
基于速度的空间轨迹停留点提取算法
2016-06-05 14:57侯颖超,王盼成,刘兴权,滕洁
地理与地理信息科学 2016年6期
侯 颖 超,王 盼 成,刘 兴 权,滕 洁
(中南大学地球科学与信息物理学院地理信息系,湖南,长沙 410083)
基于速度的空间轨迹停留点提取算法
侯 颖 超,王 盼 成*,刘 兴 权,滕 洁
(中南大学地球科学与信息物理学院地理信息系,湖南,长沙 410083)
空间轨迹中的停留点提取是将空间轨迹转换到语义轨迹的关键步骤。该文将速度变量引入停留点的提取,提出基于速度的时间聚类算法和速度聚类算法解决现有方法中的“伪停留点”和停留点丢失的问题。基于速度的时间聚类算法首先沿时间轴将轨迹点进行聚类得到候选停留点,然后利用速度阈值过滤候选停留点,得出实际停留点。速度聚类算法首先通过对速度的判断选取候选停留点,然后根据空间距离阈值对候选停留点的空间距离进行过滤,得出实际停留点,解决了停留点判断中的漏判问题。实验表明,基于速度的时间聚类算法对出租车轨迹数据(稳定时间间隔、不存在长时间轨迹点缺失)的空间轨迹停留点识别效果较好,而速度聚类算法更适用于步行轨迹(可能存在长时间轨迹点缺失)的分析。
停留点;空间轨迹;速度聚类;时间聚类
0 引言
随着全球卫星定位系统和基于无线蜂窝网的手机定位技术的发展,人们对于自身位置信息的获取越来越容易[1,2]。具有GPS定位功能的智能手机的普及和车载GPS的广泛使用,有助于获得大量高精度人类出行轨迹数据[3,4]。如何有效地分析利用这些数据,已成为当前学术界研究的热点问题。使用(longitude,latitude,time)记录的原始空间轨迹数据并不具备语义信息,不方便理解和使用。Alvares等提供了一个将坐标轨迹转换成语义轨迹的框架,并在实际工作中得到广泛使用[5,6]。该框架首先从连续记录的轨迹点中找出停留点,再将停留点和地名地址库相匹配(逆地理编码)得到停留的地名地址。这些按时间先后排列的地名地址点序列就是语义轨迹。因此,如何有效地找出轨迹中的停留点或停留区域,是从空间轨迹向语义轨迹转换过程中不可绕开的环节。
当前已有很多关于轨迹停留点的提取算法,大致可分3类:分割聚类算法、基于时间的聚类算法和基于密度的聚类算法。Ashbrook等利用K-Means算法设计了基于分割聚类的停留点挖掘方法[7]。该算法首先提取位置点,再用改进的K-Means算法将这些位置点聚类得到停留点,但该算法无法获取GPS信号未完全消失的室内地点。Kang等利用轨迹点的时间连续性设计了一个基于时间的聚类算法以挖掘停留点[8],然而GPS信号丢失问题会扰乱位置点的时间连续性,导致遗漏某些停留点。基于密度的聚类算法对位置点稠密区域进行聚类,如SMoT[9]、CB-SMoT[10]、DJ-Cluster[11]等,此类算法可发现任意形状的停留点,但难以解决GPS信号在室内丢失的问题。建筑物对GPS信号的屏蔽使得信号在进入和离开建筑物时产生两个聚类区,文献[12]在基于时间的聚类算法[8]基础上,根据时间间隔阈值和容忍距离阈值决定是否对这两个聚类区进行合并处理。但由于现实世界中的建筑物大小不一,经验值的选取较为困难,这种改进并不能有效地判别用户是仅从该建筑物内穿过还是在其内停留这一问题。
本文针对上述方法的不足,将速度变量引入停留点的提取,提出了基于速度的时间聚类算法和速度聚类算法。移动对象处于停滞状态时,速度字段的数值小于给定阈值,基于速度的时间聚类算法充分利用GPS轨迹数据这一特征,相对于轨迹记录的逐条处理而言,计算效率得到很大的提高。而对于未记录速度的GPS轨迹点,可以由上一点或下一点计算出速度值,因此基于速度聚类算法对于简易的GPS数据(longitude,latitude,time)同样具有很好的普适性,同时也能有效地避免停留点漏判问题。
1 移动对象停留点的提取算法
1.1 原始轨迹获取及预处理
空间轨迹由按时间先后顺序排列的空间点组成。空间点的数据结构可以是简单的(longitude,latitude,time),也可以是复杂的(longitude,latitude,time,altitude,radius,speed,direction)。
不同的应用场景,采集得到的空间轨迹特点不同。车载GPS不需要考虑省电问题,设备在车辆行进期间一直保持供电;由于行驶在户外,GPS信号一般不会丢失。因此车载GPS得到的空间点序列时间间隔恒定,一般不存在长时间位置信息缺失,是比较理想的空间轨迹处理样本。当前大多数的算法,也针对此类数据设计。通过手机取得的行人步行轨迹则不同,存在时间间隔变化大、较长时间位置信号缺失的情况。主要原因有:1)使用者进入建筑物内部,GPS信号消失,不能获取位置信息,造成空间点序列中相邻点时间间隔过长的情况;而在建筑物边缘靠门或窗的地方,接收到的卫星数目有限,位置精度不高,造成位置漂移或跳跃现象。2) 由于省电的要求,某些手机操作系统会杀死收集位置信息的后台服务进程;同样,用户出于省电的要求,也会有意识地禁用GPS位置服务。
上述原因使得个别定位点出现很大偏差,所以要识别异常点并将其剔除,即对轨迹进行清洗。轨迹清洗可采用以下规则:1) 手机上获取的位置信息一般包含radius字段,此字段记录了定位的精度,可以设定一定阈值,将radius值过大的记录剔除;2)采用文献[13]的方法剔除速率异常点、时间戳异常点和“跳跃点”。
1.2 基于速度的时间聚类算法
对于空间点 (longitude,latitude,time,altitude,radius,speed,direction)组成的空间轨迹,采用以下步骤进行处理:1)沿时间轴将速度为零的纪录通过时间阈值进行聚类,生成候选停留点;2)使用速度阈值对候选停留点进行过滤,得出实际停留点。
候选停留点的计算过程为:将移动轨迹中速度为零的点按时间顺序排列,将速度连续为零的轨迹点进行合并,使时间间隔小于某个阈值ε的相邻轨迹点成为一个聚类,即候选停留点。之所以称为“候选停留点”是因为存在如下情形:在相邻的采样时刻点上研究对象的速度为零,但相邻两个时刻点的时段内,研究对象却处于运动状态,其速度并不为零。例如出租车在当前时刻Ti处于位置Locationi,其速度为0,下一时刻Ti+1处于位置Locationi+1,其速度也是0,而在Ti和Ti+1两个时刻之间,车辆可能处于运动状态。因此得到的聚类可能是伪停留点。具体方法见算法1。
算法1 基于速度的时间聚类算法(候选停留点提取)
Input:Üm//速度为零的轨迹点记录,m为轨迹点数目
ε//时间阈值
Output:Ψn//候选停留点,n为候选停留点数目
1.Ψ0←Φ,i←1,j←1;
2.BEGIN;
3.FETCHLoc0∈Üm;
4.Tlast=Tstart=Loc0.time;//起始点的时间和位置
5.Locstart=Loc0;
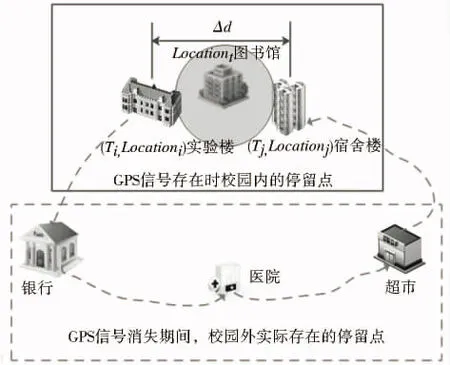
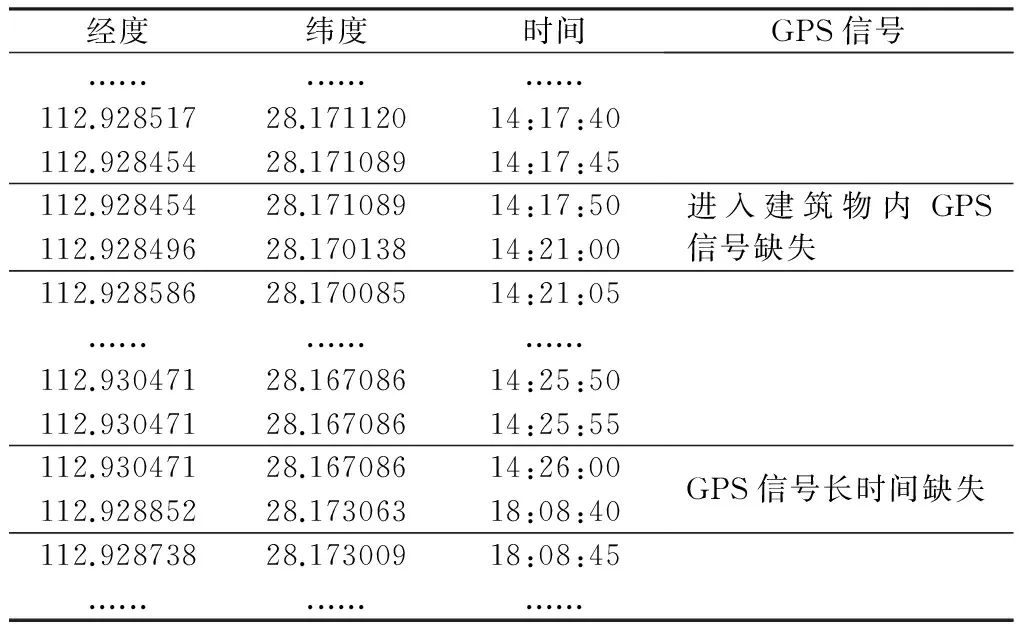
6.WHILEi 7.FETCHLoci∈Üm-i; 8.Tcurrent=Loci.time,Δt=Tcurrent-Tlast; 9.IFΔt<εTHEN //小于经验阈值,当前点和上一点聚合 10.Locend=Loci; 11.Tlast=Tend=Loci.time; 12.ELSE //聚合过程停止,记录候选停留点的信息 13.Loccenter=CenterOf(Locstart,Locend); 14.Rowj=(Tstart,Loccenter,Tend); 15.Ψj←Rowj; 16.j←j+1; 17.Tstart=Tlast=Loci.time;//准备进行下一次聚合 18.Locstart=Loci; 19.END IF; 20.i←i+1; 21.END LOOP; 22.RETURNΨn; 23.END 从候选停留点中筛选出停留点的过程为:对连续两个时刻内的运动状态进行判断,使用速度变量进行过滤,即如果Δd=Distance(Locationi,Locationi+1),v=Δd/Δt小于速度的经验阈值ρ,说明此移动对象在Δt时段内处于停止状态;否则,处于运动状态。具体方法见算法2。 算法2 基于速度的时间聚类算法(停留点提取) Input:Üm//候选停留点,m为候选停留点数目 ρ//速度阈值 Output:Ψn//停留点,n为停留点数目 1.Ψ0←Φ,i←0,j←1; 2.BEGIN; 3.WHILEi 4.FETCHregioni∈Üm;//判断候选停留点聚合过程中运动状态 5.v=CalVelocity(regioni.endPoint,regioni.startPoint); 6.IFv<ρTHEN 7.Ψ←regioni; //满足条件,归入停留点集合 8.j←j+1; 9.END IF; 10.i←i+1; 11.END LOOP; 12.RETURNΨn; 13.END 1.3 速度聚类算法 对于轨迹采样点数据缺失、采样频率不稳定(即采样间隔不确定)的情形,基于速度的时间聚类算法则不能够很好地适应。本文提出速度聚类算法对此类数据进行分析处理,将停留点的提取问题分解为对速度的判断和对GPS信号消失空间区域的判断两个子问题。 对于在时间轴上彼此相邻的轨迹采样点,如果这两个相邻点的距离-时间比(即速度)小于某一个阈值,则可认为移动对象在这两点所在时段内处于停留状态。在实际应用中,停留点中的GPS轨迹采样点并非表现为绝对的静止不动,而是一些小幅偏移点的聚合(图1中采样点聚集区是移动对象停留点)。假设在时间轴上有彼此相邻的4个采样点((Locationi-1,Ti-1)→(Locationi,Ti)→(Locationi+1,Ti+1)→(Locationi+2,Ti+2)),如果移动对象在前两个采样点之间的时段内(Ti-1,Ti)处于停留状态,在后两个采样点之间的时段内(Ti,Ti+1)也处于停留状态,也就是依次连续地处于停留状态,则将当前的停留状态与上一停留状态进行归并,即对连续的停留状态进行聚类从而形成停留点StayPoint((Locationi-1,Ti-1),(Locationi+1,Ti+1))。而对于(Locationi+2,Ti+2),如果在(Ti+1,Ti+2)时段内该移动对象依然处于停留状态,则继续向上述停留点归并,直到移动对象由停留状态转向运动状态,最终得到停留点为StayPoint((Locationi-1,Ti-1),(Locationi+2,Ti+2))。 图1 速度聚类算法 在现实环境中存在的另一问题就是移动对象遭遇信号盲区,即GPS信号在某一区域内消失,进而导致在该区域内轨迹数据缺失。而GPS信号缺失主要分为两类情形:1)由于屏障的存在而引起,诸如车辆进出隧道、行人通过地下通道或进出大型建筑物等情形;2)由于GPS轨迹采集器本身存在的问题而引起,如手机端的GPS轨迹采集器因手机没电而停止,或出于省电的考虑用户手动关闭GPS轨迹采集器。对于前一种情形,移动对象在一定时间内很少再次返回到该地点,根据空间距离-时间比(速度)这一条件判断移动对象所处的运动状态;对于后一种情形,当GPS信号在某一地点长时间缺失后在该地点附近再次出现时,可能形成信号盲区内的伪停留点。如果仅仅根据速度这一条件判断移动对象的运动状态,则可能将伪停留点误判为实际停留点。下面是一个可能产生伪停留点的例子:某高校学生志愿者,上午Ti时刻在某实验楼Locationi时GPS信号存在,由于某种原因GPS信号长时间缺失,直到晚上Tj时刻回到宿舍楼Locationj时信号再次出现,这段时间内该学生已从实验楼到过其他若干地方,最后再回到宿舍。如果仅仅通过速度确定停留点(v<ρ,则认为处于停留状态),就会出现很大的偏差。这种情形下该停留点的中心是实验楼Locationi和宿舍楼Locationj的区域中心处——图书馆Locationt(图2),而现实情况是图书馆并非是该学生的停留点(此时,图书馆是一个信号盲区内的伪停留点)。信号盲区的存在会影响对移动对象真实停留点描述的准确性。 图2 GPS信号消失重现形成的伪停留点 对于上述情形,可借助空间距离阈值BlindRegion对两个采样点的空间距离Δd进行过滤。如果相邻两个采样点间的空间距离过大(超出经验距离阈值),且通过速度变量判断处于停留状态的区域,则认为这两点间存在信号消失和重现情况,两个相邻的采样点应隶属于不同的停留点集合。具体实现方法见算法3。 算法3 速度聚类算法 Input:Üm//移动对象全天的轨迹点,m为轨迹点数目 ρ//速度阈值 blindRegion//信号盲区阈值 Output:Ψn//轨迹点中的停留点集合,n为停留点数目 1.Ψ0←Φ,i←1,j←0;flag←0,isMove=1; 2.BEGIN; 3.FETCHLoc0∈Üm; 4.WHILEi 5.FETCHLoci∈Üm-1; 6.v=CalVelocity(Loci-1,Loci); //相邻采样点间的平均速度 7.Δd=CalDistance(Loci-1,Loci);//相邻采样点间的空间距离 8.IFv<ρANDΔd 9.flag←flag+1;//相邻点处于停止态flag自增,连续停止 flag不断自增 10.IFisMove>0 THEN; 11.Tstart=Loci-1.time; 12.Locstart=Loci-1; 13.END IF; 14.isMove=-1; 16.Tend=Loci.time; 17.Locend=Loci; 18.END IF; 19.ELSE //离开停留点,处于运动状态 20.isMove=1; 21.IFflag>0 THEN //记录前一停留点的信息 22.Loccenter=CenterOf(Locstart,Locend); 23.Rowj=(Tstart,Loccenter,Tend); 中国各个时期园林呈现不同的文化特质。秦汉时期的园林主流是一种人工的自然山水园,注重模仿自然和模拟景致的自然美,对于雄奇壮丽的自然美缺乏一种具有人文意蕴的审美意识。这个时期园林文化呈现的特质是居住与园林相结合的宅园,注重的是形似,缺乏精神和意境的追求。 24.Ψj←Rowj,j←j+1; 25.END IF; 26.flag←0;i←i+1; 27.END IF; 28.END LOOP; 29.RETURNΨn; 30.END 本文提出的算法通过扩展空间数据库PostGIS/PostgreSQL实现。对于特别要求效率的部分,使用C语言编写成数据库扩展[14,15],其他部分则直接使用数据库的过程语言PL/pgSQL实现。原始轨迹数据使用分区表存储在空间数据库,停留点的提取通过SQL语句直接进行,生成的结果直接存成数据库中的表,方便后续应用。 2.1 出租车轨迹的停留点提取 本实验使用的GPS轨迹数据为某城市1个月的出租车运动轨迹,记录了车辆的longitude、latitude、time、direction、speed以及上下客信息。出租车GPS轨迹上报的时间间隔为35~40 s。此数据为典型的稳定时间间隔的轨迹数据[16,17]。 设在基于速度的时间聚类算法中采用的参数为:ε=45 s,ρ=1 m/s,长时停留点的停留时间下限为90 s;速度聚类算法选用的速度经验阈值也是1 m/s,长时间停留点的停留时间下限同样选取90 s。图3是某辆车全天24 h在某城市道路网上的轨迹点和两种算法提取的停留点。 图3 两种算法的停留点比较 由图3可以看出,停留点大多位于路口,这符合出租车因红灯而停留的情况;同时,结果中也包含了出租车上下客形成的停留点。与速度聚类算法相比,基于速度的时间聚类算法可以找出其无法识别的停留点(如图3中A-H),因此,更适合出租车数据的处理。 对于基于速度的时间聚类算法,本实验的时间阈值ε略大于GPS轨迹采样间隔的上限值。若ε过小,则聚类结果会产生过多的候选停留点,增加了停留点筛选的计算量;若ε较大,则聚类产生的候选停留点太少,会遗漏真实的停留点。在两个算法对比的过程中,考虑到出租车在35~40 s的GPS轨迹采样间隔内可能停留的情形,本实验将停留时长较短的停留点剔除,只选取停留时长大于90 s的停留点。随机选取3辆出租车的轨迹,使用两种算法分别提取停留点并计算重合率,重合率均达90%以上。 2.2 步行轨迹的停留点提取 本次实验数据通过手机App获取,设定采样间隔为5 s。实际获取数据如表1所示,有信号缺失情况。轨迹数据中含有radius(即GPS信号中的定位精度)字段,在对轨迹数据进行清洗时,将radius>15 m的轨迹点删除。轨迹采集志愿者手动上报真实停留点,用来和实验得到的停留点进行对比分析。 表1 步行GPS轨迹数据 图4(彩图见封2)为采用文献[12]改进的基于时间的聚类算法计算得到的停留点结果。图中的红色圆圈代表停留点或伪停留点,其半径大小代表停留时长;黄色小点代表行人的GPS轨迹点,局部放大图形中红色箭头代表行进方向。可见其选取的时间阈值依赖于建筑物的大小。如果时间阈值过小,不能剔除通过大型建筑物时形成的伪停留点(图4a);当时间阈值过大,通过小型建筑物并在其中停留的真实停留点将被遗漏(图4b)。 图5(彩图见封2)为本文提出的速度聚类算法计算得到的结果。步行速度阈值设定为0.1 m/s(该阈值与日常生识相符,小于该阈值则认为处于停留状态),BlindRegion设定为200 m。图5a中是基于未设置BlindRegion参数的速度聚类算法对轨迹停留点进行挖掘的结果,此时出现伪停留点(被红色圆圈标记的红色圆域)。图5b中使用速度聚类算法将BlindRegion设置为200 m,对志愿者轨迹点的停留点进行挖掘,其中局部放大的图形是志愿者早上进入食堂用餐所形成的停留点,蓝色圆圈是志愿者穿过建筑物GPS信号消失的区域,根据运行速度可知用户仅仅是通过这些建筑物而非停留。 图4 改进的基于速度的时间聚类算法 图5 速度聚类算法 速度聚类算法不涉及时间阈值,且其速度阈值是独立的,不依赖于建筑物的大小。对比图4和图5可以看出,速度聚类算法较好地避免了停留点识别过程中的误判和漏判问题。 关于BlindRegion参数的设定,如果设置过大,将会使不同的停留点聚合为一个停留点,从而产生细粒度(大比例尺)水平上的伪停留点。例如将BlindRegion设为无穷大,在遭遇图2所描述的情形时,A处停留点和B处停留点将会被合并(如图5a所示),进而会形成伪停留点。如果设置过小,将会使本应合并为一个停留点的轨迹点群产生两个邻近的停留点,例如在大型建筑物的A侧进入,经过长时间停留后从B侧离开,由于A侧和B侧距离较远(大于BlindRegion),则会在A侧和B侧分别产生两个停留点,实际上停留点CenterOf(A,B)更符合真实情况。BlindRegion参数的具体数值,采用二分法思想逐段逼近对比挖掘效率,采用文献[12]中的参数评判变量漏报率(即漏报数量与用户记录的访问点数量的比值)和误报率(即误报数量与算法挖掘的访问点数量的比值),对8名志愿者1个月的出行轨迹数据进行计算分析,结果表明BlindRegion参数取值范围在200~300 m时识别效果较好。 本文针对空间轨迹停留点识别提取过程中的“伪停留点”和“停留点丢失”问题,提出了基于速度的时间聚类算法和速度聚类算法。在基于速度的时间聚类算法中,首先沿时间轴将速度接近零的记录进行聚类选出候选停留点,然后利用速度阈值过滤候选停留点,得出实际停留点。速度聚类算法则将停留点的提取问题分解为对速度的判断和对GPS信号消失空间区域的判断两个子问题。两种方法算法清晰,效率较高。本文采用C语言和PLpgSQL直接将算法设计成空间数据库PostGIS/PostgreSQL的一个扩展,可以直接使用SQL调用。通过出租车GPS轨迹和行人步行轨迹对两种方法进行了验证,结果表明基于速度的时间聚类方法能很好地适用于采样间隔较恒定、一般不存在长时间轨迹点缺失的数据,而速度聚类算法能更好地适用于可能存在长时间轨迹点缺失的步行数据。在后续的研究中会加入对轨迹点特征的判断以确定自动采用何种算法对相应的轨迹进行处理。 [1] 陈康,黄晓宇,王爱玉,等.基于位置信息的用户行为轨迹分析与应用综述[J].电信科学,2013(4):118-124. [2] 张德干,王冬.面向LBS的服务匹配方法研究[J].计算机科学,2012,39(3):19-22,61. [3] 马林兵,李鹏.基于子空间聚类算法的时空轨迹聚类[J].地理与地理信息科学,2014,30(4):7-11,127. [4] ZHENG Y,ZHANG L,MA Z,et al.Recommending friends and locations based on individual location history[J].ACM Transactions on the Web (TWEB),2011,5(1):3-9. [5] AlVARES L O,BOGORNY V,DE MACEDO J A F,et al.Dynamic modeling of trajectory patterns using data mining and reverse engineering[A].Tutorials,Posters,Panels and Industrial Contributions at the 26th International Conference on Conceptual Modeling-Volume 83[C].Australian Computer Society,Inc.,2007.149-154. [6] BOGORNY V,KUIJPERS B,AlVARES L O.ST-DMQL:A semantic trajectory data mining Query language[J].International Journal of Geographical Information Science,2009,23(10):1245-1276. [7] ASHBROOK D,STARRIER T.Using GPS to learn significant locations and predict movement across multiple users[J].Personal and Ubiquitous Computing,2003,7(5):275-286. [8] KANG J H,WELBOURNE W,STEWART B,et al.Extracting places from traces of locations[J].ACM SIGMOBILE Mobile Computing and Communications Review,2005,9(3):58-68. [9] AlVARES L O,BOGORNY V,KUIJPERS B,et al.A model for enriching trajectories with semantic geographical information[A].Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems[C].2007.1-8. [10] PALMA A T,BOGORNY V,KUIJPERS B,et al.A clustering-based approach for discovering interesting places in trajectories[A].Proc.of ACM Symposium on Applied Computing[C].2008.863-868. [11] ZHOU C,FRANKOWSKI D,LUDFORD P,et al.Discovering personally meaningful places:An interactive clustering approach[J].ACM Transaction on Information Systems,2007,25(3):1-31. [12] 吕明琪.基于轨迹数据的语义化位置感知计算研究[D].杭州:浙江大学,2012.19-38. [13] 齐凌艳,陈荣国,温馨.基于语义轨迹停留点的位置服务匹配与应用研究[J].地球信息科学,2014,16(5):720-726. [14] 金美含.基于PostgreSQL/PostGIS的原生轨迹数据库研究[D].长沙:中南大学,2014.11-21. [15] https://www.postgresql.org/docs/9.5/static/index.html.2016-08-11. [16] 张俊涛,武芳,张浩.利用出租车轨迹数据挖掘城市居民出行特征[J].地理与地理信息科学,2015,31(6):104-108. [17] 何雯,李德毅,安利峰,等.基于GPS轨迹的规律路径挖掘算法[J].吉林大学学报(工学版),2014,44(6):1764-1770. Algorithm Study for Stay Points Recognition of Spatial Trajectory Based on Velocity HOU Ying-chao,WANG Pan-cheng,LIU Xing-quan,TENG Jie (DepartmentofGeo-informatics,SchoolofGeosciencesandInfo-Physics,CentralSouthUniversity,Changsha410083,China) Stay point recognition is a key step to convert spatial trajectory to semantic trajectory.Velocity is employed to recognize stay points.Velocity-based time clustering algorithm and velocity clustering algorithm are presented to solve pseudo stay points and losing of stay points.Given time threshold,trajectory points are clustered by velocity-based time clustering algorithm along the time axis to get candidate stay points,then real stay points are filtered out by given velocity threshold.To avoid missing stay points,the velocity clustering algorithm divides the stay point recognition task into two phases:1)Stay point candidates are obtained through the judgment of velocity;2) Real stay points are filtered out from stay point candidates by the given spatial distance threshold.Experiments show that velocity-based time clustering algorithm can recognize stay points of the spatial trajectory with stable sampling time interval well,while velocity clustering algorithm can be better adapted to the pedestrian track points which sometimes may disappear for a long time. stay point;spatial trajectory;velocity clustering;time clustering 2016-08-16; 2016-10-20 湖南省自然科学基金项目(10JJ6061) 侯颖超(1987-),男,硕士研究生,主要从事轨迹数据挖掘研究。*通讯作者 E-mail:wangpancheng@csu.edu.cn 10.3969/j.issn.1672-0504.2016.06.011 P208 A 1672-0504(2016)06-0063-06
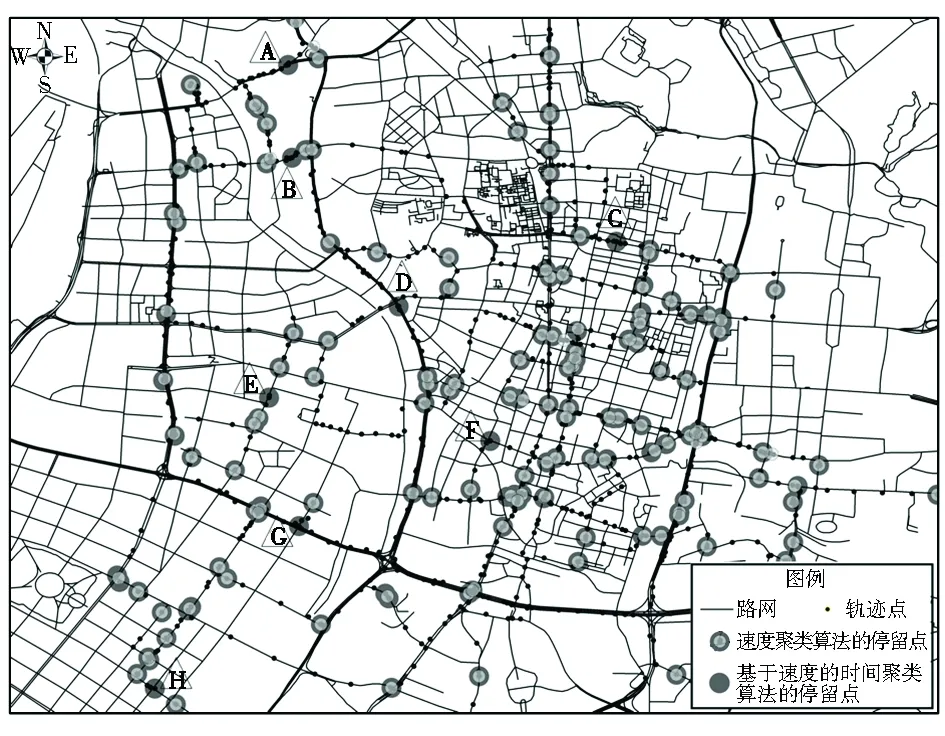
2 算法应用实例及分析


3 结语
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24读友·少年文学(清雅版)(2020年3期)2020-07-24铁道通信信号(2019年6期)2019-10-08制造技术与机床(2019年9期)2019-09-10西南交通大学学报(2018年6期)2018-12-18现代装饰(2018年5期)2018-05-26河北遥感(2017年2期)2017-08-07中国三峡(2017年2期)2017-06-09雷达学报(2017年6期)2017-03-26衡阳师范学院学报(2016年3期)2016-07-10
