
居民用户用电的聚类分析
2016-06-20 07:17徐苒茨黄珉皓
电力与能源 2016年2期
张 进,徐苒茨,徐 健,黄珉皓
(1.国网上海市电力公司浦东供电公司,上海 200122;2.复旦大学计算机科学技术学院,上海 201203;3.网络信息安全审计与监控教育部工程研究中心,201203;4.上海东捷建设(集团)有限公司,上海 201203)
居民用户用电的聚类分析
张进1,徐苒茨2,3,徐健4,黄珉皓4
(1.国网上海市电力公司浦东供电公司,上海200122;2.复旦大学计算机科学技术学院,上海201203;3.网络信息安全审计与监控教育部工程研究中心,201203;4.上海东捷建设(集团)有限公司,上海201203)
摘要:认为新一轮的用电增长引发的问题和矛盾严重威胁到电力系统的安全运营。电力部门必须加强对于用电情况的分析和预测,妥善地规划电力系统的建设和发展。居民用户是用电群体中最具代表性和规律性的一类,针对这些问题和矛盾,提出了对居民用电情况进行分析。而在分析过程中,采用了聚类算法。实验结果表明居民用户用电存在明细的规律,并总结出了规律性的结论。
关键词:负荷分析;用电分析;数据挖掘;聚类分析
近年来,随着改革开放的进一步深化,企业数量大大增加,居民生活质量得到了长足进步,从而导致了新一轮的用电增长。与此同时,国内还长期面临着电网最大负荷逐年快速增长,谷峰差增大,负荷率持续下降,高峰期电力供应紧张等一系列问题,这给电网安全运营造成了很大的威胁。为应对这些情况带来的挑战,首先,电力部门要保证电力出力足够,尽量满足最大负荷的需求;其次,电力部门必须要准确地预测各地区各区域的用电峰谷,制定高效的发电、输电计划,合理地规划电力系统的建设。当然,这些工作的顺利进行离不开详细、全面的负荷分析。本文没有采用传统的统计学分析方法,而是使用了更高效、更深入的数据挖掘分析方法。通过对居民用户的用电数据进行聚类,分析得出不同居民的用电习惯,从而总结出居民用电的规律以及用电的峰谷情况,以此来做出预测,改变发电、输电计划或者指导阶梯电价的调整。
1相关工作
近些年来,由于用电高峰等电力问题带来了巨大的压力,促使相关部门、企业开始了对电力负荷更深入的研究和分析,以便于根据问题做出相应的调整和改善[1]。但这样的研究多集中于针对全局的数据或是针对少量的局部数据,几乎没有涉及大规模且全面的局部数据(全局指电力总公司或者大的台区,局部则指每家每户)。由于全面、细粒度地采集数据需要大量人力、时间,并且受限于隐私和设备。况且,各个地方的用电方式和习惯都不尽相同,所以抽样分析也难以实现。电力部门需要自上而下地进行变革:智能电网的普及为研究提供了良好的条件。每家每户的电表都留有数据采集功能,能够自动地在每天的固定时段将数据上传到台区,台区负责收集数据并将数据发送到数据收集服务器。这样的变化不仅带来了人工成本的锐减,而且避免了抄表带来的时间误差、数据误差、数据丢失等问题。
就分析方法而言,可以采用不同于统计或者数学的方法,如文献[2,3],而是采用了基于数据挖掘的知识获取的模式。在通常情况下,知识发现是由以下步骤迭代组成[4]:
(1) 数据清理(消除噪声数据);
(2) 数据集成(组合各种数据源);
(3) 数据选择(从数据中提取用于分析工作相关的字段);
(4) 数据变换(将数据归一化处理,便于挖掘);
(5) 数据挖掘(最重要步骤);
(6) 模式评估(根据某种兴趣度度量,对挖掘出的结果进行评估);
(7) 知识表示(通过知识表示技术,表达挖掘到的知识)。
数据挖掘是知识发现的核心。运用在电力系统可以帮助电力部门发掘更深层次的知识和规律。文献[5-7]都运用数据挖掘的方法来对负荷进行分析。神经网络在负荷分析中占有了主导的地位,但在面对数量庞大并且杂乱无章的居民用户用电数据时,很难找到规律的、完备的数据集来学习,从而导致整个神经网络分析过程受到严重的影响。所以本文采用了聚类这种无监督学习的分析方法。由于聚类分析往往是针对大数据进行的,所以在负荷分析领域采用较少。而本文主要是对居民用户的用电数据进行聚类分析,尚没有针对这项工作的其他研究。
在聚类算法的选择上,选择了K-means这种实用、高效的聚类算法,而在实验或者实际工作中可能面对更为庞大的数据时,可以考虑采用基于K-means的模拟退火算法来增加效率[8];而在面对噪声较多的数据时,可以考虑使用k-δ-means算法来过滤尽可能多的噪声点[9]。
2准备工作
根据分析知道,分析工作是按照知识获取的步骤进行的。在真正地执行聚类算法之前,必须要将数据清理、数据集成、数据选择以及数据变换这几个必要的步骤全部完成。
2.1数据清理
取得了某几个台区居民用电的真实数据,称之为原始数据。原始数据中记录的是电表的读数,需要的则是用电量数据。通常情况下,电表读数序列应为非严格递增序列,所以用电量序列就应该非负。如果出现某一天的用电量为负值,则该数据发生异常。经过仔细辨别后发现,此类异常有两种可能性。
(1) 用户换表会导致异常
图1所示即为换表异常,19日之前的电表读数是正常的非严格递增序列,而19日之后的读数大幅度减少至接近于0,而且也呈现出递增趋势。当出现该类情况时,直接采用换表之后第一天的读数作为换表前一天的用电量,而换表之后的用电量仍可以采用常规的计算方法。

图1 换表导致的电表读数异常
(2) 错误的电表读数也会导致用电量成负值
图2所示的情况可能是在6~8号期间电表出现故障,导致上传的电表读数异常。但跟换表异常不同的是,无法找到一个能够直接替代该异常用电量的值,而只能通过发生异常前后正常的数据来计算得出异常点可能的读数。可以用发生异常后第一天的读数减去异常发生前一天的读数并除以连续异常的天数来近似作为用电量。

图2 电表故障导致的异常
除了负值异常之外,数据还存在着一些噪声数据,这些多是因为电表故障导致的。针对噪声点,通常都会将其舍弃,用噪声点前后数据的平均值取而代之。
2.2数据变换
由于数据比较简单,数据集成以及数据选择的工作在这里就不做赘述。接下来需要对处理过的数据进行变换。不同台区读取电表读数的具体时间不同、记录用电的方式不同、保存数据的字段不同,导致了很多表单的字段内容大相径庭,所以需要对数据进行规整,使得用电数据的规格统一,包括负荷单位统一、时间单位统一以及用户单位统一。由于K-means算法的输入只能是向量集,所以还需要将电量数据变成可以聚类的向量。本次实验会用到以下向量变换的策略:首先将每个用户某个月的用电数据按周一、周二到周日相加,然后除以累加的次数得到平均值并将这些平均值构成七维向量(每周7天)。
2.3准备工作的必要性
由于开展的是全新的工作,所以还没有权威的数据集供实验使用,而收集到的数据也会面临着数量和质量的问题。为了保证实验的严谨性及正确性,必须对数据进行严格地清理及修正。高质量的数据集也为今后的研究奠定基础。
3实验过程
实验选用R语言作为实验语言, 其内建的各种统计学、数据挖掘及数字分析功能,包括了聚类分析需要的各种算法内库,很好地契合了本次的研究工作。
3.1算法k值的选取
K-means中的k值表示簇的数量,意味着会将数据划分成k个具有相似特征的点集。但由于用电行为复杂多样,用电的特征不够明确,加之对于聚类结果也无法做出详细地预测,所以必须经过一定的实验才能确定k的取值。
可以通过在某组固定数据下测试使用不同k值所得到结果的质量来衡量。选取6月份的用电数据,赋予其不同的k值,并按照以周为周期进行聚类,得到的结果参数如表1所示。表1中,withSS表示聚类后的平方误差,betSS表示聚类前后平方误差的差值。
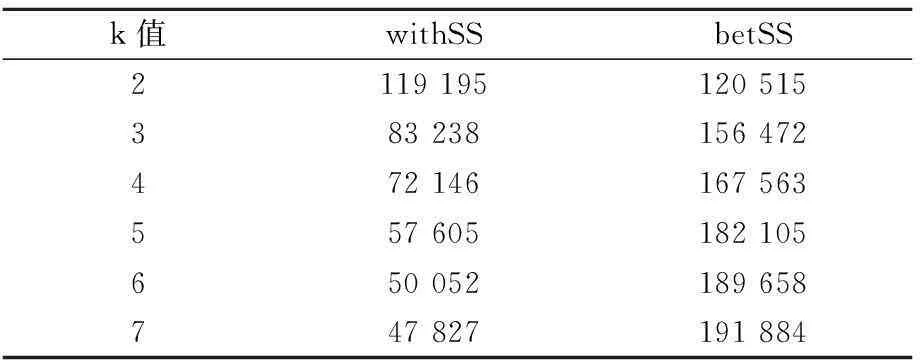
表1 不同k值的结果参数
由表1中可以明显的看出,随着k值的不断增大,聚类的效果也会逐步提升,但考虑到k-means算法的效率跟k值成正比,而且当k=3时,聚类的效果有非常明显的提升,所以选定k=3作为实验的参数。
3.2以周为周期的聚类
取定k=3后,分别对1~10月的用电数据进行以周为周期的聚类分析(11、12月数据缺失)。下面列举了3、7、10月的聚类结果图(其中指μi簇i的中心点),如图3~图5所示。

图3 3月聚类结果折线图
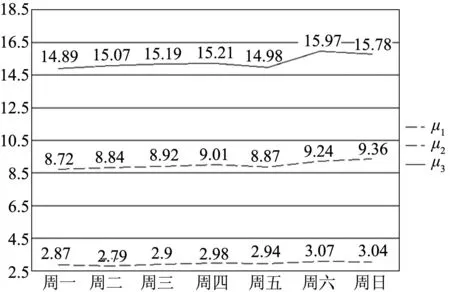
图4 7月聚类结果折线图

图5 10月聚类结果折线图
根据图3~图5,发现对每个月数据聚类得到的3个簇的中心都呈现出明显不同的3个层次:μ1各个维度上的数值基本都位置1.0~3.0之间,μ2各个维度上的数值都位于3.0~6.0之间,μ3各个维度上的数值都位于6.0以上。这说明了居民用户用电存在着显著的用电水平差异,而导致这种差异的原因可能在于每个家庭的组成不同以及家用电器使用情况的不同等。经过仔细观察,发现无论用户的用电水平如何,其周末的用电量都会有不同程度的提升,这是完全符合逻辑的。
接下来,将每个月聚类得到的所有维度上的值相加取平均数;这样每个月就会有3个值,以此来代表各个月3个层次用电水平的平均值,并将前10个月的平均值按类绘制成如图6所示。
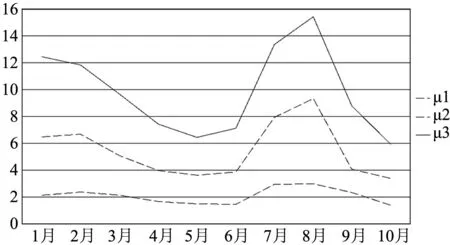
图6 均值折线图
根据图6,发现以年为周期的用电情况呈现出显著的规律:冬天气温低,需要用电取暖,所以1月和2月的用电量较高,第一类用户对低气温并不敏感;夏天气温高,需要用电降温,所以6月的用电量开始升高,到7月、8月达到极致,9月开始降低,第2、3类用户对高温天气极其敏感,就连对低温不敏感的第一类用户的用电量也有一定幅度地提升。
3.3聚类的必要性
通过聚类分析得到了实验结果,可能部分的结果也能够通过其他的分析方法来获得,比如统计学方法。但这并不能取代聚类对于分析居民用户用电的作用。通过聚类可以清晰地了解到用户用电的行为模式,属于不同模式的用户拥有不同的用电习惯,而这种模式的识别是统计学方法难以做到的,因而聚类工作的重要性毋庸置疑。
4结语
根据实验结果,可以总结出以下规律:居民用户用电情况会受到天气尤其是气温的严重影响,在低温情况下即在冬季时间段内,中高档用电水平用户的用电量会有显著的增加,在高温情况下即在夏季时间段内,所有用户都会有很大的用电量提升。而在不考虑天气的情况下,居民周末的用电量会高于平时。
通过对居民用户的用电数据进行聚类分析,能够划分并得到居民用户用电量位于的层次,这有助于了解用户的用电模式,掌握用户的用电水平。同时,电力部门可以通过结论来预测用电的高峰时间,以此来调整阶梯电价,并指导用户避开用电高峰,从而有效地抑制谷峰差的增大,缓解高峰期电力供应紧张带来的压力。
但在分析过程中,仍存在以下不足:噪声数据的处理不够精细,导致了信息的部分流失;难以识别更多更细致的用电模式。根据出现的问题,今后的工作可以围绕以下两点进行:制定更精确的噪声识别模式并使用更科学的手段对噪声数据进行处理,如b样条曲线等; 使用更小粒度的数据,增加k值。
参考文献:
[1]赵希正. 中国电力负荷特性分析与预测[M]. 北京:中国电力出版社,2002.
[2]陶莉,肖晶. 负荷特性分析方法的研究[J]. 电力需求侧管理,2003,5(4): 30-21.
TAO Li, XIAO Jing. Analysis research of load characteristic[J].Power Demand Side Management,2003,5(4):30-21.
[3]徐东升、杨巍. 基于SPSS的短期负荷特性分析及其预测研究[J]. 电力系统保护与控制,2009,37(21):147-151.
XU Dong-sheng, YANG Wei. Application of SPSS in characteristic of short load and its forecasting[J].Power System Protection and Control,2009,37(21):147-151.
[4]MICHELINE KAMBER, JIAN Pei. 数据挖掘概念与技术[M]. 北京:机械工业出版社,2012.
[5]高智. 数据挖掘技术在电力系统中的应用[J]. 华东电力,2001,29(12): 4-7.
GAO Zhi, XU Zheng. Data mining and its application in power system[J].East China Electric Power,2001,29(12):4-7.
[6]李智勇,吴晶莹. 基于自组织映射神经网络的用户负荷曲线聚类[J]. 电力系统自动化,2008,32(15): 66-70.
LI Zhi-yong, WU Jing-ying, WU Wei-lin, et al. Power customers load profile clustering using the SOM neural network[J]. Automation of Electric Power Systems,2008,32(15):66-70.
[7]耿亮,吴燕. 电力数据挖掘在电网各领域间的应用[J]. 电信科学,2013(11): 127-130.
GENG Liang, WU Yan. The application of power data mining within and between the grid fields[J].Telecommunications Science,2013 (11):127-130.
[8]陈慧萍. 基于模拟退火思想的优化k-means算法[J]. 河海大学常州分校学报,2006,20(4):29-33.
CHEN Hui-ping, HE Hui-jing, CHEN Lan-feng, et al. Optimized k-means algorithm based on simulated annealing[J]. Journal of Hohai University Changzhou,2006,20(4):29-33.
[9]SHAI Ben-David. Clustering in the Presence of Background Noise[C]. ICML2014.
(本文编辑:严加)
Clustering Analysis of Residential Electricity Utilization
ZHANG Jin1,XU Ran-ci2,3,XU Jian4,HUANG Min-hao4
(1. State Grid Shanghai Pudong Electric Power Supply Company, Shanghai 200112, China;2. School of Computer Science, Fudan University, Shanghai 201203, China;3. Engineering Research Center of Cyber Security Auditing and Monitoring,Ministry of Education, Shanghai 201203, China;4. Dongjie Construction (Group) Co., Ltd., Shanghai 201203, China)
Abstract:With the further development of the reforms and open policy, the national economy, science and technology have been improved remarkably. However, the electricity consumption increase leads to a series of contradictions and problems, and poses threat to the safe operation of power syste. In order to cope with these problems and contradictions, the electricity sector must strengthen the analysis and forecasting of electricity, make the proper planning for the construction and development of power system. Because residential utilization is the most representative and regular part of electricity consumption, this paper mainly analyzes residential electricity, mainly by means of cluster algorithm. The results show that resident users consume electricity in detailed rules, and the regularity of the rules is summarized and the conclusions are drawn in this paper.
Key words:load analysis; electricity analysis; data mining; cluster analysis
DOI:10.11973/dlyny201602006
作者简介:张进(1971),高级工程师,主要从事电力营销管理工作。
中图分类号:TM73
文献标志码:B
文章编号:2095-1256(2016)02-0180-05
收稿日期:2015-04-11
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
信息通信技术(2015年6期)2015-12-26
西安工程大学学报(2014年2期)2014-02-28
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
