
基于项目档案的学术专题情报快速辅助生成系统技术分析
2016-06-28 16:08张鲁冀赵燕燕
天津科技 2016年6期
刘 念,张鲁冀,赵燕燕,陈 默
(1. 北京电子科技学院 北京100070;2. 北京市科学技术情报研究所 北京100048;3. 大唐电信科技股份有限公司 北京100094;4. 机械工业信息研究院 北京100037)
基于项目档案的学术专题情报快速辅助生成系统技术分析
刘 念1,张鲁冀2,赵燕燕3,陈 默4
(1. 北京电子科技学院 北京100070;2. 北京市科学技术情报研究所 北京100048;3. 大唐电信科技股份有限公司 北京100094;4. 机械工业信息研究院 北京100037)
从情报研究、信息源、分析需求等层面探讨了信息情报的概念和特征,提出简单的统计分析已不能满足当前社会的决策需求,需要从大量信息中发现潜在模式,指导未来的发展,这就涉及数据挖掘、机器学习等技术。目前,国外对情报研究中的智能化技术没有统一的界定,但概观之,可以将情报研究智能化的本质概括为定量化、可计算、可重复。就此进行了阐述和分析。
信息挖据 情报 算法
0 引 言
搜索引擎是一种在Web上搜索和挖掘信息的软件系统,通过结合若干种策略,可以自动地将信息搜集起来并以统一的组织形式呈现出来,给用户提供系统的信息查询业务。搜索引擎的种类有很多,包括元搜索、垂直搜索、全文索引、目录索引等。目前较为主流的搜索引擎有百度、Google、AltaVista、雅虎、SOSO、必应等。在信息搜索方面,搜索引擎不仅需要庞大的硬件系统作为后备支持力量,还需要相当复杂的软件结构的设计。
从结构上来讲,搜索引擎主要分为网络爬虫、资料库和索引库,系统首先会启动大批量的爬虫对网络上的档案数据进行采集,将这些数据保存到资料库中,其中会运用到复杂的URL调度策略和数据抓取策略,以保证同一个网页不会被重复抓取。然后系统会对资料库中的数据建立索引,保存到索引库中,将无序的资料整理成有序的资料库。目前建立索引的主流方式是倒排索引,也称倒排文件法,由于本文主要介绍搜索引擎的网页爬虫部分,不涉及建立索引的工作,故在此不进行过度叙述。最后,用户通过输入关键词,系统将对用户输入的信息进行分析,包括分词、去噪、合并同义词等处理,最后从有序资料库中将结果返回给用户(见图1)。

图1 搜索引擎工作原理结构图Fig.1 Working principle diagram of search engine
1 元搜索模型
1.1 基本概念
元搜索是搜索引擎中的一种,也可称为“多搜索引擎”,它的本质是通过调用其他搜索引擎来进行工作,元搜索中的“元”有总的、超越的意思,故也有人称之为“搜索引擎之母”。Metacrawler是世界上最早的元搜索引擎,作者是华盛顿大学的教授Oren Etzi以及学生Erik。它是InfoSpaceInc的一部分,于1995年正式在网络上运行。元搜索模型不需要独立的网页数据库,它可以根据用户的特定需求选择不同的搜索引擎进行检索,传统意义上的元搜索模型都是采用并行结构对数据进行抓取,还能根据需要对特定的数据类型进行检索,如图片、视频、文档等。
元搜索模型解决了传统搜索引擎搜索结果不足的问题,使之更为全面,如果元搜索引擎对一个关键词检索到了若干个相同或相似的信息,则说明该信息对于用户输入的关键词最为有用,相关度最高。相反地,元搜索模型会带来更多的网页噪音,对于网页去噪带来更大的挑战。元搜索模型有着很好的发展前景,通过对检索的个性化设置和数据的整合优化,给用户提供大而全的信息,这可以为很多行业带来方便。
1.2 工作原理
元搜索模型可以被看作是有着双层C/S结构的系统。元搜索引擎接收用户发送的请求后,同时并行连接多个搜索引擎,向其发送实际的检索条件,然后将各个搜索引擎返回的结果收集起来,做统一处理,最后显示给用户。元搜索模型的系统结构包括检索请求发送模块、接口代理模块以及检索结果处理显示模块,以环形结构相互顺序连接。从搜索方式上可以分为词语搜索、目录搜索和高级搜索3种搜索方式。词语搜索的对象是文本,可以是一个词、词组或是一句话,然后对其进行分词处理以及同义词合并、关联搜索。目录搜索也被称为“分类搜索”,用户不需要输入关键词,而是通过搜索引擎提供的类别选择不同的目录进行检索。高级检索也被称为“定制检索”,需要用户输入布尔逻辑匹配组来进行检索(见图2)。
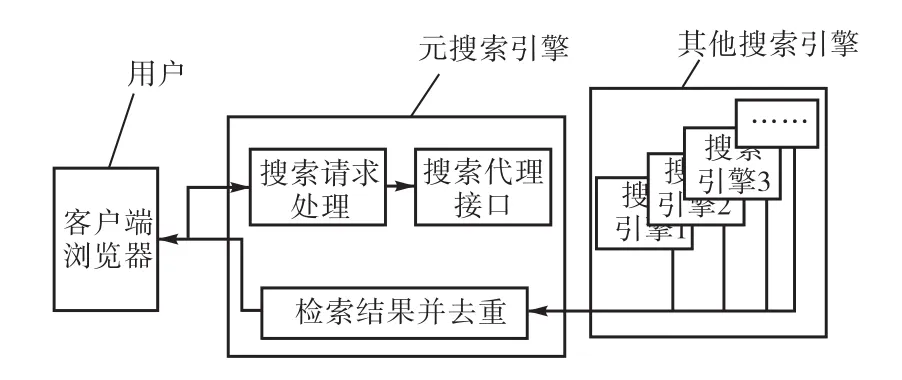
图2 元搜索模型结构图Fig.2 Meta model structure
2 垂直搜索模型
2.1 基本概念
垂直搜索模型是搜索引擎的一种表现形式,比较百度、Google等通用搜索引擎“大而全”的检索方式,垂直搜索引擎的特点则是“小而精”,是一种专门为某一行业或工作设计的搜索引擎。垂直搜索引擎不能为用户提供数以亿计的检索结构,而是提供匹配程度极高的精确数据。垂直搜索针对的用户群体普遍稳定性强、专业性强,且具有一定的行业色彩。与通用的搜索引擎比较,最大的不同是垂直搜索引擎使用结构化的信息抽取方法,将数据以结构化的方式存储到数据库中。通用搜索引擎是以网页或链接为最小单元,而垂直搜索引擎则是以结构化数据为最小单元,这种方法的好处在于可以利用不同数据的特征对象进行比较分析。
2.2 工作原理
以购物垂直搜索引擎为例,它的数据来源是网络上各种各样的购物网站,首先购物垂直搜索模型会对多个购物网站与该产品相同或相关的产品信息进行检索,按照结构化的形式将数据保存到数据库中,例如该产品的名称、重量、产地、价格等参数,最后对结构化数据建立索引。当用户通过输入关键词对某一产品进行检索时,购物垂直搜索引擎会从索引库中根据关键词提取数据,然后返回给用户。购物垂直搜索引擎不仅能对用户输入的信息进行采集,还能将产品按照价格、规格、产地等参数信息进行统计和比较,给用户提供最佳的选择方案,或者满足用户特定的检索需求。这种搜索模式产出的检索结果比通用搜索引擎的结果有更大的参考价值,同时也满足了商家的促销目的。
3 网页信息采集的工作原理及相关技术
3.1 网页信息采集策略
网页信息采集主要使用网络爬虫技术。网络爬虫是使用某种策略对Web页面信息进行采集的程序,是搜索引擎中重要的组成部分(见图3)。传统的网络爬虫以一个或若干个URL作为初始节点,然后将该URL页面上的所有链接下载到服务器内,在爬虫搜索的过程中,不断地从当前网页上获取新的URL,直到满足一定的终止条件时停止抓取。实现网页抓取主要有广度优先策略、深度优先策略以及最佳优先策略。
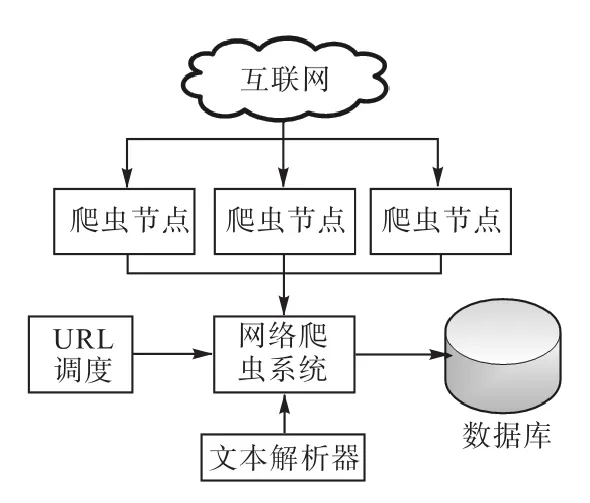
图3 网络爬虫结构图Fig.3 Web crawler structure
广度优先搜索策略(Breadth First Search)也被称为宽度优先搜索策略,是指在网页抓取的过程中,在获取当前层次中的全部URL后,再进行下一层次的搜索。该算法的目的是为了尽可能多地覆盖网页URL。聚焦爬虫就是使用了这种搜索策略,其主要思想是与初始URL距离越近的网页,与搜索的主题相关性就越大。此外还能与网页过滤技术结合,首先使用广度优先策略对网页进行抓取,再过滤掉其中相关性较低的网页。这些方法的缺点在于,随着抓取URL数量的增多,将会下载并过滤大量不相关页,结果降低了算法的效率。
深度优先搜索策略(Depth First Search)是指从起始URL开始,获取该URL中的其中一个链接,从这个链接进入,分析这个网页中的某一个URL,再选择一个进入。如此循环地抓取下去,直到完全处理一条URL路线上的链接后,再处理下一个URL。深度优先搜索策略比较简单易行,网络爬虫的初始网站往往具有较高的价值,网页排名也很高,但每深入一层,网页的价值和排名都会有一定比例的下降。这说明了重要网页通常距离初始URL较近,非重要网页与初始URL距离较远。同时,深度优先搜索策略直接影响了搜索的准确度和搜索效率,这种缺点是致命的,所以相对于其他两种搜索策略来说,这种搜索策略极少被用到实际需求中。
最佳优先搜索策略(Best First Search)是指系统通过对URL的分析做出评价,对评价值较高的URL进行抓取,直接抛弃评价较低的URL,也就是说这种搜索策略只会抓取系统认为有用的网页。这种策略容易陷入局部最优解,一旦某些有用的网页存在于被过滤掉的URL路径的后面节点中,搜索的精度就会下降。但是这种搜索策略可以过滤掉30%,~90%,的无关网页,故在实际应用中结合需求会对该算法进行改进。
3.2 并行抓取策略
为了提高信息采集的效率,需要使用多台服务器进行并行抓取,通用的搜索引擎如百度搜索引擎,至少使用上万台服务器进行并行抓取,如何保证不同的服务器抓取的URL不同是并行抓取技术的关键点之一。通用搜索引擎通常采用哈希表或信息指纹排重法来解决重复URL的下载问题,在这之中需要网络爬虫系统配置一个专用的模块来对庞大的服务器群进行信息沟通,以避免服务器之间发生冲突。而使用元搜索模型或垂直搜索模型时,往往不需要考虑服务器之间的通信问题,因为元搜索模型和垂直搜索模型在很多情况下只需要对某些搜索结果进行抓取。例如对百度搜索引擎的结果进行抓取时,共有K台服务器,每台服务器的编号是Ki(i∈[1,k]),检索结果共有M页,则每台服务器只需要抓取第到第页即可。在不考虑服务器之间通信情况下,理论上网络爬虫的执行效率会提高K倍(K为服务器数量)。
此外,每台服务器在系统内部也需要使用多线程控制模块进行加速,线程的数量依照服务器硬件水平、网络带宽以及即时网速而定。使用多线程技术可以有效地在网速范围内大大加快爬虫执行效率,但线程过多会导致系统将过多的资源分配在线程调度上,从而导致系统崩溃;而线程过少又是对系统资源和网络资源的浪费。
3.3 断点续传技术
对于网页抓取技术而言,断点续传是实现爬虫软件的必要手段之一,顾名思义,断点续传就是当爬虫软件遇到错误、线路中断或者遇到意外强制关闭后,下次开启程序依然可以从上一个断点处继续运行,这样很大程度上减少了用户的烦恼。如果一个爬虫软件不支持断点续传,那么这个爬虫系统是非常不健全和不完整的。实现断点续传的方法很简单,每当程序执行到一定程度,例如系统抓取了1,000条数据时,系统就将当前的参数保存到一个文件中,这个文件可以保存到本地也可以保存到服务器上,文件中需要写入本次执行的全部必要参数,如检索的关键词、网址、开始检索的页数、当前检索到多少页、检索结果总页数、输出文件路径等,每次写断点时更新这个文件,如果程序关闭,下次执行时就先预读这个断点文件,然后从上次的断点位置重新开始抓取。
一般的爬虫软件都设置有启动后自动运行断点续传数据的功能,并且启动后自动托盘化或执行后台运行程序,这样配合断点续传功能就可以真正脱离人工干预实现自动运行了。
4 几种经典算法的优缺点比较(见表1)
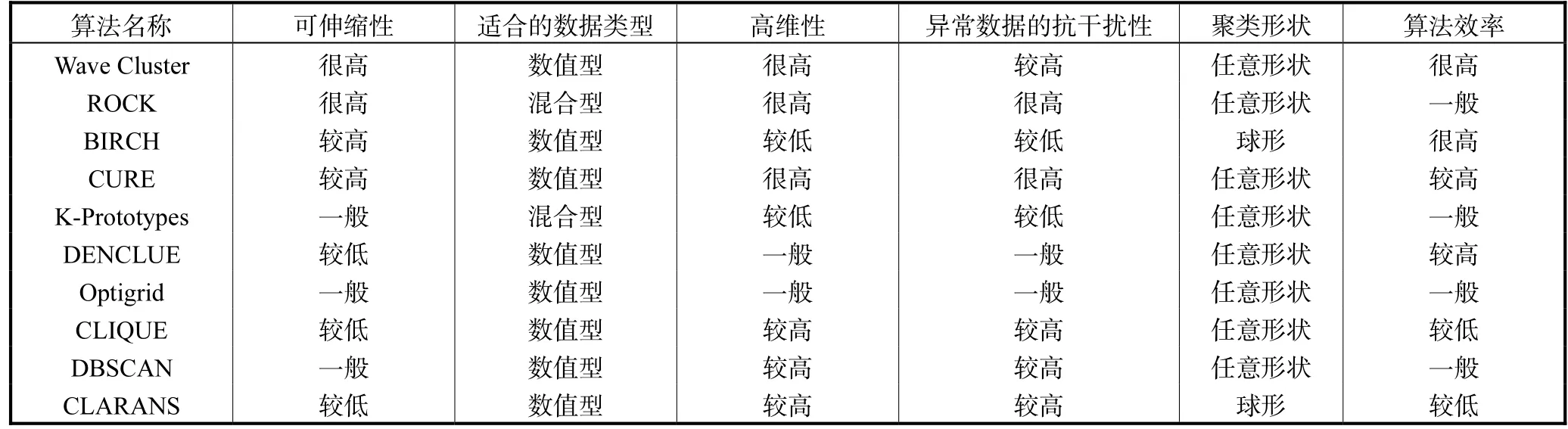
表1 布尔模型在文本表示中的样例Tab.1 The sample of the Boolean model in text representation
5 文本聚类评价方法
评价文本聚类算法的标准有很多,从类型上来说可以分为外部度量法、内部度量法和相对度量法。外部度量法是使用有监督的评价方法,人工事先对文档集合进行标注,即有文档集合X={x1,x2,x3…xn},已知人工标注的结果为{{x1,x3…},{x2,x4…},{xn-1},{xn}},对使用聚类算法进行实际聚类后得到的结果再与人工标注的方式进行比对来评价。内部度量是使用无监督的评价方法,利用聚类后的文档集合直接对聚类结果进行评价,不需要人工干预,例如通过计算每个簇的平均误差等方法进行评价。相对度量法是结合上述两种方法对聚类结果进行评价。
聚类算法评价的指标主要是依据簇内相似度最大,簇间相似度最小的标准来评价以及利用人工标注的结果作为参考。本文中主要使用主流的外部度量评价方法,下面介绍有关的几种算法。
5.1 基于F值的评价方法
F-Measure[48]值采用准确率和召回率的方法进行评价,把文档的类别记作{A1,A2…An},把文档经过聚类后的结构类别记作{B1,B2…Bm},那么对于每个初始类别Ai,找到一个与其具有最大公共子集的类别Bj,它们重复的序列数为K,则召回率为;准确率为。如图4所示,簇A为聚类之前进行过人工标注的一个类别,簇B是聚类后的一个类别,首先找到与簇B有最大交集的簇A,有,对于簇B的召回率为,准确率为,整体的召回率与准确率等于每个簇的平均值,即。召回率体现同一类别的元素被分到同一类别中的程度,准确率体现不同类别的元素被分到不同类别的程度,F值是对准确率和召回率的综合评价指标,,由于准确率和召回率是此消彼长的关系,因此一般取β=1,表示召回率和准确率的比重相同(见图4)。
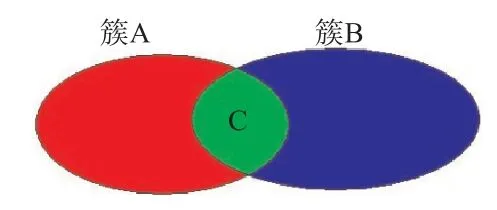
图4 准确率与召回率计算示意图Fig.4 Accuracy and recall rate calculation diagram
5.2 基于熵的评价方法
熵使用了内部一致性的方法对聚类结果进行评价,Ai表示人工标注的簇,Bj表示聚类后的簇,Cj表示与Bj存在的最大公共子集,K表示人工标注的簇个数,M表示经过聚类算法计算得出的簇个数,则熵E的计算方法为:
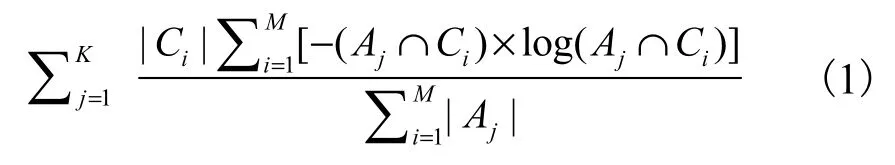
5.3 Jaccard、Rand及FM系数法
与上面的方法类似,下面使用4种聚类结果与人工标注的不同情况来进行评价(见表2)。

表2 Jaccard、Rand及FM系数法的参数说明Tab.2 Jaccard,Rand,and the parameters of FM coefficient method
Jaccard系数法,又被称为Jaccard相似性系数,Jaccard系数等于样本集交集与样本集合集的比值:

Rand系数法体现了聚类结果与人工标注的统一性的程度:

FM系数法考虑了两种情况下正确聚类的簇所占的比重:

6 前期基础
建设了覆盖所有学科领域的科技词库,该项工作为人机结合智能情报工具的设计实现奠定了关键基础,是大数据时代和大科学时代科技情报工作的基石。■
[1] 夏宁霞,苏一丹. 一种高效的K-medoids聚类算法[J]. 计算机应用研究,2010,27(12):56-65.
[2] 周洪翠,庄新妍. 基于向量空间模型的文本信息表示[J]. 呼伦贝尔学院学报,2011,6(1):35-44.
[3] 郑彦宁. 我国科技情报行业创新发展的关键问题[J].情报学报,2008,27(6):15-18.
Technical Analysis of Fast Aid System for Information Generation for Academic Subjects Based on Project Archives
LIU Nian1, ZHANG Luji2,ZHAO Yanyan3,CHEN Mo4
(1.Beijing Electronic Science and Technology Institute,Beijing 100070,China;2.Beijing Institute of Science and Technology Information,Beijing 100048,China;3.Datang Telecom Technology Co.,LTD.,Beijing 100094,China;4.Machinery Industry Information Institute,Beijing 100037,China)
The concept and features of informational intelligence were discussed from the aspects of intelligence research,information source and demand for analysis.It points out that the demand for simple statistical analysis cannot meet the demand of social decision now,and it needs to find potential models from a large number of information to guide the development of the future,which involves data mining and machine learning techniques.Today,there is no unified definition of intelligent technology in the circle of information research in foreign countries,but the nature can be summed up as quantification,calculability and repeatability.The above mentioned topic was discussed.
information mining;intelligence;algorithm
G27
A
1006-8945(2016)06-0043-04
本论文得到“北京市科技计划项目”资助,项目名称:数字科技档案自动化与利用服务系统设计研发(Z151100003215042)。
2016-05-12
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
疯狂英语·新阅版(2020年11期)2020-12-21
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
