行.由定理2可知,任务τi的调度序列是在当前TL面初始时刻被确定,而在每个TL面内任意的任务结束执行时刻,PLUFS算法对任务结束执行事件的处理不会影响到当前TL面初始时刻所确定的任务调度序列.再由假设条件易知,在当前TL面初始时刻所确定的任务调度序列无法保证任务τi在当前TL面结束时刻之前完成其局部剩余执行时间.这与定理1矛盾,命题得证. 证毕. 定理4. PLUFS算法可以保证周期任务集T的最优可调度性. 证明. 因为所有的TL面是连续的,且两两独立,没有重叠区域,前一个TL面的结束时刻是后一个TL面的开始时刻,所以可以采用归纳法证明.因为周期任务集T满足U≤m且∀τi∈T,ui≤1,所以根据PLUFS算法和定理3可知任务集T在第1个TL面内是可调度的.又因为由定理3可知任务集T在第2个TL面内也是可调度的,根据归纳假设可知PLUFS算法可以保证任意连续多个TL面的局部可调度性,从而可得所有任务均满足其截止期.命题得证. 证毕. 3.2复杂度分析 设任务集T中任务总数为n,处理器数为m,每个任务状态数量为w,每个处理器状态数量为v. 1) 时间复杂度.算法3中行②~⑧的切换处理器状态以及行⑩的调度后续任务继续执行,每步的时间复杂度均为常量,因此算法3的时间复杂度为O(1). PLUFS算法的运行时间依赖于它所调用的程序,如算法1所示.算法1的行①参数初始化的时间复杂度为O(1).根据算法2可知,算法1中最大抢占和迁移次数均为O(m).因此,算法1中行②~⑧之间有一个循环,任务结束执行事件处理程序在每个TL面内被调用次数为O(n+m). 2) 空间复杂度.如果采用顺序表存储,任务集T所占用的空间为O(n×w),处理器状态所占用的空间为O(m×v).因为HD堆中只存放一个关键字即任务的绝对截止期,所以HD堆所占用的空间为O(n). 4实验 本文在Linux 2.6环境下采用C语言编写了一个离散事件模拟器,针对具有独立DVFS和DPM的多处理器系统,实现了多种周期任务节能实时调度算法,包括非节能的P-LRE-TL算法[17]、Independent RT-SVFS算法[6]、P-RSLTF算法[9]、PLUFS算法以及Lower-Bound算法[9].其中,P-LRE-TL算法是对LRE-TL算法用于周期任务模型的简称,选用它的原因在于其计算复杂度远小于LLREF算法[8];Lower-Bound算法是忽视处理器开销条件下的理论最优算法,而其他算法可看作真实算法.Lower-Bound算法允许将所有任务以关键速度执行,它的能耗可以作为考虑开销条件下实际最优能耗的下界[9]. 本文以P-LRE-TL算法的能耗作为标准进行归一化,比较算法的归一化能耗(normalized energy consumption, NEC),然后比较可调度性(feasibility performance, FP),最后对可调度性与归一化能耗之比(简记FPNEC)这个综合指标进行比较;此外,还比较算法在不同切换能耗开销情况下的归一化能耗与不同最小可用速度情况下的归一化能耗. 4.1参数产生 为更贴近真实任务集,实验引入下列环境参数:usys,m和n.usys表示系统利用率,m表示处理器个数,n分别表示任务个数,周期任务集的总负载Workloads=usys×m.每个任务利用率ui使用Uunifast算法[18]而产生,这样不仅有助于分析利用率与任务集中任务个数的关系,还可以产生n个任务利用率在[0,Workloads]的无偏分布.每个任务的周期pi在[1,1000] ms之间均匀分布,可以模拟绝大多数硬实时应用.每个任务τi的最坏情况执行时间Ci=ui×pi. 为了全面评价算法的性能,模拟实验采用了3种不同的参数设置:1)系统利用率usys从10%开始增加到100%,步长是10%;处理器个数m分别设为4,8和16,任务个数n分别设为10,20和40,且smin=0,Esw=1 mJ;2)切换能耗开销Esw从0.2 mJ增加到1.5 mJ,步长是0.05 mJ;系统利用率usys分别设为0.1,0.3和0.7,处理器个数m=8,任务个数n=20,smin=0;3)最小可用速度smin从0 GHz增加到0.25 GHz,步长是0.0125 GHz;系统利用率usys分别设为0.1,0.3和0.7,处理器个数m=8,任务个数n=20,Esw=1 mJ.模拟时间为每组任务集的“超周期”,即任务集中所有任务周期的最小公倍数.对于每种参数设置,本文测试100 000组任务集,取平均能耗值以便较真实地反映算法性能. 4.2实验结果 Fig. 1 Normalized energy consumption changing with workloads.图1 归一化能耗 图1给出了在考虑处理器实际切换开销的情况下,P-LRE-TL,Independent RT-SVFS,P-RSLTF,PLUFS以及Lower-Bound算法在第1种参数设置下的周期任务集的归一化能耗.从图1(a)中可知,当处理器个数为4、任务集中任务个数为10时,不论任务集的总负载如何变化,PLUFS算法的节能效果除了差于理论最优Lower-Bound算法以外,优于其他真实算法,尤其在低负载情况下能耗节余比Independent RT-SVFS算法高约20%,高负载情况下能耗节余比P-RSLTF算法高约10%. 一方面,在系统利用率小于0.3的低负载情况下,PLUFS算法与P-RSLTF算法的能耗节余比较接近,两者都比Independent RT-SVFS算法具有更多的节能.这是因为Independent RT-SVFS算法静态地将任务集中所有任务分配到所有的处理器上执行[6],离线确定每个处理器的状态切换情况,运行时不再改变节能策略,而低负载情况很可能会产生频繁的状态切换,导致切换开销大于能耗节余,说明它不能较好适应因系统利用率降低而产生的动态负载变化.而PLUFS算法与P-RSLTF算法均考虑到状态切换开销问题,允许任务运行在比关键速度更低的速度来减少状态切换次数,可以更好地适应动态负载变化,从而实现更多的节能. 另一方面,在系统利用率大于0.3的高负载情况下,P-RSLTF算法与Independent RT-SVFS算法的能耗节余比较接近,随着总负载的增加,两者的能耗节余不断减少.虽然PLUFS算法获得的能耗节余也不断减少,但是更接近于Lower-Bound算法的能耗节余.这是因为P-RSLTF算法基于划分方法来调度周期任务集而只能实现降低部分任务的执行速度,Independent RT-SVFS算法属于静态节能调度方法,随着总负载的增加,所有的处理器都会运行以满足任务集可调度性的要求,此时这2种算法无法实现任务集在更多处理器上减少状态切换次数,不适应高负载情况下动态负载变化.但是PLUFS算法可以在保证周期任务集最优可调度性的同时,根据处理器开销模型和每个TL面的时间长度确定在每个TL面中所有任务的节能实时调度序列,能够利用完全动态的任务实例级迁移来减少状态切换次数,确保在高负载情况下也能取得较好的节能效果. 另外,当处理器核数m=8,任务个数n=20(如图1(b)所示)和处理器核数m=16,任务个数n=40(如图1(c)所示)时,可以得到与图1(a)相类似的结论,这反映出在不同处理器核数条件下,除了Lower-Bound算法以外,PLUFS算法的节能效果整体优于其他真实算法,其能耗节余随着总负载的增加而缓慢减少. 同时,在图1(a)~(c)中还可以注意到,在系统利用率最高时的高负载情况下,P-RSLTF算法的归一化能耗值不存在,例如在处理器核数和任务集总负载均为4,在处理器核数m=8而任务集总负载为8,以及处理器核数m=16而任务集总负载为16.这是因为P-RSLTF算法基于最大任务优先策略实现超周期内周期任务的划分调度,只考虑在可调度任务集下的平均能耗值,而在高负载情况下无法实现任务集的可调度性,故而平均能耗值不存在,如图2所示: Fig. 2 Feasibility performance changing with workloads.图2 随负载变化的可调度性分析 基于与图1相同的实验参数设置,图2给出了算法的可调度性.从图2(a)中可知,PLUFS和Independent RT-SVFS算法均能保证最优可调度性,P-RSLTF算法的可调度性却随着总负载的增加而不断降低,直至近似为0.这是因为PLUFS和Independent RT-SVFS算法均是基于TL面的流调度思想来实现最优实时任务调度,而P-RSLTF算法本质上还是多处理器划分任务调度方法,不具有最优可调度性[9].另外,从图2(a)~(c)中可以看出,PLUFS算法在不同实验参数下,均可以在实现节能的同时保证周期任务集的可调度性. Fig. 3 Feasibility performance normalized energy consumption.图3 可调度性与归一化能耗之比(FPNEC) 为了全面衡量各个节能实时调度算法的性能,基于与图2相同的实验参数设置,图3给出了可调度性与归一化能耗之比.从图3(a)中可知,不论任务集的总负载如何变化,PLUFS算法的FPNEC值最接近Lower-Bound算法,但大于其他真实算法,并且随着总负载的增加,该FPNEC值从5.8左右缓慢减小到1左右.这是因为PLUFS算法不仅保证了最优可调度性,而且能耗节余较多.Independent RT-SVFS算法的FPNEC值则随着总负载的增加,先增后减,在系统利用率大于0.3之后逐渐趋近于非节能P-LRE-TL算法的FPNEC值,这恰好反映了Independent RT-SVFS算法的静态节能实时调度特性.而P-RSLTF算法的FPNEC值在系统利用率小于0.3时接近PLUFS算法,但在系统利用率大于0.3时,其FPNEC值逐渐减小直至为0.这是因为P-RSLTF算法在高负载情况下可调度性不断降低,且能耗节余不断减少.另外,从图3(b),(c)中可以得到与图3(a)相一致的结论,这反映在不同实验参数条件下,除了Lower-Bound算法以外,PLUFS算法的FPNEC值大于其他真实算法. 图4给出了在考虑处理器不同切换能耗开销情况下,P-LRE-TL,Independent RT-SVFS,P-RSLTF,PLUFS以及Lower-Bound算法在第2种参数设置下的周期任务集的归一化能耗.从图4(a)中可知,当处理器个数m=8、任务集中任务个数n=20、最小可用速度为0和总负载为0.8时,不论处理器的切换能耗开销如何变化,PLUFS算法的节能效果除了差于理论最优Lower-Bound算法以外,优于其他真实算法.这是因为Independent RT-SVFS算法属于静态节能调度方法,本身并没有考虑切换能耗开销,不受切换能耗开销变化的影响.P-RSLTF算法基于任务利用率来计算不同任务划分方法中所有任务的执行速度,使得任务调度序列中存在大量小块的空闲时间,而PLUFS算法也是基于任务利用率计算每个TL面内所有任务的执行速度,同样会产生大量小块的空闲时间,这些空闲时间的存在使得无法更多地减少状态切换次数,因此仅仅减少切换能耗开销不会对2种算法节能效果产生较大的影响.Lower-Bound算法本身没有考虑处理器切换开销情况,显然不受切换能耗开销变化的影响. Fig. 4 Normalized energy consumption under different energy switching overheads.图4 不同切换能耗开销情况下归一化能耗 当总负载为2.4(如图4(b)所示)和总负载为5.6(如图4(c)所示)时,可以得到与图4(a)相类似的结论,这反映出在不同总负载情况下,不论切换能耗开销如何变化,除了Lower-Bound算法以外,PLUFS算法的节能效果整体优于其他真实算法,其能耗节余随着总负载的增加而缓慢减少. Fig. 5 Normalized energy consumption under different minimum available speeds.图5 不同最小可用速度情况下归一化能耗 图5给出了在考虑处理器不同最小可用速度情况下,P-LRE-TL,Independent RT-SVFS,P-RSLTF,PLUFS以及Lower-Bound算法在第3种参数设置下周期任务集的归一化能耗.从图5(a)中可知,当处理器个数m=8、任务集中任务个数n=20、切换能耗开销为1.0 mJ和总负载为0.8时,不论处理器的最小可用速度如何变化,PLUFS算法的节能效果除了差于理论最优Lower-Bound算法以外,优于其他真实算法.这是因为处理器的最小可用速度主要用于计算处理器空闲功耗和进入睡眠状态的break-even时间,随着最小可用速度的减小,处理器空闲功耗会减少,而break-even时间会增大.Independent RT-SVFS算法属于静态节能调度方法,运行时处理器的电压和频率不能改变,所以随着最小可用速度的减小,空闲功耗会减少,导致能耗节余会有所增加.Lower-Bound算法不仅没有考虑处理器切换开销情况,还不允许任务以低于关键速度来执行,而实验中最小可用速度的最大取值仍小于关键速度,所以该算法不受最小可用速度变化的影响.P-RSLTF算法和PLUFS算法都是基于任务利用率来计算所有任务的执行速度,在任务调度序列中都存在大量小块的空闲时间,空闲功耗的减少和break-even时间的增大会使得处理器倾向于空闲状态,但这样又会增加可用处理器个数,同样会增加能耗,因此最小可用速度的变化对2种算法节能效果的影响有限. 当总负载为2.4(如图5(b)所示)和总负载为5.6(如图5(c)所示)时,可以得到与图5(a)相类似的结论,这反映出在不同总负载情况下,不论最小可用速度如何变化,除了Lower-Bound算法以外,PLUFS算法的节能效果整体优于其他真实算法,其能耗节余随着总负载的增加而缓慢减少. 5结束语 本文针对具有独立DVFS的多处理器系统,在考虑处理器状态切换开销情况下,提出一种基于周期任务模型的在线节能实时调度算法PLUFS.1)该算法利用TL面流调度模型将周期任务调度分解为每个TL面内任务调度问题;2)在每个TL面的初始时刻,采用最大任务利用率优先策略来确定具有最低能耗值的活跃处理器个数,再根据状态切换时间和能量开销来确定任务调度序列;3)在TL面内任务结束执行时刻,通过维护TL面内任务调度序列和处理器状态切换,在保证周期任务集的最优可调度性下实现节能.系统的理论分析证明了PLUFS算法的最优可调度性.大量的模拟实验结果表明PLUFS算法不仅可以保证周期任务集的最优可调度性,而且整体优于现有算法,尤其在低负载情况下能耗节余比Independent RT-SVFS算法高约20%,高负载情况下能耗节余比P-RSLTF算法高约10%. 参考文献 [1]Rele S, Pande S, Onder S, et a1. Optimizing static power dissipation by functional units in superscalar processors[G]LNCS 2304: Proc of the 11th Int Conf on Compiler Construction. Berlin: Springer, 2002: 261-275 [2]Chandrakasan A, Sheng S, Brodersen R. Low-power CMOS digital design[J]. IEEE Journal of Solid-State Circuit, 1992, 27(4): 473-484 [3]Yang C, Chen Jianjia, Luo T. An approximation algorithm for energy-efficient scheduling on a chip multiprocessor[C]Proc of Design, Automation and Test in Europe. Piscataway, NJ: IEEE, 2005: 468-473 [4]Rotem E, Mendelson A, Ginosar R, et al. Multiple clock and voltage domains for chip multiprocessors[C]Proc of the 42nd Annual IEEEACM Int Symp on Microarchitecture. New York: ACM, 2009: 459-468 [5]Anderson J, Baruah S. Energy-efficient synthesis of periodic task systems upon identical multiprocessor platforms[C]Proc of the 24th Int Conf Distributed Computing Systems. Piscataway, NJ: IEEE, 2004: 428-435 [6]Funaoka K, Kato S, Yamasaki N. Energy-efficient optimal real-time scheduling on multiprocessors[C]Proc of the 11th IEEE Symp on Object Oriented Real-Time Distributed Computing. Piscataway, NJ: IEEE, 2008: 23-30 [7]Chen Jianjia. Energy-efficient scheduling for real-time tasks in uniprocessor and homogeneous multiprocessor systems[D]. Taibei, Taiwan: National Taiwan University, 2006 [8]Cho H, Ravindran B, Jensen ED, An optimal real-time scheduling algorithm for multiprocessors[C]Proc of the 27th IEEE Real-Time System Symp. Piscataway, NJ: IEEE, 2006: 101-110 [9]Chen Jianjia, Thiele L, Energy-efficient scheduling on homogeneous multiprocessor platforms[C]Proc of ACM Symp on Applied Computing. New York: ACM, 2010: 542-549 [10]Xu R, Zhu D, Melhem R, et al. Energy-efficient policies for embedded clusters.[C]Proc of ACM SIGPLANSIGBED Conf on Languages, Compilers, and Tools for Embedded Systems. New York: ACM, 2005: 1-10 [11]Langen P J D, Juurlink B H H. Leakage-aware multiprocessor scheduling for low power[C]Proc of Parallel and Distributed Processing Symp. Piscataway, NJ: IEEE, 2006: 80-87 [12]Horn WA. Some simple scheduling algorithms[J]. Naval Research Logistics Quarterly, 1974, 21(1): 177-185 [13]Huang H, Xia F, Wang J, et al. Leakage-aware reallocation for periodic real-time tasks on multicore processors[C]Proc of the 5th Int Conf on Frontier of Computer Science and Technology. Piscataway, NJ: IEEE, 2010: 85-91 [14]Zhu D. Reliability-aware dynamic energy management in dependable embedded real-time systems[C]Proc of the 12th IEEE Real-Time and Embedded Technology and Applications Symp. Piscataway, NJ: IEEE, 2006: 397-407 [15]Irani S, Shukla S, Gupta R. Algorithms for power savings[C]Proc of the 14th Annual ACM-SIAM Symp on Discrete Algorithms. New York: ACM, 2003: 37-46 [16]Zhang Dongsong, Wu Fei, Chen Fangyuan, et al. An overhead-aware optimal energy-efficient real-time scheduling algorithm on multiprocessors[J]. Chinese Journal of Computers, 2012, 35(6):1297-1312 (in Chinese)(张冬松, 吴飞, 陈芳园, 等. 开销敏感的多处理器最优节能实时调度算法[J]. 计算机学报, 2012, 35(6): 1297-1312) [17]Funk S, Nadadur V. LRE-TL: An optimal multiprocessor algorithm for sporadic task sets[C]Proc of Conf on Real-Time and Network Systems (RTNS). Paris: INRIA HAL, 2009: 159-168[18]Bini E, Buttazzo G C. Measuring the performance of schedulability tests[J]. Journal of Real-Time Systems, 2005, 30(12): 129-154 Zhang Dongsong, born in 1980. PhD and Lecturer. His main research interests include real-time theory and green computing. Wang Jue, born in 1987. Master and teaching assistant. His main research interests include database application and real-time scheduling. Zhao Zhifeng, born in 1970. PhD and associate professor. His main research interests include bigdata application and real-time scheduling. Wu Fei, born in 1968. PhD and professor. Senior member of China Computer Federation. His main research interests include green computing, parallel computing and information intelligent process. 收稿日期:2016-03-11;修回日期:2016-05-16 基金项目:国家自然科学基金项目(61402527,61272097) 中图法分类号TP316.4 PLUFS: An Overhead-Aware Online Energy-Efficient Scheduling Algorithm for Periodic Real-Time Tasks in Multiprocessor Systems Zhang Dongsong1, Wang Jue1, Zhao Zhifeng1, and Wu Fei2 1(ZhenjiangWatercraftCollege,Zhenjiang,Jiangsu212001)2(CollegeofElectronicandElectricalEngineering,ShanghaiUniversityofEngineeringScience,Shanghai201620) AbstractAlthough some existing multiprocessor energy-efficient approaches for periodic real-time tasks can achieve more energy savings with taking practical overhead of processor into consideration, they cannot guarantee the optimal feasibility of periodic tasks. For the non-ignorable overhead of switching the processor state in embedded real-time systems, this paper proposes an overhead-aware online energy-efficient real-time scheduling algorithm in multiprocessor systems, the periodic tasks with largest utilization first based on switching overhead (PLUFS). PLUFS utilizes the fluid scheduling concept of time local (TL) remaining execution plane and the switching overhead of the processor states to implement energy-efficient scheduling for real-time tasks in multiprocessors at the initial time of each TL plane as well as at the end execution time of a periodic task in each TL plane. Consequently, PLUFS can obtain a reasonable tradeoff between the real-time constraint and the energy-saving while realizing the optimal feasibility of periodic tasks. Mathematical proof and extensive simulation results demonstrate that PLUFS guarantees the optimal feasibility of periodic tasks, and on average saves more energy than existing algorithms, and improves the saved energy of some existing algorithms by about 10% to 20% at the same time. Key wordsoverhead; multiprocessor systems; energy-efficient scheduling; periodic task; real-time system This work was supported by the National Natural Science Foundation of China (61402527,61272097).