
一种基于硬件的10G网络中TCP流处理方法
2016-06-06 07:50赵正伟安永果李洪磊
无线电通信技术 2016年3期
赵正伟,张 英,安永果,李洪磊
(1.中国电子科技集团公司第五十四研究所,河北 石家庄050081;
2.军械工程学院 信息工程系,河北 石家庄050003;
3.西安卫星测控中心,陕西 西安 710043)
一种基于硬件的10G网络中TCP流处理方法
赵正伟1,张英2,安永果3,李洪磊1
(1.中国电子科技集团公司第五十四研究所,河北 石家庄050081;
2.军械工程学院 信息工程系,河北 石家庄050003;
3.西安卫星测控中心,陕西 西安 710043)
摘要:近年来,设计高速的网络设备用以在流层面进行分组处理,一直是工业界和学术界的研究热点。10G网络下的TCP流处理同时面临性能问题和异常情况的处理。真实流量的许多特性,会导致基于硬件的TCP流处理系统内存耗尽。针对这种情况,提出并实现了一种用于10G网络中TCP流处理的硬件设计方法,能够处理百万量级TCP流的分组重组和状态跟踪。该解决方案提出了大规模流表的流替换算法和对全局流表的快速的单轮访问方式,采取了对乱序数据缓冲管理的主动释放策略,设计了一种无链的数据结构,保证了最坏情况下的处理时间要求。仿真结果显示,该系统可以处理超过99%的10G网络流量。基于FPGA的硬件原型也验证了系统的设计。
关键词:10G网络;硬件加速;TCP重组;TCP状态跟踪
0引言
随着网络带宽的迅速增长和网络流量处理需求的日益复杂,采用定制的硬件进行网路流量处理与分析已成为共识[1]。从IP层的分组过滤到应用层的数据过滤,硬件加速已被应用到网络的各个层次[2-3]。
10G网络中TCP处理的性能瓶颈在于对流记录表的访问上[4]。这就需要解决内存访问的瓶颈,充分利用硬件并行性进行高速的TCP处理;在基于硬件的TCP流状态跟踪系统提供记录的替换机制。
本文在分析数据中心真实流量的基础上,提出了一个基于硬件的TCP流状态跟踪和重组解决方案,能够支持10 MPPS的处理速度,并且能够保证最坏情况下的处理时间要求。对真实的流量分析结果显示,该方案可以使用合理的资源处理99%的10G网络流量。我们也用FPGA实现了一个原型,验证了该系统的设计。
1真实Trace分析
我们采集了某公司和某研究机构的数据中心中汇聚链路的trace,带宽分别是10G和1G,持续时间约60 min。下文中分别称为Trace_10G和Trace_1G。
trace中出现的TCP流可分为3类[5]:第一类是没有头部的流(headless flow),这些流在trace开始之前建立,其SYN分组没有被采集到;第二类是完整的流(complete flow),在trace开始之后建立,并且在trace停止之前结束;第三类是没有尾部的流(tailless flow),在trace开始之前建立,并且在trace停止之前没有结束。如果在trace停止时,一条流有未填充的序号但是其FIN分组已经到达,这条流仍然被看做是没有尾部的流。
对2个trace的真实流量进行了统计分析[6],分析结果如表1所示。可以看出,2个trace的乱序流的比例都小于1%,所需要的最大缓冲均超过10 MB。

表1 真实流量分析
Trace_10G中不同类型流的数目随时间的变化情况如图1所示。活动流是连接已经建立并且没有结束的流,图中显示活动流的数目一直在增加。在trace停止时的活动流就是无尾流,为辨别无尾流的活动性,统计了这些流最后一个分组到达时间和trace停止时间的间隔,称之为分组的间隔时间,如图2所示。

图1 Trace_10G的流情况统计

图2 Trace_10G的分组间隔累积分布
图中右侧可以看出,在trace停止时,无尾流在超过100 s的时间内没有收到任何分组。图中左侧的曲线是每条流中相邻的2个分组的间隔时间。大多数的间隔时间都超过100 s,也就是说,许多实时流没有收到FIN但是已经不传输数据了,这些流称为僵尸流(zombie flow)。TCP子系统必须为每条无尾流分配一条流记录以用于TCP重组,无尾流数目的持续增加不可避免地导致内存耗尽。
图3是一条流的分组重组所需缓冲的累积分布,从图中可以看出,几乎所有的分组重组所需要的缓冲都不超过40 KB。

图3 分组重组所需缓冲的累积分布
2TCP处理框架
从前面对真实流量的分析可知,只有一部分的TCP流有乱序情况发生[7]。为了能够处理10 Gbps的高速流量,采用快速通道分组处理顺序流的分组,其执行时间是固定的;用另外的一个慢速通道处理乱序流的分组。
此外,真实流量的2个特性也必须考虑:① 由于僵尸流的存在,必须设计流记录的替换机制[8],这可能导致一个新接收到的分组找不到它的相关记录,称之为无记录分组;② 因为没有足够多的缓存,小部分的流不能完成TCP重组,将这些流视为异常流。无记录分组和异常流的分组将被上传到主机,并由主机的TCP子系统处理。
2.1带替换优先级的流表
为了进行替换操作,需要维护一些替换操作所需的信息,提出了一种带替换优先级的流表。把流记录存放在二维的数组里,每一行就是一个链表,存储了流记录以及一个哈希值,该哈希值等于行号。每一行还是一个哈希冲突链,其长度就是哈希冲突链所允许的最大长度。查询一个分组的相关记录需要2个步骤:首先根据分组的四元组的哈希结果找到目标记录的行号,接着在该行中找到目标记录。对每行增加一个替换优先级域,用于记录该行所有记录的替换优先级,用以在需要时把该记录替换出去。
替换优先级域由次序域和计数器域组成。次序域是0,1,2,3…n-1的一个排列(n是行的长度),每个数字代表该行中的对应列所表示的流记录,次序域占用(n-1)×log2n位。次序域是该行中所有记录的替换顺序,最右侧的数字表示最优先被替换出去的记录的列号。当一行中没有空闲的记录可以使用时,次序域的值全为0。计数器域记录该行已经被使用的记录的数目,占用log2n位。如果计数器域和次序域全为0,表示该行所有的记录都没有被使用,其他情况下计数器域为0表示该行n个记录全被使用。整个替换优先级域占用n×log2n位,当行的长度是4的时候,每行只需要一个字节就可以存储替换操作所需的全部信息。替换优先级处理过程如图4所示。
存储替换优先级有2种选择:分离的流表和合并的流表。如果流表不是很大(小于10M行),替换优先级可以存储在cache中,即SRAM或者FPGA的Block RAM中,而不是DRAM中,这种流表称之为分离的流表;如果流表的行数大于10M,替换优先级就不能被存在SRAM里了,需要把替换优先级和流记录都存在DRAM里,这种流表称之为合并的流表。

图4 替换优先级变化示意图
2.2两级流表
流表的2种存储方法具有各自的缺点:分离的流表访问效率较高,但是支持的流的数目有限;合并的流表的容量只受DRAM容量的限制,因而可以支持千万量级的活动流,但是其获取替换优先级的延迟很大,导致在处理分组之前必须等待。
为克服上述缺点,设计了两级的流表。第一级称为全局流表,用于存储活动流的简化记录,简化记录包括处理无乱序情况的TCP流所需的全部信息,如四元组和期望的序号;第二级称为乱序流表,对每条乱序流维护一个乱序记录,乱序记录的内容包括TCP重组所需要的全部信息,如乱序报文段的地址和长度,以及两个乱序报文段之间的间隔大小。
全局流表是一个合并的流表,它记录的长度很小,可以在一个DDR read burst内读取替换优先级和一行的所有记录,并且可以在一个write burst内写回更新数据。
对乱序流来说,由于只有一小部分的流有乱序情况发生,所以采用分离的流表更合适。替换优先级可以以较低的延迟从cache中获取,然后根据替换优先级的次序域逐条读取记录。考虑到流分组的局部性,一次就读到目标记录的概率很高,所以更大的乱序记录不会引入额外的存储开销,64或128 bytes就足够使用。
如果数据流没有乱序情况发生,就由快速通道处理,首先获取全局的流表,接着根据流记录内容和分组头更新流的状态。如果有乱序情况发生,就由慢速通道处理,必须从乱序流表中获取乱序记录并完成TCP重组。
2.3快速通道处理
快速通道处理首先根据分组四元组的哈希结果,从全局流表里取得目标行,继而找到流记录,并更新该流的状态。如果没有发生乱序,并且分组序号和期望序号相等,用分组的长度更新流的状态。否则,流被标记为乱序流,这个标记在流的生命周期内不会被取消,该流的所有后续分组都将由慢速通道处理。
全局的流记录里包含快速处理通道所需的全部信息,包括:
CA,SA:客户端/服务端地址;
CP,SP:客户端/服务端端口号;
CSEQ,SSEQ:客户端/服务端期望序号;
CS:连接状态。
一条全局流记录需要24 bytes,如果全局流表的一行是128 bytes的话,每行能存放5条记录。这个值也可以设置为32 bytes,多余的字节可以用于扩展。
2.4慢速通道处理
慢速通道用来处理乱序的流。首先在cache中读取替换优先级,继而找到对应的乱序记录,并根据记录的相关域、序号以及分组长度对分组进行重组。TCP重组包括以下步骤:将当前分组写入乱序缓冲,从乱序缓冲中读取数据,如果当前分组填满了期望序号和乱序数据之间的空隙(gap),就上传到主机。如果一条流的重组太复杂,慢速通道不能完成处理,则将其视为异常流,乱序流表将丢弃异常流,但是全局流表将保留异常流的记录,并在状态域中对其打上异常标记。
乱序流记录包括慢速通道处理所需的全部信息,除了前面提到的全局流记录之外,全局流表还包括以下的数据:
CBA:客户端到服务端乱序缓冲基地址;
SBA:服务端到客户端乱序缓冲基地址;
CSEQOFF,SSEQOFF:乱序缓冲中期望的序号偏移;
DSV:数据报文有效标识;
DSD:数据报文方向;
DSH1~N,DST1~N:数据报文头/尾指针。
其中,N是一个连接可以容纳的乱序数据报文的数目,S是乱序数据缓冲的大小。
对每个乱序的TCP流进行重组时,需要一块连续的固定长度的存储空间。如果乱序数据的大小超过该空间的大小,慢速通道不会为这条流申请新的缓冲区,而是把它视为异常流,将其流记录和乱序数据上传到主机,其后续的分组将直接上传到主机。与每次申请一小块页面(page)继而将这些页面链接起来的缓冲区管理策略比起来,这种策略要简单得多。如果一条流长时间占用缓冲,说明这条流的最后一个分组已经到达很长一段时间,这条流很可能是一条僵尸流。采用一种主动释放策略来处理这些流。由于限制了乱序流表的大小,所以在较长的时间内没有收到新的分组的乱序流将会被替换出去,并不额外消耗数据缓冲,而在全局流表中,是通过申请尽可能多的空间来替换可能是僵尸流的流,造成数据缓冲的额外开销。
2.5优化
在上述方案中,对全局流表的访问非常有规律,不需要在控制器中进行复杂的调度。每个分组只需要一个burst read和一个burst write,所以,通过调整分组的输入顺序就可以达到高效的bank-level并行,如图5所示。

图5 Round-Robin分组请求
在工作模块(working module)之前放置一组FIFO,FIFO和DRAM的bank之间是一一对应关系。FIFO中待处理的所有分组的相关记录都位于对应的bank中。这里有一个分发模块,以轮转方式从FIFO中取出分组,然后再送到工作模块中。多个工作模块并发访问全局流表,形成了对bank的交织访问。这种没有内存控制器参与的策略称为RRPR(Round Robin Packet Request)。慢速通道由于只有一小部分的分组需要访问乱序流表。所以不需要使用RRPR。
3系统实现
在硬件系统中实现TCP处理框架,需要2个DDR2内存模块:全局流表独占一个,另一个由乱序流表和乱序数据缓冲共享。用2个SRAM芯片存储分组的有效载荷以及乱序流表的替换优先级。系统架构如图6所示。
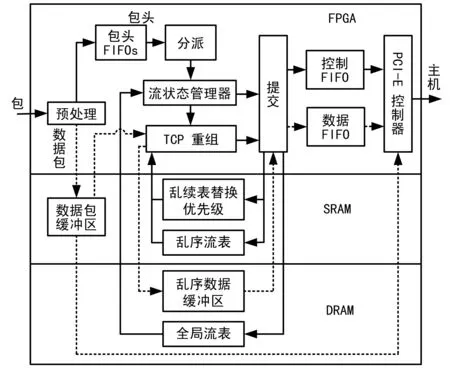
图6 系统架构图
模块之间沿实线传输的是分组头及其相关数据结构,沿虚线传输的是分组的有效载荷。
数据预处理模块过滤掉非TCP的分组,根据四元组计算哈希值(用于索引各种数据结构),提取分组的有效载荷并将其存入SRAM中。接着创建一个header结构,包括分组头、哈希值、有效载荷的SRAM地址,并把这个头结构传递给后继模块。
流状态管理器接收到头结构后,从全局流表中取出流记录,如果是乱序流则把头结构传递给乱序流处理模块,否则更新头结构,并将其传递给提交模块。
重组模块完成乱序TCP流的重组,并更新乱序记录的相关域,该模块不涉及分组载荷的传输。
提交模块负责更新各种数据结构,包括全局流表、乱序流表、乱序流表的替换优先级以及缓存乱序分组的载荷。
4系统评价
本节中采用软件算法仿真来对真实流量进行离线分析,对基于硬件的TCP处理框架进行性能和容量评价[9]。另外实现了一个FPGA的原型,用于硬件资源评估。
4.1性能评价
用DRAMsim[10]来分析系统的吞吐量。使用DRAMsim默认的DDR2配置,DDR2-400,时序参数3-3-3-9,单通道数据总线宽度为64 bytes,cache line大小(即burst length)为128 bytes,1个rank,4个bank,地址映射采用sdram_hiper_map,控制器的事务选择方式为FCFS,芯片延迟为2。CPU主频(即FPGA的工作频率)设置为200M。
图7显示的是在不同的配置下,处理这个内存请求序列时的内存效率。可以看出RRPR能显著地提高内存访问效率。当有2个工作模块同时访问全局流表的时候,控制器的效率达到峰值。原因在于每个工作模块并发访问2个bank。所以在4个bank的DRAM中,3个工作模块将会导致频繁的bank冲突。当DDR2-400的访问效率是80%时,内存控制器每秒可以处理20M次突发访问,也就是说系统可以处理10 MPPS。真实流量中分组的平均长度约是400 bytes,即10G流量下3.36 MPPS。由此可以得出结论,该TCP子系统可以处理10G的真实流量。

图7 访问全局流表时的内存总线效率
4.2容量评价
假设全局流表只有4M条记录,占用128 MB。使用3种类型的全局流表:2M×2,1M×4,和512K×8。使用2种替换策略:LRE选择一行中最早建立的流的记录,并将其替换出去;LRU选择一行中最不活跃的流(即最长时间没有收到新的分组的流)的记录,并将其替换出去。对一分钟内被替换记录和无记录分组情况进行统计。
结果表明:对于无记录分组的数目,LRU的效果要比LRE好得多,这与期望是一致的。只考虑LRU,与4列或8列相比,2列情况下的无记录分组数目要大得多。在全局流表是4列的情况下,2个trace的无记录分组的比例分别为0.14%和0.013%。
对异常流会有2种结果:一种是这条流收到的乱序分组的数目超过了给它分配的缓冲区大小;另一种是这条流有太多的乱序数据报文,以致于乱序记录不能保存所有的数据段的状态。对这种情况的统计如表2、表3和表4所示。

表2 Trace-10 G中乱序缓冲溢出时的异常流数目

表3 Trace-10 G中不同乱序表情况下的异常流数目

表4 Trace-10 G中乱序数据报文溢出时的异常流数目
从表2中可以发现,如果一条流的乱序数据超过64 KB,那么这条流通常都大于1 MB。所以,把缓冲区的大小由64 KB增大至1 MB并不能解决问题。表3列出了在主动释放策略下,不同的乱序流表情况下的异常流数目。表3中每个分组的平均访问时间非常接近1,说明大多数情况下,LRU策略从目标行中取出的第一个记录就是当前分组的相关记录。
在主动释放和非主动释放策略下的内存使用情况比较如图8所示。主动释放策略能显著降低缓冲区的大小,同时异常流的数目几乎没有增加。

图8 主动释放策略下的乱序数据缓冲需求
根据表4的统计,必须考虑在一条流中同时处理2个或更多的乱序数据段。考虑到乱序数据记录的大小,每个记录保留4-6个数据段是很有必要的。
综合考虑所有因素,把全局流表设置为2M×4,乱序流表设置为4K×16,一条流支持的最大并发乱序数据段设置为6。一条乱序流的数据缓冲设置为64 KB。统计了Trace_10G的后面30 min的情况。结果显示,0.23%的TCP分组是无记录分组,0.76%的分组属于异常流。全部的内存需求,包括2个流表以及乱序数据缓冲,小于512 MB。假设处理10G的网络流需要的资源是Trace_10G的4倍(Trace_10G中流量的平均速率是2.6G),处理10G流量时,TCP子系统所需的DRAM是2 GB,目前的技术完全能够支持。
4.3FPGA原型
为了验证我们的设计,实现了一个基于FPGA的10G POS网卡。FPGA采用Xilinx Virtex5 LX110t[11],FPGA接收的数据来自一个Cortina OC192 Integrated Framer,CS1777[12]。设计的逻辑开销如表5所示,设计的频率能达到250 MHz。

表5 Virtex5 LX110t的设备利用率
FPGA器件在逻辑资源利用率为50%~70%时可以达到性能和资源利用的最优[13-14]。表5的统计数据表明,输入/输出模块使用率较高,存储器使用率适中,其他逻辑单元使用率偏低。总之,文中解决方案的实现不需要过多的FPGA资源。
5结束语
本文提出了一种基于硬件的TCP状态跟踪和重组解决方案。该方案采用高效的流记录替换算法,来应对活动流数目的持续增长;采用主动释放乱序数据缓存的策略,以避免缓存分组造成内存耗尽。
文中的解决方案能够到达10 MPPS的处理速度,在合理的内存资源下,能够处理99%的10G流量。对于如何更加合理利用FPGA资源以获得更高的TCP流处理速度需要进一步的研究和探索。
参考文献
[1]SONG Tian,ZHANG Wei,WANG Dong-sheng,et al.A Memory Efficient Multiple Pattern Matching Architecture for Network Security [C] ∥Proc of INFOCOM 2008.Phoenix :IEEE,2008:166-170.
[2]孙召敏,杨越,陈启美.云基础设施中TPL2-SW网络模型的优化[J].计算机应用研究,2012,29(6):2268-2273.
[3]郭勇,陈艳玲.多发多收网络仿真器的FPGA实现及测试[J].无线电工程,2013,43(1):4-6.
[4]苏琪,龚俭,苏艳珺.基于抽样流记录的RTT估计[J].软件学报,2014,25(10):2346-2361.
[5]王远,丁伟,龚俭.TCP数据流超时研究[J].厦门大学学报(自然科学版),2007,46(增刊2):192-195.
[6]龙剑友,王维,何晶.网络流量自相似性的影响因素[J].吉首大学学报(自然科学版),2008,29(4):38-41.
[7]Dharmapurikar S,Paxson V.Robust TCP Stream Reassembly in the Presence of Adversaries [C] ∥Proc of 14th Conference on USENIX Security Symposium.Berkely:USENIX Association,2005:5-5.
[8]廖鑫.一种基于LRU算法改进的缓存方案研究与实现[J].电子工程师,2008,34(7):46-48.
[9]夏爱民,刘栋,张帆.TCP拥塞控制建模分析方法[J].无线电工程,2011,41(8):4-5.
[10]Wang D,Ganesh B,Tuaycharoen N,et al.DRAMsim:A Memory System Simulator[J].SIGARCH Computer Architecture News,2005,33(4):100-107.
[11]Xilinx.Xilinx University Program XUPV5-LX110T Development System [OL].http:∥www.xilinx.com/univ/xupv5-lx110t.htm.
[12]Cortina Systems.OC192/48 Integrated Framer [OL].http:∥www.cortina-systems.com/products/view/4.
[13]高丽丽.基于Xilinx V5的SAR_GMTI若干关键技术的实现[D].西安:西安电子科技大学 ,2013:31-32.
[14]陈雪峰,刘洋.基于FPGA的北斗卫星信号快速捕获[J].无线电工程,2014,44(3):46-49.
A Hardware-based TCP Flow Processing Solution in 10Gbps Network
ZHAO Zheng-wei1,ZHANG Ying2,AN Yong-guo3,LI Hong-lei1
(1.The 54th Research Institute of CETC,Shijiazhuang Hebei 050081,China;2.Department of Information Engineering,Ordnance Engineering College,Shijiazhuang Hebei 050003,China;3.China Xi’an Satellite Control Center,Xi’an Shaanxi 710043)
Abstract:There is an increasing interest in designing high-speed network devices to perform packet processing at flow level.However,TCP processing for 10Gbps network traffic needs not only to address performance problems but also to cope with abnormal conditions.Some characteristics of real traffic,will result in memory exhaustion in hardware-based TCP processing subsystem which is less flexible for exceptional processing.For this case,this paper presents a hardware design which is capable of processing real traffic in 10G networks with TCP reassembly and tracking states of millions of parallel TCP flows.The solution has several features:①a simple and effective implementation of flow replacement algorithm for massive flow table;②fast one round access to global flow table;③an active release policy for out-of-order data buffer management;④a link-less data structure which ensures time limit for worst case processing.The simulation result shows that the system can process over 99% of the 10G network traffic.A FPGA-based prototype is also implemented for evaluation.
Key words:10G network;hardware acceleration;TCP reassembly;TCP state tracking
中图分类号:TP391.4
文献标志码:A
文章编号:1003-3114(2016)03-70-6
作者简介:赵正伟(1982—),男,博士,工程师,主要研究方向:航天测控。张英(1982—),女,硕士,讲师,主要研究方向:军用通信技术。
基金项目:国家高技术研究发展计划(863计划)项目(2013AA122105)
收稿日期:2016-01-05
doi:10.3969/j.issn.1003-3114.2016.03.19
引用格式:赵正伟,张英,安永果,等.一种基于硬件的10G网络中TCP流处理方法[J].无线电通信技术,2016,42(3):70-75,114.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
计算机与现代化(2022年7期)2022-07-29
数学物理学报(2022年2期)2022-04-26
河北大学学报(自然科学版)(2020年4期)2020-09-02
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
网络安全和信息化(2018年3期)2018-11-07
西安电子科技大学学报(2018年5期)2018-10-11
金桥(2018年4期)2018-09-26
电脑爱好者(2015年21期)2015-09-10
