
一种改进的SMO分类算法
2016-06-22 08:01:52刘晓莹杨宝华
滁州学院学报 2016年2期
关键词:支持向量机
刘晓莹,杨宝华
一种改进的SMO分类算法
刘晓莹,杨宝华
摘要:针对序列最小优化(SMO)算法对大规模数据集训练速度慢、分类精度不够高的问题,提出了一种改进方法。该方法对SMO算法的核函数进行改进,通过增大二次项系数的绝对值提高分类正确率,并结合网格搜索法优化基于核函数改进的SMO算法的有关参数。实验结果表明,该算法显著提高了分类的正确性,缩短了算法的建模时间。
关键词:支持向量机;SMO算法;核函数;参数寻优
随着人类社会的快速发展,信息技术、互联网、云计算、物联网等诸多领域的突破,使大量的数据在急剧膨胀,因此迫切需要更加快速、精确的方法对收集到的海量数据进行分类,以便从中提取出有效的、新颖的、精炼的、可理解的知识。现有的分类算法[1]有很多种,比如经典的有决策树、人工神经网络、贝叶斯、支持向量机等方法。
近年来,SMO算法[2]已经受到越来越多研究者的关注。项堃[3]等人提出一种运用删减部分支持向量,提前结束循环条件的策略;王越[4]等人选取优化步长最大的违反KKT条件的样本和其配对样本;王朝辉[5]等人通过改变存储策略,将算法中的五个工作集替换成三个工作集;骆世广[6]等人提出将算法的终止条件改为目标函数值的改变量,并改变SMO后期迭代循环条件。
上述算法仅在缩短训练时间方面已经取得了一定的改进,但当训练大规模数据集时,SMO分类效果还不够明显,分类正确率也需要进一步的提高。本文提出一种改进方法,通过增大二次项系数的绝对值提高分类正确率,通过实验结果验证,该方法可以大幅度降低建模时间,提高分类精度。
1序列最小优化算法
1.1支持向量机概述
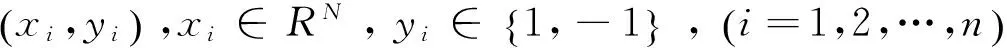
式中:αi为拉格朗日乘子,C为惩罚因子。
根据上述问题得到的对偶问题为
(1)
分类决策函数为:
(2)
式中:α*为最优解;b*为阈值,它由任一个支持向量求出也可通过两类中任意一对支持向量取中值求得。
1.2SMO算法
SMO算法[8]是目前SVM处理大数据集十分有效的方法。整个SMO算法包括两个步骤:
步骤一:求解两个变量的二次规划的解析方法
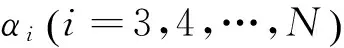
经过推导可得:
(3)
其中:
经过修剪后的α2
(4)
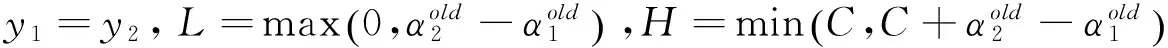

步骤二:选择变量的启发式方法。
SMO选择第一个变量的过程称为外层循环,外层循环在训练样本中选取违反KKT条件最为严重的样本点,并将其对应的变量作为第一个变量。具体地,检验训练样本点是否满足KKT条件,即
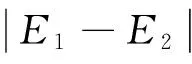
SMO算法的优点在于通过两个变量的二次规划问题的解析来求解,不需要进行巨大的矩阵运算,但其在面对大规模数据时,出现训练速度慢、分类正确率不够高的问题。
SMO算法的大部分训练时间主要集中在最有可能违反KKT条件的非边界样本上。该算法训练速度慢的主要原因在于它需要计算和存储核函数矩阵,随着数据样本的增加,所需的内存空间也增大。因此,可通过减少计算核函数矩阵的方法来加快算法的速度。
1.3核函数
核函数的基本思想就是通过一个非线性变换将输入空间映射到一个高维特征空间,在这个特征空间中求解最优分类面。每个中间节点对应一个支持向量,输出的决策函数是中间节点的线性组合。
不同的核函数及其参数的选择对于SMO算法具有重要的影响。核函数的引入避免了“维数灾难”,大大减小了特征空间的计算量,无需知道非线性变换函数φ的形式和参数。核函数可以和不同的算法相结合,形成多种不同的基于核函数技术的方法[9]。目前常用的核函数[10]主要有三类:
1)多项式核函数:
(5)
2)高斯核函数:
(6)
3)Sigmoid核函数:
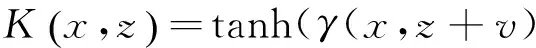
(7)
2SMO算法的改进
2.1核函数的改进
Vapnik等人提出测试样本分类误差率的期望上界
(8)
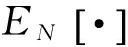
选取SMO算法的某个核函数与系数(1+m)(m>0)相乘,以高斯核函数为例,如(9)式:
(9)
由(9)式可知,核函数与一个系数(1+m)(m>0)相乘可增大LD中二次项系数的绝对值,从而减小了αi的最优值及支持向量个数,减少分类误差率,提高支持向量机的分类精度和推广能力。
2.2参数寻优
在核函数改进方法中,参数m的取值直接影响了基于核函数改进的SMO算法的分类性能,因此选择合适的参数也是非常重要的。本文选用网格搜索法[11]优化核函数的参数m和惩罚因子C。用基于核函数改进的SMO算法计算整体的分类精度,直到得到满意的分类结果为止。其具体步骤如图1所示。
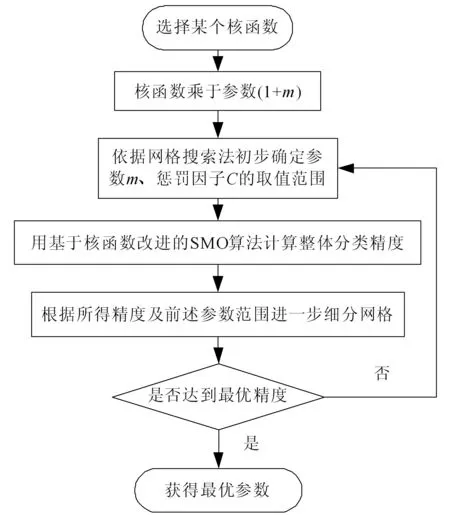
图1结合网格搜索法的SMO参数寻优步骤
3实验结果与分析
3.1实验一
为验证本文方法的有效性,在加州大学厄文分校(UCI)的机器学习数据库中选用两组数据集Labor和Sensor_reading_4进行测试,Labor数据集包含57个实例,16个属性,2个类别,属于小数据集。Sensor_reading_4数据集包含5458个实例,4个属性,4个类别,属于大数据集。本文方法用Java语言实现,在实验中,选用RBF核函数,利用十折交叉验证法评价分类器,对于Labor数据集,C取1,m取111;对于Sensor_reading_4数据集,C取1,m取147。实验结果如表1所示。
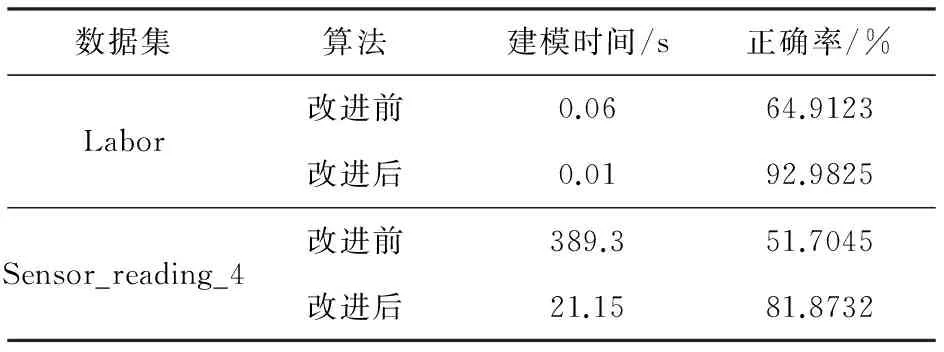
表1 RBF核函数改进前后实验结果对比
表1显示了基于核函数改进的SMO算法和SMO算法分类结果比较,从表中可以看出,以Sensor_reading_4大数据集为例,在建模时间上,基于核函数改进的SMO算法差不多只用了21.15s,大幅度降低了建模时间,其分类正确率为81.8732%,与SMO相比,提高了近30%。实验结果表明,基于核函数改进的SMO算法,具有更高的分类正确率,且大大缩减了算法的建模时间,尤其是对大规模数据集而言,效果更显著,同时也验证了本文方法的可行性和有效性。在Sensor_reading_4数据集上,基于核函数改进的SMO算法的误分可视化结果如图2所示。
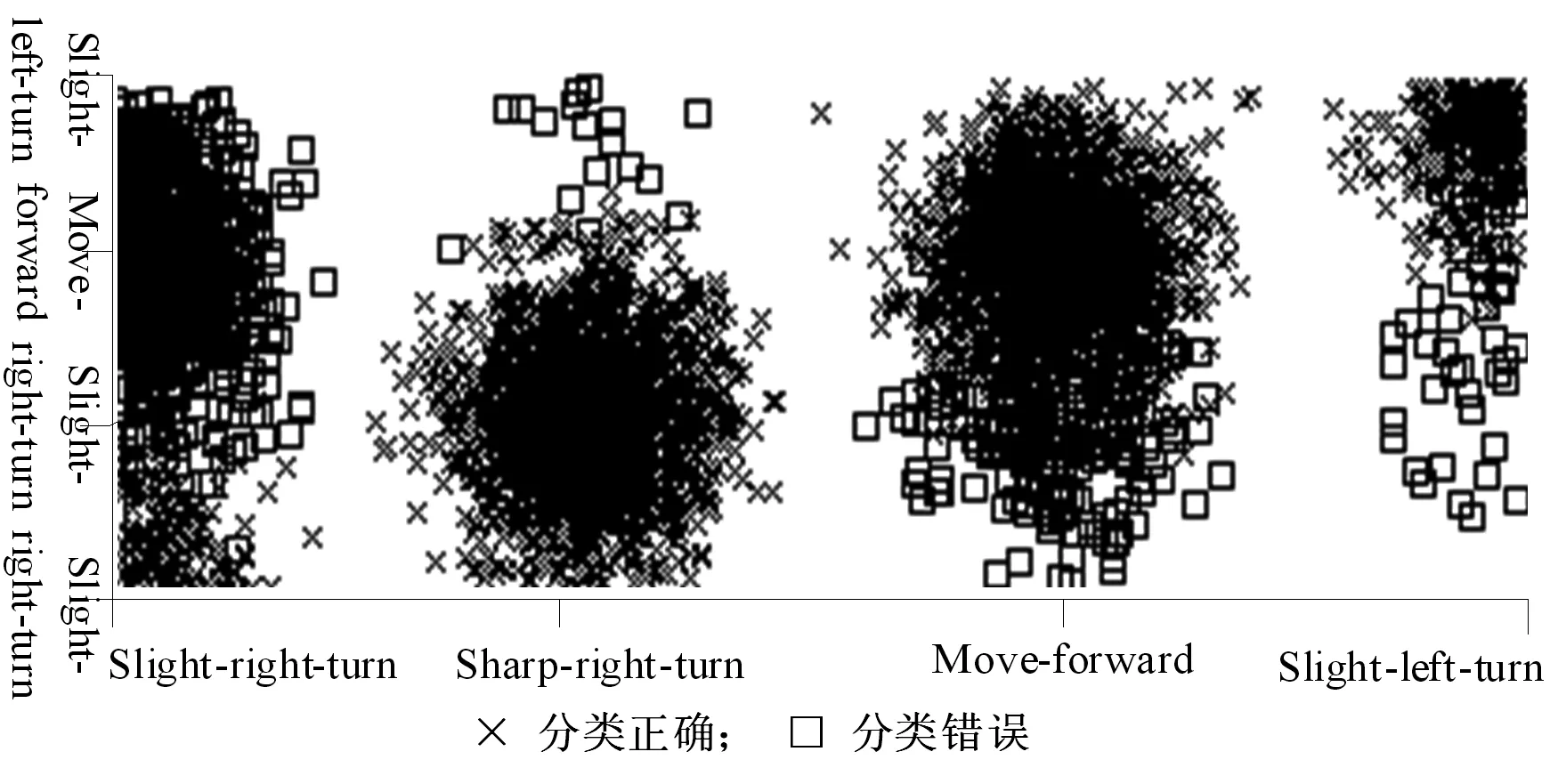
图2Sensor_reading_4数据集的误分可视化结果
Sensor_reading_4数据集包含四个类别属性:Slight-right-turn、Sharp-right-turn、Move-forward、Slight-left-turn。X轴为实际类别,Y轴为预测类别,图中方块表示分类错误的样本,叉表示分类正确的样本。
3.2实验二
为寻找上述实验中参数m的最优值,本文采用网格搜索法优化基于核函数改进的SMO算法的参数m和惩罚因子C。以Sensor_reading_4数据集为例,实验过程如下:
(1)选定一组C,m的取值范围和搜索步长,设C的初始范围为[1,8],步长为1;m的初始范围为[0,50],步长为1。
(2)用基于核函数改进的SMO算法计算整体的分类正确率和搜索时间,实验结果得到使分类正确率最高的最优参数C=1,m=45。
(3)根据得到的最优参数,在其附近选择不同的取值范围进行二次寻优,并计算出搜索时间和分类正确率,比较不同的取值范围对分类正确率的影响,实验结果如表2所示。
从表2可以看出,第三组的搜索时间最短,且分类正确率最高,选择此组参数作为最优参数,即最优值C=1,m=147。同样,对于Labor数据集,采用网格搜索法得到的最优参数C=1,m=111。
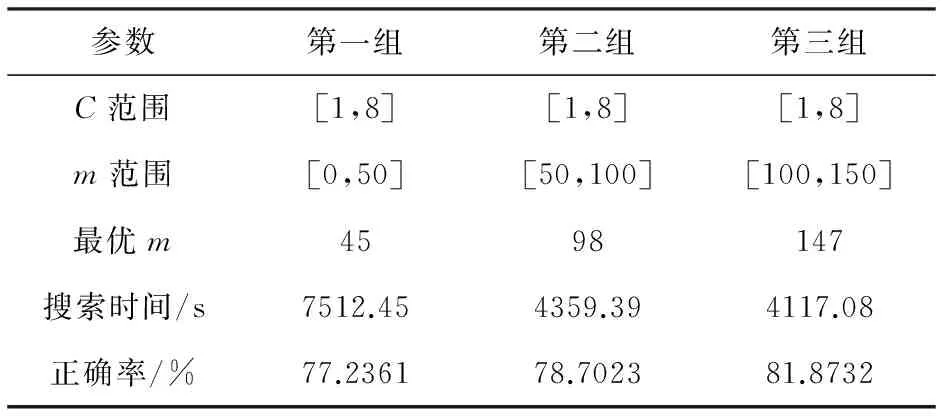
表2 不同取值范围内参数寻优结果对比
4结束语
本文在对Vapnik等人提出测试样本分类误差率的期望上界的分析的基础上,通过减少支持向量数的方法来减小分类误差率,提出了核函数改进方法,提高了分类正确率,且大幅度降低了建模时间。结合网格搜索法,优化基于核函数改进的SMO算法的有关参数。实验结果证明,在大数据情况下,该方法能有效的克服SMO算法的缺陷,并获得较好的分类效果。
网格搜索法对于大数据集的搜索时间过长,该方法需要进一步的改进研究,参数的寻优方法可作为今后的研究方向。
[参考文献]
[1]罗可,林睦纲,郗东妹.数据挖掘中分类算法综述[J].计算机工程,2005,31(1):3-5.
[2]Platt J C. Fast training of support vector machines using sequential minimal optimization[C]//Advances in Kernel Methods-Support Vector Learning. Cambridge, MA: MIT Press, 1999: 185-208.
[3]项堃,喻莹.一种改进序贯最小优化算法的方法[J]. 现代电子技术, 2013, 36( 8) : 17-19.
[4]王越,吕奇峰,王泉等.一种改进的支持向量机序列最小优化算法[J].重庆理工大学学报(自然科学),2013,27(3):76-79.[5]骆世广,骆昌日,周业明.针对大规模样本集的SMO训练策略[J].广东技术师范学院学报,2008,9:30-33.
[6]王朝辉,黎鑫.基于WEKA的序列最小化算法的改进研究[J].工业控制计算机,2012,25(8):81-84.
[7]顾亚祥,丁世飞.支持向量机研究发展[J].计算机科学,2011,38(2):14-17.
[8]张宏灏.准线性支持向量机及序列最小优化算法[D].西安:西安电子科技大学,2013.
[9]张倩,杨耀权.基于支持向量机核函数的研究[J].电子科学与工程,2012,28(5):42-45.
[10]邬啸,魏延,吴瑕.基于混合核函数的支持向量机[J].重庆理工大学学报(自然科学),2011,25(10):66-70.
[11]王健峰,张磊,陈国兴等.基于改进的网格搜索法的SVM参数优化[J].应用科技,2012,39(3):28-31.
责任编辑:王与
中图分类号:TP301.6
文献标识码:A
文章编号:1673-1794(2016)02-0030-03
作者简介:刘晓莹,安徽农业大学信息与计算机学院硕士研究生;通信作者:杨宝华,农业部农业物联网技术集成与应用重点实验室,安徽农业大学信息与计算机学院副教授(合肥 230036)。
基金项目:国家自然科学基金项目(61203217),安徽农业大学学科骨干培育项目(2014XKPY-62)
收稿日期:2015-11-15
猜你喜欢
现代电子技术(2016年23期)2017-01-12 09:57:47
现代电子技术(2016年23期)2017-01-12 09:26:09
无线互联科技(2016年13期)2017-01-10 02:49:43
中国水运(2016年11期)2017-01-04 12:26:47
软件导刊(2016年11期)2016-12-22 21:52:38
电子技术与软件工程(2016年20期)2016-12-21 10:21:33
价值工程(2016年32期)2016-12-20 20:36:43
价值工程(2016年29期)2016-11-14 00:13:35
科学与财富(2016年28期)2016-10-14 21:19:17
考试周刊(2016年53期)2016-07-15 09:08:21
