
基于词典优化与空间一致性度量的目标检索
2016-06-16 07:12赵永威李弼程
计算机研究与发展 2016年5期
赵永威 周 苑 李弼程
1(武警工程大学电子技术系 西安 710000)2(河南工程学院计算机学院 郑州 451191)3(解放军信息工程大学信息系统工程学院 郑州 450002)(zhaoyongwei369@163.com)
基于词典优化与空间一致性度量的目标检索
赵永威1周苑2李弼程3
1(武警工程大学电子技术系西安710000)2(河南工程学院计算机学院郑州451191)3(解放军信息工程大学信息系统工程学院郑州450002)(zhaoyongwei369@163.com)
摘要基于视觉词典模型(bag of visual words model, BoVWM)的目标检索存在时间效率低、词典区分性不强的问题,以及由于空间信息的缺失及量化误差等导致的视觉语义分辨力不强的问题.针对这些问题,提出了基于词典优化与空间一致性度量的目标检索方法.首先,该方法引入E2LSH(exact Euclidean locality sensitive hashing)过滤图像中的噪声和相似关键点,提高词典生成效率和质量;然后,引入卡方模型(chi-square model, CSM)移除词典中的视觉停用词增强视觉词典的区分性;最后,采用空间一致性度量准则进行目标检索并对初始结果进行K-近邻(K-nearest neighbors, K-NN)重排序.实验结果表明:新方法在一定程度上改善了视觉词典的质量,增强了视觉语义分辨能力,进而有效地提高目标检索性能.
关键词目标检索;视觉词典模型;精确欧氏位置敏感哈希;空间一致性度量;卡方模型
近年来,随着图像数据规模的增大,使得图像处理面临的环境更加复杂.虽然SIFT等[1]局部特征在图像处理领域表现出了良好的性能,但是,其特征维数较高,若采用VA-File,K-d树等一些传统的索引结构进行检索就会导致“维数灾难”现象.视觉词典模型(bag of visual words model, BoVWM)[2-3]由于其突出性能,已成为当前图像标注[4]、图像检索与分类[5-8]等领域的主要解决方法.但是,以下3个关键性问题的存在极大地限制了BoVWM模型的性能:1)关键点检测算子会产生大量的噪声点无疑会增加计算消耗、降低词典生成效率;2)当前聚类算法的局限性[9-10]和图像背景噪声的存在,使得聚类生成的词典中包含一些类似于文本信息中的“的”、“和”、“是”等“停用词”,这里称其为“视觉停用词”,严重影响了视觉词典的质量;3)传统的BoVWM模型中视觉单词间空间信息的缺失和量化误差严重等导致视觉语义表达分辨力不强.
近年来,研究人员针对这些问题做了许多探索性研究,如在过滤噪声关键点方面:Rudinac等人[11]将相互距离小于1个像素值的特征点看作相似的近邻点,然后计算其中心值作为代表性特征点,这种方法最大的缺点是计算开销大,因为它需要遍历图像的每个像素点.Jamshy等人[12]通过学习特征点对某一特定应用的先验知识来过滤大部分特征点,然而这种方法却降低了图像分类性能.而针对“视觉停用词”去除问题,Sivic等人[2]考虑到单词的信息量大小与其出现的频率有一定的关系,从而提出了一种基于词频的“停用词”过滤方法,然而,这种方法却忽略了视觉单词和目标语义概念间的相互关系.Tirilly等人[13]则根据关键点的几何性和概率隐语义分析模型淘汰无用的视觉单词,Yuan等人[14]试图以统计视觉单词组合也即“停用词组”出现的概率来滤除一些无用信息,但是却忽略视觉词组内部各单词之间的空间关系.
针对视觉单词间空间信息的缺失和量化误差严重的问题,刘硕研等人[15]采用一种基于上下文语义信息的图像块视觉单词生成算法,利用PLSA模型和Markov随机场共同挖掘单词的上下文信息.张瑞杰等人[16]考虑到图像多尺度空间与单词上下文语义共生关系,在不同的图像尺度空间挖掘单词的上下文语义信息,进一步弥补了传统BoVWM模型的空间信息不足问题.Chen等人[10]则提出了一种基于软分配的视觉词组(visual phrase)构建方法,在弥补视觉单词空间信息的同时,有效克服了传统视觉词组构建方法[17]导致的特征信息丢失问题.而为了减小量化误差,Gemert等人[18]提出了视觉单词不确定性(visual word uncertainty)模型,该模型同样是采用软分配策略对SIFT特征编码,进一步验证了软分配方法对于减弱视觉单词同义性和歧义性影响的有效性.Otávio等人[19]则提出一种基于视觉单词空间分布的图像检索和分类方法,该方法将视觉单词的空间信息嵌入到向量空间中,并对单词在图像中的相对位置关系进行编码,从而得到更为紧致的视觉表达方式.Yang等人[20]则利用视觉语言模型结合目标区域周围的视觉单元构建了包含上下文语义信息的目标语言模型,进一步改善了目标检索性能.此外,文献[21]在利用上下文近义词构建视觉词汇直方图的同时,结合查询扩展方法解决目标视角变化较大、目标遮挡严重的情况问题.但是,查询扩展方法都依赖于较高的初始查全率,在初始查全率较低时反而会带来一些负面影响.
针对上述问题,本文提出一种基于视觉词典优化与空间一致性度量的目标检索方法.1)引入精确欧氏位置敏感哈希算法[22](exact Euclidean locality sensitive hashing, E2LSH),利用该算法的位置敏感性和处理高维数据的高效性对图像初始关键点进行过滤,降低噪声点的影响,降低计算消耗;2)根据引入卡方模型(chi-square model, CSM)分析视觉单词与目标类别的相关性大小并结合单词词频滤除一定数量的视觉停用词,增强视觉词典的区分性;3)采用一种包含特征点角度、方向等空间一致性信息的度量方法完成目标检索,并引入K-近邻重排序方法,进一步改善目标检索在复杂环境下的性能.
1视觉词典优化
1.1关键点过滤
假设在视觉位置相近的关键点是相似的,将其捆绑在一块计算其质心,并将其作为一个有代表性的关键点.每个关键点pi={ui,si,θi,ri}由4部分组成,分别为:特征点在图像中的位置坐标ui、特征的尺度si、主方向θi及128维SIFT描述向量ri.为了提高过滤效果,本文选取k(k=6)个位置敏感函数联合起来以拉大关键点碰撞概率之间的差距,定义函数族:
(1)
其中,g(p)=(h1(p),h2(p),…,hk(p)),可知,经函数g(p)∈G降维映射后,关键点p都会变为一个k维向量a=(a1,a2,…,ak),然后,再采用主次Hash函数h1,h2对向量a进行Hash,构建Hash表并存储关键点.主次Hash函数的定义如下:
(2)
(3)
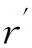
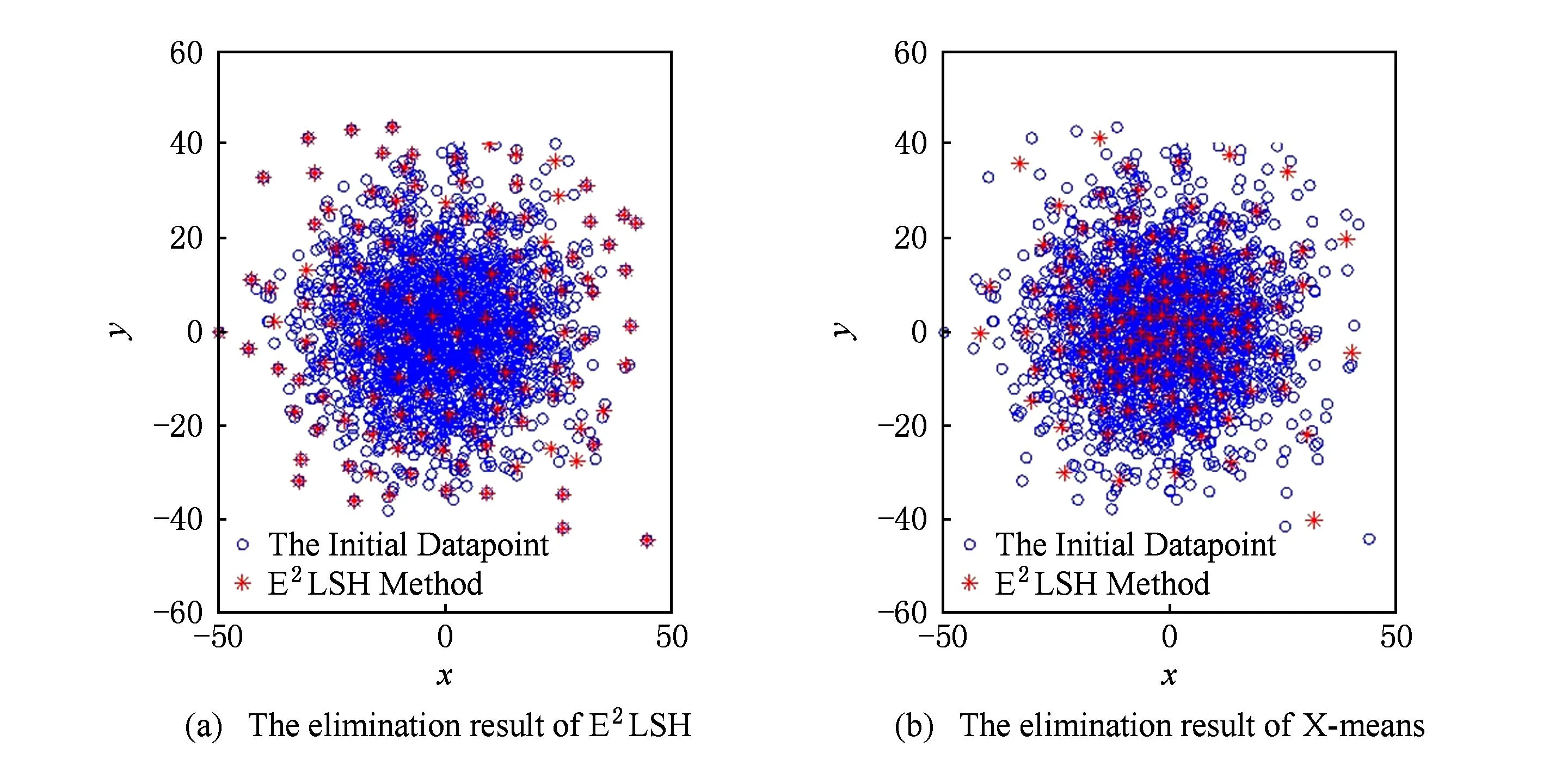
Fig. 1 The sketch map of different methods for eliminating key points.图1 不同方法对关键点过滤的示意图
Fig. 2 The map of E2LSH to eliminate the key points.图2 E2LSH对all_souls81图片关键点过滤效果图
由文献[8]的研究表明,X-means算法是当前关键点过滤方法中较为有效的主流过滤方法,为此,本文分别采用E2LSH和X-means算法对随机产生的数据点进行过滤以验证E2LSH算法的有效性.如图1所示.从图1不难看出,X-means方法过滤得到的代表性关键点较为不均,而由E2LSH过滤得到的代表性关键点更为均匀.因此,基于E2LSH的过滤方法在一定程度上能够避免关键点密集区域描述同一语义概念的关键点被分别捆绑到多个类别的现象,同时也能避免关键点稀疏区域描述不同语义概念的关键点被错误地捆绑到一个类别的现象,进而,提高过滤后各关键点的代表性和区分能力.图2进一步给出了E2LSH对Oxford5K数据库中all_souls81图片关键点过滤的效果图,其中,圆圈代表初始关键点,星形点则表示经E2LSH过滤后的关键点.由图2不难看出,E2LSH算法能有效地对关键点进行过滤,提高关键点的代表性.
1.2“视觉停用词”去除
卡方模型是一种医学上常用的测量2个随机变量相关性的方法,受此启发,可以采用卡方模型统计视觉单词与各目标图像类别之间的相关性,卡方值越小表示该视觉单词与各图像类别的相关性越小,区分性也就弱,反之亦然.因此,可以结合单词词频以更好地滤除“视觉停用词”.假设视觉单词w的出现频次独立于目标类别Cj,Cj∈C,1≤j≤k,图像集C={C1,C2,…,Ck},而视觉单词w与图像集C中目标类别的相互关系可以由表1来描述.
表1中,n1j表示目标类别Cj包含单词w的图像数目,n2j表示目标类别Cj不包含单词w的图像数目,n+j则表示目标类别Cj中的图像总数,并用ni+,i=1,2分别表示图像集C中包含单词w的图像总数和不包含w的图像总数.如此,表1中视觉单词w与各图像类别的卡方值可计算如下:
Table 1The Relationship Between Visual Word and Object Categories

表1 视觉单词与各目标类别关系
(4)
卡方值x2就代表了w与各目标类别间统计相关性的大小,同时考虑到单词w词频的影响,对卡方值赋予权重如下:
(5)
其中,tf(w)表示单词w词频.由此,就能够按照式(5)对每个单词的卡方值进行排序,然后去除一定数量S的“视觉停用词”即可.
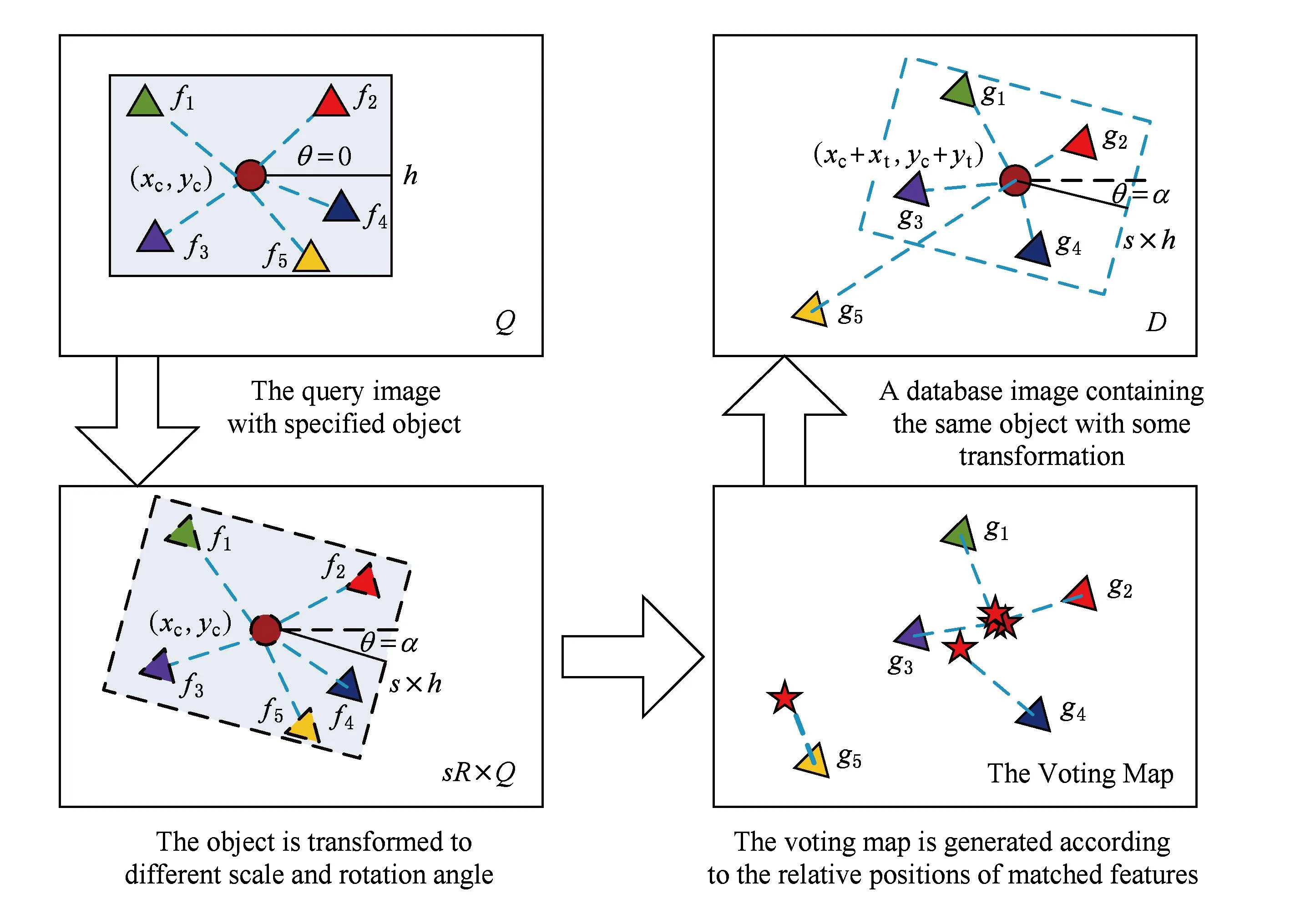
Fig. 3 The illustration of spatially-constrained similarity measurement.图3 空间一致性度量示意图
2相似性度量准则
2.1空间一致性度量方法
这里,用Q表示查询图像,D表示图像库中任一幅图像,其SIFT特征点分别表示为{f1,f2,…,fm},{g1,g2,…,gn},那么,2幅图像之间的空间一致性度量可计算如下:
S(Q,D|T)=
(6)

(7)
故而,就有S*(Q,D)=S(Q,D|T*)可以用来衡量图像Q和图像D之间的相似性,且所有的检索结果也能以此进行排序.由图3上面2幅图不难看出,2幅图像中只有特征点(fi,gi),i=1,2,3是满足空间一致性条件的.(f5,g5)是一个错误匹配点对,(f4,g4)的取舍则决定于式(6)中参数ε的大小.
为了计算S*(Q,D),需要找到最优变换T*,这里可将对T进行分解处理,首先将360角度空间划分nR部分,(一般nR=4或8),同样地,尺度空间被划分为nS部分,通常nS=8,变化范围为12到2之间.令V(f)表示特征点与查询图像中的矩形框中心cQ之间的相对位置关系向量,那么由匹配的特征点对(f,g)的位置及V(f)就能定位图像D中的矩形框中心,L(cQ)=L(g)-V(f),如果w(f)=w(g)=wk,特征点对(f,g)的投票得分为
(8)
Fig. 4 The retrieval result examples of vote map and object location map.图4 检索结果的投票得分图和目标定位示意图
不难看出,若相互匹配的特征点对符合空间一致性条件,那么尤其投票得出的矩形框中心位置也是相近的,如图3所示.每次投票得出的目标位置中心就代表了一个变换T,那么利用式(8)投票所得分数就等同于利用式(6)进行相似性度量.可以看出,这种机制可以同时进行目标检索和定位而不需要子图检索和后处理,极大地提高了目标检索系统的实用性和方便性.在实际应用中,可将投票得分图归一化为nx×ny个图像块大小,同时为了避免投票时的量化误差及弱化目标遮挡等情况的影响,本文对所估计的中心块周围的16×16像素的窗口块进行投票,而每个块的得分大小为Score(wk)×e-dσ2,e-dσ2为权重系数,由每个块与中心块之间的距离d和σ参数决定,整个过程相当于对投票得分图进行一次高斯平滑.
图4给出了对中心块周围的像素的窗口块进行高斯平滑以及对应的目标定位的示例图,从图4可以看出,给出一幅查询图像就能按照上述方法得到相应检索图像的投票得分图,然后依据此对目标进行定位,而每个投票得分图都存在一个极值点,也即是大部分匹配特征点对都将票数投向的位置.
2.2K-近邻重排序
根据上述相似性度量方法对数据库进行检索,那么结果可依据S*(Q,D)值的大小进行排序,记为R(Q,D),并令Ni表示查询图像的第i个检索结果,则有R(Q,Ni)=i,用Nq={Ni},i=1,2,…,k表示查询图像的K-近邻.为了有效地利用K-近邻图像包含的信息,本文重新利用其中的每一幅图像作为查询图像重新检索,并分别将排序结果记为R(Ni,D),依据这个排序结果给图像库中的每幅图像分配一个得分1R(Ni,D),那么经重排序之后的图像得分可定义为
(9)
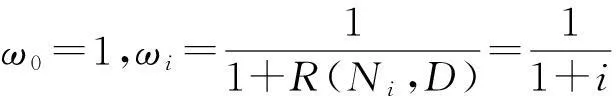
(10)
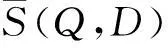
(11)
然后,所有图像即可按照式(11)进行重排序,完成检索.
3实验设置与性能分析
3.1实验设置
本文选取Oxford5K数据库[23]作为实验数据库,并从每个目标类别中选取50幅图像,共550幅图像作为训练图像库来生成视觉词典,词典规模为10 000.此外,引入Flickr1数据库[24]作为干扰数据以验证本文方法在复杂环境下的实验性能.实验硬件配置为Core 2.6 GHz×4、内存4 GB的台式机,软件环境为MATLAB2012a,性能评价指标采用查准率均值(average precision,AP)和平均查准率均值(mean average precision,MAP)以及时间效率,相关定义如下:

(12)

(13)
3.2实验性能分析
首先,为了选取合适的Hash函数个数值,实验从550幅训练图像库中提取约1 436 634个特征点,然后利用E2LSH对其过滤,并采用AKM聚类算法对未过滤关键点和不同k值过滤后的特征点进行聚类,生成相同单词数目的词典进行目标检索分析了参数k对目标检索结果MAP值的影响(此时,令σ2=0),如图5所示.从图5不难看出,随着参数k值的变化,目标检索的MAP值也随之变化,且在k>3时,经E2LSH过滤后的检索MAP值要高于未过滤的目标检索.当k=6时,目标检索MAP值最大,这是因为,当k值较小时会使得过滤后的关键点数目过少,从而容易丢失图像包含的细节信息,而当k值较大时导致过滤后的特征点数目过多,使得算法过滤效果不明显,综合考虑,本文取k=6时剩余代表性关键点数目为1 002 105个,过滤率为31.3%.然后,实验又将本文方法与传统的AKM算法在生成视觉词典时的时间消耗作了对比,具体如图6所示.从图6可以看出,本文方法在经E2LSH算法的过滤以后,视觉词典的生成效率有较为明显的提升.
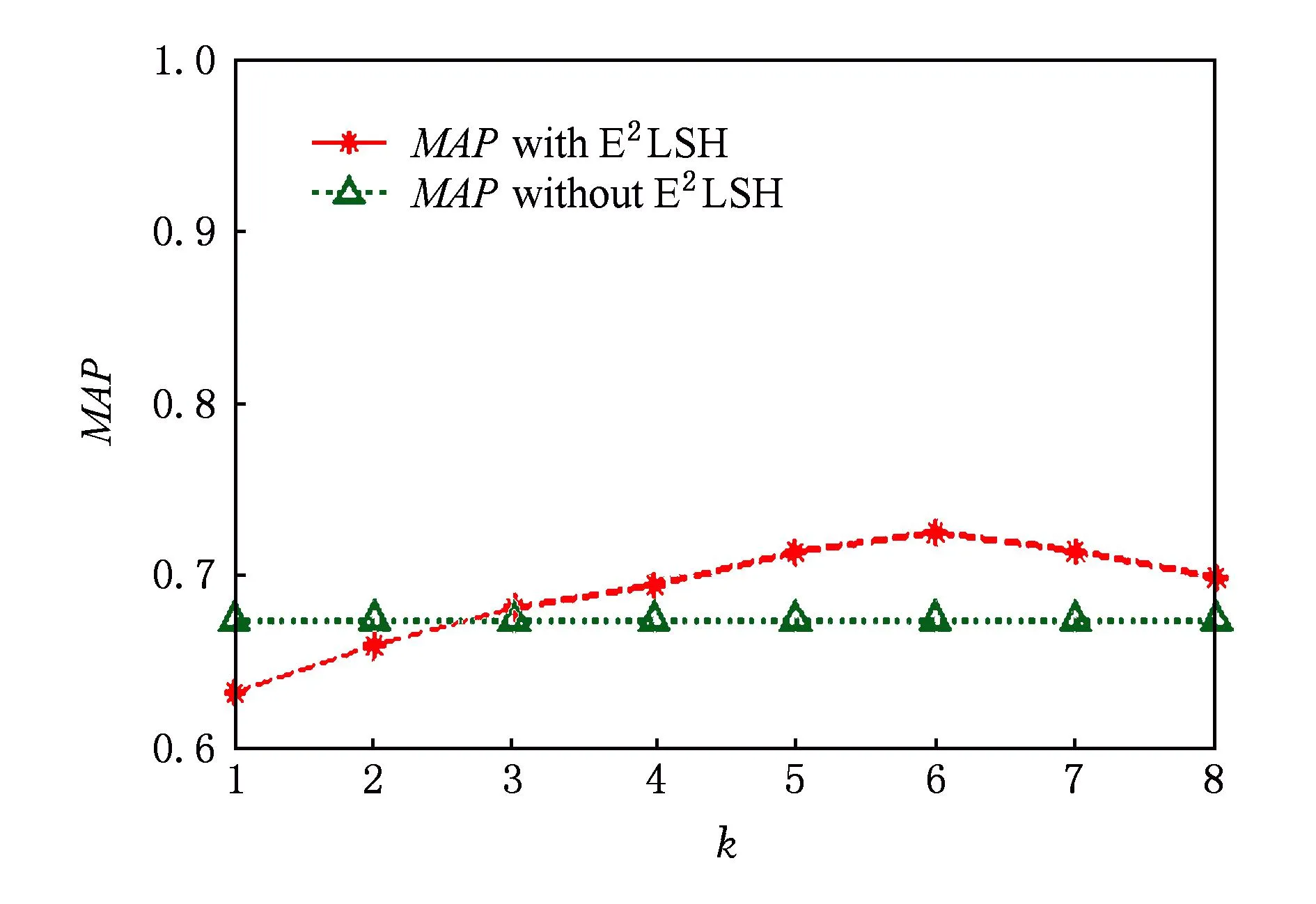
Fig. 5 The influence of parameter k on MAP.图5 参数k对目标检索MAP值的影响
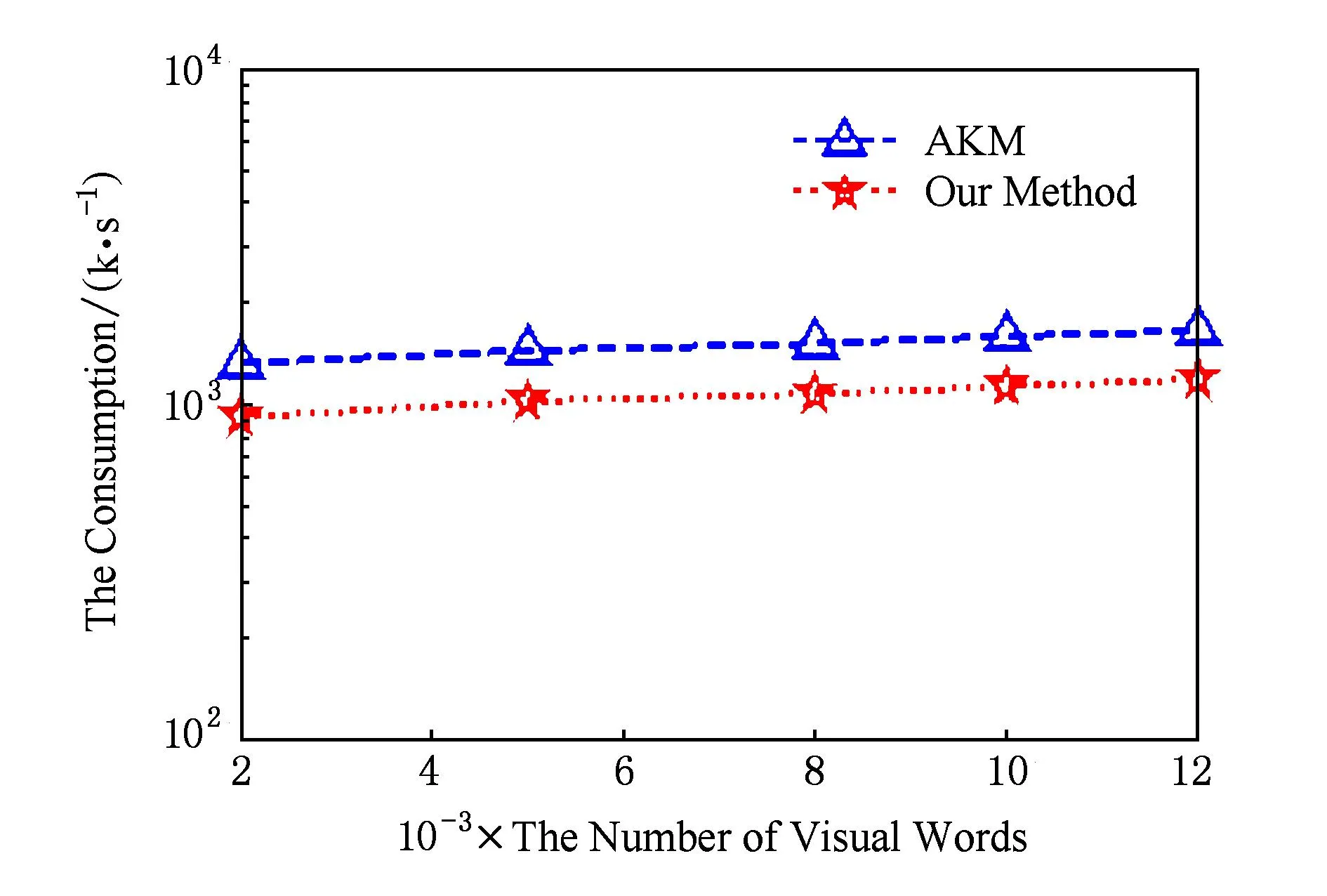
Fig. 6 The efficiency comparison of different methods.图6 不同方法构建词典效率对比
随后,为了验证卡方模型对滤除“视觉停用词”的有效性,实验在E2LSH函数个数k=6的情况下对关键点进行过滤,并生成规模为10 000的视觉词典,然后利用卡方模型滤除一定数量S的视觉停用词,验证过滤不同数目“视觉停用词”对目标检索结果的影响,并与未进行视觉停用词滤除时的目标检索结果进行对比,得其检索MAP值如图7所示.从图7不难看出,采用卡方模型滤除一定数目的“视觉停用词”能够在一定程度上提高目标检索的MAP值,并且在滤除数目S=1 000时能够达到最高的MAP值,即为76.4%.同时,从图7可以看出,当滤除的单词数目过多时,会导致目标检索性能降低,这是因为滤除过多难免使一些代表性强的单词也被错误地滤除.
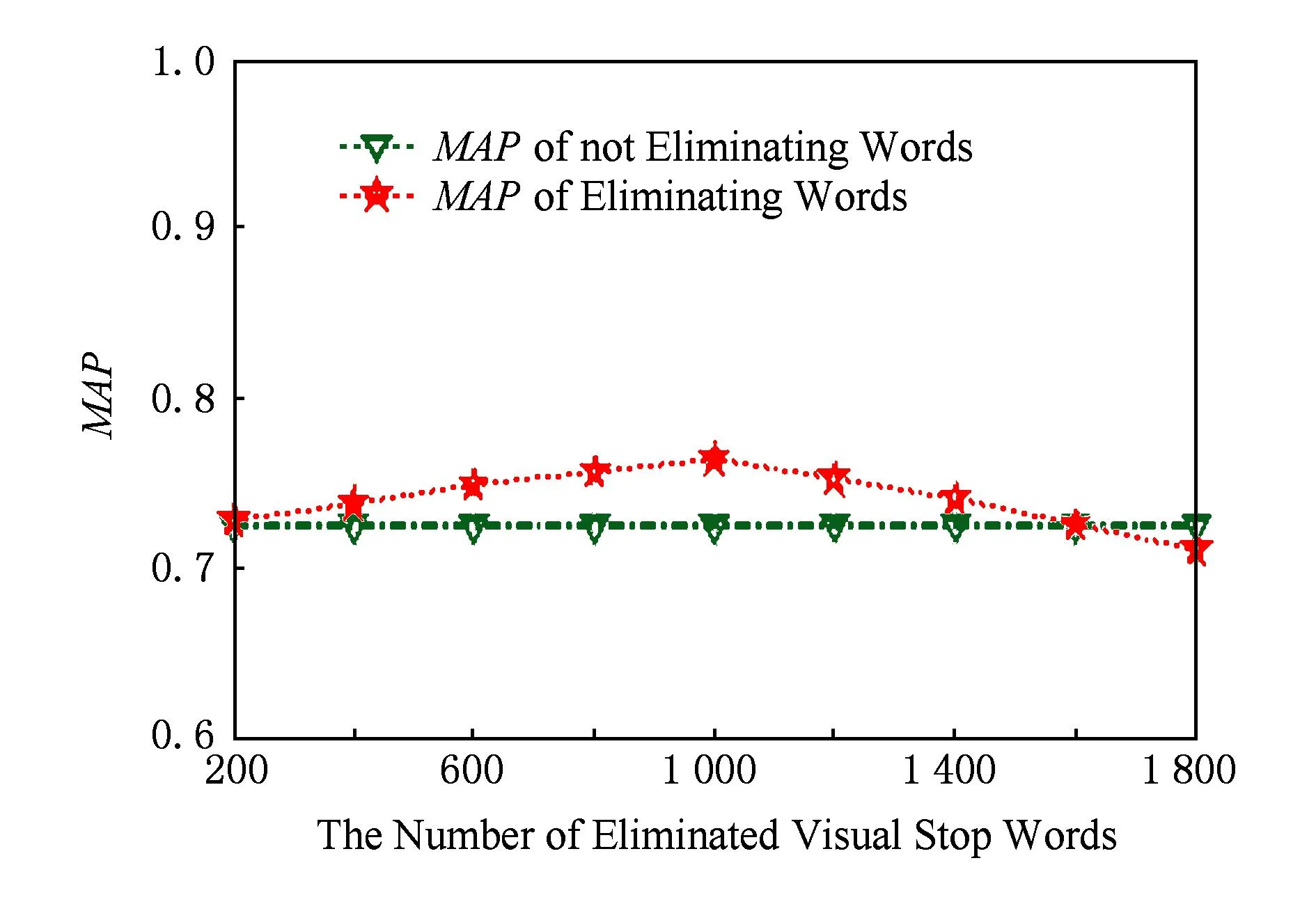
Fig. 7 The influence of the number of eliminated visual stop words on MAP.图7 去除停用词数目对目标检索MAP值的影响
然后,在E2LSH函数个数k=6、去除视觉停用词数目S=1 000的情况下,实验以Oxford5K为实验数据库分析了空间一致性度量准则中参数σ2对目标检索MAP值的影响,结果如图8所示.其中,当σ2=0时表示不对投票结果进行高斯平滑,也即是每个匹配特征对都将票数投向根据式(8)所估计的一个中心块,由图8不难看出,当σ2>0时,也即表示对所估计的中心块周围16×16窗口块进行投票的MAP值明显优于未对投票结果进行高斯平滑的情况(即σ2=0),且在σ2=2.5时取得最大的MAP值,因此,本文取σ2=2.5.
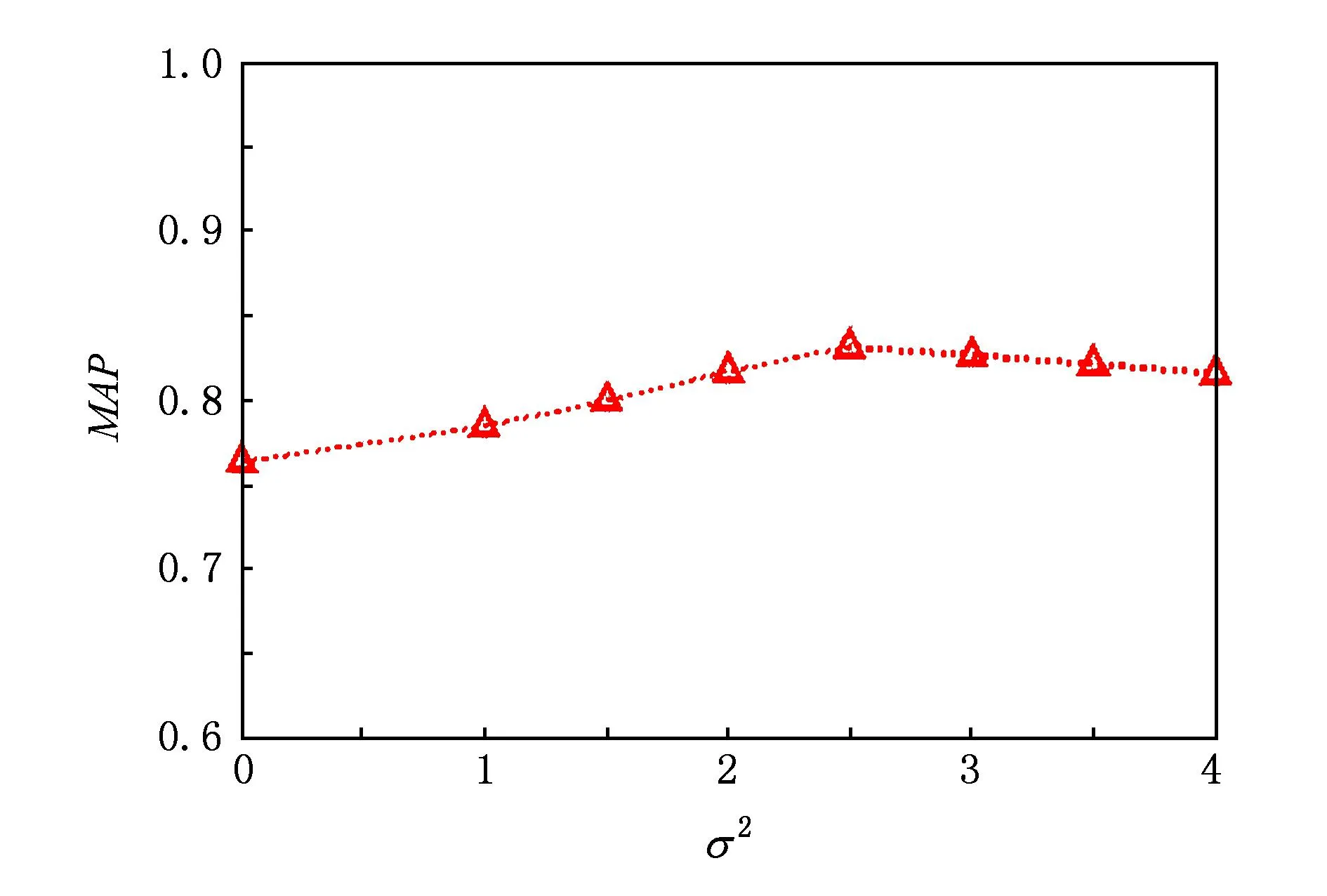
Fig. 8 The influence of parameter σ2 on MAP.图8 参数σ2对MAP值的影响
其次,由于基于上下文语言模型的目标检索方法[20](AKM+language model, AKM+LM)能够很好地记录视觉单词间的空间关系,是当前弥补空间信息不足方面具有代表性的方法,而基于上下文近义词和查询扩展目标检索方法[21](contextual syn-onymous visual words+query expansion, CSVW+QE)在映射视觉词汇直方图时,很好地利用了视觉单词的上下文近义词,也是当前较为经典的利用单词空间信息的方法,且该方法又引入了查询扩展策略进一步改善检索结果.因此,为了验证本文方法中空间一致性度量准则以及重排序方法对改善目标检索结果的有效性,实验将本文方法(enhanced visual dictionary and spatially-constrained similarity measure, EVD+SCSM)与AKM+LM方法、CSVW+QE方法以及将优化的视觉词典与语言模型相结合的方法(enhanced visual dictionary+language model, EVD+LM)在Oxford5K数据库上对11个查询目标的检索准确度作了比较,得平均查准率均值MAP如表2所示:
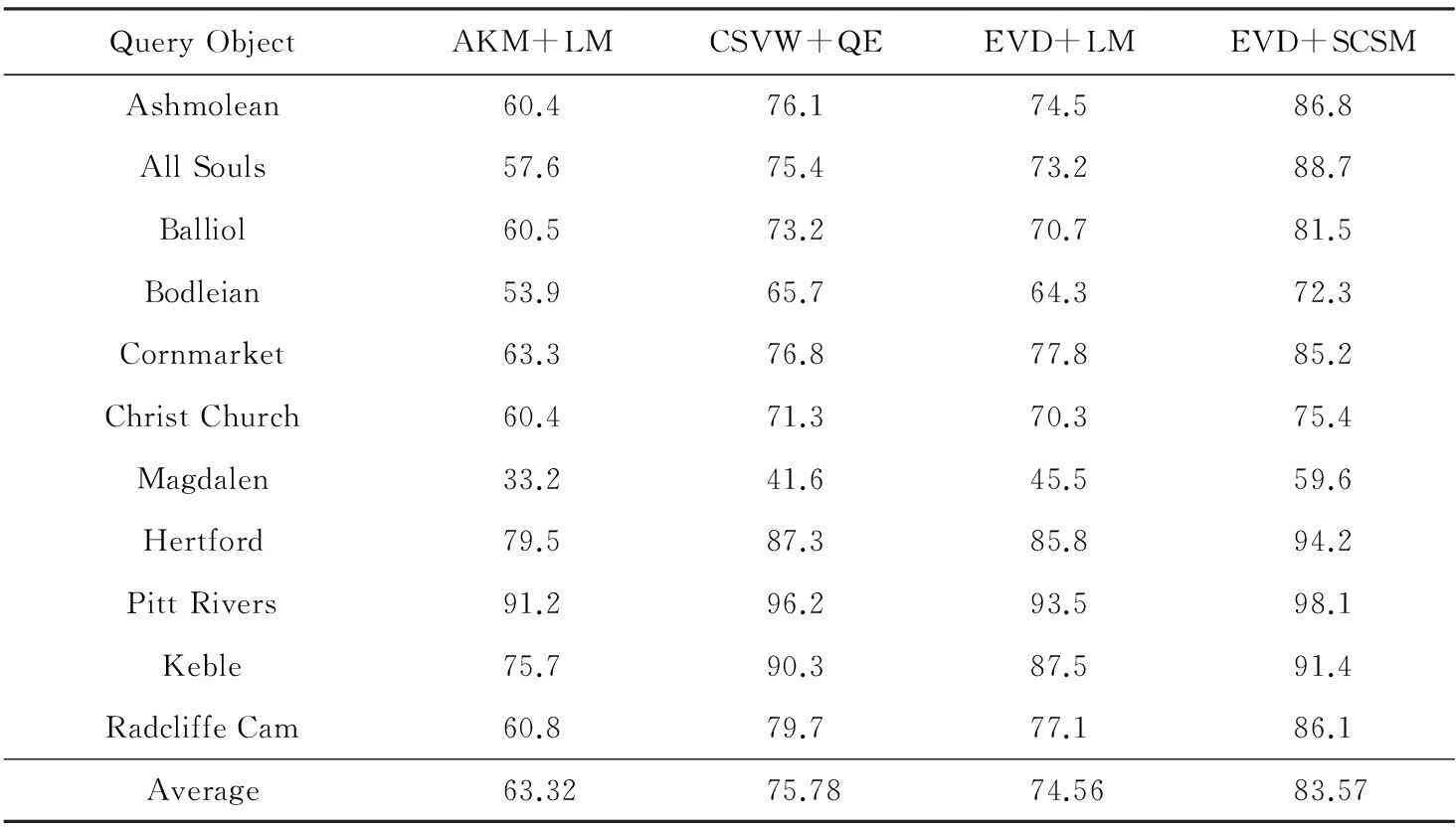
Table 2 The Comparison of Object Retrieval MAP Values of Different Methods
从表2可知,对不同的查询目标而言,采用AKM+LM方法的MAP值均低于其他3种方法;而EVD+LM方法的MAP值相较于AKM+LM方法有一定的改善,足以说明本文提出的词典优化方法能有效降低图像背景噪声点和停用词的影响,提高视觉词典的区分性;同时CSVW+QE方法的性能要略好于EVD+LM方法,这是因为CSVW+QE方法在利用空间信息的基础上又结合查询扩展策略,得到了更多与查询目标相关的图像.但是,本文方法的检索MAP值要远高于上述3类方法,与EVD+LM方法对比可以看出,本文中的空间一致性度量准则对单词空间信息的利用优于视觉语言模型.由此也说明改善视觉词典质量能提高视觉词典对图像内容的语义表达能力,而更加准确的度量方法则能更加精确地对图像内容的表达形式进行度量,二者都能在一定程度上提高目标检索精度.与CSVW+QE方法相比,可知本文方法在词典优化的基础上,结合空间一致性度量准则和重排序,使得本文方法综合性能优于CSVW+QE方法.
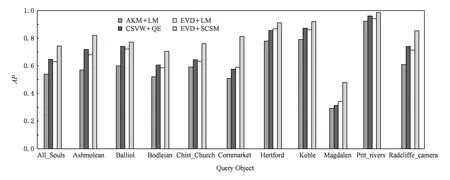
Fig. 9 The AP of different methods on Oxford5K.图9 在Oxford5K数据库上的目标检索AP值
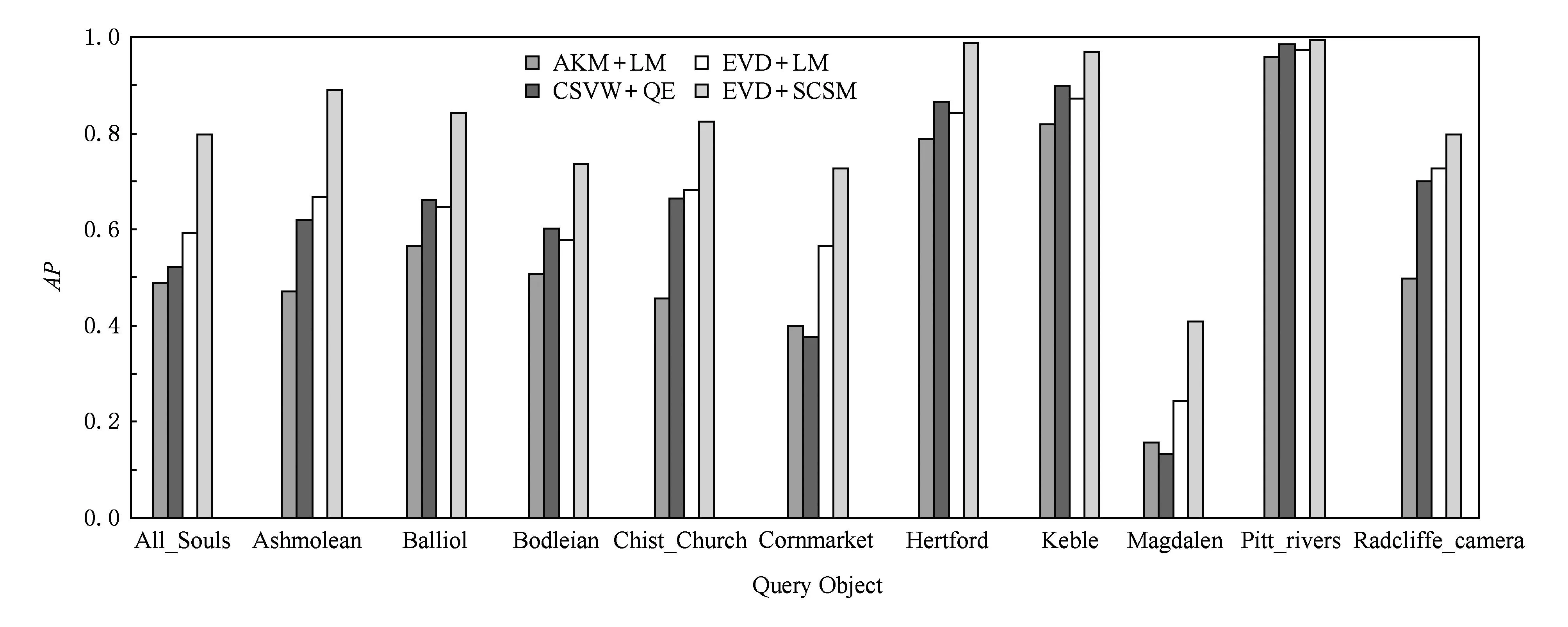
Fig. 10 The AP of different methods on Oxford5K+Flickr1.图10 在Oxford5K+Flickr1数据库上的目标检索AP值
然后,又引入Flickr1数据库作为干扰数据验证本文方法在复杂数据环境下的性能.实验结果如图9和图10所示.对比图9和图10可知,采用本文方法(EVD+SCSM)进行检索较之其他3种方法有更好的表现,且在加入干扰项数据库之后,AKM+LM方法、EVD+LM方法因没有对查询目标的信息进行有效扩展,因此其检索性能都有明显的下降.CSVW+QE方法及本文方法却下降不明显;但是,当加入大规模干扰数据之后,由于CSVW+QE方法中的查询扩展策略依赖于较高的初始查全率,所以对于初始查全率较低的Cornmarket,Magdalen等目标而言,其检索AP值反而低于AKM+LM方法和EVD+LM方法.而本文方法采用的K-近邻重排序方法是在空间一致性度量准则下进行的,能够自动地舍弃那些不满足空间一致性条件的特征点信息,所以其检索AP值不受初始查全率影响,由此说明本文方法在大规模干扰数据情况下仍能取得较好的检索结果,实用性更强.
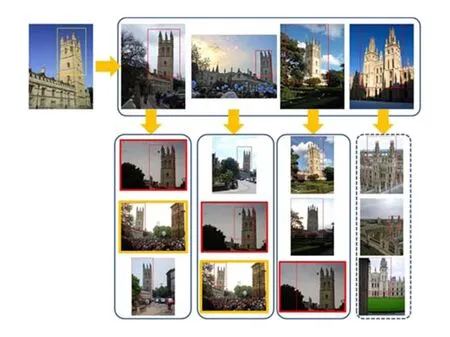
Fig. 11 Example of K-NN re-ranking result.图11 K-近邻重排序结果示意图
最后,图11给出了K-近邻重排序方法的效果示例图.从图11可以看出,第1行图像中的第5幅最近邻图像与查询目标图像无关,但是由其检索得到的虚线框中的任何一幅图像的最终检索得分不会改变,因为它们与其他的最近邻图像不相关.而用实线框框标识的图像会得到较高的检索得分,因为它们与K-近邻中的多数图像相关.不难看出,采用K-近邻重排序方法之后可以得到更多包含查询目标的图像.
4结语
为了改善生成视觉词典的质量、提高视觉单词对图像内容的表达能力,本文首先利用E2LSH算法对图像初始关键点进行过滤,降低噪声点的影响;然后,引入卡方模型统计各视觉单词与目标类别的相关性,并结合单词词频信息移除词典中的视觉停用词;最后,为了确保度量的准确性,采用空间一致性度量准则进行相似性度量以弥补传统视觉词典模型中单词空间关系缺失降低量化误差并对初始检索结果进行K-近邻重排序.实验结果有效地验证了本文方法的有效性.
需要注意的是,在今后需要研究如何降低E2LSH算法的随机性问题来提高过滤效果的鲁棒性.此外,如何通过距离度量的学习使得特征空间的距离更加接近真实的语义距离也是今后亟待解决的问题.
参考文献
[1]Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110
[2]Sivic J, Zisserman A. Video Google: A text retrieval approach to object matching in videos[C]Proc of the 9th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2003: 1470-1477
[3]Jégou H, Douze M, Schmid C. Improving bag-of-features for large scale image search[J]. Computer Vision, 2010, 87(3): 316-336
[4]Ji Chuanjun, Liu Zuotao, Chan Wen, et al. Context modeling based automatic image annotation system[J]. Journal of Computer Research and Development, 2011, 48(1): 441-445 (in Chinese)(纪传俊, 刘作涛, 产文, 等. 一个基于语义上下文建模的图像自动标注系统[J]. 计算机研究与发展, 2011, 48(1): 441-445)
[5]Chen Y Z, Dick A, Li X, et al. Spatially aware feature selection and weighting for object retrieval[J]. Image and Vision Computing, 2013, 31(12): 935-948
[6]Wang J Y, Bensmail H, Gao X. Joint learning and weighting of visual vocabulary for bag-of-feature based tissue classification[J]. Pattern Recognition, 2013, 46(12): 3249-3255
[7]Cao Y, Chang H W, Zhiwei L, et al. Spatial-bag-of-features[C]Proc of the 23rd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 3352-3359
[8]Zhu Jun, Zhao Jieyu, Dong Zhenyu. Image classification using hierarchical feature learing method combined with image silency[J]. Journal of Computer Research and Development, 2014, 51(9): 1919-1928 (in Chinese)(祝军, 赵杰煜, 董振宇. 融合显著信息的层次特征学习图像分类[J]. 计算机研究与发展, 2014, 51(9): 1919-1928)
[9]Li Dai, Sun Xiaoyan, Wu Feng, et al. Large scale image retrieval with visual groups[C]Proc of the 20th IEEE Conf on Image Processing. Piscataway, NJ: IEEE, 2013: 2582-2586
[10]Chen Tao, Yap K H, Zhang Dajiang. Discriminative soft bag-of-visual phrase for mobile landmark recognition[J]. IEEE Trans on Multimedia, 2014, 16(3): 612-622
[11]Rudinac M, Lenseigne B, Jonker P. Keypoint extraction and selection for object recognition[C]Proc of the 8th IEEE Conf on Machine Vision Applications. Piscataway, NJ: IEEE, 2009: 191-194
[12]Jamshy S, Krupka E, Yeshurun Y. Reducing keypoint database size[C]Proc of the 15th Int Conf on Image Analysis and Processing. Berlin: Springer, 2009: 113-122
[13]Tirilly P, Claveau V, Gros P. Language modeling for bag of visual words image categorization[C]Proc of the 2008 Int Conf on Content-based Image and Video Retrieval. New York: ACM, 2008: 249-258
[14]Yuan J, Wu Y, Yang M. Discovery of collocation patterns: From visual words to visual phrases[C]Proc of the 20th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 1-8
[15]Liu Shuoyan, Xu De, Feng Songhe, et al. A novel visual words definition algorithm of image patch based on contextual semantic information[J]. Acta Electronica Sinica, 2010, 38(5): 1156-1161 (in Chinese)(刘硕研,须德,冯松鹤, 等. 一种基于上下文语义信息的图像视觉单词生成算法[J]. 电子学报, 2010, 38(5): 1156-1161)
[16]Zhang Ruijie, Li Bicheng, Wei Fushan. Image scene classification based on multi-scale and contextual semantic information[J]. Acta Electronica Sinica, 2014, 42(4): 646-652 (in Chinese)(张瑞杰, 李弼程, 魏福山. 基于多尺度上下文语义信息的图像场景分类算法[J]. 电子学报, 2014, 42(4): 646-652)
[17]Yeh J B, Wu C H. Extraction of robust visual phrases using graph mining for image retrieval[C]Proc of 2010 IEEE Int Conf on Multimedia and Expo (ICME 2010). Piscataway, NJ: IEEE, 2010: 3681-3684
[18]Van Gemert J C, Veenman C J, Smeulders A W M, et al. Visual word ambiguity[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2010, 7(32): 1271-1283
[19]Otávio A B P, Fernanda B S, Eduardo V, et al. Visual word spatial arrangement for image retrieval and classification[J]. Pattern Recognition, 2014, 47(1): 705-720
[20]Yang Linjun, Geng Bo, Cai Yang, et al. Object retrieval using visual query context[J]. IEEE Trans on Multimedia, 2012, 13(6): 1295-1307
[21]Xie Hongtao, Zhang Yongdong, Tan Jianlong, et al. Contextual query expansion for image retrieval[J]. IEEE Trans on Multimedia, 2014, 56(99): 1-32
[22]Slaney M, Casey M. Locality-sensitive hashing for finding nearest neighbors[J]. IEEE Signal Processing Magazine, 2008, 8(3): 128-131
[23]Robotics Research Group. Oxford5K dataset[DBOL]. [2014-03-26]. http:www.robots.ox.ac.uk_vggdataoxbuildings
[24]Yahoo Company. Flickr1 dataset[DBOL]. [2014-03-24]. http:www.flickr.com

Zhao Yongwei, born in 1988. PhD, lecturer. His research interests include image analysis and processing.

Zhou Yuan, born in 1978. Master, lecturer. Her research interests include image processing and multimedia technology.

Li Bicheng, born in 1970. PhD, professor. His research interests include data mining and artificial intelligence processing.
Object Retrieval Based on Enhanced Dictionary and Spatially-Constrained Similarity Measurement
Zhao Yongwei1, Zhou Yuan2, and Li Bicheng3
1(DepartmentofElectronicTechnology,CAPFEngineeringUniversity,Xi’an710000)2(SchoolofComputerScience,HenanUniversityofEngineering,Zhengzhou451191)3(InstituteofInformationSystemEngineering,PLAInformationEngineeringUniversity,Zhengzhou450002)
AbstractBag of visual words model based object retrieval methods have several problems, such as low time efficiency, the low distinction of visual words and the weakly visual semantic resolution because of missing spatial information and quantization error. In this article, an object retrieval method based on enhanced dictionary and spatially-constrained similarity measurement is proposed aiming at the above problems. Firstly, E2LSH (exact Euclidean locality sensitive hashing) is used to identify and eliminate the noise key points and similar key points, consequently, the efficiency and quality of visual words are improved; Then, the stop words of dictionary are eliminated by chi-square model (CSM) to improve the distinguish ability of visual dictionary; Finally, the spatially-constrained similarity measurement is introduced to accomplish object retrieval, furthermore, a robust re-ranking method with the K-nearest neighbors of the query for automatically refining the initial search results is introduced. Experimental results indicate that the quality of visual dictionary is enhanced, and the distinguish ability of visual semantic expression is effectively improved and the object retrieval performance is substantially boosted compared with the traditional methods.
Key wordsobject retrieval; bag of visual words model; exact Euclidean locality sensitive hashing(E2LSH); spatially-constrained similarity measure; chi-square model (CSM)
收稿日期:2015-01-20;修回日期:2015-07-07
基金项目:国家自然科学基金项目(60872142,61301232)
中图法分类号TP391
This work was supported by the National Natural Science Foundation of China (60872142,61301232).
