
数据挖掘在高校图书馆服务中的应用探析
2016-06-16 02:47陈洁
大学图书情报学刊 2016年2期
陈 洁
(安徽大学,合肥 230601)
数据挖掘在高校图书馆服务中的应用探析
陈洁
(安徽大学,合肥 230601)
摘要:高校图书馆服务的进一步发展需要更多信息的支持。数据挖掘技术作为一种信息分析的辅助技术可以应用到高校图书馆服务中。数据挖掘利用聚类分析、关联性分析等手段,可帮助高校图书馆对客户进行分类,发现各类客户的特征,采购客户需要的资源并开展有针对性的服务。高校图书馆应用数据挖掘在经济、技术和运行方面都是可行的。
关键词:高校图书馆;数据挖掘;聚类分析;关联性分析;个性化服务
1高校图书馆服务对数据挖掘的需求
随着高校图书馆越来越多地参与到教学与科研过程中,其服务水平也需要有相应提高。当前高校图书馆追求以客户需求驱动图书馆服务,使用户的满意度提高,从而以最低成本实现对教学、科研最有效的支持[1]。
以用户需求为驱动的图书馆服务流程如图1所示。

图1用户需求驱动的图书馆服务流程
首先,高校图书馆通过各种途径收集用户(包括潜在用户)的相关信息,实现用户的识别。这里的潜在用户是指没有图书馆服务记录的学生。其次,图书馆根据相关信息对用户进行分类,体现用户群之间的差异。再次,图书馆对区分后的不同用户群进行分析,了解其特点和需求。最后,图书馆根据所了解的需求进行纸质和电子资源的采购[2],根据用户的特征提供有针对性的定制服务。采购和服务获得的信息以及最终绩效数据被记录,并在对用户进行识别、区分和特征分析的过程中使用。
由此可以看出,全流程的各阶段都有大量的数据需要分析,而很多时候理想的分析结果隐藏在数据中,需要专业人员和技术来实现这一过程。但是,基于现在各高校图书馆人员的专业结构和职位分配,相当多的信息分析难以完成。因此,必须寻找一种途径便捷地实现数据的分析。
数据挖掘被称为数据库中的知识发现,它利用神经网络、模式识别、归纳逻辑的方法,从大量数据中挖掘出未知的、有价值的一些模式和规律,归纳成为知识后供使用。由此可见,数据挖掘正是高校图书馆所需要的数据分析工具。借助于这种工具,高校图书馆才有可能真正实现需求驱动服务[3]。
2数据挖掘在高校图书馆服务中的具体应用
数据挖掘在高校图书馆服务中的不同阶段有着不同应用。
2.1 数据收集阶段
在这一阶段要对所收集的数据进行处理,提高数据的质量,有利于后续的数据挖掘。例如,安徽大学研究生和本科生专业非常多,因此,用户数据中“专业”属性会有很多种取值,从而增加后续分析的难度。结合国家专业学科分类,“专业”属性可以向更高层次泛化,形成替代属性“学科门类”,各数据在该属性只会有13种取值,有利于后续的挖掘。根据图书馆数据采集的情况,本阶段还可以进行数据清洗、数据消减、数据集成与转换。
2.2 用户分类阶段
利用数据挖掘中的聚类分析技术,可以十分方便地对高校图书馆用户进行分类[4]。由于这种分类建立在前期大量数据的基础上,所以分类结果更为科学和准确。例如高校图书馆根据如下算法进行分类:(1)建立包括用户和潜在用户的用户集CW,其中每个用户对象为xi;(2)在CW中任选k个典型对象构成聚类中心集合OW,其中每个对象oj对应为Cj类的中心;(3)计算CW中每个用户对象xi到OW中每个对象oj的距离。由于每个用户对象的各属性是混合类型,所以不使用欧式距离,而如果利用k-modes算法的相异度计算公式,又无法体现数值型属性间的实际差异,所以要对算法进行相应的修改[5]。最终,将每个xi归入距其最近的oj所在的类Cj;(4)计算聚类是否收敛,如果收敛则聚类完成。如果未收敛,重新计算各类的中心,并重复步骤c和d。
2.3 分类识别阶段
在该阶段主要可以应用数据挖掘中的分类识别和关联性分析技术。
数据挖掘中的分类识别是对样本数据进行分析,找出其中的分类规则,有利于对所有对象进行分类,进而针对每类对象采取相应措施。高校图书馆可以利用分类中的相关思想,对聚类的结果进行分析,识别各类的特征,更重要的是可以识别出各类对象中影响结果的关键因素。
以安徽大学为例,通过整理数据库得到以下数据:
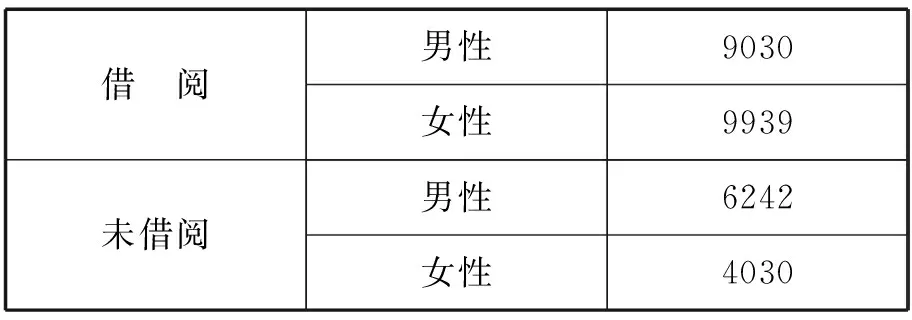
表1 安徽大学2012-2013学年借阅数据
可以通过相应算法得到性别对借阅与否的重要性。
设结果属性A可以取m个不同值,对训练样本S可分为Ci,i∈[1,2,…,m],Si为Ci中样本个数。设定属性B取v个不同的值,训练样本分为Sj,j∈[1,2,…,v],设Sij为Sj中属于Ci的样本数,则利用B对A的影响计算为[6]
Gain(B)=I(S1,S2,…,Sm) -E(B)

设属性A为是否借阅,C1为借阅,C2为不借阅;设属性B为借阅者性别,S1为男性,S2为女性,则根据上表和计算方法
所以,Gain(B)= I(S1,S2) - E(B)=0.1
所以性别对是否借书的判断结果的信息增益为0.1,而利用同样计算性别对借书多少的信息增益为0.01,所以性别更多影响是否借阅,而不会影响借阅者借阅量的多少。
关联性分析主要用于发现数据之间的联系,从而建立相应的模式,有利于针对性的决策。数据挖掘中的关联性分析主要是一种无指导的学习,高校图书馆在应用中可以将其变换为有指导的学习,发现服务对象的一些行为模式,从而实施有针对性的服务,提高最终的效果。
以安徽大学为例,以80位学生的相关信息为训练样本,分析与借阅多少相关的关联规则。每条信息包括年级、学科种类、借阅情况。为了简化计算难度,学科种类和借阅进行了泛化处理,其结果构成以下四个集合:
年级{G1(一年级),G2(二年级) ,G3(三年级) ,G4(四年级)}
学科种类{D1(理科),D2(文科)}
借阅情况{B1(多),B2(少)}
根据训练样本得到表2,如下所示:

表2 单项集支持度
设置支持度最小为8则表2中没有任何项集被排除,因此通过组合得到表3,如下所示:

表3 二项集支持度
因为支持度应大于8,所以得到筛选后的集合进一步筛选和组合得到表4。
{G2,D1},{G2,D2},{G2,B1},{G2,B2},{G3,D2},{G3,B1},{G4,D2},{G4,B2},{D1,B1},{D1,B2},{D2,B1},{D2,B2}

表4 三项集支持度
所以最后得到集合{G3,D2,B1}和{G4,D2,B2}
计算G3&D⟹B1的置信度
Confidence(G3&D2⟹B1)=
计算G4&D2⟹B2的置信度
Confidence(G4&D2⟹B2)=
因为有较高的置信度,所以根据训练样本可以得到关联规则G3&D2⟹B1和规则G4&D2⟹B2,即三年级文科生会借阅很多书籍,而四年级文科生借书较少。
2.4 数据挖掘结果的应用
高校图书馆可以利用数据挖掘的结果,在采购、服务等方面做出更为有效的决策。根据上文所得到的分类识别结果,安徽大学图书馆可以尝试实施有针对性的措施。例如,根据上文的计算结果,性别对学生借书的意愿有较大影响,因此可以针对男性和女性制定不同的宣传策略和激励措施,以提高学生借阅量;针对三年级文科生借阅量大的情况,可以更多地了解他们的需求,听取他们对图书馆的意见,比如说图书的采购、室内的布局、桌椅和书架排列等,从而更好地完善图书馆工作;针对四年级文科生,可以联系其学习、实习和书写论文的实际情况,推荐相应的书籍和资料,以便更好地体现图书馆的服务功能。
3高校图书馆应用数据挖掘的可行性分析
虽然数据挖掘已经是一种成熟的技术,但是如果想应用到图书馆服务中,还需要从技术、经济、实际运行等方面进行可行性分析。如果数据挖掘技术难以获得或者不成熟,数据挖掘技术实施的成本高而收益低,实际运行会产生不好的影响,则高校图书馆没有实施该技术的必要。
3.1 技术可行性
目前,数据挖掘技术已经应用到通信、零售、金融、制造等多个领域,大量企业在其经营管理过程中使用了该技术。在这些企业的使用过程中,基本上没有出现因为技术本身缺陷造成损失的情况,因此,数据挖掘技术较为成熟,应用该技术的技术风险较小。另一方面,由于目前社会对大数据分析极为重视,所以数据挖掘的各种应用发展较快。有相当多的软件或者系统已经可以实现对大量数据的挖掘[7],也有一些企业提供数据挖掘的相关服务。高校图书馆可以根据自身情况,选择由自己完成或者外包数据挖掘工作。因此,高校图书馆获得数据挖掘技术并不困难。
3.2 经济可行性
在成本方面,应用数据挖掘必然会导致高校图书馆成本上升。如果高校图书馆选择自己实施数据挖掘,则需要购买相应功能软件或者升级原有系统;如果图书馆选择购买第三方的数据挖掘服务,则需要支付相当的购买费用,这些都会带来额外的成本。另外,数据挖掘会增加高校图书馆系统的计算量,图书馆可能需要对原有硬件进行升级或者购买新的硬件,这会增加硬件成本。
数据挖掘的执行和挖掘结果的应用不同于图书馆传统业务,所以需要对相关人员进行有关数据挖掘方面业务的培训,以保证有足够的人员支持日常的数据挖掘业务。相关培训会带来时间和资金方面的损耗。
数据挖掘是基于大量数据的,高校图书馆必须向数据挖掘服务提供充足的、符合其要求的数字化信息[8]。因此,高校图书馆可能需要将获得的各种数据进行分析和转换,以满足数据挖掘的要求。但是应该看到,由于目前高校图书馆信息化水平较高,各种信息资源的数字化程度较高,所以在这方面的成本上升可能并不明显。
在成本上升的同时,应用数据挖掘能够从多方面为高校图书馆带来收益。首先由于数据挖掘对图书馆用户进行了有效分类,同时还提供了各类用户最真实的需求,所以图书馆能够有针对性地采购纸质资源和电子资源,避免了采购各种资源后无人使用的现象,从而有效地降低图书馆采购成本,提高采购资源的有效性。
由于数据挖掘对每一类用户进行定义性描述、分类与预测、关联性分析,所以高校图书馆能够针对每一类用户,甚至每一位用户提供定制服务。定制服务能够过滤掉用户不需要的服务和资源,提供对于用户来说最适合的服务形式和服务内容,使用户使用图书馆服务更为便捷,使用的效率和效果也有显著提高。
高校图书馆是学生必须使用的一种教辅工具,但是因为种种原因,很多学生对图书馆服务使用较少,实际上影响了学习的效果。数据挖掘通过聚类分析、分类与预测等方法对这些潜在用户群进行分析,能够提供关于潜在用户的相关知识,有利于图书馆采取相对应的措施,吸引潜在用户,提高他们对图书馆的使用率。
综上所述,实施数据挖掘会在短期内提高图书馆的成本,但是能够长期提高图书馆的服务质量,有利于图书馆服务于教学、科研目标的实现。所以,如果高校图书馆能够负担初期的成本,则实施数据挖掘在经济上是十分可行的。
3.3 运行可行性
在高校图书馆服务中应用数据挖掘,是为了更详细地定义用户的各种特征,以方便图书馆在资源采购和服务等方面的决策。数据挖掘实际上是在原有决策过程中,增加了一些决策的支撑材料,对决策过程本身影响不大,不会产生流程的重构。因此,应用数据挖掘对组织和流程的影响较小,不会有太大的实施阻力。
应用数据挖掘会对部分图书馆员产生新的知识要求,这些馆员需要进行相应的培训。但是无论是自我开发数据挖掘应用、购买数据挖掘软件还是数据挖掘服务,对馆员的培训都只是操作流程的更新或者操作技能的提高,对理论知识要求极少,培训的难度较低。因此,人员能够很快地适应含有数据挖掘的新环境,应用数据挖掘人员方面的阻力较小。因此,在图书馆服务中实施数据挖掘的运行可行性较高。
4结语
基于大数据分析的服务,是提高高校图书馆服务水平的重要途径。数据挖掘一方面能够使图书馆的服务更加有针对性,另一方面又不会对现有的流程产生太大的影响。因此在高校图书馆服务中应用数据挖掘,是一种收益大、风险小的改进方法。在实施数据挖掘的过程中,高校图书馆应该注意在原始数据的清洗、挖掘方法的选择以及挖掘结果的应用等方面加以控制,追求最优,以保证实施的最终效果。
参考文献:
[1] 陈双飞.大数据时代图书馆基于服务生命周期的客户关系管理研究[J].现代情报, 2014, 34(5):91-93.
[2] 迟春佳,毛志勇.基于数据挖掘的高校图书馆图书采购计划辅助决策研究[J].现代情报, 2009,(7):108-110.
[3] 顾倩.数据挖掘应用于高校图书馆个性化服务的探讨[J].图书馆杂志,2013,32(8):63-65.
[4] 王慧敏,贺兴时,牛四强.数据挖掘在高校图书馆中的应用[J].西安工程大学学报, 2014, 28(2):241-245.
[5] 张月琴,陈彩棠.基于新相异度量的模糊K—Modes聚类算法[J].电脑开发与应用,2012,25(5):32-34.
[6] 朱明.数据挖掘[M].合肥:中国科学技术出版社,2002:68-69.
[7] 杨建明,刘芳.基于数据挖掘的高校图书馆服务优化研究[J].情报探索,2014,198(4):25-28.
[8] 杨江丽,高凡,董若剑.基于数据挖掘的高校图书馆读者行为研究——以西南交通大学图书馆为例[J].图书馆研究,2013,43(3):106-110.
(责任编辑:朱爱瑜)
Analysis of Data Mining in the Service of the University Library
CHEN Jie
(Anhui University, Hefei230601, China)
Abstract:The further development of university library services requires more information to support. Data mining can be applied to the service of the university library as a kind of auxiliary information analysis technology. Data mining can help the university library to separate the customers, find the characteristics of various customers, purchase the right resources and provide targeted services by using clustering analysis and association analysis. The application of data mining in university library is feasible both in economy, technology and operation.
Key words:university library; data mining; cluster analysis; association analysis; personalized
基金项目:安徽省高等学校图书情报工作委员会基金项目(TGW13B16);安徽大学图书馆基金项目(TSG14B07)
中图分类号:G251
文献标识码:A
文章编号:1006-1525(2016)02-0053-05
作者简介:陈洁,女,馆员。
收稿日期:2015-10-27
猜你喜欢
青年时代(2016年30期)2017-01-20
河南图书馆学刊(2016年12期)2017-01-09
河南图书馆学刊(2016年12期)2017-01-09
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年21期)2016-10-17
科技视界(2016年21期)2016-10-17
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
