
数字图书馆个性化搜索引擎的用户建模
2016-07-09 15:39杨凯
现代电子技术 2016年7期
关键词:数字图书馆
杨凯

摘 要: 网络信息的高速增长导致了信息定位与获取的复杂化,通过分析目前网络的信息超载问题,对现有用户模型的表示法和更新技术进行比较,提出了一种以用户行为和用户操作的资料作为数据源,在用户兴趣漂移问题上采用兴趣衰减,即兴趣学习与常用的滑动窗口算法相结合的方法。最后以数字图书馆个性化搜索引擎中的用户建模系统的设计与实现为例,先后通过与普通向量空间表示模型的对比实验以及用户兴趣漂移时的跟踪学习,证明算法优化有利于更好地表达用户的兴趣,对提高个性化信息服务的质量有实用价值。
关键词: 数字图书馆; 个性化搜索引擎; 用户建模; 向量空间模型
中图分类号: TN911?34; TM417 文献标识码: A 文章编号: 1004?373X(2016)07?0097?06
Abstract: The rapid increasing of network information leads to the complexity of information positioning and acquisition. The existing expression method of user model and updating technology are compared by the analysis of information overloading problem of the current networks. A method of using user behavior and use operation data as the data source is proposed. The interest declining method is adopted for the user interest drift, which is integrated with interest learning and commen used sliding window algorithm. The design and implementation of user modeling system in personalized search engine of digital library is taken an example. The contrast experiments of the proposed model and the model expressed by common vector space, and tracing learning while user interest drift verifies that the optimized algorithm can better express the user interest, and has practical value to improve the quality of high personalized information service.
Keywords: digital library; personalized search engine; user modeling; vector space model
0 引 言
以用户为中心这一服务理念越来越深入图书馆行业的每个角落。早期的个性化信息服务主要集中在实现个性化服务的具体技术上,如推荐技术,信息检索技术,用户聚类技术。然而随着个性化信息服务的深入研究,人们逐渐意识到个性化信息服务的质量不仅取决于具体的推荐技术、检索技术等,还取决于对用户兴趣特点的可计算描述,而且后者更为重要[1]。所以,对用户建模技术的研究开始独立出来作为信息服务中的基础技术。近年来,国内对个性化信息检索用户模型的研究主要集中在用户模型的表示方法、用户建模方法、用户建模技术、用户模型优化等问题上。例如,最常用的用户个性化模型的表示方法有:向量表示法,概念层次表示法等[2]。
因特网为人们提供了日益丰富的资源,但如何从海量的信息资源中获得所需的信息是一个亟待解决的问题。用户对搜索结果的满意度是衡量搜索引擎服务质量的关键之一。用户希望在数字图书馆搜索和获取信息的时候,能够得到更智能的服务方式,而这个智能服务的一个关键因素就是基于个性化[3]。
通过用户建模,得到用户的搜索倾向,当用户进行检索时,对搜索关键词进行分析、扩展并对搜索结果进行过滤,可以在一定程度上提高搜索引擎的搜索质量。同时,可以定时搜索网络新增信息,主动向用户提供其感兴趣的信息。而各种用户模型之间可以通过交流变得更合理,更完善[4]。
个性化搜索引擎不仅可以提高搜索引擎的检索效率,而且使检索结果更加人性化。它通过建立用户的兴趣描述和对不同用户提供不同的信息服务,来满足人们的需求。用户模型作为个性化服务的基础和核心,其质量直接关系到个性化信息服务的质量。在个性化搜索引擎中,首先挖掘用户的兴趣信息,建立合理的模型,然后管理用户的兴趣,通过不断的更新与维护逐渐优化模型,提高用户兴趣需求的表达准确度,为后续的个性化搜索提供基础。
1 用户建模的理论与技术
目前提供个性化信息服务的系统有很多。一些常用的方式有:信息定制服务、最新信息推荐服务、专家咨询服务、个人的知识管理服务、个性化信息检索服务等。要实现个性化服务,首先必须了解用户的个性,对用户兴趣进行挖掘是个性化主动信息服务的基础性前提。目前收集用户信息,发现用户兴趣的方法主要有三类:显示获取方法、隐式获取方法、评价反馈。在用户信息获取技术中,最常用的方法就是前两种获取方式的结合。本系统就是采用了这种方法,并以隐式的行为信息为主,较少需要用户主动参与。显式信息主要包括用户的基本信息和定制信息,隐式信息主要包括用户的浏览行为信息,搜索行为信息。
正确的建模方法能够对用户个性和使用习惯进行跟踪,系统能够不断学习,挖掘用户潜在的兴趣。系统采用了一种有针对性的机器学习方法建模。首先明确可以代表用户兴趣的行为有哪些,并确定这些行为所能表达的用户兴趣程度,然后对搜集到的用户行为信息进行数据挖掘、分析和抽取,计算出模型信息。有针对性的机器学习提高了学习的准确度,通过调节兴趣行为权重参数提高模型的表达能力。
针对用户兴趣漂移问题,采用LRU算法和滑动窗口算法结合的方案。若用户主动更新,如修改并提交定制信息,则以主动行为为主,同时随时间系统自动更新,若用户没有主动参与,则完全采用系统的自动更新。这种方式既利用了用户定制兴趣的针对性,也取消了用户参与的必要性,但保证了模型的准确性。
2 用户建模系统的分析与设计
2.1 向量空间模型的某些局限性
目前,基于向量空间方法用户建模过程中的一些局限性。大部分用户建模的信息源是基于用户浏览的页面和文本内容,或基于用户的查询字段;向量空间表示法是常用的信息资源的表示方式,但是没有考虑到特征项的领域含义和词语表达本身固有的同义性;而单纯的滑动窗口方法,如文献[5]所述,当兴趣量大于窗口大小[L]时,按照到来的先后顺序, 将最初到达的兴趣移出,这种做法有可能将某些先到,但兴趣度高的兴趣描述移出。
系统将采用兴趣衰减、兴趣学习与滑动窗口相结合的方式,提高兴趣表达的准确度。
2.2 信息资源模型
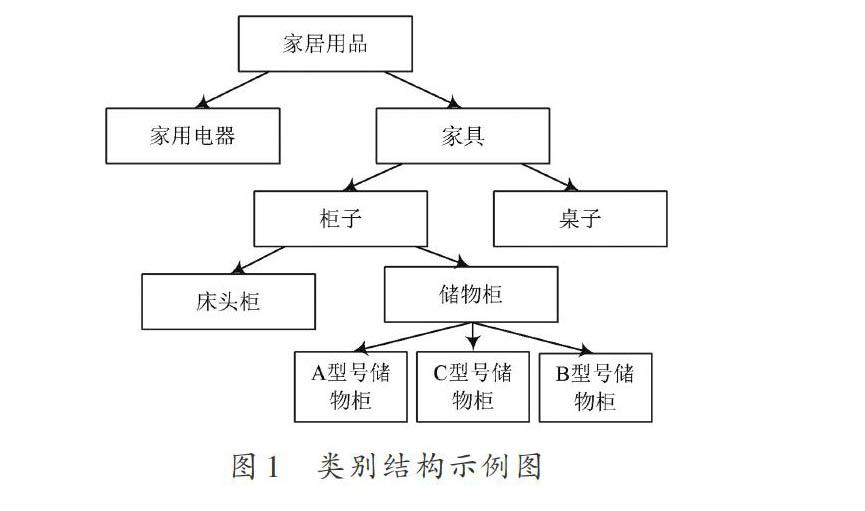
对于被用户使用的对象需要提供基本的情况信息,至少包括代码、名称、类别、关键字/介绍。对象的特征由类别和关键字代表,即{类别,关键字列表},在这种表示法中,类别使用的数据结构是树,如图1所示。
2.3 用户兴趣模型
在个性化服务用户建模中,最常用的方式是将显式方式和隐式方式结合起来,通过显式方式来获取静态用户信息,通过隐式方式来获取动态用户信息[6]。建模的用户信息源包括以下几个方面:
(1) 用户浏览的页面;
(2) 用户在页面内的行为,如添加网页到书签,打印页面,页面内容复制,页面保存等;
(3) 用户的定制信息;
(4) 用户搜索行为查询的关键字,查询次数及其最后查询时间。
当用户使用某信息资源时,例如浏览某些文献,将产生对该资源的兴趣值,使用式(3)进行计算。对于某用户的浏览行为,假设如图2所示。
图2中系列1,系列2,系列3分别表示用户浏览的三类图书。用户对系列1的兴趣逐渐上升,对系列2的兴趣先升后降,对系列3的兴趣也逐渐上升但上升幅度较慢。对于用户的此浏览行为,单纯的滑动窗口算法得到的用户兴趣序列如图3所示。
由图3可知,当兴趣稳定时,单纯的滑动窗口模型表达比较准确,但是当用户的兴趣发生变化,即由系列1和系列2的兴趣变为系列1和系列3的兴趣的过程中,兴趣对象发生剧烈变化,稳定性很差。若采用兴趣衰减,兴趣学习与滑动窗口相结合的方法,得到的用户兴趣表达如图4所示。
每天的兴趣得分由前一天的兴趣得分经过一天时间的衰减加上本天的浏览得分,由此兴趣得分图可得到此模型的滑动窗口中的兴趣对象,如图5所示,对于三方面结合的方法,由于考虑了用户兴趣权重的衰减,新的浏览行为的影响,当用户的兴趣发生改变时,虽然有所迟延,但可以迅速调节跟踪兴趣变化,表达能力比滑动窗口方法要好,比较符合实际情况。
滑动窗口的大小与用户平均兴趣量、对资源访问的频度、资源量的大小相关。用户的兴趣量越大,资源量越大,所需的滑动窗口的尺寸就越大。
2.4 系统功能设计
本文设计的系统功能模块包括信息搜集模块、用户建模模块和检索模块,信息搜集和检索功能模块通过与客户端的交互得到所需资料,并提供服务,用户建模功能模块是系统功能的核心。
搜集本系统所需的相关信息,包括用户基本信息,用户行为信息等,并把从客户端得到的用户信息经检验后整理到数据库中,为其他模块提供所需的信息,是系统建模的主要数据依据。
用户建模代理是系统的核心部分。以用户模型为中心,通过使用可设置的参数,建立用户模型,并提供模型更新方法。当用户使用某对象时,显然用户对此对象是有一定兴趣的。对于对象,可用相应的类别代码及对象的关键字或简述表示。然后根据参数权重计算用户行为代表的对此类别的兴趣度及对此类别下某些关键字的兴趣度,并把此结果记录到用户模型中。
搜索代理是使用用户模型提供服务的一个功能模块,它通过对搜索结果的过滤及重置,向用户提供优化后的检索记录。由用户模型可以得知用户对哪些类别比较感兴趣,因此不同类别的对象可以按用户的兴趣度排序。相同类别的对象可以按关键字列表得分排序,即对照用户模型中此类别的关键字列表及分数,分别计算各对象的关键字得分,分值大的兴趣度高。
2.5 总体设计方案
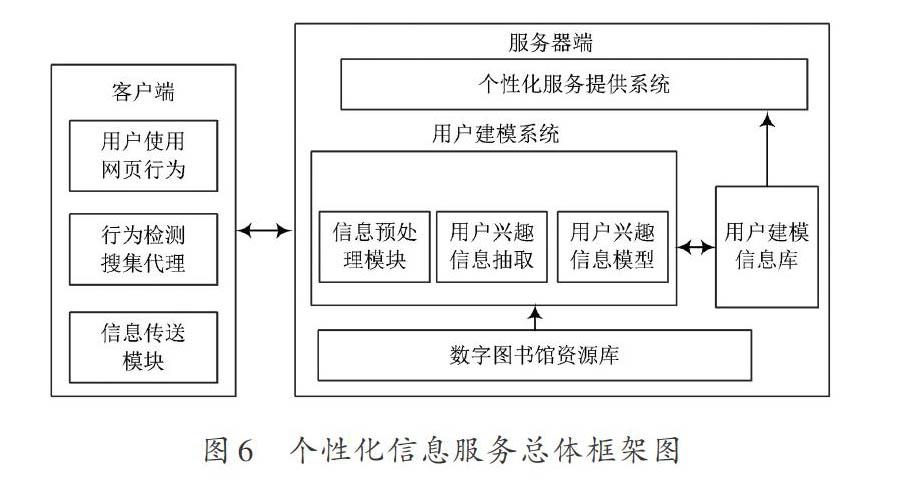
个性化信息检索根据用户的兴趣和特点进行检索,返回与用户需求相关的检索结果。与传统信息检索系统相比,个性化信息检索系统增加了信息处理,用户建模,更新模型,优化查询等模块。搜索引擎的个性化技术主要包含:建立能较好反映用户兴趣偏好的用户模型,并且用户模型能随用户新的行为做适应性的改变,用户的搜索结果可使用用户模型进行重排。在数字图书馆环境下,信息资源为文献资源。个性化信息服务的总体设计如图6所示,本文设计的系统主要是服务器端的功能。
相对于一般的基于向量空间的用户模型系统和针对数字图书馆的文献信息资源,本系统做了以下修改和改进:针对文献资源,使用中图分类树及关键字列表表示信息的特征;使用双重权重向量空间方法进行用户建模;考虑了时间的有效性。当进行用户建模时,若提供的行为信息超过了某时间段, 则视为无效;资源关联性分析,读者对不同类别资源的喜爱存在一定的关联;同时优化兴趣的衰减过程,使用可调节的权重参数。系统使用一些可调节的参数满足不同应用程序的需要,系统部分可调节参数及默认值见表1。
3 系统实现
系统结构采用三层架构的模式。因为这种模型下,将复杂的业务逻辑从数据操作中分离,不必直接与数据库交互,而是通过使用DAO层向外提供的接口,更加易于访问,易于管理。
3.1 信息的表示与存放
对于用户的浏览行为,通常包括把页面加入书签,复制页面部分内容,保存页面到本地磁盘,打印此页面等,这些代表用户兴趣的行为需要被记录下来,同时是哪个用户在哪个页面进行操作也需要记录,这是一种隐式的不需要用户参与的数据。用户定制自己感兴趣的类别是一种显示的直接得到用户兴趣的方式,需要有CustomInfo和CustomeTime信息,包括用户ID、用户定制信息、用户定制日期。
当用户对某关键字搜索时,系统将进行记录,很明显用户对此关键字有一定的兴趣。用户的搜索行为需要得到的信息有KeyWord,LastSearchTime,Times信息;同时,系统需要了解用户的基本情况,获取用户的基本信息,如Name,Sex,Major等。对于数字图书馆系统,需要有文献信息的支持,其中类别代码和关键字列表为重点,类别代码使用此文献的中图分类码。关键字列表使用文献的关键字,表示为逗号隔开的关键字,如数据挖掘,用户模型,个性化,本体等。
3.2 用户兴趣模型的实现
通过对各种用户基本信息及行为信息的分析,得到用户模型,此模型是整个系统的核心,使用模型对用户新的搜索行为进行重排或提供信息推荐服务。用户的兴趣用兴趣类别,兴趣得分,兴趣程度及类别中的关键字表示。分类码BookCode的长度是可重置的,BookCode的长度是指类别树的深度。一个用户可有多条记录,这些记录共同表示该用户的兴趣。
3.3 用户建模功能的实现
4 数据模拟与实验
4.1 文献数据搜集
测试所需的对象数据关键在于标题,类别代码,作者,关键字列表,鉴于这些信息在一些文献网如万方数据库,能获得较全内容,因此把文献作为被使用的对象。共搜集图书数据1 158条。同时,提取全部关键字及对应的分类号,作为备选待用的搜索字存入表SearchWords中,共得到3 598条关键字。
4.2 与普通向量空间模型对比测试
在此采用双重权重表示法,考虑了一定程度的资源关联性及随时间的兴趣衰减模式等,与普通的用户模型相比有一定的优势。
模拟设计10人参与,其ID分别为1~10,兴趣点分别为:政治法律,经济,文化,天文,生物,医药卫生,农业科学,工业技术,交通,环境科学。首先随机选出100篇文章,每类别10篇,按照兴趣点随机产生10人的浏览行为数据。
系统随机产生10用户对相关类别的定制,每人定制约2类,并产生相关类别的一些关键字的搜索行为,每人搜索大约2个关键字,产生定制数据及搜索行为数据,使用本系统所提供方法及默认的建模参数,建模结果如图7所示。采用普通的用户模型,建模结果如图8所示。
建模之后,针对每个读者对其余1 058本图书重排序,假设此1 058本图书是某次搜索产生的结果,位置前者为高兴趣度的文献。由于系统只是对假定的检索结果重排,所以不宜对查全率检测,对于查准率,取信息总量为100,因为全部资源的数目有限,不相关文献较多,对各种用户模型都没有明显的区分效果,所以只查看前100条记录的准确率会更有利。查准率与普通向量空间用户模型的对比如图9所示。图中,采用双重权重表示的用户模型,结合用户行为数据和改进的滑动窗口算法比普通的向量空间模型表示法更能准确表达用户的兴趣趋势,满足用户的需求。
4.3 动态学习效果测试
为了测试学习算法的动态学习效果,首先用数理化类作为兴趣样本生成用户浏览,定制,搜索数据,然后从序列4开始,逐渐改变兴趣,追加学习工业技术类的文献,产生行为数据。每次兴趣学习后,都对测试样本文献进行重排,然后计算其查准率,表2为用户的学习过程。
用户兴趣中数理化领域所占比例及数理化的查准率呈上升趋势,这表明用户模型文件中该领域的兴趣度在不断上升,学习算法能动态地捕捉到该过程,能随着学习的进行实时地更新用户模型。之后,随着数理化类文献学习量的减少及工业技术类文献的追加学习,前者查准率呈下降趋势,后者上升。这说明,如果用户的兴趣发生了转移,系统中体现在追加学习其他类别的文献、原类别的文献在结果中所占的比例会下降。这表明学习算法能够随着用户兴趣的转移合理地“遗忘”掉用户过去的爱好,而积累用户的新近兴趣。
5 结 论
本系统采用用户的浏览、定制和搜索行为结合被操作的信息作为建模信息来源,使用一种改进的基于向量空间模型的双重向量表示法来表达用户特征,并采用兴趣衰减、兴趣学习与滑动窗口算法相结合的方式对用户模型进行更新。最后,在数字图书馆个性化搜索引擎系统中实现,并通过两组实验,即与普通向量空间用户模型的对比实验和用户兴趣漂移时的跟踪学习,实验证明该方法能够比较准确地描述读者兴趣,通过用户模型优化搜索结果,有一定的使用价值。
参考文献
[1] KANG Haiyan, LI Chen. Research and design on personalized DL based on J2EE [C]// 2008 IEEE Pacific?Asia Workshop on Computational Intelligence and Industrial Application. Wuhan, China: IEEE, 2008: 527?531.
[2] ZHU Zhengyu, XU Jingqiu, REN Xiang, et al. Query expansion based on a personalized Web search model [C]// Procee?dings of 2007 3rd IEEE International Conference on Semantics, Knowledge and Grid. [S.l.]: IEEE, 2007: 128?133.
[3] 胡燕,吴虎子,钟珞.中文文本分类中基于词性的特征提取方法研究[J].武汉理工大学学报,2007,29(4):132?135.
[4] 屈军,林旭.文本分类中特征提取方法的比较与分析[J].现代计算机,2007(4):10?13.
[5] 林霜梅,汪更生,陈弈秋.个性化推荐系统中的用户建模及特征选择[J].计算机工程,2007,33(17):196?199.
[6] 张莉.基于Web数据挖掘的个性化信息智能Agent挖掘系统模型[J].科技广场,2006(8):53?55.
猜你喜欢
河南图书馆学刊(2016年12期)2017-01-09
河南图书馆学刊(2016年12期)2017-01-09
散文百家·下旬刊(2016年11期)2016-12-28
中国管理信息化(2016年21期)2016-12-27
青春岁月(2016年22期)2016-12-23
医学信息(2016年29期)2016-11-28
资治文摘(2016年7期)2016-11-23
电脑知识与技术(2016年24期)2016-11-14
企业导报(2016年12期)2016-06-17
