
电话交谈语音识别中基于LSTM-DNN语言模型的重评估方法研究
2016-07-04 10:29左玲云张晴晴颜永红
重庆邮电大学学报(自然科学版) 2016年2期
关键词:语音识别
左玲云,张晴晴,黎 塔,梁 宏,颜永红
(中国科学院 声学研究所 语言声学与内容理解重点实验室,北京 100190)
电话交谈语音识别中基于LSTM-DNN语言模型的重评估方法研究
左玲云,张晴晴,黎塔,梁宏,颜永红
(中国科学院 声学研究所 语言声学与内容理解重点实验室,北京 100190)
摘要:近年来,神经网络语言模型的研究越来越受到学术界的广泛关注。基于长短期记忆(long short-term memory,LSTM)结构的深度神经网络(LSTM-deep neural network,LSTM-DNN) 语言模型成为当前的研究热点。在电话交谈语音识别系统中,语料本身具有一定的上下文相关性,而传统的语言模型对历史信息记忆能力有限,无法充分学习语料的相关性。针对这一问题,基于LSTM-DNN语言模型在充分学习电话交谈语料相关性的基础上,将其应用于语音识别系统的重评估过程,并将这一方法与基于高元语言模型、前向神经网络(feed forward neural network,FFNN)以及递归神经网络(recurrent neural network,RNN)语言模型的重评估方法进行对比。实验结果表明,LSTM-DNN语言模型在重评估方法中具有最优性能,与一遍解码结果相比,在中文测试集上字错误率平均下降4.1%。
关键词:长短期记忆;神经网络语言模型;语音识别;重评估
0前言
语言模型是用数学方式描述语言学中词与词之间的约束现象,在自然语言处理技术中具有重要作用,广泛应用于语音识别、语音合成、机器翻译以及手写体识别等领域。N-Gram语言模型是一种简单有效的统计语言模型,因其简单、易用、高效等特点,在过去几十年实际应用中一直发挥重要作用[1]。目前,用于构建N-Gram语言模型的主要工具有SRILM[2],Kenlm[3-4]以及Kaldi等。尽管如此,N-Gram语言模型仍存在一些问题,比如,随着N元文法语言模型阶数的增长,需要估计的参数量会急剧增加并存在数据稀疏问题,无法有效利用长距离的上下文信息,而且无法捕捉词与词之间的相似性等。
针对这些问题,有学者提出高级语言模型,例如神经网络语言模型[5-6]。相比传统的N元文法语言模型,神经网络语言模型能够自动学习词语的连续空间表达,把词法和词义相近的词在连续空间上聚集在一起,可以在很大程度上缓解数据稀疏问题。最典型的神经网络语言模型是Bengio的前向神经网络语言模型(feed forward neutral network language model,FFNNLM)[7-8],Mikolov的递归神经网络语言模型(recurrent neutral network language model,RNNLM)[9-11]以及Sundermeyer提出的基于长短期记忆 (long short-term memory,LSTM)[12]结构的深度神经网络语言模型(LSTM-deep neural network language model,LSTM -DNNLM)。前向神经网络语言模型虽然可以对词进行连续空间表达,对历史信息起到一定的聚类作用,但是只能考虑有限个历史词信息;递归神经网络语言模型理论上可以考虑无限个历史词信息,但是随着新词的不断引入,这种神经网络语言模型存在着记忆衰退严重的问题[13];而LSTM-DNN语言模型在隐藏层引入了LSTM结构单元,这种结构单元包含一个将信息储存较久的存储单元,这个记忆单元被一些特殊的门限所保护,可以选择性记忆网络误差回传的参数,对历史信息起到良好的记忆功能[14]。神经网络语言模型因其过高的计算复杂度很少直接应用在解码阶段,它们通常应用在搜索空间较小的重评估阶段。
语言模型重评估通过用复杂的模型对一遍解码的N候选列表或者词图进行重新打分,然后根据新的分数进行排序,最终输出识别结果。在电话交谈语音识别系统中,用神经网络语言模型进行重评估成为当前研究的热点。然而,电话交谈风格的语料具有一定的上下文相关性,传统的神经网络语言模型对历史信息的记忆存在一定的局限性。为了解决这一问题,本文提出了将LSTM-DNN语言模型应用在电话交谈语音识别系统中。这种语言模型因其特殊的结构单元可以选择性记忆误差回传的参数,对历史信息起到良好的记忆功能。此外,本文将一遍解码的识别结果引入到电话交谈语音识别的LSTM-DNN语言模型重评估中,进一步提升了LSTM-DNN语言模型重评估的性能。
1语音识别系统基本框架
自动语音识别系统的主要任务是把给定的语音转换成一系列的词串。目前,应用最广泛的语音识别系统是基于统计建模的。语音识别系统通常假设输入语音的特征序列为O=(o1,o2,…,oT),与该语音特征对应的最可能出现的词序列为W=(w1,w2,…,wK)。语音识别的过程即给出语音特征,求最大后验概率的形式


(1)
(1)式中:P(O|W)由声学模型决定;P(W)由语言模型决定。
典型的语音识别系统的基本框架主要包含5个模块:特征提取、声学模型、语言模型、发音词典以及解码(一遍解码、重评估)[15]。由于声学信号是动态时变的,性能非常不稳定,声学模型只能识别语音信号中音素、音节或者词的相似程度,但不能捕捉到词与词之间的相关性[15]。语言模型则可以利用不同的上下文信息或者其他语言学信息来预测每一个词可能发生的概率。这样便可以在一定程度上解决声学模型混淆度的问题。因此,语言模型在语音识别系统中起着重要的作用。本文所用的语音识别系统基本框架如图1所示。针对电话交谈语料的上下文相关的特性,在进行重评估时,本文提出了一种引入历史句子信息的神经网络语言模型重评估方法:用一遍解码的结果作为历史句子信息,对选取的M个最优候选结果用基于LSTM结构的神经网络语言模型进行重评估;并将用高元文法语言模型进行重评估的结果与用LSTM神经网络语言模型重评估的结果进行融合,选出最优结果,作为待识别的语音信息的最终识别结果。

图1 语音识别系统基本框架Fig.1 Basic framework of speech recognition system
2神经网络语言模型
N-Gram语言模型将词看作离散的符号,容易出现数据稀疏问题。解决该问题的一种方案是采用基于神经网络语言模型的连续空间建模方法。该方法首先基于分布式假设条件,通过投影矩阵将离散的词映射到连续空间,形成相应的词矢量(wordembedding)特征,这种词矢量可以一定程度上刻画词与词之间的距离,并可以把词法或语义相近的词聚集在一起。以此为基础,将分布式的上下文矢量信息输入到神经网络,并在输出层预测下一个词出现的概率。这种连续空间建模方法是离散空间建模方法的进一步扩展,和离散空间建模方法相比,基于神经网络语言模型的连续空间建模方法可以在性能上取得更好的效果[15]。
2.1前向神经网络语言模型(FFNNLM)
前向神经网络语言模型(feedforwardneutralnetworklanguagemodel,FFNNLM)基本结构[7]如图2所示,由4部分组成:输入层、投影层、隐藏层和输出层。词典中的每一个词首先被表示为一个与词典大小维数相等的稀疏向量,该向量仅根据词的位置有一维为1,其余均为0。随后,将当前需要被预测词的前N-1个词的稀疏向量相连接作为网络的输入,即代表词的历史信息。历史信息接下来通过一个投影矩阵被线性映射到一个连续的空间,形成相应的词矢量特征,这一过程在某种程度上可以自动获得词义的等价性聚类。最后,投影层的词矢量在隐藏层进行非线性变换,并在输出层使用softmax激活函数对输出值进行归一化。
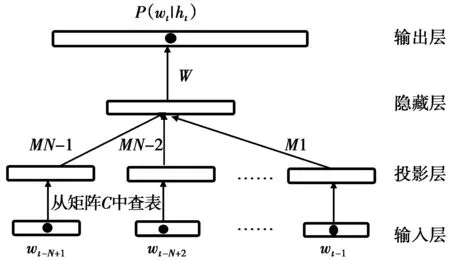
图2 前向神经网络语言模型基本结构图Fig.2 Basic structure of feed forward neutral network language model
前向神经网络语言模型虽然能够自动学习词语的连续空间表达,使得词法和词义相近的词在连续空间上聚集在一起,但是只能考虑有限个历史词信息。针对这一问题,有学者提出了递归神经网络语言模型。
2.2递归神经网络语言模型(RNNLM)

图3 递归神经网络语言模型基本结构图Fig.3 Bsic structure of recurrent neutral network language model
递归神经网络语言模型(recurrentneutralnetworklanguagemodel,RNNLM)的基本结构[9]如图3所示,主要包含输入层、隐藏层及输出层3部分。各部分的数学表达式为
输入层:
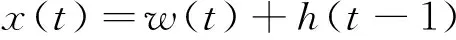
(2)
隐藏层:

(3)
输出层:
(4)
(3),(4)式中,f(z)为sigmoid激活函数。
(5)
g(z)为概率规整函数
(6)
由上述公式可以看出递归神经网络语言模型输入层不仅包含了当前输入,而且加入了当前词的全历史词信息。隐藏层采用非线性变换sigmoid函数。输出节点为给定词历史,下一个词出现的概率。递归神经网络语言模型和前向神经网络语言模型最本质的区别在于不仅在输入空间上操作,而且还在中间状态空间上操作,即在隐藏层引入了自循环,理论上可以利用所有的历史词信息。但是在实际应用中随着新词语的不断引入,历史信息会被稀释,因此存在着严重的记忆衰退问题。针对这一问题,又有学者提出了基于LSTM结构的神经网络语言模型。
2.3基于LSTM结构的深度神经网络语言模型(LSTM-DNNLM)
基于LSTM结构的神经网络语言模型和递归神经网络语言模型原理一致,最本质的区别在于隐藏层引入了LSTM结构单元。这种神经网络语言模型的基本架构[16-17]如图4所示;LSTM基本结构单元[16-17]如图5所示。

图4 LSTM-DNN语言模型基本结构图Fig.4 Basic structure of neutral network language model based on LSTM unit
LSTM结构单元和标准的神经网络结构单元最主要的区别在于引入了3个门结构:输入门、输出门和忘记门,使输入和输出之间不再只是进行简单的线性变换。3个门的取值均和当前的输入词信息、上一个隐藏层信息和上一个中心结点的取值有关。具体计算为
(7)
(8)
(9)
(10)
ht=ottanh(ct)
(11)
(7)—(11)式中,σ(x)为logisticsigmoid函数,分别代表输入门、忘记门、输出门和中心激励。LSTM结构单元包含一个尝试,将信息储存到较久的存储单元,这个记忆单元被一些特殊的门所保护,可以选择性记忆网络误差回传的参数,解决了递归神经网络语言模型记忆衰退严重的问题。

图5 LSTM基本结构单元Fig.5 Basic structure of LSTM unit
由于神经网络语言模型计算复杂度较高,一般不用于语音识别系统的一遍解码中,而是用于重评估阶段[18]。为了验证引入LSTM结构的神经网络语言模型的有效性,本文提出了引入历史句子信息的LSTM神经网络语言模型重评估方法,并与传统的语言模型重评估方法进行了系统地对比。具体实施方案如下(如图1所示)
步骤1输入待识别的语音信息,并对输入的待识别的语音信息进行预处理;
步骤2用N元文法语言模型对预处理后的信息进行一遍解码,然后从中选取M个最优的候选结果;
步骤3在获得的M个最优的候选结果中引入一遍解码的识别结果作为历史句子信息;
步骤4用高元文法语言模型对选取的M个最优的候选结果进行重评估;
步骤5用基于长短时记忆网络结构的神经网络训练语言模型对引入历史句子信息的M个最优的候选结果进行重评估;
其中,针对电话交谈语料的上下文相关的特性,在进行重评估时,用一遍解码的结果作为历史句子信息,对选取的M个最优候选结果用LSTM神经网络语言模型进行重评估;
步骤6将用高元文法语言模型进行重评估的结果与用LSTM神经网络语言模型重评估的结果进行融合,选出最优结果,作为待识别的语音信息的最终识别结果。
3实验设计及分析
3.1实验设计
本文在面向电话交谈的语音识别任务上,评估各类神经网络语言模型重评估方法的有效性。测试环境采用实验室自主开发的大词汇连续语音识别系统,该系统是采用基于紧致状态网络的单遍解码器,其他参数详见参考文献[19]。我们采用的训练数据包括语言数据联盟(linguistic data consortium,LDC)提供的汉语文本语料:Call-Home、Call-Friend以及Call-HKUST[20];实验室采集的自然口语对话数据,统称为CTS(conversational telephone speech)语料。另一部分训练数据为网上自行下载的文本语料,统称为通用语料。实验室自采的电话信道数据(shiwang1)作为开发集,2005年国家863高科技计划提供的数据集(86305)[21]以及香港大学2004年采集的电话自然口语对话的部分数据(LDC_Test)(约1小时)作为测试集[20]。实验中分别在这2个测试集上验证LSTM-DNN语言模型重评估方法的有效性。具体数据分布如表1所示。

表1 实验数据分布
3.2神经网络语言模型训练环境
本实验中用rwthlm[17]训练各类神经网络语言模型:前向神经网络语言模型、递归神经网络语言模型以及基于LSTM结构的神经网络语言模型。神经网络语言模型迭代次数均为15。
3.3重评估环境
本文中所用的重评估环境是自己搭建的n-best重评估环境。实验中均采用一遍解码得到的10个最优候选结果进行重评估。经验证,N元文法语言模型的分数和神经网络语言模型的分数具有互补性,将二者融合可以降低语音识别的错误率[15]。所以本实验采用4元语言模型和神经网络语言模型进行插值重评估。通过在开发集上进行插值系数调优,重评估时4元语言模型和神经网络语言模型的插值比例均为0.5。
3.4实验结果及分析
3.4.1基于高元语言模型的重评估实验
电话交谈风格的语料本身具有一定的上下文相关性,所以训练模型时考虑历史词信息的个数会影响到识别的性能。N元文法语言模型虽简单、有效,但随着阶数的增长,需要估计的参数数目急剧增加,会严重影响解码速度。因此,高元文法语言模型很少直接应用在第一遍解码中,而是用在搜索空间较小的重评估阶段。
为了验证高元文法语言模型重评估方法的有效性,我们进行了相关实验,首先,用CTS语料和通用语料通过SRILM工具在开发集上进行插值系数调优,把插值后的3元文法语言模型作为base模型进行一遍解码。然后,用相同方法得到的4元文法语言模型对一遍解码结果中抽取的10best进行重评估。实验结果可参见表2。实验表明:针对电话交谈语料的上下文关联性,用考虑历史词信息更多的高元语言模型进行重评估,其性能有一定提升,但不明显,这是因为高元文法语言模型考虑的历史词信息数有限。为达到良好的重评估效果,下面将尝试使用神经网络语言模型进行重评估。
3.4.2基于各类神经网络语言模型的重评估实验
本实验采用的是各类神经网络语言模型和4-Gram语言模型插值对10best进行重评估。具体重评估对比结果如表2所示。
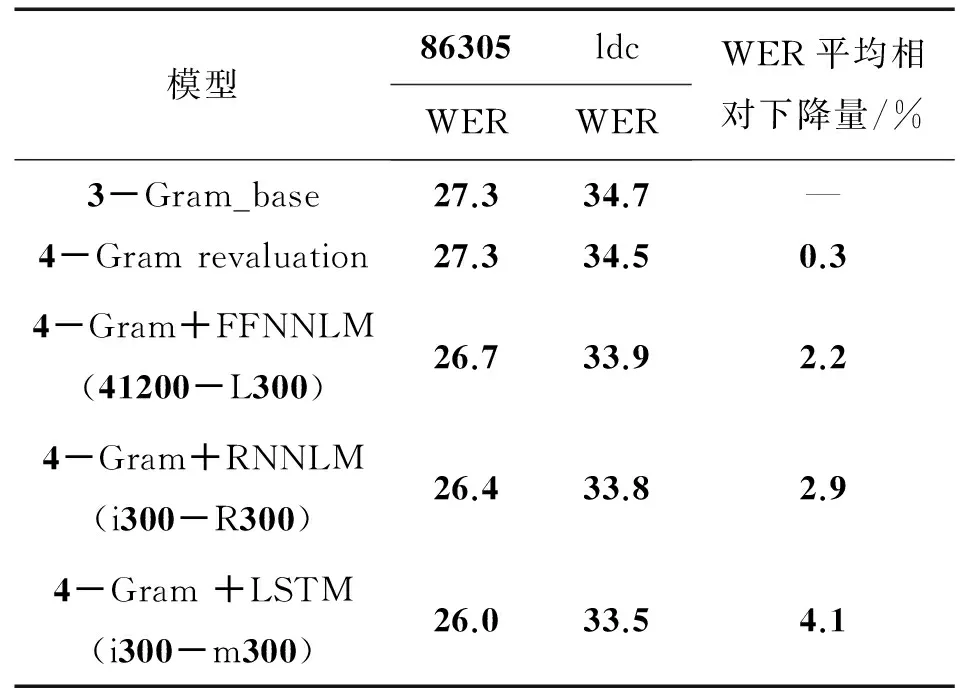
表2 基于不同种类语言模型的重评估实验结果
在表2中,FFNNLM(41200-L300)表示前向神经网络语言模型考虑了一句话中前4个词的历史信息,投影层和隐藏层均包含300个结构单元;RNNLM(i300-R300)包含投影层和隐藏层的递归神经网络语言模型,投影层和隐藏层均包含300个结构单元;LSTM(i300-m300)表示引入LSTM结构的神经网络语言模型,投影层包含300个结构单元,隐藏层包含300个LSTM结构单元;WER表示字错误率。实验结果表明:在投影层和隐藏层结构单元数相同的情况下,用前向神经网络语言模型、递归神经网络语言模型以及基于LSTM结构的神经网络语言模型进行重评估,性能有一致性的提升。
FFNNLM与4-Gram进行插值重评估,并与基线进行对比,重评估性能有一定幅度提升。因为,FFNNLM可以把词映射到连续空间,对词义相近的词起到聚类作用,比N元文法语言模型学习能力更强。而RNNLM相对于FFNNLM进行重评估,性能又有进一步的提升。因为FFNNLM只能考虑有限个历史词信息,RNNLM理论上可以考虑所有历史词信息。然而基于LSTM结构的神经网络语言模型相比于RNNLM重评估性能又有一定幅度的提升。这是因为随着新词的不断引入,RNNLM存在记忆衰退问题,而LSTM结构单元因包含一个尝试将信息储存较久的存储单元,可以对历史句子信息起到良好的记忆功能。
综上所述,在电话交谈语音识别任务中,基于LSTM结构的神经网络语言模型重评估方法具有最优性能。实验中,用投影层和隐藏层均为300个结构单元的LSTM模型和4-Gram模型进行插值重评估,WER平均相对下降4.1%。
3.4.3影响LSTM-DNN语言模型重评估的主要参数实验
从上述实验分析可以看出,基于LSTM结构的神经网络语言模型因其良好的记忆功能在面向电话交谈的语音识别任务中重评估性能最优。下面分析主要参数对LSTM-DNN语言模型重评估性能的影响。
1)历史句子信息数对重评估性能的影响
本实验中,所用的模型均为投影层、隐藏层单元数均为300的LSTM神经网络模型。在各个测试集上的重评估性能进行对比,具体实验结果如表3所示。
在表3中,LSTM_History_n表示重评估时考虑一遍解码中的前n句话作为历史句子信息。实验结果表明:引入一遍解码的识别结果作为重评估的历史句子信息,重评估性能虽然没有大幅度提升,但都具有一致性的提升。

表3 不同历史信息句子数对重评估性能的影响
电话交谈风格的语料中,一句话发生的概率与它前面几句话有着一定的相关性,在进行重评估时,需要考虑同一段对话的历史信息,进而展开重评估更显合理。但是电话交谈的语料随着句子数的增加,两句话之间的关联性会变弱,或者基本没有关联性,所以没有必要考虑所有的历史句子信息。在本实验中,通过对比不同历史信息句子数对重评估性能的影响,我们认为在面向电话交谈语音识别任务中,将同一对话前5句话左右的信息作为历史信息,进行重评估性能更优。
2)结构单元数对重评估性能的影响
本实验分别用含有不同结构单元数的LSTM神经网络语言模型和4元语言模型进行插值重评估,对比了不同的结构单元数对模型性能的影响,具体实验结果如表4所示。

表4 不同的结构单元数对重评估性能的影响
实验结果表明,随着投影层和隐藏层结构单元数的增加,LSTM-DNN语言模型性能有一致性的提升,但到达一定数量之后模型的性能基本上没有改善。这是因为,隐层结构单元过少,会导致网络误差较大,自学习能力比较差;若隐层结构单元数过多,虽然可使网络的系统误差减小,但一方面使网络训练时间延长,另一方面,训练容易陷入局部极小点而得不到最优点,甚至会出现“过拟合”现象。所以,训练模型时在满足网络模型性能的前提下,应尽量选择较少的结构单元进行训练。
4结论
在面向电话交谈语音识别系统中,语料本身具有一定的上下文相关性,而LSTM-DNN语言模型因其特殊的结构可以对语料的相关性进行充分学习。本文基于LSTM-DNN语言模型,研究了面向电话交谈语音识别系统的重评估性能。通过搭建引入历史句子信息的神经网络语言模型实验环境,对比了不同神经网络语言模型的重评估性能。实验表明:基于LSTM结构的深度神经网络语言模型在电话交谈的语音识别任务中重评估性能最优。同时在经过各类主要参数调优后,用LSTM深度神经网络进行重评估,与一遍解码结果相比,字错误率平均相对下降4.1%。
参考文献:
[1]文娟.统计语言模型的研究与应用[D].北京:北京邮电大学,2009.
WEN Juan. Research and application of statistical language model[D]. Beijing: Beijing University of Posts and Telecommunications, 2009.
[2]STOLCKEA,SRILM. An extensible language modeling toolkit[C]//INTERSPEECH 2010, 7th International Conference on Spoken Language Processing. Denver Colorado: The International Speech Communication Association, 2002:901-904.
[3]HEAFIELD K,KENLM: Faster and smaller language model queries[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Portland: The Association for Computational Linguistics,2011: 187-197.
[4]HEAFIELDK, POUZYREVSKY I, CLARK J H, et al. Scalable Modified Kneser-Ney Language Model Estimation[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia Bulgaria: The Association for Computational Linguistics, 2013: 690-696.
[5]MIKOLOV T.Statistical language models based on neural networks[D].Prague:Brno University of Technology,2012.
[6]PAPPAS N, MEYER T. A Survey on Language Modeling using Neural Networks, No. EPFL-REPORT-192566 [R]. Martigny :Idiap, 2012.
[7]BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2003(13): 1137-1155.
[8]SCHWENK H. Continuous space language models[J]. Computer Speech & Language, 2007, 21(3): 492-518.
[9]MIKOLOV T, KARAFIáT M, BURGET L, et al. Recurrent neural network based language model[C]//INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association.MakuhariChiba:The International Speech Communication Association,2010: 1045-1048.
[10] MIKOLOV T, KOMBRINK S, DEORAS A, et al. RNNLM-Recurrent neural network language modeling toolkit[C]// Proceeding of the 2011 ASRU Workshop. Waikoloa, Hawaii: Institute of Electrical and Electronic Engineers,2011: 196-201.
[11] MIKOLOV T, KOMBRINK S, BURGET L, et al. Extensions of recurrent neural network language model[C]//ICASSP 2011,Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing. Prague Congress Center, Prague:Institute of Electrical and Electronic Engineers,2011: 5528-5531.
[12] HOCHREITER S,SCHMIDHUBER J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[13] BENGIO Y, SIMARD P, FRASCONI P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE transactions on neural networks,1994,5(2): 157-166.
[14] GRAVES A. Supervised sequence labelling with recurrent neural networks[M]. Heidelberg: Springer, 2012.
[15] 司玉景. 递归神经网络在电话语音识别系统中的研究与应用[D].北京: 中国科学院大学,2014.
SI Yujing. Research and application of recurrent neural network technology in telephone speech recognition system[D]. Beingjing: University of the Chinese Academy of Sciences, 2014.
[16] SUNDERMEYER M, SCHLüTER R, NEY H. LSTM Neural Networksfor Language Modeling[C]//INTERSPEECH 2012, 13th Annual Conference of the International Speech Communication Association.Portland, Oregon: The International Speech Communication Association, 2012:194-197.
[17] SUNDERMEYER M, SCHLüTER R, NEY H. rwthlm-The RWTH Aachen University Neural Network Language Modeling Toolkit[C]// INTERSPEECH 2014,15th Annual Conference of the International Speech Communication Association.Singapore:The International Speech Communication Association, 2014: 2093-2097.
[18] SUNDERMEYER M, NEY H, SCHLUTER R. From Feedforward to RecurrentLSTM Neural Networks for Language Modeling[J]. IEEE/ACM Transactions, 2015, 23(3): 517-529.
[19] HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv preprint arXiv, 2012, 1207.0580: 1-18.
[20] ZHANG Qingqing, PAN Jielin, YAN Yonghong.Tonal Articulatory Feature for Mandarin and its Application to Conversational LVCSR[C]//INTERSPEECH 2009, 10th Annual Conference of the International Speech Communication Association. Brighton, U.K: The International Speech Communication Association,2009: 3007-3010.
[21] 钱跃良, 林守勋, 刘群, 等. 2005 年度 863 计划中文信息处理与智能人机接口技术评测回顾[J]. 中文信息学报, 2006, 20(1): 1-6.
QIAN Yueliang,LIN Shouxun,LIU Qun,et al.A Review on 2005 HTRDP(863) Evaluation on Chinese Information Processing and Intelligent Human-Machine Interface[J].Chinese Journal of information,2006,20(1):1-6.
Revaluation based on LSTM-DNN language model in telephone conversation speech recognition
ZUO Lingyun, ZHANG Qingqing, LI Ta, LIANG Hong, YAN Yonghong
(Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustics,Chinese Academy of Sciences,Beijing 100190,P.R.China)
Abstract:In recent years, the research on the neural network language model has received more and more attention from the academic circles. At present, the neural network language model based on LSTM structure has become a research hotspot.In the speech recognition system, the corpus itself has certain relevance.But the traditional language models have limited memory capacity, and they cannot fully learn the relevance of the corpus.To solve this problem,a novel LSTM-DNN language model is applied to the revaluation of speech recognition, which fully exploits the correlation on a telephone conversation corpus. It is further compared with existing revaluation methods based on language models such as high order language model, feed forward neural network (FFNN) language model and recurrent neural network (RNN) language model.The experimental results show that the performance of LSTM-DNN language model is optimal. Compared to the first pass of decoding, the relative decline in average word error rate is 4.1% in the Chinese test sets.
Keywords:long short-term memory; neural network language model; speech recognition; revaluation
DOI:10.3979/j.issn.1673-825X.2016.02.007
收稿日期:2015-12-02
修订日期:2016-04-09通讯作者:左玲云zuolingyun@hccl.ioa.ac.cn
基金项目:国家自然科学基金(10925419,90920302,61072124,11074275,11161140319,91120001,61271426);中国科学院战略性先导科技专项(XDA06030100,XDA06030500);国家863 计划(2012AA012503) ;中科院重点部署项目(KGZD-EW-103-2)
Foundation Items:The Natural Science Foundation of China (10925419,90920302,61072124,11074275,11161140319,91120001,61271426); The Strategic Priority Research Program of the Chinese Academy of Sciences (XDA06030100,XDA06030500); The National 863 Program (2012AA012503); The CAS Priority Deployment Project (KGZD-EW-103-2)
中图分类号:TN911
文献标志码:A
文章编号:1673-825X(2016)02-0180-07
作者简介:

左玲云(1989-),女,山东聊城人,硕士研究生, 主要研究方向为语音识别、语言模型等。E-mail:zuolingyun@hccl.ioa.ac.cn

张晴晴(1983-),女,重庆人,副研究员, 主要研究方向为语音识别、声学模型、语言模型等。E-mail:zhangqingqing@hccl.ioa.ac.cn
黎塔(1982-),男,江西景德镇人,副研究员, 主要研究方向为语音识别、声学模型、解码器等。E-mail:lita@hccl.ioa.ac.cn
梁宏(1988-),女,贵州毕节人,助理研究员,主要研究方向为语音识别、语言模型等。E-mail: lianghong@thinkit.cn
颜永红(1967-),男,江苏常州人,博士生导师,研究员, 主要研究方向为语音信号处理、语音识别、语种识别、关键词检索等。E-mail:yanyonghong@hccl.ioa.ac.cn
(编辑:张诚)
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年12期)2016-06-14
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
电子技术与软件工程(2015年6期)2015-04-20
无线互联科技(2015年2期)2015-04-02
物联网技术(2015年3期)2015-03-31
软件导刊(2015年1期)2015-03-02
