
一种改进的模糊聚类算法研究
2016-07-04 06:20郭文卓
企业技术开发·中旬刊 2016年1期
关键词:聚类分析
郭文卓
摘 要:针对模糊C-均值聚类算法不能很好对非椭球形分布,或结构形状不对称分布的数据进行聚类的问题,文章提出了一种基于点密度的模糊C-均值聚类算法PD-FCM,该算法利用数据的点密度能够反映其对不同数据密度分类的符合程度的这一特性,构造了修正参数来改进基于欧几里德距离度量方式,从实现对FCM算法的优化。在人造数据集和知名数据集上的实验结果该算法在准确率和隶属度的准确s性方面优于模糊C-均值聚类算法。
关键词:聚类分析;模糊聚类;点密度;隶属度
中图分类号:TP311 文献标识码:A 文章编号:1006-8937(2016)02-0055-03
1 概 述
作为一种无监督的学习方法,聚类是根据数据集中样本之间的相似度将数据集划分为若干个簇的过程,在图像处理、生物信息学、目标识别、医学诊断等领域有着极其广泛的应用[1,2,3]。按照样本的隶属度划分,可以将聚类方法分为硬聚类和模糊聚類。硬聚类将样本属于某一簇的隶属度设为0或1,其中取值为1表示该样本完全属于某一个簇,反之则完全不属于,即样本的类别是分明的。然而,在现实生活中,很多事物的属性带有模糊性,因此模糊聚类将每个样本对各个簇的隶属度扩展到区间[0,1]上来表示模糊性,对于簇彼此之中有噪声和交集数据的数据集,模糊聚类的结果在一定程度上要比硬聚类方法更加科学[4],可以满足广泛的应用需求。
Dunn对硬C-均值算法HCM进行了坚实的分析后,提出了新的模糊划分概念,采用了Ruspini定义的集合,用目标函数的方式表达出硬C-均值算法,且可以应用到模糊性的环境,得到了更简单和易懂的模糊C-均值聚类算法FCM[5]。这种类聚算法可以依据隶属度而知道每个数据点隶属哪个聚类的聚类算法。Bezdek为硬C均值聚类(HCM)方法改进提出了这种方法。随后,Bezdek对算法持续改进,且证明了算法的收敛性[6]。Bezdek的贡献为聚类问题提供了一个很实际且有效的办法,为未来模糊集理论的发展奠定了基础。
在聚类算法中用于度量样本相似性或相异性的距离函数对于聚类结果有着重要的影响。经典模糊C-均值算法使用Euclid distance度量样本的相似度,优点是简单运算。缺点是对簇的大小/形状,算法初始值都比较敏感,如在某些特定情况下,不能很好的划分,Euclid distance方式也不能划分密度接近的簇。通常,改变这一距离度量方式[7,8]可以部分的控制这些因素的影响。本文沿袭了这一思路,提出了改进的基于点密度的模糊C均值聚类算法PD-FCM,即根据点密度信息生成一个修正参数来弥补Euclid distance的缺陷,形成样本与聚类中心的距离矩阵,从实现对FCM算法的优化。
2 PD-FCM算法
给定由n个样本组成的数据集X={x1,x2,...,xn},xi∈Rs,以及簇个数k。模糊聚类的基本思想是将数据集X划分为k个簇s1,s2,...sk,使得公式(1)所示的目标函数最小。
Euclid distance方法计算样本和样本的相似性,由于简单运算比较,不能处理形状不对称或者不是椭球形的簇,且不能划分簇间数据密度不同的数据集。为此,引入点密度的概念,表示任意样本点的密度,用于对距离度量方式进行改进,其计算方法如公式(2):
3 实验部分
为了验证算法的有效性,将本文提出的PD-FCM与经典的模糊C-均值算法FCM进行对比分析,实验中采用了两种来源的数据集,一类是人造数据集,另一类是从UCI中选取的知名的数据集。所有实验程序采用JDK 1.6版本开发,关键的参数模糊系数m设为2.0。每次实验重复10次,实验结果取平均值,评价标准采用准确率precision:
3.1 人造数据集
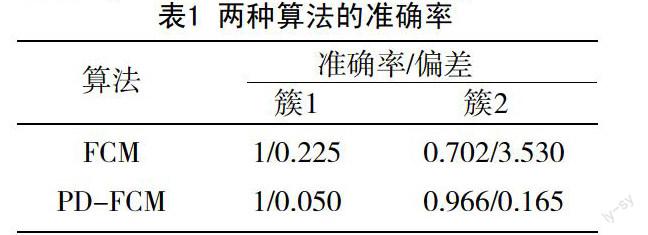
采用随机产生数据的方式构造了1组人造数据集,该数据集包含两个簇,两个簇中的数据点的分布均采用二维正态分布,样本个数均为100个,其中第1个簇中样本点分布在坐标原点为圆心,半径为1的圆内,而第2个簇中样本点分布在以(5.5,0)为圆心,半径为5的圆内。显然,第1簇中的数据密度大于第2组的。实验结果,如图1所示。
从图中可以直观地看出PD-FCM更为准确地将人造数据集划分为了两个簇。进一步地,计算得到的准确率如表1所示,同样验证了PD-FCM对于FCM而言在针对第2簇的分类准确率上有较大优势,这是因为参考密度来更新距离的密度因子,因此提高FCM算法的准确性。两种算法的准确率,见表1。
3.2 UCI数据集
从UCI数据集中选择了两组用于聚类任务的知名数据集,Wine和IRIS数据集,对PD-FCM和FCM算法进行对比实验。IRIS数据集一共有150个样本,维数为4,类别为3类,每类均有50个样本。
第一类为Iris Setosa,该类别的样本与其它类别的样本的距离较大,而第2类Iris Versicolour和第3类Iris Virginica对应的数据相距则较为接近,而且有一部分数据是交叉或者重叠的。
WINE数据集有178个样本,维数为13,类别也为3类,三类样本数分别是59、71和48,该数据集存在高维稀疏的特性。
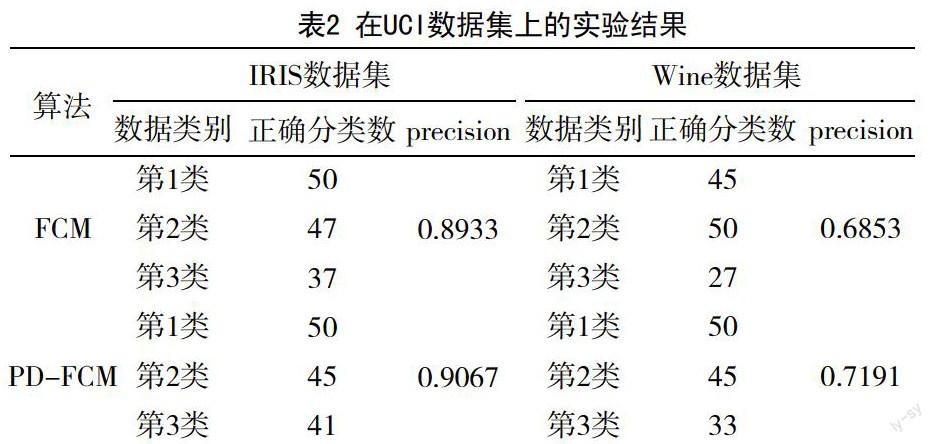
首先对算法的有效性进行分析。在这两组数据集上的实验结果,见表2。
从表中可以看出,对于IRIS数据集,由于第1类数据距离其他两组数据较远,所以2种算法均能很好地将其分离出来,对于数据之间存在融合的第2类和第3类数据,PD-FCM算法表现出更高的准确性,较FCM算法提高了1%。但是,第2类的分类正确数有所下降。
对于Wine数据集而言,由于数据集本身具有高维稀疏的特性,这导致两种算法的准确率都比较低;但PD-FCM算法由于采用了密度调节因子,所以准确率提升了4.9%,同样地对第2类的分类结果也有影响,正确个数也小幅下降,但并未影响算法的准确率。
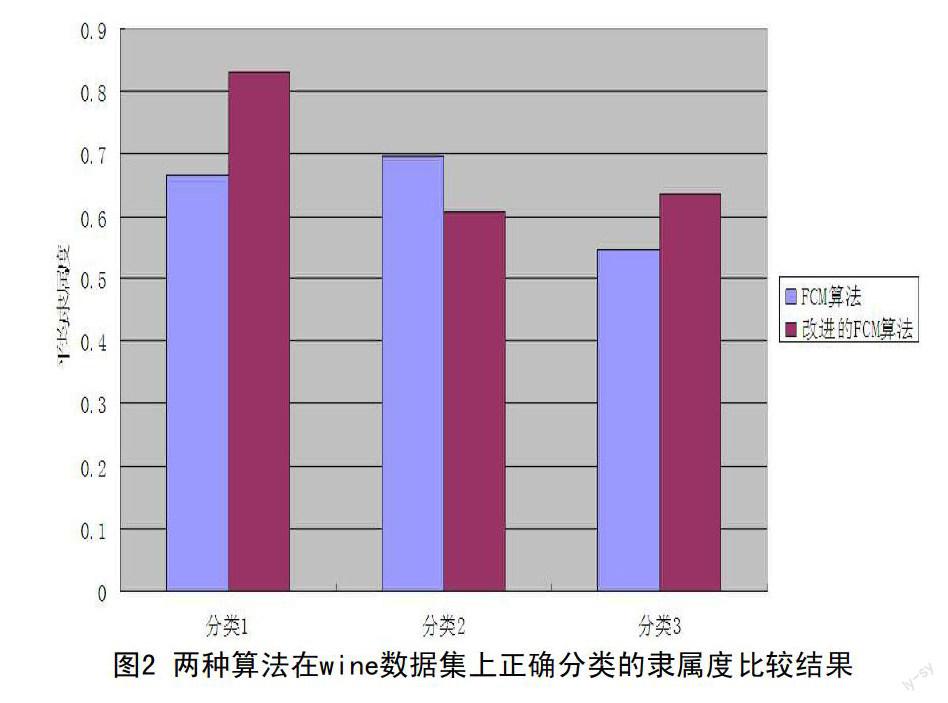
隸属度的准确性也是评价模糊聚类算法的有效性的一个重要度量。下面以wine数据集为例,对两种算法的最终隶属度进行分析。首先给出两种算法正确分类样本的隶属度分布图,如图2所示。
图上的隶属度越接近于1,则代表该算法的隶属度的准确性越高。从图中可以看出,在PD-FCM算法在第1类和第3类数据上获得的隶属度均较FCM算法有所提高,而第2类的隶属度则有所下降,这就表明采用了密度信息的PD-FCM算法更加适用于模糊信息系统的生成。
4 结 语
相似性度量方法是聚类算法的重要组成部分,对于聚类结果有着重要的影响。本文为了克服欧氏距离度量方法对于簇的形状、大小都比较敏感的问题,从优化相似性度量方法着手,提出了改进的基于点密度的模糊C均值聚类算法PD-FCM,该算法将样本点的密度信息融入到距离度量方法和优化目标函数中,能否适应多种不同的簇形状和大小,实验结果也表明改进后的算法在准确率和隶属度的准确性方面优于模糊C-均值聚类算法。
实验结果也发现PD-FCM并不是总是优于FCM算法,因此未来的工作可以考虑如何集成多种类型的模糊聚类算法,充分利用每种算法的优势进一步提高算法的分类准确性。
参考文献:
[1] Sajith, A. G., & Hariharan, S. Spatial fuzzy C-means clustering base
ed segmentation on CT images[A].The 2nd IEEE International Confer
ence on Electronics and Communication Systems (ICECS)[C].2015.
[2] 陈科尹,邹湘军,熊俊涛,等.基于视觉显著性改进的水果图像模糊聚类 分割算法[J].农业工程学报,2013,(6).
[3] 李波,邱红艳.基于双层模糊聚类的多车场车辆路径遗传算法[J].计算 机工程与应用,2014,(5).
[4] Velmurugan, T. Performance based analysis between k-Means and F
uzzy C-Means clustering algorithms for connection oriented telecomm
unication data.[J].Applied Soft Computing 2014,(19).
[5] Bezdek,J.C.,Ehrlich,R.,Full,W.FCM:The fuzzyc-mean sclustering algorit
hm[J].Computers & Geosciences,1984,(2).
[6] Pal, Nikhil R., and James C. Bezdek. On cluster validity for the fuz
zy c-means model[J].IEEE Transactions on Fuzzy Systems,1995,(3).
[7] WuKL, YangMS. Alternative c-means clustering algoritllms.[J] Pattem
Recognition.2002,(10).
[8] Menard M, Courboulay V, Dardignac P. Possibilistic and probabililist
ic fuzzy clustering: Unification within the framework of the non-exte
nsive thermostatistics.[J]Pattern Recognition.2003,(6).
猜你喜欢
软件导刊(2016年11期)2016-12-22
科技创新导报(2016年21期)2016-12-17
对外经贸(2016年8期)2016-12-13
数学学习与研究(2016年19期)2016-11-22
商场现代化(2016年26期)2016-11-21
新媒体研究(2016年19期)2016-11-18
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
