
科研动态搜索引擎的自动分类方法研究
2016-06-30 09:15:16王春梅孙占全
科学与管理 2016年2期
王春梅,孙占全,李 钊,杨 春
科研动态搜索引擎的自动分类方法研究
王春梅1,2,3,孙占全1,2,3,李 钊1,2,3,杨 春3
(1.山东省计算中心(国家超级计算济南中心);2.山东省计算机网络重点实验室;3.山东省电子政务大数据示范工程技术研究中心,济南 250014)
摘要:随着搜索引擎应用的不断深入,人们对搜索引擎的个性化需求越来越多,对搜索结果的要求也越来越越高,如何实现高精准的垂直领域信息搜索和推荐是目前搜索领域所面临的难题。科研动态是科研工作者非常关心的信息,为提供更高效精准的科研动态信息,本文将基于半监督的分类方法用于科研动态信息的自动分类,用于科研动态搜索引擎系统,实现科研动态信息按用户需求精准搜索和推送,通过实例验证分类方法的有效性。
关键词:文本分类;半监督学习;搜索引擎;科研动态
1 引言
随着电子信息技术的快速发展,信息化办公已成为当前政府、科研机构、企事业单位的主流形式,互联网已成为查询信息的主要渠道,搜索引擎成为工作人员的日常工具。常用的搜索引擎包括百度、谷歌、必应、雅虎等水平搜索引擎,其搜索信息覆盖面广,信息量大,可满足各类用户的通用需求。但通用搜索引擎在提供丰富信息的同时,也带来一些问题,如结果不准确、实效性差等[1]。随着搜索引擎应用的不断深入,人们对搜索引擎的个性化需求越来越多,对搜索结果的要求也越来越高,因此,针对一些特定领域的垂直搜索引擎得到广泛的关注,垂直搜索引擎是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户,可为用户提供更加“专、精、深”的搜索结果,现已形成很多行业搜索引擎,如购物,旅游,汽车,工作,房产,交友等行业[2]。垂直搜索的行业应用越来越细分化,需求也越来越多。高校科研院所非常关注科研动态信息,包括各级政府部门发布的科研政策、项目主管部门发布的项目指南等动态信息,及时了解各种科研动态信息对应科研工作者的项目成功申报非常重要。科研工作人员关注的网站有几十,甚至上百个,每个网站浏览一遍,需要花费大量的时间,为方便科研工作人员的科研动态信息的方便快捷获取,形成了科研动态搜索引擎,可实现科研动态信息的检索和推送。科研动态信息数量很多,包含的内容也多种多样,为实现科研动态信息的精准推送,需要文本分类方法对抓取信息进行自动分类。
文本分类已有大量的研究,高精度的文本分类模型通常需要大量的标注样本,而大量的样本标注通常需要通过人工标注来实现,需要花费大量的时间,一般很难获取大量的训练样本[3、4]。针对少量有标注样本的文本分类,也有一些研究工作,主要是基于半监督学习的分类方法[5、6]。本文将基于半监督的分类方法用于科研动态信息的自动分类,实现科研动态信息的精准推送。
2 科研动态搜索引擎系统
科研单位的科研工作者需要关注大量的科研动态信息,如科技项目指南、科技奖励申报、科技活动信息等,为实现相关信息的自动采集,利用网络爬虫技术,通过网页种子设置,定向抓取相关网站信息;网页信息通常是半结构化信息,通过网页结构解析,将网页主体内容提取出来,利用分布式NoSql数据库Hbase对抓取的大量网页信息进行分布式存储;利用文本分析技术,包括中文分词、特征提取、建立索引等技术,实现网页信息的提取和快速检索;根据提取的文本特征信息,对网页内容进行挖掘分析,实现网页分类、搜索推荐等功能;以门户网站和邮件推送的形式为科研工作者提供服务。科研动态搜索引擎的系统结构如图所示。本文主要针对搜索引擎的网页内容自动分类方法进行研究,实现科研动态信息的自动分类。
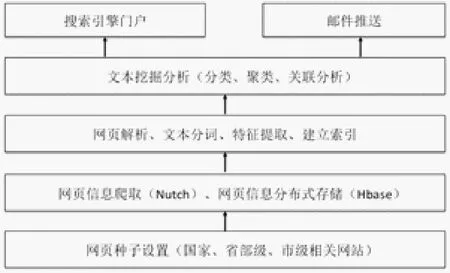
图1 科研动态搜索引擎系统架构
3 半监督分类方法
半监督学习是对具有少量标签样本的分类问题的有效方法之一。针对半监督学习,提出了的很多模型,其中tri-training模型是对协同训练模型的改进,降低了对数据集两个冗余视图的条件,从而大大提供了模型的可应用性。本文利用tri-training模型对科研动态信息进行分类,采用的分类器包括支持向量机、最近邻规则分类和Bayes分类器,方法介绍如下。
3.1支持向量机
支持向量机首先将输入单元映射到高维的特征空间,然后找一个分割超平面使得两类之间的边缘最大,边缘最大化是个二次规划问题,通过引入拉格朗日乘子可以变换成对偶问题来解决[7]。
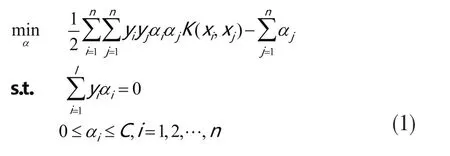
分类任务通常包括一定样本量的训练数据和测试数据,在每个训练样本中都包含一个目标值和多个因素,支持向量机的目的是生成一个在只知道测试数据的因素值就可以预测目标值的模型。通过优化计算求得后,用下面的决策函数实现分类分析
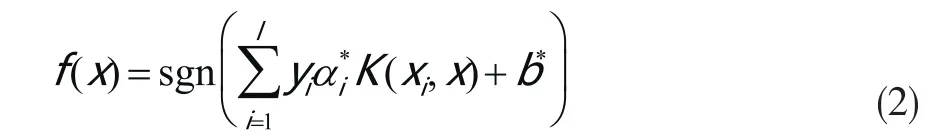
3.2KNN
最近邻规则方法是按一定的相关测度,搜索与待分类向量最临近的k个样本,通过判断k个样本的所属类别最多的一类来确定所属类别[8]。本文根据欧氏距离来确定待分类向量与样本之间的相关性,即
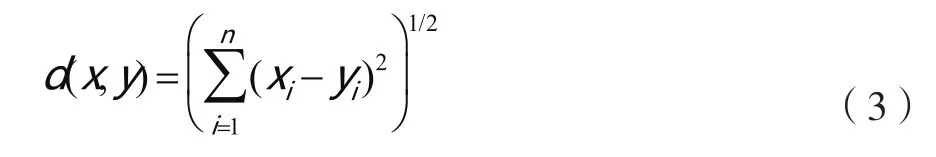
在计算完所有样本与待分类向量的相关度后,选择相关度最大即距离最小的k个样本,然后,利用投票表决法,近邻中哪个类别的点最多就分为该类。
3.3朴素Bayes网络
朴素Bayes分类是一种简单的分类算法,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,选择概率最大的一类作为分类结果[9]。设为一个待分类项,其中为特征变量维数,为的一个特征属性,类别集合,其中为类别数。首先,根据样本计算各类的特征条件概率分布
假设各个特征属性是条件独立的,贝叶斯定理为

根据Bayes定理,对于待分类项,通过下式确定该项的所属类别。
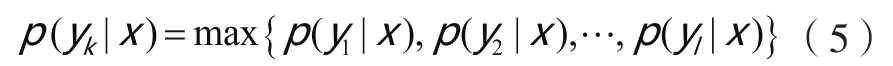
利用上面介绍的三个分类器,对有标签的样本进行建模训练,分布得到相应的分类器,对于任意一个无标签的样本 ,用已训练好的分类器进行分类,如果有两个分类器的结果一致,则将其进行标注为该类,然后将其加入到另外一个分类其的训练样本当中。对所用无标签样本进行分类分析,更新各个分类器的训练样本,然后对分类器进行重新训练,直到分类器不再变化为止。
4 基于文本分析的科研动态信息自动分类
文本分类需要对文本进行处理,提取出文本特征,从而进行挖掘分析,分析过程如下。
(1)文本特征提取
首先利用分词工具对抓取的网页信息进行分词,然后利用TF-IDF方法对网页信息进行提取,生成网页特征向量。
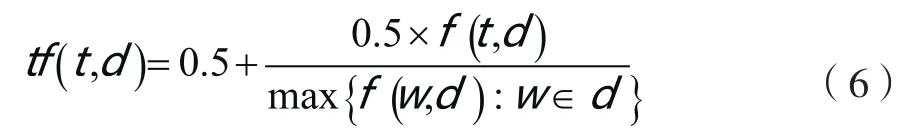
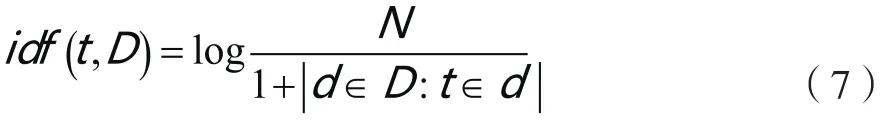
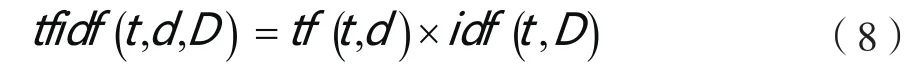

(2) 特征选择
文本生成的特征向量维数是根据所有分析文档生成的分词词库确定的,当文本量很大时,文本向量的维数会很高,如果用所有特征对文档进行分类分析,计算量会非常大,而且大多数的特征对于文档分类并不起作用。为提高文档分类的效率,需要对生成的文档特征进行特征选择,选择信息量最大的特征组合进行文档分类。本文采用无监督的单词贡献度法对文本特征进行选择。单词贡献度认为一个单词的重要性取决于它对整个文本数据集相似性的贡献程度,其计算公式为:
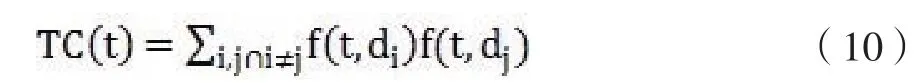
(3)文档分类
在获取网页的文本特征后,根据第3节介绍的半监督学习方法对文档进行分类分析,从而实现科研动态网页的自动分类。
5 实例分析
5.1数据源
针对山东省计算机领域科研部门的通用需求,利用科研动态搜索引擎系统抓取了科技部、工信部、国家自然基金委、发改委、山东省科技厅、山东省经信委、山东省发改委、济南市科技局、济南市经信委等40多个网站的通知通告和科技动态相关栏目网页信息,共收集了30000多条数据。根据用户对科研动态信息需求的不同,将抓取信息分为三种类型:政策类、新闻类、项目申报类。人工标注每类1000个,共3000个样本,利用本文提出的半监督分类方法,根据已采集的信息进行分类建模,生成科技动态信息的自动分类模型,对新抓取的科技动态信息自动分类。
5.2文本处理
首先,利用中科院分析工具ICTCLAS,对已收集的30000个样本进行分词,分别标题和正文进行分词,分别生成8912和15032分词向量维度。根据式(4)计算每个分词在每个文档的标题和正文中的TF-IDF值,生成标题和全文的文档向量。根据单词贡献度计算公式(9),分别针对标题向量和全文向量的每个分词计算单词贡献度,分词选择300个和500个贡献度最大的分词作为选择的特征用于文本的分类。
5.3文档分类
根据已标注的3000个样本,利用选择300个分词的特征向量,对基于标题的文档分类模型进行训练,包括支持向量机、KNN和Bayes网络;利用选择的500个分词的特征向量,对基于全文的文档分类模型进行训练,包括支持向量机、KNN和Bayes网络。根据生成的6个分类模型,利用第3节介绍的半监督分类方法,利用其余27000个无标识的样本对分类模型进行训练,对无标识样本进行自动分类,生成科技动态自动分类模型,用于新抓取信息的自动分类。
27000个未标识样本中,选择1000个进行人工验证,分类正确率达到85.4%,能够满足实际应用的需求。
6 结论
面向行业应的垂直搜索引擎在各领域的需求越来越多,对获取信息的精准性、有效性要求越来越高,为实现更加高效、精准的信息推送,将人工智能技术应用到搜索引擎系统已成为必然,虽然在这方面已有大量的研究工作,但由于垂直搜索引擎的个性化要求太多,很多应用领域的需求没有解决。本文将半监督学习的分类方法,应用于科研动态垂直搜索引擎系统中,解决了不同用户对不同信息的需求问题,得到了令人满意的结果。在科研动态搜索引擎领域还有很多需要进一步研究的问题,将结合更多的人工智能技术来提升系统性能是我们接下来的研究工作。
参考文献:
[1]程时端,郭亮,王文东. 社会搜索研究综述[J]. 北京邮电大学学报,2013,36(1): 1-12.
[2]王文钧,李巍. 垂直搜索引擎的现状与发展探究[J]. 情报科学,2010,28(3): 477-480.
[3]文翰,肖南峰. 基于强类别特征近邻传播的半监督文本聚类[J]. 模式识别与人工智能,2014,27(7): 646-654.
[4]Uysal,A. K.,and Gunal,S. A novel probabilistic feature selection method for text classification[J]. Knowledge- Based Systems,2012,36: 226-235.
[5]G. Li,K. Chang,S. C. H. Hoi. Multiview Semi-Supervised Learning with Consensus[J]. IEEE Transactions on Knowledge and Data Engineering,2012,24(11): 2040-2051.
[6]X. Cui,J. Huang,J. T. Chien. Multi-View and Multi-Objective Semi-Supervised Learning for HMM-Based Automatic Speech Recognition[J]. IEEE Transactions on Audio,Speech,and Language Processing,2012,20(7): 1923-1935.
[7]丁世飞,齐丙娟,谭红艳. 支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1): 2-9.
[8]郭躬德,黄杰,陈黎飞. 基于KNN模型的增量学习算法[J].模式识别与人工智能 2010,23(5): 701-707.
[9]刘啸啸. 基于Bayes算法的网页文本分类研究[J]. 数字技术与应用,2015,(12): 138-139.
(责任编辑:张 萌)
Study on Classification Methods of Scientific Research Search Engine
WANG Chunmei1,2,3,SUN Zhanquan1,2,3,LI Zhao1,2,3,YANG Chun3
(1.Shandong Computer Science Center(National Supercomputer Center in Jinan);2.Shandong Provincial Key Laboratory of Computer Networks;3.Shandong Demonstration Engineering Technology Research Center of E-government Big Data,Jinan 250014)
Abstract:With the development of searching engine,more and more personal requirement about searching comes into being. The requirement is higher than before. How to provide efficiency and accurate searching and recommending results is a difficult issue to be resolved. Scientific research trends is concerned by each research and different research has different requirement. For providing more accurate scientific research trends information,semi-supervised learning model is used to realize auto classification of scientific research related information. The classified information is recommended according to different personal requirement. The efficiency of the method is illustrated through practical analysis.
Keywords:Text classification;Semi-supervised learning;Searching engine;Scientific research trends
中图分类号:G254
文献标识码 :A DOI∶10.3969/j.issn.1003-8256.2016.02.006
基金项目:国家自然基金项目(61472230)、山东省计算中心(国家超级计算济南中心)内部立项资助(2015-003)
作者简介:王春梅 (1974-),女,副研究员,研究方向:软件工程技术、大数据 。
猜你喜欢
计算机应用(2016年12期)2017-01-13 01:24:36
电子技术与软件工程(2016年22期)2016-12-26 12:56:34
数字技术与应用(2016年9期)2016-11-09 23:23:56
电脑知识与技术(2016年23期)2016-11-02 23:40:10
科教导刊·电子版(2016年23期)2016-10-31 21:38:23
科技视界(2016年24期)2016-10-11 09:36:57
中国卫生(2015年12期)2015-11-10 05:13:38
警察技术(2015年3期)2015-02-27 15:37:09
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
