
一种基于MFCC和IPA转换的关键音检索系统研究
2016-07-04 06:20李志伟
企业技术开发·中旬刊 2016年1期
李志伟

摘 要:海量视音频信息检索一直是人们研究与应用的热点。文章介绍的一种关键音检索系统,使用MFCC算法提取语音特征,调用Viterbi解码算法和国际音标模式库,解码得出该音频文件对应的国际音标序列。并利用距离编辑算法计算得出关键词在音频文件各个时间点处的置信度,获取检索模块输出的检索结果。本系统具有与待检测语言无关的特点,对普通话和英语的检索准确率不低于90%,且支持敏感度调节和多词汇并行检测的优点。
关键词:语音检索;MFCC算法;IPA
中图分类号:TN912.34 文献标识码:A 文章编号:1006-8937(2016)02-0048-02
1 概 述
面对海量的视音频信息流,依靠传统的人工处理技术费时费力,急需要采用自动化的监控和高效的信息检索技术。而传统的视音频检索技术主要依赖于人工标注,所能搜索的范围也受限于标注信息,这远不能满足快速增长的海量数据处理的需求,不能提供更准确的基于内容的检索。与词汇无关的关键词检测方法(Key Word Spotting,KWS),是在一段连续语音中找出给定的目标词的发音所出现的准确时间段,并给出每个候选段的置信度。其缺点在于无法处理集外词,对于比较自然随意的语音(Spontaneous Speech)和在噪音的环境下,识别率会下降。
国际音标,又称国际語音字母(International Phonetic Alphabet,IPA),是用于为全世界所有语言注音的符号系统。它根据一符一音的原则把发音规则表示成相应符号。通过最小的音素发音方式,就可以对任何语音进行标注。
对于常用的语言,如汉语可以使用44个音标标注,英语50个标注。
本文介绍的语音检索系统就是利用国际音标的一符一音的原则,对于最小的发音单元“音素”进行计算机建模。该系统基于MFCC算法,通过转换预料库成对应的国际音标,经Viterbi解码和距离编辑算法检索出结果,系统具备与词汇无关和多关键词检测的特点。
下面分别从MFCC算法、系统设计及其优缺点三个方面进行介绍。
2 MFCC算法
2.1 MFCC算法综述
目前最有效的提取语音特征的方法是MFCC或线性预测倒谱系数(LPCC)法。
其中,MFCC特征提取方法是根据人耳对不同频率的声音信号具有不同的感知能力,且在频域上声音信号呈现非线性关系而提出。
该方法首先对语音信号预加重、分帧、加窗处理,然后对每帧进行离散傅里叶变换,得到在频率域上的能量分布。
根据人耳特性设置一组三角滤波器组,计算每个滤波器输出的能量的对数,再经过离散余弦变换,得到一组系数即MFCC。
2.2 具体步骤
具体步骤如下:
①原始语音信号经过预加重、分帧、加窗,用FFT转化为频域信号x(m),并计算其短时能量谱P(f)。将P(f)转化为美尔坐标上的频率P(fmel)。
②在美尔频域内将三角带通滤波器加于Mel坐标,得到滤波器组Hm(k),0≤m≤M0,M0为滤波器个数.每个滤波器的中心频率为f(m),每个带通滤波器的传递参数为:
MFCC充分考虑了人的听觉特性,没有任何前提假设,具有良好的识别性能和抗噪能力。
3 系统设计
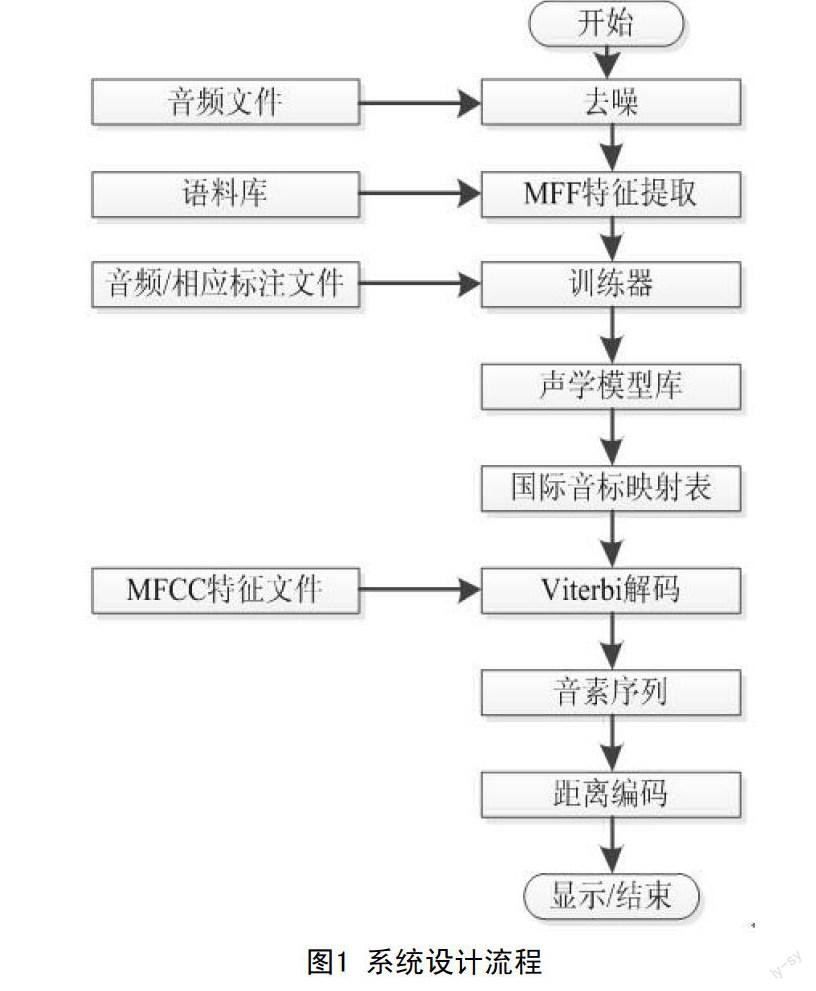
语音检索系统的第一步,即是对获取的音频文件进行去噪处理。
其次,提取音频文件的MFCC特征,并通过对不同语言的语料库进行训练,完善国际音标模式库,也即国际音标的隐马尔科夫模型。
通过系统内部“汉子—拼音—国际音标”的映射表将待检索的关键词转化为国际音标。调用Viterbi解码算法和国际音标模式库,解码得出该音频文件对应的国际音标序列。
最后,利用距离编辑算法计算得出关键词在音频文件各个时间点处的置信度,获取检索模块输出的检索结果,然后根据用户对置信度区间的调节而动态的显示。
系统设计流程,如图1所示。
4 系统优缺点
建设国际音标(IPA)的语音模式库是音标检索系统的重要一环。对于该检索系统来讲,只要语言(或方言)能够用国际音标进行标注,均可以检索。具体优缺点如下。
4.1 具有语言无关性
将音频文件转换为国际音标标注,具有语言无关性的优点,支持任何一种语言的检索。不需要知道语言的具体含义,只需要获得关键词的发音,即可用国际音标进行标注,对音频文件快速检索。
4.2 准确率高,误报率低
普通话和英语检索准确率应达到90%以上,误报率低于10%。30 min音频,搜索5个音素,耗时<1s。1h音频,搜索5个音素,耗时约3~5 s。由于系统采用Viterbi算法对音频MFCC特征文件进行解码,参与解码的冗余音素较多,对系统的检索速度和精度有一定影响。
4.3 支持敏感度调节
关键词的音素序列在对本地音频解码得到的音素序列上进行检索,通过距离编辑算法计算得出每个音素对应时间点处的置信度,从而在音频的各个时间点处贴上了与关键词的相似值(也称置信度)的标签,从而用户可以任意筛选自己需要得到的置信区间的音频时间点,具有敏感度调节的功能。
5 结 语
本文介绍了一种基于MFCC特征提取的关键音标检索系统,该系统对提取的特征加以训练,并加入国际音标映射表,经Viterbi解码,输出音素序列,再经距离编辑算法得出检索结果。的音标转换的关键音检索系统,采用了基于MFCC算法。它具备与词汇无关的关键词检测能力,同时又能够提供较快速的搜索速度和准确的检测结果。支持多关键字并行检索和敏感度调节的能力,对语音检索系统的研究具有一定的理论参考意义。
参考文献:
[1] 王明合,张二华,唐振民,等.基于Fisher线性判别分析的语音信号端点 检测方法[J].电子与信息学报,2015,(6).
[2] 李伟,吴及,吕萍.面向海量数据的语音敏感信息检测系统[J].信息工程 大学学报,2010,(5).
[3] 牛滨,孔令志,罗森林,等.基于MFCC和GMM的个性音乐推荐模型[J].北 京理工大学学报,2009,(4).
猜你喜欢
新教育时代·教师版(2019年16期)2019-06-17
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
现代交际(2016年24期)2017-04-14
传播与版权(2017年11期)2017-03-28
网络安全技术与应用(2017年11期)2017-03-10
文理导航(2015年33期)2015-11-19
电脑爱好者(2015年5期)2015-09-10
