
光谱特征波长的SPA选取和基于SVM的玉米颗粒霉变程度定性判别
2016-06-15 16:35:24喜明杰
光谱学与光谱分析 2016年1期
袁 莹,王 伟,褚 璇,喜明杰
中国农业大学工学院,现代农业装备优化设计北京市重点实验室,北京 100083
光谱特征波长的SPA选取和基于SVM的玉米颗粒霉变程度定性判别
袁 莹,王 伟*,褚 璇,喜明杰
中国农业大学工学院,现代农业装备优化设计北京市重点实验室,北京 100083
利用波长范围在833~2 500 nm的傅里叶变换近红外光谱(Fourier transform near infrared spectroscopy, FT-NIR)对不同霉变程度的玉米颗粒进行检测区分。首先,为避免光谱数据首尾噪声影响,对比四种常见的预处理方法,最终选择移动平均平滑法对原始光谱数据进行预处理;然后为选出合适的样本集划分方法以提高模型预测性能,对常见的四种方法进行对比,最终利用SPXY(sample set partitioning based on joint x-y distance)法进行样本集划分;进一步为减少数据量,降低维度,使用连续投影算法(successive projections algorithm, SPA)提取出7个特征波长,分别为833,927,1 208,1 337,1 454,1 861和2 280 nm;最后,将七个特征波长数据作为输入,选取径向基函数(radial basis function, RBF)作为支持向量机(support vector machine, SVM)核函数,取参数C=7 760 469,γ=0.017 003建立判别模型。SVM模型对训练集和测试集的预测准确率分别达到97.78%和93.33%。另取不同品种的玉米颗粒,以同样的标准挑选样品组成独立验证集,所建立的判别模型对独立验证集的预测准确率达到91.11%。结果表明基于SPA和SVM能有效地对玉米颗粒霉变程度进行判别,所选取的7个特征波长为实现在线霉变玉米颗粒近红外检测提供了理论依据。
霉变;玉米颗粒;FT-NIR;SPA;SVM
引 言
我国是玉米生产和消费大国,玉米除食用之外,还用作饲料和工业原料。然而目前因霉变造成的玉米产后损失过于严重,这不仅影响着玉米产量,而且一旦霉变玉米被人畜食用,也会严重危害人畜健康,因此,及时检出霉变玉米尤为重要。
目前,对霉变玉米的检出大多采用人工感官鉴定方法进行品质检测,不仅效率低下,工作量大,而且对于品质的检测不能标准化,同时杂质、霉变、虫蚀等缺陷有时不易进行肉眼的判断;而传统的生物培养方法需要破坏大量样本,不利于大群体筛选,而且测定程序过于复杂不能及时分析等。
近红外光谱技术是近些年来发展较快的分析方法之一,它依据化学成分对近红外光谱的吸收特性而进行测定。其优点在于无需复杂的样品前处理,是一种快速无损的分析检测方法,结合光纤可以被运用到在线检测中,因此广泛应用于谷物品质和营养的定性及定量检测[1, 2]。许多研究表明利用近红外结合适当的化学计量学方法可识别谷物的品种[3],并对其内部的营养物质进行定性定量的检测,而且谷物颗粒的霉变检测也已经成为西方发达国家的研究热点[4-5]。
本工作在运用移动平均平滑法进行光谱预处理和运用SPXY(sample set partitioning based on joint x-y distance)法进行样本集划分的基础上,采用连续投影算法(successive projections algorithm,SPA)[6]提取光谱中的特征波长,降低了光谱信息的维度,剔除了冗余信息,提取出的特征波长作为支持向量机(support vector machine, SVM)的输入用于建立不同霉变程度玉米颗粒分类模型,探索玉米颗粒霉变程度近红外检测方法的可行性。
1 实验部分
1.1 仪器设备
实验使用仪器为德国布鲁克公司(BRUKER,德国)的MPA型傅里叶变换近红外光谱仪,其采集模式为积分球反射模式,波长范围为833~2 500 nm(12 000~4 000 cm-1),分辨率为4 cm-1。利用光谱仪自带的OPUS软件进行光谱数据获取。并利用Matlab2012b平台结合台湾大学林智仁(C.J Lin)等开发的LIBSVM工具箱对光谱数据进行处理分析。
1.2 材料和样品
选取150粒2012年收获的自然感染霉菌的豫玉32玉米颗粒作为样品,其形状和大小基本一致。参照文献[7]的方法进行分组,每组挑选50粒玉米颗粒组成样品集:
(1)无症状组:玉米颗粒表面无明显的霉菌损害的迹象,除了非常轻微的变色。
(2)中度霉变组:可见的真菌生长占玉米颗粒表面的30%~70%,且严重变色。
(3)重度霉变组:真菌生长覆盖整个严重变色玉米颗粒的表面。
1.3 光谱数据预处理
由于样品形状不同及表面凹凸不平,由此产生的散射会对光谱的采集造成一定的影响,并且由光谱仪得到的光谱信号中不仅含有有用信息,同时也叠加着随机误差,使得光谱曲线中存在噪声干扰,因而需要对原始光谱数据进行预处理。常见的预处理方法有标准化(autoscaling)、移动平均平滑法(moving average smoothing)、局部加权回归散点平滑法(locally weighted scatterplot smoothing,LOWESS)、S-G卷积平滑法(Savitzky-Golay smoothing)等。
标准化,可以给光谱中所有波长变量以相同的权重,但是不能反映光谱的趋势及变化。移动平均平滑法,优点为计算量少,能较好的反映光谱的趋势及变化,但是当预处理数据较大时,存储的数据量也较大,且平滑点数对预处理的影响较大。LOWESS平滑法,其特点是使得线性回归模型中的参数可以随着自变量的不同取值改变,但是也从而加大了计算量。S-G卷积平滑法,可以有效减少光谱数据中的随机噪声,平滑点数的影响较小,但计算相对复杂。
为选择适合本研究光谱数据的预处理方法,利用Matlab2012b平台对四种常见的光谱数据预处理方法进行对比。取各组的前30个样品,共90个样品数据组成训练集,取各组剩余20个样品共60个样品数据组成测试集,分别利用标准化、移动平均平滑法、LOWESS平滑法以及S-G卷积平滑法四种方法进行预处理,并分别将预处理后的数据利用SVM进行初期的预测,对比预测结果,从而选择出适合的预处理方法。
1.4 样本集划分
样本集划分即采用某种特定方法将总体样本划分为训练集和测试集,用于进行模型建立及对模型的预测能力进行验证,它在一定程度上决定着所建模型的预测性能。在进行样本集划分时,数据需具有一定的代表性,并且要保证训练集和测试集样本数量的合理分配,既要满足建模的要求,也不会引起数据冗余或模型过拟合。常见的样本集划分方法主要包括随机法(random sampling, RS), Kennard-Stone算法(KS)及SPXY算法等。
随机法,即按照简单规则或完全无规律划分样本集,这种方法简单、速度快,但是很难得到较为理想的样本集,且每次划分都是随机的,训练集和测试集的样本差异大,从而会影响模型的稳定性。KS法是基于变量之间的欧氏距离,在特征空间中均匀选取样本。该方法所选的训练集样本分布均匀,但因需要计算两两样本之间的欧式距离,计算量大。SPXY法是Galvao等[8]在KS法的基础上提出的,其逐步选择过程与KS法相同,只是在计算过程中,将变量x和y均考虑在内,这样有效兼顾了样本的光谱和待测量信息。
为选择出预测性能好的样本集划分方法,本文利用Matlab2012b平台对顺序划分、随机法、KS法以及SPXY法四种方法进行样本集划分方法的对比。
1.5 SPA
SPA是一种前向循环波长选取方法,从一个波长开始,每次循环都计算其在未选入波长上的投影,将投影向量最大的波长引入到波长组合中,每个新选入的波长,都与前一个线性关系最小。这种方法能够有效地消除波长变量之间的共线性影响,降低样品光谱数据维数,减少计算量,在多种光谱的多元定量和定性分析中得到了广泛的应用。
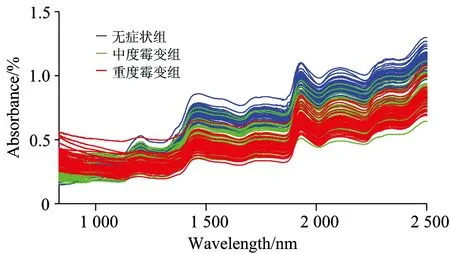
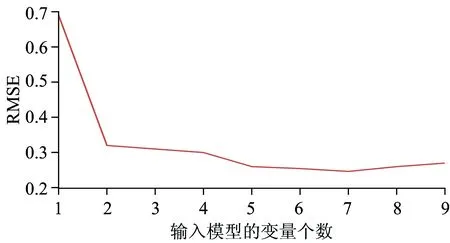
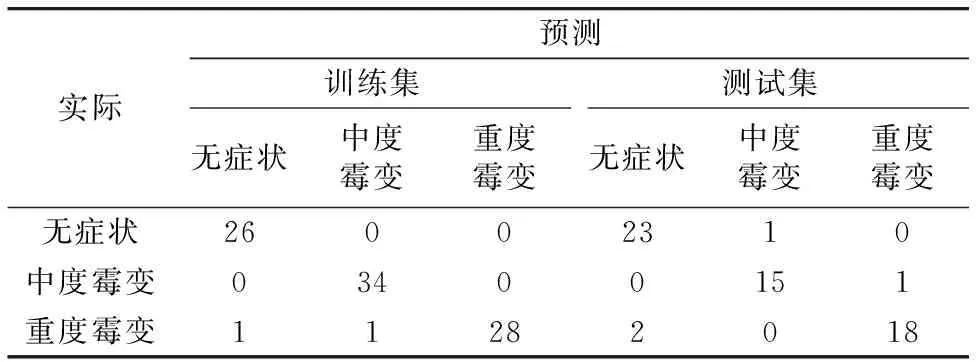
对于样品数M和波长数K组成的光谱矩阵XM×K,N(N (1)第一次迭代(p=1)开始前,在光谱矩阵中任选一列向量xj,记为xk(0),即k(0)=j,j∈1, …,m; (2)将未被选人的列向量位置的集合记为s,s={j, 1≤j≤m,j∉{k(0), …,k(p-1)}}; (3)计算剩余列向量xj(j∈s)与当前所选向量xk(p-1)的投影: (4)提取投影向量最大波长的变量序号: k(p)=arg[max(‖Pxj‖)],j∈s; (5)令xj=Pxj,j∈s;p=p+1,如果p 最终选取的波长变量组合为{k(p),p=0, …,h-1}。对于每一个初始k(0),循环一次后利用多元线性回归(multple linear regresion,MLR)进行交互验证分析, 最小均方根误差(root mean square error,RMSE)对应的k(p)即为最终的选择结果[11]。 2.1 原始光谱数据获取 利用傅里叶变换近红外光谱仪采集每粒玉米胚芽面的光谱数据,最终得到的光谱数据为扫描64次所得的平均光谱,所有样品的光谱曲线如图1所示。从图中可以看出,无症状组和重度霉变组基本可以分开,而中度霉变组与其他两组略有重叠,因而需要运用化学计量学方法进行分类判别,样品的原始光谱结果与1.2节分组基本一致。 2.2 光谱预处理结果 由于原始光谱曲线在波长1 000 nm之前存在噪声干扰,同时为保留光谱曲线中的有用信息,分别利用标准化、移动平均平滑法、LOWESS平滑法及S-G卷积平滑法对光谱数据进行预处理,取各组的前30个样品,共90个样品数据组成训练集,取各组剩余20个样品共60个样品数据组成测试集,预处理后得到的数据分别作为SVM的输入进行初步的预测,对比预测结果,从而选取合适的预处理方法,便于后续的数据分析。四种预处理方法对应的训练集及测试集的预测准确率如表1所示。 Fig.1 Original spectra Table 1 Prediction accuracy got by different preprocessing methods/% 由表1可知,采用移动平均平滑法对光谱数据进行预处理,训练集及测试集的预测结果都较高。通过试验,最终采用21个窗口的移动平均平滑法对样本数据进行预处理。 2.3 样本集划分方法选择 由于样本集的划分在一定程度上决定着所建模型的预测性能,为选出合适的样本集划分方法,对常见的四种方法进行对比。共采用了150个玉米颗粒样品,取其中的90个样品作为训练集,60个样品作为测试集。使用2.2节中最终选择的21个窗口的移动平均平滑法对样本数据进行预处理,然后分别利用顺序划分、随机法、KS法以及SPXY法四种方法进行样本集划分。其中顺序划分即取各组的前30个样品数据组成训练集,取各组剩余20个样品数据组成测试集。划分后得到的训练集和测试集输入到SVM进行划分效果的对比,四种样本集划分方法的预测准确率如表2所示。 Table 2 Prediction accuracy got by different grouping method 利用SPXY法进行样本集划分时,训练集及测试集的预测准确率均高于其他方法,因此,采用SPXY法对样本集进行划分。运用SPXY法的样本集划分结果如表3所示。从表中可以看出,各组的训练集测试集的样品数差异不大。 Table 3 Result of grouping by SPXY 2.4 波长优选 样本数据共含有2 100个光谱数据点,由于数据量大,运算时间长,且存在多重共线性,在进行分类模型建立时,会降低模型的准确性。因此利用SPA对样本数据进行降维,提取出样本数据中重要的波长点。 对预处理后的数据用SPA进行波长的优选,然后利用优选的波长数据建立MLR校正模型,最小RMSE值对应的波长变量个数即为最终的选择结果。图2为提取不同个数波长变量时RMSE的走势图,从图中可知,提取7个波长变量时模型的RMSE最小为0.246 6。 Fig.2 RMSE in different wavelength variables 图3表示使用SPA筛选得到的7个特征波长,在图中以白色方块表示。7个特征波长分别为833,927,1 208,1 337,1 454,1 861和2 280 nm。其中,1 208 nm代表C—H二阶倍频伸缩,即CH2;1 454 nm代表O-H一阶倍频伸缩,表明存在淀粉成分;1 861 nm代表C—Cl六阶倍频伸缩;2 280 nm代表C—H伸缩和CH2变形组合,同样表明存在淀粉成分。 Fig.3 Optimal characteristis wavelengths selected by SPA 2.5 SVM模型验证 以SPA提取的7个波长数据作为输入,利用SVM进行分类模型的建立和验证。利用RBF函数作为SVM的核函数,在惩罚参数C=7 760 469,核函数参数γ=0.017 003的条件下,建立分类模型。利用建立好的模型对训练集和测试集进行预测,预测结果如表4所示。 可以看出训练集的90个样品中,有1粒重度霉变的颗粒被错判为无症状组,1粒被错判为中度霉变,判别准确率为97.78%。测试集的60个样品中,有1粒无症状组的颗粒被错判为中度霉变,1粒中度霉变组的颗粒被错判为重度霉变,2粒重度霉变的颗粒被错判为无症状组,判别准确率为93.33%。分析错判原因,在对颗粒进行分组挑选时,可能会由于部分霉变无法用肉眼识别,从而造成错分。 Table 5 Classification result Table 5 Predictive result of the independent validation set 同时,为了验证模型的通用性,另取2013年收获的先玉335玉米颗粒,并以相同的分组标准每组挑选30粒共90粒作为独立验证集,利用21个窗口的移动平均平滑法进行预处理,然后将7个特征波长的信息输入到已建立的判别模型中,判别结果如表5所示。可以看出,独立验证集的预测准确率达到91.11%,表明本文所建立的判别模型具有通用性。 按照霉变程度将同年收获的自然感染霉菌的豫玉32玉米颗粒分成三组,运用波长范围在833~2 500 nm的FT-NIR系统进行光谱数据的采集,首先采用21个窗口的移动平均平滑法对样本数据进行预处理,并利用SPXY算法对样本集进行划分;然后为了对光谱数据进行降维,利用SPA筛选特征波长,选取7个特征波长数据作为输入,利用SVM进行分类模型的建立和验证。最终建立的模型对训练集及测试集的预测准确率分别达到97.78%和93.33%。另取2013年收获的先玉335玉米颗粒,以同样的标准挑选90粒作为独立验证集,按照相同的方法进行预处理,所建立的判别模型对独立验证集的预测准确率达到91.11%。结果表明基于SPA和SVM能有效地对霉变玉米颗粒进行判别,所选取的7个特征波长为在线霉变玉米颗粒近红外检测提供了理论依据。 [2] LIU Xin-ru, ZHANG Li-ping, WANG Jian-fu, et al(刘心如, 张黎平, 王建福, 等). Spectroscopy and Spectral Analysis(光谱学与光谱分析), 2013, 33(8): 2092. [3] LIANG Jian, LIU Bin-mei, TAO Liang-zhi, et al(梁 剑,刘斌美,陶亮之,等). The Journal of Light Scattering(光散射学报), 2013, 25(4): 423. [4] Singh C B, Jayas D S, Paliwal J, et al. International Journal of Food Properties, 2012, 15(1): 11. [5] YAO Hai-bo, Hruska Z, Kincaid R, et al. Biosystems Engineering, 2013, 115: 125. [6] Bregman L M. Akademiia Nauk SSSR, Doklady, 1965, 162: 487. [7] Tallada J G, Wicklow D T, Pearson T C, et al. Transactions of the ASABE, 2011, 54(3): 1151. [8] Galvão R K H, Araujo M C U, José G E, et al. Talanta, 2005, 67(4): 736. [9] CHU Xiao-li(褚小立). Molecular Spectroscopy Analytical Technology Combined with Chemometrics and Its Applications(化学计量学方法与分子光谱分析技术). Beijing: Chemical Industry Press(北京: 化学工业出版社), 2011. *Corresponding author Selection of Characteristic Wavelengths Using SPA and Qualitative Discrimination of Mildew Degree of Corn Kernels Based on SVM YUAN Ying, WANG Wei*, CHU Xuan, XI Ming-jie Beijing Key Laboratory of Optimization Design for Modern Agricultural Equipment, College of Engineering, China Agricultural University, Beijing 100083, China The feasibility of Fourier transform near infrared (FT-NIR) spectroscopy with spectral range between 833 and 2 500 nm to detect the moldy corn kernels with different levels of mildew was verified in this paper. Firstly, to avoid the influence of noise, moving average smoothing was used for spectral data preprocessing after four common pretreatment methods were compared. Then to improve the prediction performance of the model, SPXY (sample set partitioning based on joint x-y distance) was selected and used for sample set partition. Furthermore, in order to reduce the dimensions of the original spectral data, successive projection algorithm (SPA) was adopted and ultimately 7 characteristic wavelengths were extracted, the characteristic wavelengths were 833, 927, 1 208, 1 337, 1 454, 1 861, 2 280 nm. The experimental results showed when the spectrum data of the 7 characteristic wavelengths were taken as the input of SVM, the radial basic function (RBF) used as the kernel function, and kernel parameterC=7 760 469,γ=0.017 003, the classification accuracies of the established SVM model were 97.78% and 93.33% for the training and testing sets respectively. In addition, the independent validation set was selected in the same standard, and used to verify the model. At last, the classification accuracy of 91.11% for the independent validation set was achieved. The result indicated that it is feasible to identify and classify different degree of moldy corn grain kernels using SPA and SVM, and characteristic wavelengths selected by SPA in this paper also lay a foundation for the online NIR detection of mildew corn kernels. Mildew grain;Corn kernels;FT-NIR;SPA;SVM Aug. 21, 2014; accepted Dec. 5, 2014) 2014-08-21, 2014-12-05 国家科技支撑计划项目(2012BAK08B04)资助 袁 莹,女,1991年生,中国农业大学机械工程硕士研究生 e-mail:410708790@qq.com *通讯联系人 e-mail: playerwxw@cau.edu.cn S132 A 10.3964/j.issn.1000-0593(2016)01-0226-05
2 结果与讨论





3 结 论
猜你喜欢
特产研究(2022年6期)2023-01-17 05:06:16北京航空航天大学学报(2022年8期)2022-08-31 08:58:58制导与引信(2017年3期)2017-11-02 05:16:56实用口腔医学杂志(2017年6期)2017-09-19 02:51:28中国照明(2016年4期)2016-05-17 06:16:15工业设计(2016年11期)2016-04-16 02:50:19中国光学(2015年5期)2015-12-09 09:00:28环境科技(2015年6期)2015-11-08 11:14:26物理实验(2015年9期)2015-02-28 17:36:46电网与清洁能源(2015年2期)2015-02-28 16:03:07
