
基于社交网络中双重好友及用户偏好的协同过滤推荐
2016-07-19 01:18:18胡致杰
长春工业大学学报 2016年3期
胡致杰, 印 鉴
(1.广东理工学院 信息工程系, 广东 肇庆 526100;2.中山大学 数据科学与计算机学院, 广东 广州 510006)
基于社交网络中双重好友及用户偏好的协同过滤推荐
胡致杰1,印鉴2*
(1.广东理工学院 信息工程系, 广东 肇庆526100;2.中山大学 数据科学与计算机学院, 广东 广州510006)
摘要:针对目前基于社交网络的协同过滤推荐算法只融入直接好友信息且不能有效防御概貌注入攻击等问题,提出一种融合双重好友及用户偏好的协同过滤推荐算法,通过设置合适的熟悉度阈值在社交网络的直接好友、间接好友中选取可信好友用户集作为目标用户K近邻候选集,在共同评分项目数的基础上,采用用户偏好相似度与评分相似度的加权相似度作为寻找近邻用户的标准,完成目标用户项目评分预测。在数据集Flixster上的实验结果表明,融合双重好友关系及用户偏好的推荐算法不仅具有较好的推荐准确率,还具有较强的抗概貌注入攻击能力。
关键词:协同过滤; 社交网络; 双重好友; 用户偏好; 概貌注入攻击
0引言
大数据时代,如何让人们在海量数据中寻找需要的信息变得越来越难,为此各类个性化推荐系统应运而生,其中协同过滤推荐是应用最广、最成功的推荐方法之一。其基本思想是:系统中的用户、项目不是孤立存在,而是彼此间具有一定相似性,利用相似用户或相似项目即可实现评分预测或项目推荐。常用的协同过滤推荐为两大类:基于内存的协同过滤和基于模型的协同过滤[1]。基于内存的协同过滤是根据用户项目评分矩阵选取相似度高的用户作为近邻用户,并依据近邻来完成评分预测或项目推荐;基于模型的协同过滤则是对用户评分数据进行数学建模,用以表示用户的行为和兴趣偏好,再通过模型求解实现评分预测或项目推荐。
1相关工作
协同过滤推荐虽能产生高质量的推荐,但存在数据稀疏、冷启动及扩展性三大固有问题,许多学者对此展开了研究,并提出了多种解决方法。如文献[2]提出不确定近邻的协同过滤方法,自适应地选择预测目标的近邻对象,对预测结果进行平衡推荐。文献[3]提出一种并行化的隐式反馈推荐模型p-IFRM,通过将用户及产品随机分桶并重构优化更新序列,达到了并行优化的目的。文献[4]通过矩阵分解填补用户评分,再利用填补后的稠密矩阵直接预测用户评分,较好地解决了数据稀疏性问题。文献[5]提出概率推理模型,通过贝叶斯、高斯概率推理预测用户评分,可一定程度上提高推荐准确度。
在社交网络普遍应用、社交信息极大丰富的背景下,融入社交信息的推荐系统越来越受到人们关注。文献[6]提出一种融合用户社交网络信息的协同过滤方法,通过融入社交网络中关系用户的偏好特征进行矩阵分解产生推荐,实验表明,算法能提高推荐准确度以及缓解数据稀疏性和冷启动问题。文献[7]采用基于随机梯度矩阵分解的社会网络推荐算法,一定程度上缓解了数据的稀疏性问题。文献[8]将社交网络中的信任关系融入协同过滤,通过计算信任网络的信任度来选取最近邻,推荐准确度有较高提升。文献[9]提出利用信任传播的方法,计算加权平均信任度估计值的方法。文献[10]提出结合评分与信任的协同推荐算法,综合了用户相似度与信任度,提高了推荐精度和评分覆盖率。文献[11]提出基于双重邻居选取策略的推荐方法,将用户相似度和信任度作为选取近邻的双重标准,有效提高了推荐质量。
以上融合社交网络的推荐算法都能一定程度上提高推荐准确度,缓解数据稀疏性与冷启动,但仍存在一些不足:
1)在融合社交信息时较多考虑的是目标用户的直接好友,而用户的潜在好友则少有考虑。
2)好友关系是一种社会关系,个人偏好则是用户对不同项目好恶的体现,二者之间呈完全正相关性,但真实情况下二者不具有完全正相关性。
3)一些恶意用户为实现自己的项目被优先推荐,常常会进行概貌注入攻击,对此文献少有考虑。
为此,文中提出融合社交网络中双重好友及用户偏好的协同过滤推荐算法(CollaborativeFilteringRecommendationBasedonDoubleFriendandPreference,CF-DFP),算法基于社交网络中双重好友关系寻找目标用户可信好友用户集,通过可信好友用户的偏好相似度与评分相似度得到加权相似度,然后选取加权相似度最高的前K个用户作为目标用户的最近邻以完成项目评分预测,实验表明,算法能获得较高的推荐准确度,也能一定程度上防御恶意用户的概貌注入攻击。
2基于社交网络中双重好友及用户偏好的协同过滤推荐
2.1问题定义
在社交网络中,基于“好友推荐的可信度更高”的认知观将社交网络中的好友关系融入推荐算法,更符合现实应用情况,但社交网络中的好友包含直接好友和潜在好友,同时不同类型好友个人偏好不同。如何在协同过滤推荐算法中既融入社交网络的好友关系,又考虑好友的个人偏好是文中研究的主题。
2.2基于社交网络的双重好友及熟悉度
推荐系统一般包含用户集、项目集和用户项目评分矩阵,假设U= {u1,u2,…,um}表示用户集,I={i1,i2,…,in}表示项目集,R=[Ru,i]m×n表示用户项目评分矩阵,其中Ru,i表示用户u对项目i的评分,通常R是一个极其稀疏的矩阵。
在社交网络中,用户之间的关系可以抽象表示为一个无向有权图
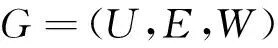
式中:U----用户节点集;
E----直接好友关系集;
W----E中直接好友关系权重集,这里表示用户之间的熟悉度,值越大表示熟悉度越高,关系越亲密。
在构建的好友关系网络中,可以定义直接好友、潜在好友及好友间的权重,如图1所示。
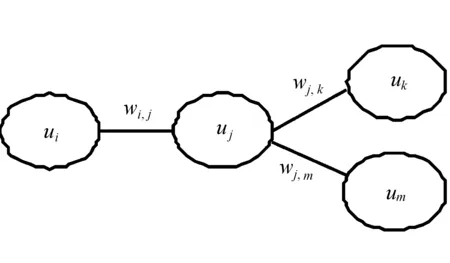
图1 好友关系网及权重
定义1好友关系网络中,直接相连的两个用户称为直接好友,用户ui的直接好友集记为Ud(ui),图1中(ui,uj),(uj,uk),(uj,um)互为直接好友。
定义2好友关系网络中,通过相同直接好友相连,但彼此不直接相连的两个用户称为潜在好友,用户ui的潜在好友集记为Up(ui),图1中(ui,uk),(ui,um),(um,uk)互为潜在好友。
定义3直接好友间的熟悉度即为直接好友间的权重,可表示为:
(1)
式中:familarityd(ui,uj)----用户ui,uj的熟悉度;
wi,j----用户ui,uj之间的权重;
Ud(ui)----用户ui的直接好友集。
定义4通过共同直接好友传递的熟悉度即为潜在好友间的熟悉度,抽象表示如下:
(2)
式中:U+----用户ui,uk共同直接好友集。
2.3可信好友用户集的选取
在社交网络中,如果两个用户之间越熟悉,则两者之间进行的推荐越可信,因此,可选取与目标用户熟悉度较大的直接好友或潜在好友作为可信好友,并依据可信好友用户项目评分预测目标用户项目评分,既可获得较高的推荐质量,也可排除用户恶意注入的评分记录。
定义5可信好友用户集S,给定好友熟悉度阈值θ,目标用户ui∈U,如下面两式成立,则uj,uk∈S(ui)。
(3)
(4)
构造目标用户可信好友用户集的算法描述如下:
算法1可信好友用户集构造算法。
输入:目标用户ui,好友关系图G,熟悉度阈值θ;
输出:目标用户ui的可信好友用户集S(ui)。
Begin
①A1←G//构造社交网络的邻接矩阵
②wi,j←A1,式(1)、式(2) //根据邻接矩阵计算直接好友、潜在好友间的权重
③A2←wi,j//构造权重邻接矩阵
④S(ui)←ui,θ,A2
End
算法主要包含两部分:一是依据社交网络关系图构造邻接矩阵,利用邻接矩阵计算直接好友与潜在好友间的熟悉度,并构造社交网络的权重邻接矩阵;二是利用权重邻接矩阵和熟悉度阈值选择目标用户ui的可信好友用户集S(ui)。
2.4可信好友用户的偏好相似度与评分相似度
在协同过滤推荐中,为目标用户选取理想的近邻用户是保障推荐质量的关键,传统方法仅根据用户评分相似度确定近邻进行推荐的质量往往不高。因此,我们提出在目标用户的可信好友用户集中综合用户的偏好相似度及评分相似度来选取近邻用户。
偏好度是用户对不同项目喜好程度的一种体现,对应用户评分矩阵,如果两个用户共同评分的项目数越多,表明他们的个人偏好越接近,偏好相似度就越高,用户的偏好相似度可用如下公式计算:
(5)
式中:sim′(ui,uj)----用户ui,uj的偏好相似度,sim′(ui,uj)∈[0,1];
I(ui)----用户ui的评分项目集。
在协同过滤算法中,用户相似性可根据用户项目评分矩阵进行计算,常用的相似度包括余弦相似性、改进的余弦相似性和Pearson相似性,文献[12]用实验证明Pearson相似性更适于度量用户间的相似度,因此,这里采用Pearson相似性作为用户相似度的度量方法,具体计算公式如下:
(6)
式中:sim″(ui,uj)----用户ui,uj的评分相似度,sim″(ui,uj)∈[0,1];
Rui,c----用户ui对项目c的评分;
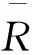
Iij----用户ui,uj共同评分项目集。
2.5用户加权相似度及推荐
对用户偏好相似度与评分相似度进行线性组合可得用户加权相似度,并根据加权相似度选取近邻用户完成评分预测或项目推荐,加权相似度计算公式如下:
(7)
式中:sim(ui,uj)----用户ui,uj的加权相似度;
α----调和参数,用于调节用户偏好相似度与评分相似度,α∈[0,1]。
根据式(7)计算得到目标用户与可信好友用户之间的加权相似度,并依据加权相似度大小选取目标用户的K近邻,再结合用户评分矩阵完成目标用户对目标项目的评分预测,预测评分计算公式如下:
(8)
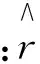
Uk----用户ui的K近邻。
基于可信好友用户偏好度和相似度的推荐算法描述如下:
算法2基于可信好友用户偏好度和相似度推荐算法。
输入:目标用户ui,可信好友用户集S(ui),用户项目评分矩阵R,最近邻用户数K;
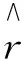
Begin
①R+←S(ui),R;//构造可信好友用户评分矩阵
②sim′(ui,uj)←R+,公式(5);//使用公式(5)在R+上计算用户偏好度
③sim″(ui,uj)←R+,公式(6);
④sim(ui,uj)←α,公式(7);//使用公式(7)计算用户加权相似度
⑤Uk←加权相似度最大的前K个用户
End
2.6算法复杂度分析

3实验结果及分析
3.1实验数据集及评价指标
实验采用来自Flixster网站的数据集作为实验数据集,该网站是一电影社交网站,用户可以分享电影评价及推荐新电影,也可通过电影认识爱好相同的人。数据集包含用户对电影的评分以及用户间的好友信息,包含481 189个用户, 18 760部电影,450 297 863条用户评分记录, 4 197 338条好友关系,用户平均好友数约为8.72,评分数据的稀疏度为95.01%。
实验随机抽取2 000个用户的好友信息及评分数据作为样本数据,并将其中的80%作为训练集,20%作为测试集。
平均绝对误差(Mean Absolute Error, MAE)是较直观、常用的推荐系统评价指标,通过计算项目的预测评分与实际评分之间的偏差来估算推荐的准确度,MAE值越小,表示推荐的准确度越高,MAE计算公式如下[13]:
(9)
式中pi----推荐系统预测的目标用户对项目i的评分;
ri----目标用户对项目i的实际评分;
n----预测评分的项目数。
3.2θ对MAE的影响
θ是目标用户与好友用户之间熟悉度的阈值,主要用于确定目标用户的可信好友用户集,值的大小直接决定可信好友的数量及评分数量,因此需对θ作调优实验。实验参数设置为:α=0.7,K=50,设置θ从0.1变化到1.0,每次变化增量为0.1,依次统计每次改变时的MAE值,实验结果如图2所示。
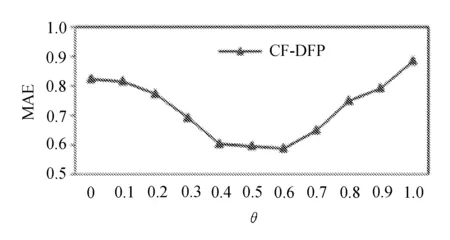
图2 θ对MAE的影响
从图2中可知,θ=0时,是将所有用户都作为目标用户的可信好友,这与传统的协同过滤相同;θ=1时,是将与目标用户具有完全相同好友关系的用户作为可信好友用户,将导致可信好友用户数量极少,推荐质量较差。实验表明,θ在0.6左右取值MAE较小,这也比较符合社交网络中的好友关系图谱。
3.3α对MAE的影响
α是对可信好友用户的偏好相似度与评分相似度进行调和的参数,通过α调和得到用于推荐的加权相似度,因此α对推荐准确度有较大影响。实验参数设置为:θ=0.6,K=50,设置α从0.1变化到1.0,每次变化增量为0.1,依次统计每次改变时的MAE值,实验结果如图3所示。
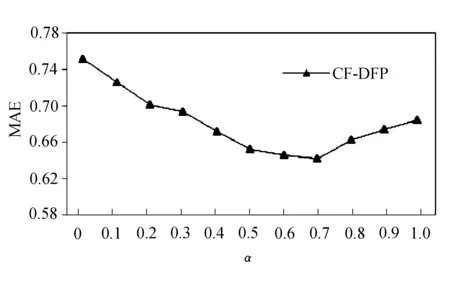
图3 α对MAE的影响
实验结果表明,综合用户偏好相似度与评分相似度的推荐效果比只使用其中一种相似度的推荐效果要好,准确度要高。当α=0.7时,MAE值最小,推荐质量最高。
3.4推荐质量对比
为评判算法的推荐质量,将文中提出的融合社交网络中双重好友及用户偏好的协同过滤推荐算法(CF-DFP)、传统的基于用户的协同过滤推荐算法(UserCF)、融合社交网络信息的协同过滤方法(SocialRec)[6]、结合时间权重与信任关系的协同过滤推荐算法(TTCF)[14]的推荐质量进行对比。实验参数设置为:θ=0.6,α=0.7,4种推荐算法的MAE值对比如图4所示。
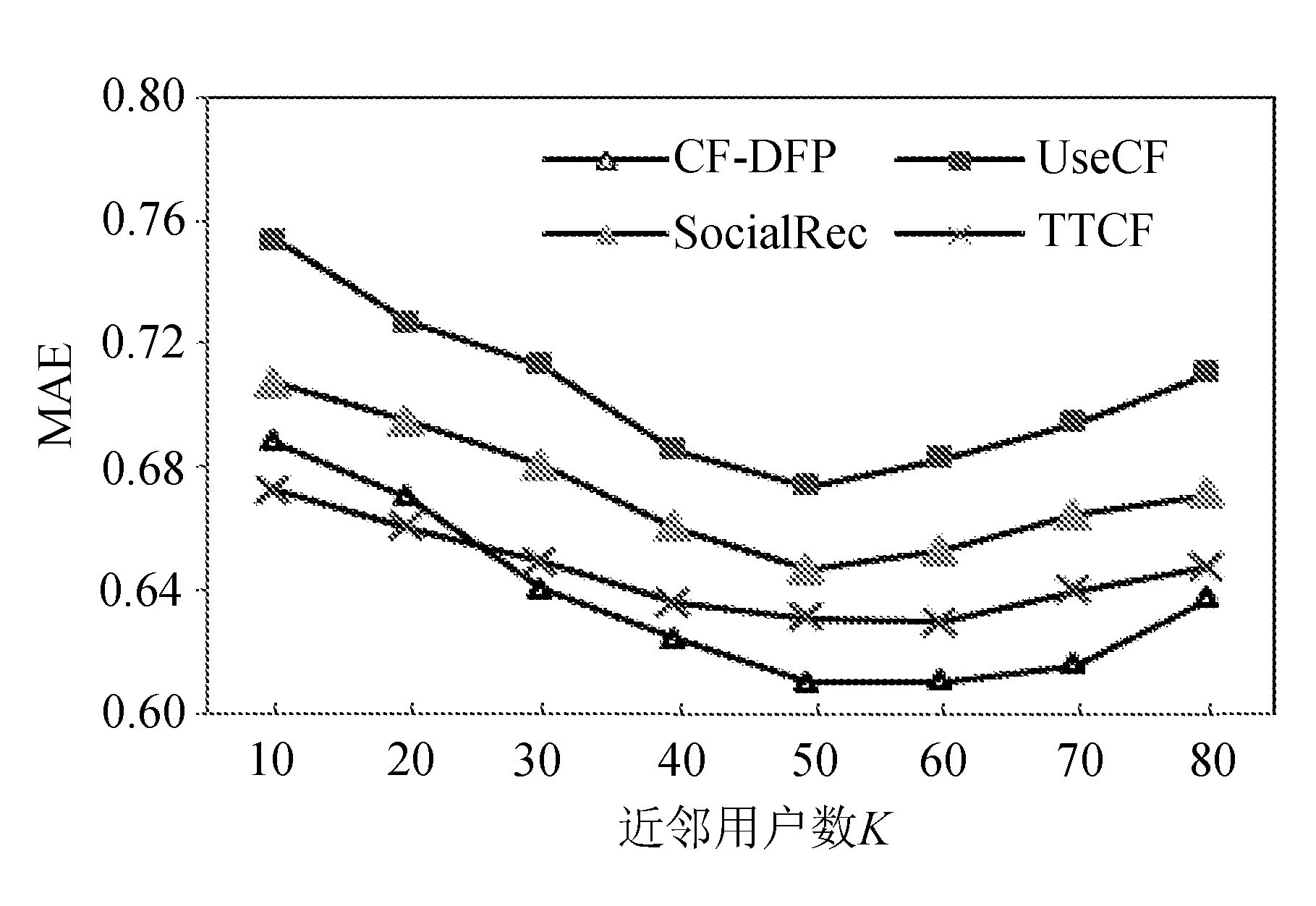
图4 推荐算法质量对比
从图4可以看出,在邻居数量较少时,TTCF算法的MAE值最小,推荐质量最高;随着邻居数量的增加,4种算法的MAE值都呈现出先降后升的趋势,但当最近邻数大于30后,文中的CF-DFP算法能获得比其它3种算法更低的MAE值,并在近邻数为[50,60]区间MAE值最小。因此,推荐算法整体上具有较高的推荐准确度。
3.5抗概貌注入攻击对比
为评判算法的抗攻击能力,分别向实验数据集中注入2%、4%、6%、8%、10%的概貌入侵记录,设置θ=0.6,α=0.7,K=50,上述4种算法的MAE值对比结果如图5所示。
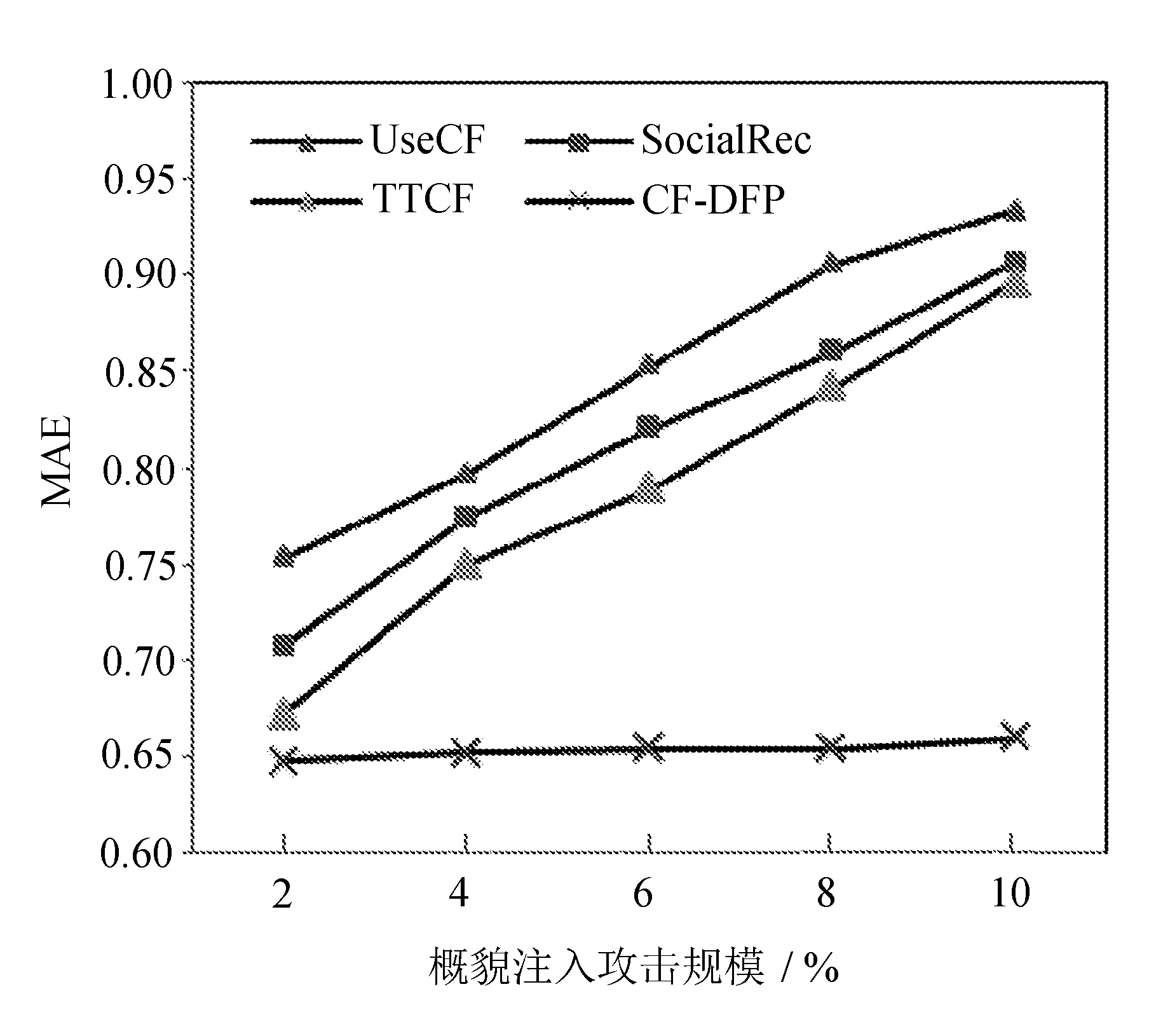
图5 抗概貌入侵对比
从图5可以得出,文中的CF-DFP算法不仅具有较强的抗概貌入侵能力,还具有良好的平稳性。而其它3种算法抗概貌入侵性能较差,随着攻击规模的增大,MAE值都呈现快速上升趋势,推荐准确度急剧下降。
4结语
针对协同过滤推荐算法的推荐准确度和抗攻击能力进行了探索,将社交网络中的直接好友、潜在好友及用户偏好融入推荐算法,算法在用户的直接好友、潜在好友中选取可信好友用户,在可信好友用户集中将用户的偏好相似度与评分相似度作为目标用户K近邻的双重选取依据。实验证明,利用社交关系和用户偏好能极大提高用户预测评分的精确度,同时具有良好的抗概貌注入攻击能力。在社交网络应用日益广泛、信息日益丰富的背景下,如果在推荐系统中更多地融入社交网络信息以改善协同过滤推荐的三大固有问题是未来研究的热点。后续的工作主要包括以下两个方面:一是算法进一步融合社交网络中的隐形好友关系----“可能感兴趣的人”;二是在大数据背景下,如何用并行化来实现可信好友用户集的计算。
参考文献:
[1]许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[2]黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[3]印鉴,王智圣,李琪,等.基于大规模隐式反馈的个性化推荐[J].软件学报,2014,25(9):1953-1966.
[4]ShanH,BanerjeeA.Generalizedprobabilisticmatrixfactorizationsforcollaborativefiltering[C].//Proceedingsof2010IEEE10thInternationalConferenceonDatamining.Piscataway:IEEEPress,2010:1025-1030.
[5]ThakurSS,SingJK.Onlineproductpredictionandrecommendationusingprobabilitygraphicalmodelandcollaborativefiltering:Anewapproach[C].//Proceedingsof2011RecentAdvancesinIntelligentComputationalSystems.Piscataway:IEEEPress,2011:151-156.
[6]贺超波,汤庸,傅城州,等. 融合社交网络信息的协同过滤方法[J].暨南大学学报:自然科学版,2013,34(3):243-248.
[7]李卫平,杨杰.基于随机梯度矩阵分解的社会网络推荐算法[J].计算机应用研究,2014,31(6):1654-1656.
[8]LiYM,WuCT,LaiCY.Asocialrecommendermech-anismfore-commerce:combiningsimilarity,trust,andrelationship[J].DecisionSupportSystems,2013,55(3):740-752.
[9]韩丽.社交网络中的信任推荐和好友搜索过滤算法研究[D].秦皇岛:燕山大学,2012.
[10]秦继伟,郑庆华,郑德立,等.结合评分和信任的协同推荐算法[J].西安交通大学学报,2013,47(4):100-104.
[11]贾冬艳,张付志.基于双重邻居选取策略的协同过滤推荐算法[J].计算机研究与发展,2013,50(5):1076-1084.
[12]BreeseJS,HeckermanD,KadieC.Empiricalanalysisofpredictivealgorithmsforcollaborativefiltering[C]//ProceedingsoftheFourteenthConferenceonUncertaintyinArtificialIntelligence.MorganKaufmannPublishersInc.,1998:43-52.
[13]RicciF,RokachL,ShapiraB,etal.Recommendersystemsandbook[M].Berlin:Springer,2011:145-186.
[14]赵海燕,候景德,陈庆奎.结合时间权重与信任关系的协同过滤推荐算法[J].计算机应用研究,2015,32(5):157-162.
Collaborativefilteringrecommendationalgorithmbasedondoublefriendsrelationshipsanduserspreferences
HUZhijie1,YINJian2*
(1.DepartmentofInformationEngineering,GuangdongPolytechnicCollege,Zhaoqing526100,China;2.SchoolofDataandComputerScience,SunYat-SenUniversity,Guangzhou510006,China)
Abstract:Collaborativefilteringrecommendationbasedonsocialnetworksuffersthefollowingproblems:directfriendsinformationisconsideredonly,weakercapabilityofprofileinjectionattackresistance.Toaddresstheproblem,acollaborativefilteringrecommendationalgorithmbasedondoublefriends’relationshipsandusers’preferences(CF-DFP)isproposed.ThetrustyfriendsetisselectedfromdirectfriendsandpotentialfriendsinsocialnetworkbyproperfamiliaritythresholdandisconsideredasKnearestneighborcandidates(KNNC).Meanwhile,weightedsimilaritycombiningusers’preferencesandratingsisusedtofindKNNinKNNCandpredictratingsforusers.RelatedexperimentresultsonFlixsterdatasetshowthattheproposedalgorithmcannotonlyimprovetheaccuracyofcollaborativefiltering,butalsoresiststheprofileinjectionattackeffectively.
Keywords:collaborativefiltering;socialnetwork;doublefriends’relationship;userpreference;profileinjectionattack.
收稿日期:2016-03-11
基金项目:国家自然科学基金资助项目(61033010,61472453); 广东省自然科学基金资助项目(S2013020012865); 广东省科技计划项目(2013B090200006)
作者简介:胡致杰(1974-),男,汉族,湖北蕲春人,广东理工学院讲师,硕士,主要从事数据挖掘、推荐系统方向研究,E-mail:gl_hzj@foxmail.com. *通讯作者:印鉴(1968-),男,汉族,湖北仙桃人,中山大学教授,博士生导师,主要从事大数据、数据挖掘方向研究,E-mail:issjyin@mail.sysu.edu.cn.
DOI:10.15923/j.cnki.cn22-1382/t.2016.3.05
中图分类号:TP393
文献标志码:A
文章编号:1674-1374(2016)03-0230-06
猜你喜欢
计算机时代(2016年12期)2017-01-14 21:05:05
中国新通信(2016年22期)2017-01-13 08:22:08
软件导刊(2016年11期)2016-12-22 21:40:40
现代情报(2016年11期)2016-12-21 23:35:01
电脑知识与技术(2016年27期)2016-12-15 19:41:16
电脑知识与技术(2016年26期)2016-11-24 18:12:54
电脑知识与技术(2016年24期)2016-11-14 00:32:08
企业导报(2016年20期)2016-11-05 18:53:13
戏剧之家(2016年19期)2016-10-31 19:44:28
新闻前哨(2016年10期)2016-10-31 17:46:44
