
国内图书情报领域基于图书推荐的共词聚类分析*
2016-06-17 08:24:09赖思银广东石油化工学院图书馆广东茂名525000
图书馆学刊 2016年3期
赖思银(广东石油化工学院图书馆,广东茂名525000)
国内图书情报领域基于图书推荐的共词聚类分析*
赖思银
(广东石油化工学院图书馆,广东茂名525000)
[摘要]选取CNKI数据库中收录的图书情报领域以“图书推荐”为主题的文献为数据来源,运用SATI进行词频的统计构建相关矩阵,基于共词分析法,借助SPSS软件进行聚类分析和多维尺度分析,结果表明目前国内图书情报领域图书推荐的研究热点主要集中于4个方面,即读者借阅兴趣模型构建、数据挖掘与处理、图书推荐服务与阅读推广、图书推荐系统应用与推广,并对研究主题进行了详细解析,为国内图书情报领域图书推荐的研究提供参考。
[关键词]图书馆学情报学图书推荐共词分析SPSS
1 引言
图书馆馆藏资源作为科学情报传递工作的物质基础条件,拥有着海量的优质资源,这些资源是人类长期积累的一种智力资源。近年随着计算机信息技术的高速发展,这些传统的智力资源也在向数字化、网络化方向发展,推动了图书馆服务的时空延伸性。然而在海量的资源面前,读者却很难从中发现自己感兴趣的信息资源,或者说很难呈现读者真正想要的资源,这与信息化发展过程中的个性化、智能化等特点相悖。以读者检索图书文献为例,当读者在检索系统输入关键词进行检索时,服务端被动接受读者提交的数据进行反馈,这个过程并没有结合读者以往的历史记录等信息进行综合考虑读者需求的兴趣或个性偏好,导致这种服务模式显得过于单一与低效,同时也降低了图书文献的利用率。针对这一问题,在当代图书馆发展过程中关于服务个性化、智能化的问题探讨越来越多,个性化、智能化的图书推荐服务正成为图书馆界一个研究热点,在此背景下,笔者基于共词分析法对国内图书情报领域关于“图书推荐”的研究主题进行了整理分析,借助SPSS软件进行数据的分析与展显,以期为国内图书情报领域的图书推荐研究提供参考。
2 数据来源
笔者所使用的数据来源于CNKI数据库,设定检索字段为“图书推荐”,检索学科类别设定为“图书情报与数字图书馆”,检索时间为2015年10月10日,共检索出179条记录,借助Excel、SATI3.2等软件进行关于“图书推荐”为主题的高频关键词进行抽取和构建共现矩阵、相关矩阵和相异矩阵,通过SPSS软件进行聚类分析和多维尺度分析,其结果可为国内图书情报领域关于“图书推荐”的研究提供一定的参考。
3 数据统计分析
3.1词频统计分析
共词分析法是一种常用的内容分析方法,其原理是统计一组文献的主题词两两之间在同一篇文献出现的频率,便可形成一个由这些词对关联所组成的共词网络,根据网络内节点之间的远近便可以反映主题内容的亲疏关系,通过研究文献主题词对象,利用应力系数、聚类分析等统计分析方法,把众多分析对象之间错综复杂的共词网状关系简化为以数值、图形直观地表示出来的过程[1]。关键词是一系列主题词的逻辑组合,常用于科技论文、科技报告和学术论文的文献主题思想内容表达,是文献主题概念实际意义的自然语言词汇,其主要功能是便于读者查阅和检索文献[2]。对关键词的词频统计和共词分析能够客观反映国内关于“图书推荐”研究的发展情况。
运用SATI3.2软件对CNKI中图书情报领域中检索出的关于“图书推荐”的文献进行关键词抽取并进行频次统计,在检索到的179篇文献中共含关键词2363个,经过合并意思相近、去除无实际意义关键词等数据处理手段后,最后选择了频次统计≥7的21个高频关键词进行分析研究,如表1所示。

表1 国内图书情报领域“图书推荐”研究论文高频关键词
通过对高频关键词进行两两统计,统计选取的21个关键词在文献中出现的总次数,构建一个21*21的共词矩阵。由于共词矩阵在表现各关键词之间频率高低的时候存在单一性,为了消除这种单一性,更好地体现各关键词之间的内在联系,将共词矩阵转换为相关矩阵[3]。相关矩阵也叫相关系数矩阵,由矩阵各列间的相关系数构成。经转换后的相关矩阵数值在[0,1]区间,数值越接近1,表示两关键词之间的相似度越大,距离越近。数值越接近0,表示两关键词之间相似度越小,距离越远。由于在统计的过程中存在较大的误差,相关矩阵中的稀疏性明显,为了进一步减少误差,更好地进行下一步的分析研究,将相关矩阵转化为相异矩阵。相关矩阵如表2所示,相异矩阵如表3所示。

表2 相关矩阵(截取部分)

表3 相异矩阵(截取部分)
3.2聚类分析
聚类分析(Cluster Analysis)是一个将数据集中的所有数据,按照相似性划分为多个类别(Cluster,簇:相似数据的集合)的过程。聚类分析要求同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。将表3相异矩阵导入SPSS软件,采用系统聚类中的Ward法进行聚类分析,Ward聚类方法的思想是同类内离差平方和较小,不同类之间偏差平方和较大。设定聚类距离为欧氏距离,分别得到聚类凝聚表和聚类树状图,聚类凝聚表如表4所示。
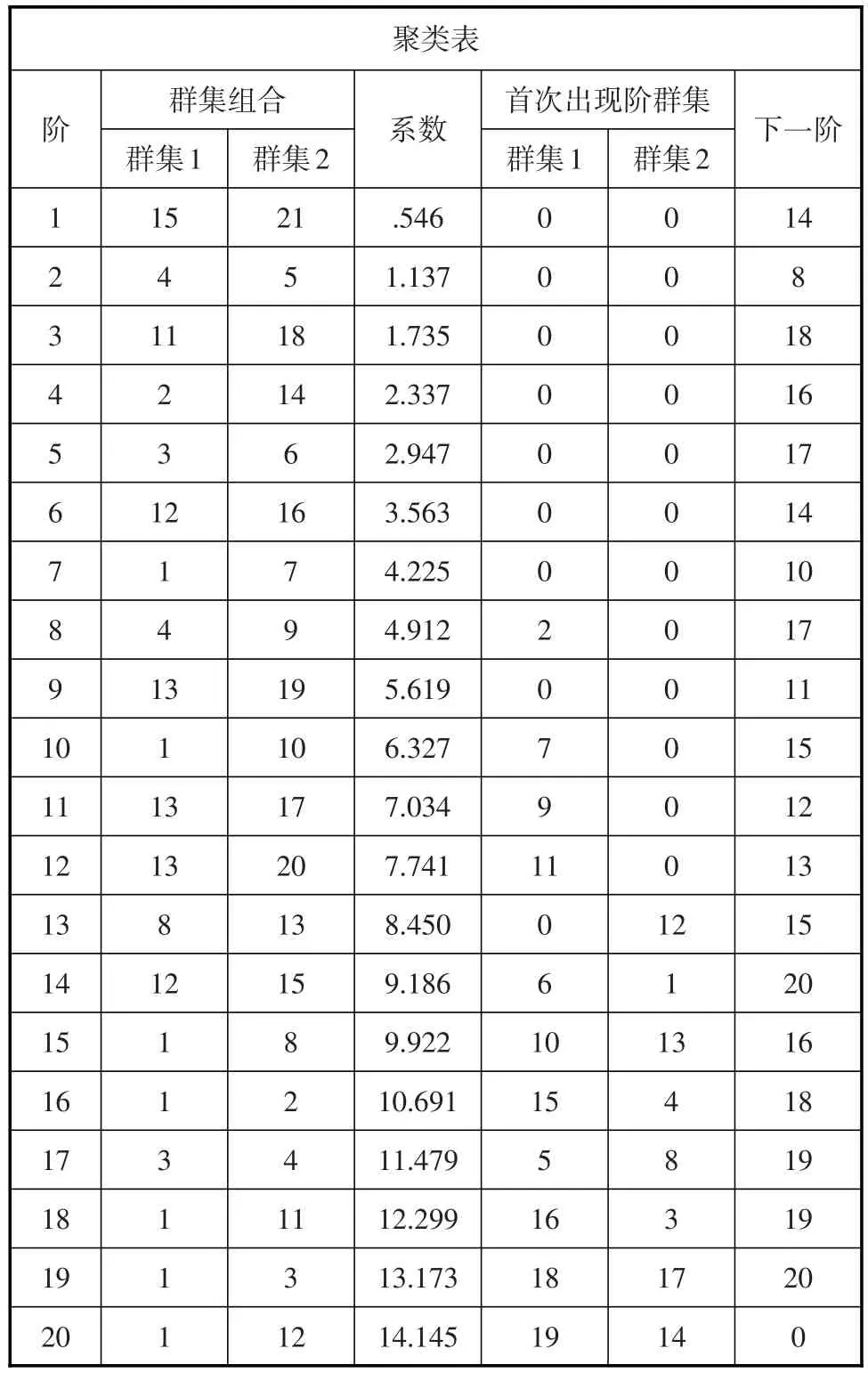
表4 层次聚类分析的凝聚状态
通过观察高频关键词层次聚类分析的凝聚状态表可知,第一步由关键词15(决策树)21(兴趣模型)聚成一类,然后在第14步和关键词12(个性化图书推荐)聚成一类,关键词12又在第6步和关键词16(聚类)聚成一类,接下来就是关键词15和关键词21聚成的类与关键词12和关键词16聚成的类再进行聚合形成新的聚类,其他聚合过程依此类推,其聚类结果可见聚类树状图2。

图2 高频关键词层次聚类分析树状图
观察高频关键词层次聚类分析的凝聚状态表和高频关键词层次聚类分析的树状图可以发现:国内图书情报领域“图书推荐”研究热点主要集中于“读者借阅兴趣模型构建”“数据挖掘与处理”“图书推荐服务与阅读推广”“图书推荐系统应用与推广”4个主题,具体分析笔者将在后文进行阐述。
3.3多维尺度分析
多维尺度分析(MDS),是基于研究对象之间的相似性或距离,将研究对象在一个低维(二维或三维)的空间形象地表示出来,进行聚类或维度分析的一种图示法。通过多维尺度分析所呈现的空间定位图,能简单明了地说明各研究对象之间的相对关系[4]。
将表3的高频关键词相异矩阵输入SPSS进行多维尺度分析,选择PROXSCAL分析模型,拟合结果如表5所示。其中标准化初始应力系数(Stess)为0.12612,效果为好;离散所占比例(D.A.F.)为0.87388,拟合程度效果较好。
多维尺度分析的变量二维分布图可以根据各高频关键词之间的距离远近较全面地反映出各高频关键词之间的联系,如图3所示。通过观察图3变量二维分布图的结果,可以看出图中反映的结果和聚类分析中凝聚状态表和树状图反映的结果比较符合。

表5 多维尺度分析的拟合度结果

图3 多维尺度分析的变量二维分布图
4 图书推荐研究主题分析
4.1I类:读者借阅兴趣模型构建
读者借阅兴趣模型是指读者在某个时间周期内相对稳定的图书借阅信息需求的形式化描述,反映了读者在一段时间内的兴趣倾向。读者借阅兴趣模型构建是个性化图书推荐服务的关键所在,可以对服务系统产生直接的影响,近年来读者借阅的兴趣模型构建受到越来越多的研究者重视。马华[5]在研究了某高校图书馆的读者数据后利用数据挖掘中的决策树方法,对不同的读者进行了阅读兴趣的分类,构建了基于数据挖掘技术中决策树算法的读者阅读兴趣模型,为读者提供了个性化的图书推荐服务。
4.2II类:数据挖掘与处理
数据挖掘技术是指通过算法从大量数据中深层挖掘其中隐藏的共性规律的过程,并通过建立个性化的推荐系统为用户提供主动的信息推荐服务。由于数据挖掘具有强大的信息整理与分析能力,越来越多的商业用户把数据挖掘技术用于知识发现上面。数据挖掘技术应用于图书馆则是利用了图书馆现有的业务数据库里的读者借阅数据,通过对这些数据进行挖掘与分析,可以发现读者借阅图书的兴趣偏好与共性,进而在读者的个人数字图书馆页面进行书目推荐。周玲元[6]提出了一种改进的Apriori算法在高校图书推荐服务中的应用方法,通过改进的数据挖掘算法,把数据库里潜在的联系转化成显性知识进行推荐服务,提高了服务质量。
4.3III类:图书推荐服务与阅读推广
在信息高速发展的推动下,读者对于信息和阅读的需求也越来越趋于向个性化、多元化的方向发展,图书馆应该通过深入调查读者的内在需求,充分了解读者对于图书偏好等信息,制定符合读者的书目推荐服务,有的放矢地开展图书馆的图书推荐服务和阅读推广服务。
4.4IV类:图书推荐系统应用与推广
图书推荐系统的构建主要是基于关联规则的数据挖掘,利用读者借阅数据,将读者的借阅数据转化成适合个性化需求的读者数据,并在图书推荐系统中进行可视化的技术应用。图书推荐系统的技术应用可以为读者提供图书借阅的主动引导,提高借阅效率,具有重要的研究意义。我国比较成熟的图书推荐系统主要包括:国家科技图书文献中心系统(NSTL)、中国高等教育文献保障系统(CALIS)、国家科学数字图书馆(CSDL)。
5 结语
通过对国内图书情报领域图书推荐的高频关键词进行聚类分析、多维尺度分析,笔者发现国内图书情报领域关于图书推荐的研究集中于“读者借阅兴趣模型构建”“数据挖掘与处理”“图书推荐服务与阅读推广”“图书推荐系统应用与推广”4个方面。总体来说,国内图书情报领域对于图书推荐的研究侧重于理论探讨,而在技术和实践应用方面的研究有所欠缺。另外研究力度不均衡,个别主题存在较多重复研究,而在应用推广、图书借阅信息的数据挖掘应用等主题上,研究内容不够深入。国内图书情报领域的学者应加强对图书推荐的创新性和持续性研究,开拓新的研究主题,重点探讨图书推荐的计算机技术手段的应用及阅读推广方法的有效推广等方面的应对策略。
参考文献:
[1]冯璐,冷伏海.共词分析方法理论进展[J].中国图书馆学报,2006(2):88-92.
[2]刘涛,刘玉英,杜亮.近5年图书馆学研究热点分析基于共词分析视角[J].图书馆学刊,2012(10):122-125.
[3]郭春侠,叶继元.基于共词分析的国外图书情报学研究热点[J].图书情报工作,2011(20):19-22.
[4]翁胜斌.CNKI数据源的关键词共现分析与多维尺度分析的现实方法[J].现代情报,2013(4):27-38.
[5]马华,等.决策树分类算法在个性化图书推荐中的应用[J].软件,2012(8):100-104.
[6]周玲元,段隆振.改进的Apriori算法在高校图书推荐服务中的应用研究[J].图书馆学研究,2013(2):89-91.
赖思银男,1978年生。硕士,馆员。研究方向:数据库、数据分析、数字图书馆。
(由稿日期:2015-12-03;责编:杨新宽。)
[分类号]G252.1
*本文系广东省茂名市科技计划项目“多维度高校图书馆数据仓库构建研究”(项目编号:20150350);广东石油化工学院青年创新人才培育项目“基于数据挖掘的图书馆信息推送系统研究”(项目编号:512102)成果之一。
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:49:18
现代装饰(2022年4期)2022-08-31 01:42:30
现代装饰(2022年3期)2022-07-05 05:59:04
大众投资指南(2021年35期)2021-02-16 01:06:26
图书馆建设(2018年5期)2018-07-10 09:46:40
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
小天使·一年级语数英综合(2015年10期)2015-10-14 06:37:12
中国教育信息化(2015年24期)2015-08-22 12:21:56
阜阳职业技术学院学报(2015年4期)2015-05-17 03:58:53
