
基于二元文法模型的汉语句子相似度计算
2016-08-01 03:07郜炎峰王硕宁
中国科技信息 2016年13期
郜炎峰 王硕宁
基于二元文法模型的汉语句子相似度计算
郜炎峰1王硕宁2
1.哈尔滨商业大学计算机与信息工程学院;2.黑龙江旅游职业技术学院郜炎峰(1990-)男,硕士研究生,研究方向:自然语言处理。

行业曲线
本文针对汉语句子相似度计算准确率低的问题,提出解决方案。在自然语言处理领域起到至关重要的作用。
如付诸现实将产生可观的经济效益。
创新点:1.在关系向量模型的基础上,加入了长句子的影响因素,使关键词的相似度计算更加准确;2.采用更加合理的句长相似度计算公式,使句长对句子相似度的影响更加合理。
随着信息技术的飞速发展,自然语言处理越来越受到人们的重视,句子相似度计算在自然语言处理领域具有非常重要的地位。基于二元文法模型的汉语句子相似度计算方法以相邻关键词共同出现进行加权的方式计算句子相似度。方法重点考虑关键词词形和句长相似度,还适当考虑了近义词的情况。实验结果表明,该方法可以更好的处理句子长度差较大的句子相似度,在计算汉语句子相似度时准确率高于关系向量模型的方法。
在信息技术迅速发展的今天,信息科技迅速融入各个行业,中国网民数量和网络规模也出现了爆炸性的增长,互联网每天都会有海量的信息产生,这些信息以文本、语音、图片等形式被保存下来,其中文本数据信息占据了三分之二。面对海量的数据,如何从中获取有效信息是自然语言处理的重要使命,汉语句子相似度计算作为自然语言处理的一个热点和难点,在自然语言处理中扮演重要的角色。
句子相似度计算
研究概况
句子相似度计算广泛应用于信息过滤、机器翻译、自动文摘、信息抽取等领域,它的研究现状与其相关的领域息息相关。
国外对英语和日语的句子相似度计算的研究相对比较成熟,但是缺少对汉语句子相似度计算的研究。
国内的汉语句子的相似度研究近些年才逐渐受到重视,并取得了一定的成果,例如:张培颖综合考虑了语句的六个方面特征,并赋予不同特征不同的权重,提出了多特征融合的句子相似度计算方法。吴全娥,熊海灵综合考虑关键词词形、语义和句法结构三个方面计算句子的相似度。文献[5-7]都是从语义的角度计算句子相似度的方法。
本文着重考虑了关键词词形的相似度,对汉语句子的影响因素做了深入研究,提出了基于二元文法模型的汉语句子相似度计算方法。
句子分析
关键词划分
在汉语言文学中,汉语句子都是由起重要作用的主谓宾成分和次要作用的修饰成分组成。一般主语和宾语是代词、名词,谓语是动词、形容词。因此,本文将名词、动词、代词、形容词作为关键词。
特征分析
在句子相似度计算方法中,关键词一直作为唯一的主角,具有无可替代的作用,语句特征虽然很多,但是大多特征都是无足轻重,甚至部分特征之间存有一定的牵制作用,全部考虑所有的特征可能适得其反,本文除关键词外,仅重点考虑句长的影响。
文中的句长表示一个句子包含的词语个数,在句子中词语的多少与信息量的大小有着直接的关系,一般句长较大的句子含有信息量较多。
汉语句子相似度计算
概念与公式
基础概念
设定一个句子Ti,经过分词处理,并提取关键词,得到的词语按顺序构成一个关键词向量,表示形式Ti={g1,g2,g3,…,gn},其中gi表示一个关键词,Ti的句长表示为Len(Ti)。Ti中每一个词语都有一个初始权重值1/n,这些权重值构成的向量称为权重值向量,表示为Tci={1/n,1/n,…,1/n}。
设定两个句子Ti和Tj,Tj的句长较大,针对Ti={g1,g2,g3,…,gn}中的每一个词gi,如果gi或其近义词在向量Tj={g1,g2,g3,…,gn}中也存在,则Ti和Tj共同存在的词构成的向量,称为存在向量,表示为Ei,j={e1,e2,…,ep},其中1≤p≤n。存在向量中的每一个词对应的权重值向量中的权重值构成的向量,称为存在值向量,句子Ti的存在值向量表示为Eci={c1,c2,…,cp},句子Tj的存在值向量表示为Ecj={c1,c2, …,cp}。
假如现对Ti和Tj两个句子进行相似度计算,Tj的句长较大,对存在向量中每一个词ei,让ei在Ti和Tj中的前一个相邻词作比较,如果这两个相邻词是相同的词或近义词,就把该词在权重值向量Tci和Tcj中相应的权重值增加β倍,同时将存在值向量Eci和Ecj中相应的权重值也增加β倍,如果它们不是相同的词或近义词,则权重值不作任何改变。对于ei在Ti和Tj中的后一个相邻词做相同处理,β的取值由实验反复验证获得。
计算公式
设定句子Tj的句长较大,本文提出句长的相似度计算公式如公式(1):
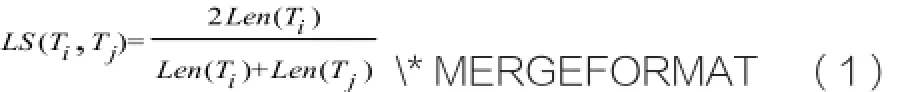
另外,本文根据词语的前后相邻关系提出关键词相似度计算公式,如公式(2):
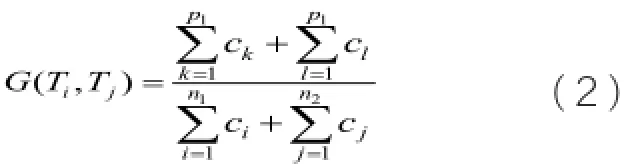
式中,存在向量Ei,j的长度为p1,句子Ti的句长Len(Ti)为n1,句子Tj的句长Len(Tj)为n2;ck代表存在值向量Eci中第k项的值,0<k≤p1,cl代表存在值向量Ecj中第l项的值,1≤l≤p1;ci代表句子Ti的权重值向量Tci第i项的值,1≤i≤n1,cj代表句子Tj的权重值向量Tcj第j项的值,1≤j≤n2。
句子相似度计算具体实现
方法介绍
输入:两个汉语句子Ti、Tj
输出:句子相似度S(Ti,Tj)
方法:
1)假如Tj的句长较大,利用NLPIR分词软件做分词处理。
2)对分词处理后的句子Ti、Tj抽取关键词,并构造两个句子的关键词向量,计算两个句子的存在向量Ei,j。
1.2.3 RTCA增殖实验 RTCA(Real Time Cellular Analysis)中文名为实时细胞分析技术。可实现实时、动态的对细胞进行定量分析,可用于追踪细胞增殖、迁移和浸润。本实验采用xCELLigence RTCA DP(model:3×16)仪器,实验开始前RTCA机器整体置于5%CO2 37℃细胞培养箱内,待RTCA机器温度与培养箱内一致方可开始实验。
3)根据存在向量,分别计算Ti和Tj的权重值向量Tci、Tcj以及Ti和Tj的存在值向量Eci、Ecj。
4)由公式(1)计算两个句子的句长相似度。
5)由公式(2)计算关键词的相似度。
6)采用以下方法计算两个句子相似度。
计算方法
该方法是以基于关键词词形的相似度计算方法为基础,公式表示如式(3):
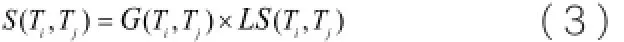
该方法加入了长句子的影响因素,同时也在一定程度上缩小了两个句子长度差对句子相似度的影响。
比较实验
本实验采集了150个汉语句子作为一个测试集,实验分别采用殷耀明等提出的基于关系向量模型的相似度计算方法和本文提出的相似度计算方法做相似度计算结果的比较实验,从中计算出相似度最高的句子组数,每组包含两个句子。分别设定为50组和40组时,实验结果如表1所示。
表1中结果表明本文的相似度计算方法明显优于关系向量模型的相似度计算方法。分析错误数据,发现参考文献中的方法在计算两个句子相似度时,过分夸大了句长的影响。本文方法能更加准确的衡量两个句子的影响因素,因此正确率也较高。
另外,本实验采用的测试集中含有的非关键词较少,对非关键词较多的句子的相似度进行计算时,其正确率可能会受到影响。例如:“不管怎样,你都要我去。”与“你要我去?”两个句子具有相同的关键词,意思却有明显差别。此外,不同的标点符号可能导致两个句子的意思有差异。
结语
本文提出的基于二元文法模型的句子相似度计算方法适当考虑了相邻词语之间的相互影响,准确的衡量了句长对相似度的影响。该方法仅对非关键词较少的句子相似度计算做了验证实验,对非关键词较多的句子相似度还需要做进一步研究。
基金项目:黑龙江省自然科学基金,基于多策略的汉语语句改写研究,F201243;黑龙江省教育厅科学研究项目,基于句子结构特点的汉语语句改写方法研究,12511127
DOI:10.3969/j.issn.1001- 8972.2016.13.025
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05
心理学报(2022年5期)2022-05-16
新高考·高一数学(2022年3期)2022-04-28
客联(2021年5期)2021-09-10
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国医学影像学杂志(2015年9期)2015-12-15
