
基于CUDA的数字调相信号并行解调程序设计*
2016-07-01 08:50刘燕都郑海昕王小平
通信技术 2016年2期
刘燕都,郑海昕,王小平
(1.装备学院,北京 101416;2.76160部队,广东 广州 510000)
基于CUDA的数字调相信号并行解调程序设计*
刘燕都1,郑海昕1,王小平2
(1.装备学院,北京 101416;2.76160部队,广东 广州 510000)
摘要:在通用计算机上实现数字通信的接收解调是近年来信号处理领域的重要研究方向。就实时性要求较高的数字调相信号解调问题,分析了算法的可并行性,研究了在通用计算机上实现的算法。针对“CPU+GPU”异构计算平台特点,提出了数字调相信号并行计算模型,基于CUDA平台设计了混频器、鉴相器、滤波器等模块的并行程序,实现了BPSK信号解调。测试结果表明,计算时间比为1:1.7,在SNR=9.6 dB时误码率可以达到10-5,与专有硬件解调数字调相信号的指标相当,但通用计算机平台实现方法更为灵活、易于功能扩展。
关键词:数字调相信号;解调;CUDA;并行
0引言
近年来,随着通用计算机性能的不断提高,数字通信系统中信号处理平台在经历了由模拟器件构建的硬件平台向软件无线电技术的数字化平台的转变后,正在开始向纯软件化的方向发展,将采样后的信号直接送入通用计算机,以软件处理的方式完成信号的解调、解码等。
数字相位调制,也就是相移键控(Phase Shift Keying,PSK),是一种十分重要的基本数字调制技术,也是一种用载波相位表示输入信号信息的调制技术。在时不变信道中,调相信号比调幅和调频信号具有更高的抗噪声性能和频带利用率,即使在有衰落信道、多径和强干扰的情况下也有较好的效果。因此,数字相位调制是一种性能优良的调制方式,在卫星通信、高速数据传输中得到了广泛应用。根据理想软件无线电的发展趋势[1],通信过程中,各项功能都应由软件来实现。本文基于高性能计算平台,研究了调相信号的软件化并行解调算法,以及基于CUDA的并行程序设计方法,并对调相信号并行解调程序进行测试,验证了调相信号并行解调的可行性。此处填入前言内容 。
1调相信号解调
调相信号解调方法一般可分为相干解调和非相干解调[2]。相干解调需要恢复与输入信号同频同相的信号,而非相干解调只需提取同频信号,虽然非相干解调实现方式简单,但相干解调因其恢复的信号与输入信号相位严格对齐,因此解调效果更好,应用更为广泛。但调相信号在调制过程中抑制了载波分量,若要提取同频同相的载波进行解调一般采用特殊设计的锁相环[3]。如平方环法、Costas环[4]等。还可以根据相邻码元之间相位跳变情况采用差分解调方法[5],算法相对简单,但其抗噪声性能要明显劣于相干解调。数字Costas环结构见图1。
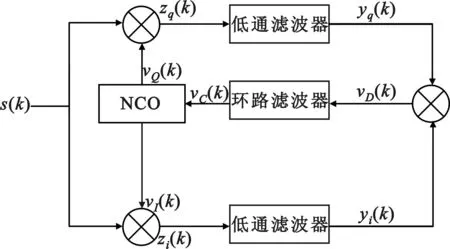
图1 数字Costas环结构
以二进制数字调相信号为例,其信号经采样后[6]:

(1)
(2)

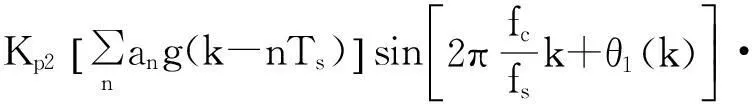
(3)


(4)
式中,K11,K12为低通滤波器系数,经滤波后的I、Q两路信号经相乘鉴相后,由环路滤波,可得:

(5)
式中,Kp为鉴相增益,Kd为环路增益,环路滤波器输出为NCO的频率控制字。
当环路锁定后,提取出同频同相的相干载波后,将其与输入的已调信号直接相乘,并滤波输出,即可得到基带信号波形,如图2所示,解调和锁相环跟踪如图3所示。


图2 数字调相信号时域波形及频谱

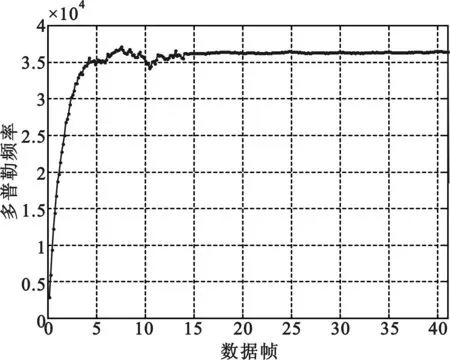
图3 解调结果及锁相环路频率跟踪曲线
2基于CUDA的并行计算模型
分析Costas环结构,可知不仅I、Q两路可以实现任务级的并行计算,其中的鉴相器、混频器和滤波器还可以实现数据级的并行计算,因此,研究在特定并行计算平台上的计算方法。
2.1CUDA
CUDA[7]是由NVIDIA公司推出的一种通用并行计算架构。起初是为加速图像实时处理而设计的一种运行在GPU上的开发平台,其充分运用了GPU的高存储带宽和超大规模的浮点计算单元,现在被广泛应用于大型并行化问题,如气象模拟、地震预报、分子计算等。CUDA硬件架构如图4所示。

图4 CPU和GPU结构对比
从图4不难看出,GPU是特别为计算密集,高并行度计算设计的,因此将更多的片上资源用于计算而不是数据缓存和逻辑。特别地,从GPU结构分析,其非常适合处理SIMD(单指令多处理)并行问题,即同一程序在多个数据上并行执行的问题,而数字信号处理具备这种特征,所以在CUDA平台非常适合进行数字信号处理。
2.2并行计算模型
根据GPU的硬件设计特点,CUDA在并行算法设计层做出了较为细致的约束[8]。模型假设CUDA线程在物理上独立的GPU上执行,GPU作为主机的协处理器,采取异构并行的模式,并行计算的内核程序在GPU上执行,程序的其它部分在CPU上执行。因为GPU设备不具备显示功能,因此数据需要在显存和内存之间由PCIe总线进行交互,受限于通用计算机的速度限制,在大规模数值计算中,数据传输时间占了程序大部分执行时间,图5所示为不同数据规模下并行加的计算时间,在数据规模较小时,数据几乎占了程序总执行时间99%以上,因此,只有在计算规模较大时,才能体现GPU计算的优势。


图5 并行求和运算时间对比
根据CUDA平台这一特点,数字通信系统并行计算模型中,应尽量减少数据传输,充分发挥GPU高性能计算能力。如图6所示,程序执行开始,将需要处理的数据全部转至显存,全部大规模计算由GPU完成,CPU和GPU在程序执行过程中,只进行少量数据传递,CPU只进行小规模的计算和数据监视和显示功能。

图6 基于GPU的数字通信并行计算模型
3数字调相信号并行解调程序设计
3.1数字调相信号解调算法结构
根据2.2节的并行计算模型和Costas环解调结构,数字调相信号并行解调算法[9-11]如图7示。
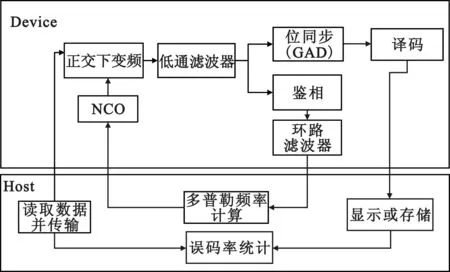
图7 基于CUDA的数字调相信号并行解调算法模型
中频采样数据从CPU读取并传输到GPU,在GPU中完成数字正交下变频、低通滤波、位同步、鉴相、环路滤波和译码;环路滤波后的相位误差信号传输回CPU计算多普勒频移,多普勒频移再传回GPU修正NCO输出的正、余弦波形;GPU译码后的数据再传回CPU进行显示和存储。见图8。

图8 算法流程
3.2混频器设计
混频器就是把信号从中频搬移到基频,是软件无线电的核心,通常硬件上采用数控振荡器(NCO)产生本地数字载波进行混频。并行混频时,对应数据点与对应相位的正弦和余弦波形采样点做乘法,并行程序算法如图9所示。

图9 变频器算法流程
混频器伪代码如下:
__global__ voidDownfreqKernel()
Begin
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid downfreq[tid].x = chandata[tid]*cos(2*PI*(fb+phasefd)); downfreq[tid].y = chandata[tid]*sin(2*PI*(fb+phasefd)); End 3.3滤波器设计 FIR滤波器以其良好的群延迟性被广泛应用在数字通信系统中,其可以保证任意幅频特性的同时具有严格的线性相频特性,同时其具有有限长冲击响应,算法如图10所示。 图10 滤波器算法流程 滤波器伪代码如下: __global__ void GPUFilterKernel() Begin __shared__ float2 cache[]; inttid = threadIdx.x + blockIdx.x * blockDim.x; cache[threadIdx.x].x=signal[tid].x; cache[threadIdx.x].y=signal[tid].y; __syncthreads(); float sumx=(cache[threadIdx.x].x+ ……+cache[threadIdx.x+16].x)*f.a; float sumx=(cache[threadIdx.y].y+ ……+cache[threadIdx.x+16].x)*f.a; result[tid].x=sumx; result[tid].y=sumy; End 3.4鉴相器设计 鉴相器主要完成鉴别输入信号相差的功能,是锁相环路的关键,在并行程序设计中,主要依靠求解前后采样点相差的办法,算法如图11所示。 图11 鉴相器算法流程 鉴相器伪代码如下: __global__ void ComputeSubphaseKernel() Begin inttid = threadIdx.x + blockIdx.x * blockDim.x; data[tid] = atan2(-src[tid].y,src[tid].x); data[tid] = src[tid+1]-src[sid]; if (data[tid]>PI) data[tid] -= 2*PI; else if (data[tid]<-PI) data[tid] += 2*PI; End 3.5测试结果 测试硬件平台选用NIVIDIA Tesla K20显卡,输入数据1 ms模拟数据,计算时间在1.7 ms以内,如图12所示,程序能够正确解调原数据,在Eb/N0=9.6 dB时误码率可以达到10-5。 图12 基于CUDA的BPSK信号并行解调结果 4结语 在通用计算机平台上实现数字调相信号的接收解调,降低了系统设计、开发的难度和成本,软件化的处理方式增加了系统的灵活性,通过加载不同的软件,可以实现更多的功能。通过硬件的升级和重组,还可以进一步提高系统性能。可见基于通用计算机平台,尤其是基于CUDA的数字信号处理是信号处理的一个重要发展方向,也是计算机应用的新趋势和研究的新领域。 参考文献: [1]王晓琴,黑勇.软件无线电硬件体系结构研究[J].科学技术与工程,2006,16(13):1820-1824. WANG Xiao-qin,HEI Yong.A Study of Software Radio Hardware Architecture[J].Science Technology and Engineering,2006,16(13):1820-1824. [2]Sklar Bernard.Digital Communications[M].北京: 电子工业出版社,2006:538-542.Sklar Bernard.Digital Communications[M].Beijing: Publishing House of Electronics Industry,2006:538-542. [3]刘艳华.Costas环法BPSK信号解调的研究与实现[J].通信技术,2012,45(01):16-21. LIU Yan-hua.Research and Implementation of BPSK signal Demodulation based on Costas[J].Communications Technology.2012,45(01):16-21. [4]季仲梅,杨洪生,王大鸣等.通信中的同步技术及应用[M].北京:清华大学出版社,2008:111-117. JI Zhong-mei,YANG Hong-sheng,WANG Da-ming,et al.Synchronization Technology and Application in Communication[M].Beijing: Tsinghua University Press,2008:126-128. [5]方浩华,王跃林,徐会勤等.基于DSP的DPSK差分解调的实现与研究[J].移动通信,2003增刊:79-84. FANG Hao-hua,WANG Yue-lin,XU Hui-qin,et al.Research on DPSK Difference Demodulation based on the DSP Implementation[J].Mobile Communications,2003(Supplement.):79-83. [6]Riter S.An Optimum Phase Reference Detector for Fully Modulated Phase Shift Keyed Signal[C].IEEE AES-5,1969,4(7):11-17. [7]NVIDIA Corp.NVIDIA CUDA Programming Guide 5.0[S].http://www.nvidia.com/object/cuda_Develop.html. [8]陈国良,孙广中,徐云等.并行算法研究方法学[J].计算机学报,2008,31(09):1493-1502. CHEN Guo-liang,SUN Guang-zhong,Xu Yun,et al.Methodology of Research on Parallel Algorithms[J].Chinese Journal of Computers,2008,31(09):1493-1502. [9]Core Mark T,Tan Harry H.BER for Optical Heterodyne DPSK Receivers Using Delay Demodulation and Integration Detection[J].IEEE Transactions on Communications,2002,50(1):1451-1459. [10]LI Gui-xin.,AN Zhi-qi.,YUAN Si-jie.Study on Software Demodulation of DQPSK Signal based on Digital Phase Measurement[J].Journal of Spacecraft TT&C Technology.2008,27(2): 1105-1110. [11]Mitra S K.Digital Signal Processing,A Computer-Based Approach[M].Second Edition,MeGraw-Hill Companies,Inc.,2001. Parallel Programming of PSK Signal Demodulation based on CUDA LIU Yan-du1,ZHENG Hai-xin1,WANG Xiao-ping2 (1.Equipment Academy,Beijing 101416,China;2.Unit 76160 of PLA,Guangzhou Guangdong 510000,China) Abstract:To implement digital communication receiving/demodulation on the general computer is an important research direction in the field of signal processing in recent years.Parallelism of the algorithm for BPSK signal demodulation with high real-time requirements is analyzed and implemented on the general computer.Based on the characteristics of "CPU + GPU" heterogeneous computing platform,the parallel computation model for digital phase modulation signal is proposed,and based on CUDA platform,the parallel-program modules of mixer,phase discriminator and filter are designed,thus to realize the BPSK signal demodulation.Experiment results show that the computing time ratio of 1:1.7,the BER of 10-5when SNR=9.6 dB could be reached,well-matched with those by special hardware demodulation,and in particular,the implementation method by general computer is more flexible,and easier for function extension. Key words:digital phase modulation signal; demodulation ; CUDA; parallel doi:10.3969/j.issn.1002-0802.2016.02.020 * 收稿日期:2015-09-10;修回日期:2015-12-20Received date:2015-09-10;Revised date:2015-12-20 中图分类号:TN911.7 文献标志码:A 文章编号:1002-0802(2013)08-0227-06 作者简介: 刘燕都(1986—),男,硕士研究生,主要研究方向为高速数字信号处理,航天测控技术; 郑海昕(1974—),女,硕士,副教授,主要研究方向为航天测控技术,空间数据传输; 王小平(1987—),男,学士,主要研究方向为高速信号处理,空间信息传输。




