
《中国家庭追踪调查》中字词测试的信度和效度分析
2016-06-05 14:19李佩华
中国考试 2016年11期
吴 琼 李佩华
《中国家庭追踪调查》中字词测试的信度和效度分析
吴 琼 李佩华
大型综合性调查经常包含认知测试部分。基于控制调查成本以及降低数据缺失率的要求,大型调查中的认知测试设计一般较为简洁,在这种情况下,其信度和效度可能受到影响。本文运用经典测试理论和项目反应理论两种方式来分析“中国家庭追踪调查”中字词测试的信度和效度。我们还同时比较了3种计分方法,它们分别是原始分计分法、最难题计分法以及基于项目反应理论的计分法。分析结果显示,“中国家庭追踪调查”中字词测试信度较高,其结构效度和效标效度良好。3种计分方法结果的相关度很高,在分析截面数据时没有实质性的差别。
中国家庭追踪调查;字词测试;认知测试;信度;效度;经典测试理论;项目反应理论
认知测试在国内外大型调查中经常出现,如美国的《健康与退休调查》(Health and Retirement Study)、《儿童早期发展追踪调查》(Early Childhood Longitudinal Study)以及国内的《中国健康与养老追踪调查》(China Health and Retirement Longitudinal Study)、《中国家庭追踪调查》(China Family Panel Studies,以下简称CFPS)等。大型调查中的认知测试与独立的认知测试有所不同。前者对控制调查成本以及减少受访者负担以降低数据缺失率更为关注,于是认知测试的设计会尽量简洁。本研究旨在分析全国性大型调查CFPS中字词测试部分在简洁的设计思路下的信度和效度。
CFPS从2010年正式启动,在全国25个省、市和自治区(不含新疆、西藏、青海、内蒙古、宁夏、海南)采用分层抽样的方法,访问样本家庭中的每个人,收集社区、家庭、个人层面的数据,内容涉及经济、人口、健康、教育等各方面;计划每两年对家庭中的核心人员进行追踪。其基线调查已经收集到来自634个社区中14 960个家庭中共57 155个成员的数据。
本文运用经典测试理论方法和项目反应理论方法,分析此调查中字词测试部分的信度和效度,针对CFPS的设计,对字词测试采用3种不同的计分方法,并对其进行比较。
1 CFPS中字词测试
字词测试是CFPS中认知测试的一部分,它适用于调查中年龄在10周岁及以上的人群。访员向受访者出示的图片中的文字,受访者将所示文字朗读出来。由于CFPS是追踪性调查,因此,为了受访者在追踪访问中不受以前测试的影响,字词测试共设计了8套难度相当的试卷,受访者在首次调查中随机接受其中的一套试卷,在下次访问中同样的受访者会接受另外一套试卷。每一套字词试卷共包含34个文字,它们按难度由低到高的顺序排列,受访者从最容易的试题开始,按顺序逐字回答,直到他们连续答错3道试题或全部完成试题为止。为了尽量缩减访问时间,提高访问效率,不同学历的受访者从不同的试题开始回答。具体来说,具有小学及以下学历的受访者从第1道试题开始,具有初中学历的受访者从第9道题开始,具有高中及以上学历的受访者从第21道题开始。这样的设计虽然缩短了调查用时,降低了受访者负担,但它带来了试题层面数据的两种系统性缺失,一是试卷一开始那些被认为对某些受访者太容易的试题(即未呈现的试题),另一种是试卷结尾部分那些被认为对某些受访者太难的试题(即未触及的试题)。
2 心理测量学模型
信度和效度是心理测量学中的基本概念,它们是衡量试卷质量的重要指标。信度是指测量结果的一致性或稳定性,效度是指测量结果能准确反映所要测量的特质的程度。我们运用以下两种心理测量学的模型来分析CFPS字词测试分数的信度和效度。
2.1 经典测试模型
经典测试理论(Classical Test Theory,CTT)认为,我们所观测到的分数(O)由两部分组成:受访者的真实分数(T)以及误差分数(E);误差是随机的(即O=T+E),并且与真实分数没有相关性。这种定义是完全理论性的,因为在现实中,真实分数总是不可知的。信度概念建立在平行测试(Parallel Forms)的概念之上,其值定义为两个平等测试分数的相关系数值;这个定义同样也是理论性的,因为完全平行的测试很难实现。在现实中,信度的计算方法会采用其他方式,而Cronbach’s alpha便是其中运用最为广泛的方法。我们将在下文阐述这种方法。所有基于CTT理论的分析都存在一个的根本局限性,那就是结果受样本的影响很大。
2.2 项目反应理论模型
项目反应理论(Item Response Theory,IRT)认为,受访者有一定的概率答对每一道题,这个概率是受访者能力(通常用θ表示)以及试题性质(如难度、区分度)的综合函数。在IRT理论中,信度的概念主要被测试信息函数(Test Information Function,TIF)取代,与CTT中提供单一的总体信度值不同,TIF能反映出在不同的受访者能力区间该测试所测量的信息量,这个信息量与信度呈正相关。虽然TIF在IRT中运用广泛,但为了便于跟CTT中的信度估计值保持一致,IRT框架也提供了一个综合性信度指数:边际信度值(Marginal Reliability Estimate)。
3 计分方法
由于CFPS字词测试设计的特殊性,其计分方法至少有原始分计分法、最难题计分法、IRT计分法3种,其中前两种基于CTT,后一种基于IRT。
3.1 原始分计分法
原始分计分法根据受访者答对试题的数量来计分,这是CTT框架下最直接和最常用的计分法。在CFPS中,由于不同学历的人群从不同的试题开始,其原始分需要在最基本的计算上稍做调整。具体来说,对于小学及以下学历的受访者,其原始分等于其答对试题的数目;对于初中学历的受访者,其原始分等于其答对试题的数目加上8;对于高中及以上学历的受访者,其原始分等于其答对试题的数目加上20。
3.2 最难题计分法
最难题计分法根据受访者答对的最难一道试题的序号来打分。这种计分法基于一种假设:即试题有绝对的难度顺序,答对难题的受访者具备答对难度较低的所有试题的能力(但由于误差的存在,其实际答案也许不一定总是正确的)。CFPS字词测试的设计思路建立在这个假设之上。
需要提到的是,以上两种基于CTT的计分方法,在计分时均忽略了8套试卷之间难度上可能存在的细微差别,并没有通过统计的方法来进行分数等值计算(Equating)。这种做法出于两方面的考虑:第一,计算出各试卷的平均分相差很小,不同试卷平均分的效应差均不超过0.10(由实际组间差除以整个样本的标准方差得出),而且在大部分情况下不具有统计显著性。在试卷几乎没有实质性差别的情况下,不进行统计性的等值计算效果可能更好,因为统计性等值计算本身也会引进误差。第二,原始分计分法和最难题计分法的相对优势(即其在计算及分数诠释上的便利)在进行分数等值计算后会相对削弱。
3.3 IRT计分法
这种计分方法是建立在由IRT中的双参数lo⁃gistic(以下简称2PL)模型建模的基础上,采用贝氏估计的期望后验法(Expected a Posteriori,EAP)所得的分数。对于每一套试题,IRT模型将答题人分成3组(即按学历而从不同试题开始回答的3组人群),并考虑到这3组人所答试题的不同。相比于CTT来说,IRT的一个特点是即使受访者答的题不一样,IRT也能提供可以直接比较的分数。未呈现给受访者的试题不在计分模型中,而未触及的试题算做错题。为了统计估算的需要,第一组受访者能力的平均值预设为0,其标准方差预设为1,IRT的分析由统计软件BILOG-MG实施。
4 信度
4.1 CTT信度
在CTT下,我们采用最常用的信度估计方法Cronbach’s alpha,对参与同一套试卷的3个教育组分别计算。Cronbach’s alpha将每道试题都视为一个小测试,然后将同一套试卷中的每道试题相互视为平行测试。从数学意义上来说,Cronbach’s alpha是信度值的一个低估值,其值在0~1之间,越接近1,指示信度值越高。Cronbach’s alpha的局限性在于受试卷试题数量的影响很大,试题数量越多,Cronbach’s alpha值越接近1。前面已经提到过,字词测试的设计使其存在两种系统性缺失,在计算Cronbach’s alpha时,我们将未呈现的试题去除,而将未触及的试题视为错题。因此,对于3个教育组来说,每套试卷的实际长度分别为34道题、26道题和14道题。
4.2 IRT信度
我们采用EAP估计中所计算的经验信度值(Empirical Reliability)作为IRT中信度的估计。经验信度是由真实分数方差除以真实分数方差与误差分数方差的和而得出。在EAP估计中,误差分数方差是样本中所有个体能力后估值的方差的平均数,而真实分数方差直接由样本计算出的EAP得分的方差得出。这个值由BILOG-MG直接计算得出。
5 效度
5.1 结构效度
结构效度(Construct Validity)是指测量结果符合理论设想的科学意义的程度。我们利用Mplus软件将数据与单因子验证性因子分析模型进行拟合。拟合优度由以下3个指数综合判断:RMSEA, CFI和TLI。如果RMSEA不大于0.08,且CFI和TLI都不小于0.90,则模型拟合得较好。除验证性因子分析以外,我们也使用探索性因子分析模型来分析数据。
5.2 效标效度
效标效度(Criterion Validity)是指测量结果与能表示被测概念的标准变量之间的相关性。我们通过分析字词测试分数与两个效标变量的相关性来收集相关效度证据。这两个效标变量分别是CFPS的数学测试以及受访者的教育年限。数学测试是CFPS认知测试的另外一部分,共有4套试卷,每套24道题,这24道题分别来自12个年级,每个年级水平有2道试题。试题也是按其难度排序,具有小学学历及以下的从最容易的第1道题开始测试,初中学历的从第13道题开始测试,高中及以上学历的从第19道题开始测试。CFPS的数学测试采用最难题计分法。受访者教育年限来自受访者自己的陈述,如果其缺失,则从家庭成员的代答中尝试寻找。无论是CFPS数学测试,还是受访者教育年限,并非都是字词测试的黄金效标变量,但受访者的数学能力及其教育年限应该与其识字能力呈现显著的正相关性。
6 结果
本研究的分析共涉及23 980个样本,样本量在8套试卷中大致呈均衡分配,每套试题答题者在2 907~3 072人。样本人群的平均年龄在42岁,约49%为男性。不同套试卷答题者在年龄和性别的平均分布上没有差别。每套试卷中,约有52%的人具有小学及以下文化程度(教育分组1),约30%的人具有初中学历(教育分组2),剩下的18%具有高中及以上学历(教育分组3)。
6.1 信度
表1展示了分试卷和分组得出的Cronbach’s alpha的值和经验信度值。总体来说,信度值处在高区间,最低值为0.85。跟预计相符,基于CTT的信度值Cronbach’s alpha受题量多少(即实际试卷长度)的影响,其值总是在第一组中最大(试卷长度为34道题),第二组其次(试卷长度为26道题),在第三组中最小(试卷长度为14道题);而基于IRT的信度值并没有这样的模式。但不论是CTT,还是IRT,都同样反映出第三组的信度值最小。
6.2 分数分布
表2列出了基于3种计分方法得出的分数分布。原始分计分法和最难题计分法属于同一度量衡,它们具有直接可比性,最难题计分法的平均分稍高于原始分计分法。3种得分都呈负偏态分布,说明处在高分区间的人多于处在低分区间的人。在3种得分中,IRT计分法的偏度(-0.46)相对其他两种计分较高。与正态分布相比,3种得分的分布都相对扁平(峰度为负值),而IRT计分法的峰度(-0.80)比其他两种得分更接近零。

表1 基于CTT和IRT方法的信度值
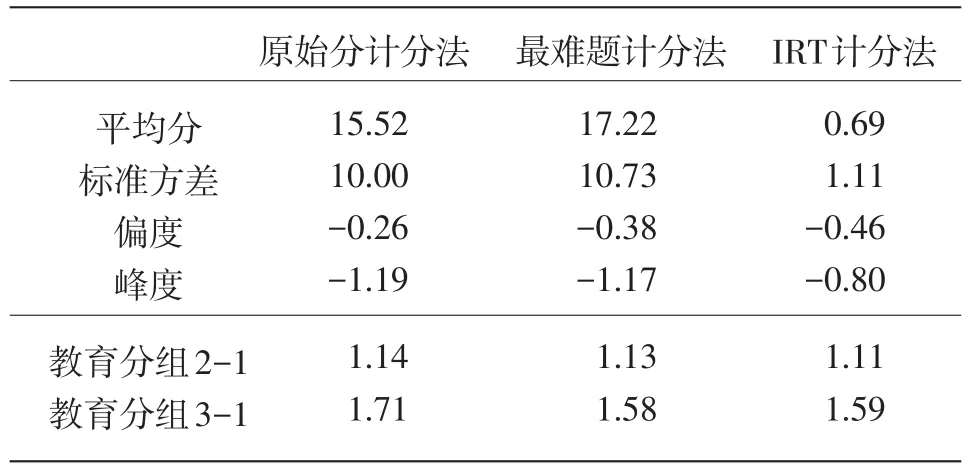
表2 不同计分法的分数分布和描述性统计结果
表2中同时列出了各教育分组的平均分数和标准方差。教育程度高的小组的平均得分明显高于教育程度低的小组,这样的模式虽然跟原始分计分法和最难题计分法的规则有很大关系,但IRT计分法并没有强制这样的模式。由于3种计分法并不都处于同样的度量衡,为了方便比较,我们计算了效应差。我们注意到最难题计分法和IRT计分法得出的教育组间效应差非常类似,但原始分计分法得出的组1和组3之间的差别要大于基于其他两种计分法得出的差别。
我们也计算了3组分数之间的相关系数(见表3),3组分数之间的相关性非常高,相关系数的值不低于0.95。

表3 3种计分法的相关系数值
6.3 结构效度
表4所显示的各拟合优度指数反映出数据和单因子验证性因子模型拟合得比较充分。对于8套试卷所产生的数据来说,RMSEA处在0.05到0.08之间,CFI和TLI高达0.99。探索性因子模型的结果也支持一个因子的假设,最大的特征值(约在28左右)远大于第二大特征值(约在2左右),我们不赘述详细的探索性因子模型分析结果。
6.4 效标效度
总体来说,3种计分法的得分与两个效标变量(CFPS数学测试得分、教育年限)有很高的相关性(如图1和图2所示)。具体来说,原始分计分法(NR)在3类得分中与两个效标变量的相关度在每套试题中都最高;IRT计分法的得分与两个效标变量的相关度在大部分情况下都高于最难题计分法,因此总体上最难题计分法(HSN)与效标变量的相关度最低。我们认为最难题计分法与效标变量相关度最低的这一发现是相对稳健的,因为数学测试得分的计分法也是最难题计分法。

图1 三种计分法结果与数学测试分数的相关系数

表4 单因子验证性因子模型拟合优度结果

图2 三种计分法结果与教育年限的相关系数
7 结论与讨论
本研究运用CTT和IRT方法对CFPS中的字词测试进行了信度和效度的检验。信度由Cronbach’s alpha以及IRT经验信度系数得出,效度通过因子分析以及相关性分析得出。无论是CTT还是IRT方法得出的初步结论都一致,CFPS的字词测试具有较高的信度,其结构效度较好,与现有的效标变量相关度很高。
本研究特别比较了3种计分法(原始分计分法,最难题计分法和IRT计分法),基本结论是这三者之间高度一致,运用任何一种计分法得出的结论都不会对研究结果产生实质性区别。尽管如此,我们还是发现了小的差别。首先,IRT计分法得分的分布在三者当中偏度最高(-0.46),峰度最接近正态分布(-0.80);其次,原始分计分法得出的教育分组1到组3之间的组间差大于由其他两种计分法得出的组间差;再次,原始分计分法与两个效标变量(CFPS数学测试分数、教育年限)的相关度最高,最难题计分法最低。如果一定要在三者之间推荐一个分数,原始分计分法也许有微弱优势,这主要是因为其在计算方法上和分数诠释方面都比IRT更加便捷。但要注意的是,这种推荐只适用于截面数据的分析。如果要做追踪分析的话,也许其他的计分法(如IRT)更加适用。
本研究的一个主要局限性是缺乏最佳的效标变量。在理想的状态下,我们希望拥有受访者在另一个字词测试方面的分数,将这个分数作为效标变量。但这种黄金的效标变量不存在,我们只能借助于与识字水平高度相关的其他变量。另一个局限性是我们只有该试题测试的基线数据,无法分析测试对时间的敏感性。但我们的样本人群中有很广的年龄层,相关的分析已经发现测试分数和年龄有很强的相关性,具体来说,对于16岁以下的青少年来说,其分数随年龄增长,而对于成人来说,其分数随年龄降低。
当大型调查中包含认知测试时,其设计通常要在很大程度上考虑调查成本控制以及受访者负担。在这种情况下,信度和效度也许要受影响。本研究的初步分析发现CFPS字词测试的信度和效度均比较理想。
[1]谢宇.中国家庭追踪调查(2010)用户手册[C/OL].[2016-10-12]. http://www.haihongyuan.com/zhexuelishi/160948.html.
[2]李灿,辛玲.调查问卷的信度与效度的评价方法研究[J].中国卫生统计,2008,25(5).
[3]NOVICK M.The axioms and principal results of classical test theory [J].Journal of mathematical psychology,1966(3),1-18.
[4]韩耀风,郝元涛,方积乾.项目反应理论及其在生存质量研究中的应用[J].中国卫生统计,2006(6).
[5]HAMBELTON R.Emergence of item response modeling in instru⁃ment development and data analysis[J].Medical Care,2000(38): 60-65.
[6]HAMBELTON R.SWAMINATHAN H.Item Response Theory: Principals and Applications[M].Boston:Kluwer Academic Publish⁃ers,1985.
[7]KOLEN M J,BRENNAN R L.Test equating,scaling,and linking [M].New York,NY:Springer,2004.
[8]BIRNBAUM A.Some latent trait models and their use in inferring an examinee’s ability[M]//LORD F M,NOVICK,M R(Eds.).Statis⁃tical theories of mental test scores.MA:Addison-Wesley,1968.
[9]SIJTTSMA K.On the use,the misuse,and the very limited useful⁃ness of Cronbach’s Alpha[J].Psychometrika,2009(74):107-120.
[10]MUTHEN L K,MUTHEN B O.Mplus User’s Guide[M].7th ed. Los Angeles,CA:Muthén&Muthén,2013.
[11]HU L,BENTLER P.Fit indices in covariance structure modeling: sensitivity to underparameterized model misspecification[J].Psy⁃chological Methods,1998(3):424-453.
[12]徐宏伟,骆为祥.中国家庭追踪调查2010年综合变量(1):字词与数学测试,中国家庭追踪调查技术报告系列(CFPS-11)[C/ OL].[2016-10-12].http://www.docin.com/p-1729243739.html.
Psychometric Properties of the Literacy Test from China Family Panel Studies
WU Qiong&LI Peihua
Many large scale surveys contain cognitive assessment modules.The design of those cognitive tests is often brief in order to minimize test administration cost and maintain acceptable response rates.This paper evaluated the psychometric properties of the literacy test from China Family Panel Studies(CFPS)using both Classical Test Theory(CTT)and Item Response Theory(IRT)approaches.We also compared three different scoring methods:number-right,highest sequence number,and IRT scaled scores.Both CTT and IRT approaches provided positive evidence for reliability and validity of test scores from the CFPS literacy test.Three scoring methods yielded results that were highly consistent with one another.
Reliability;Validity;Cognitive Assessment;Literacy Test;Classical Test Theory;Item Response Theory;China Family Panel Studies
G405
A
1005-8427(2016)11-0044-7
(责任编辑:周黎明)
吴 琼,女,北京大学中国社会科学调查中心,副研究员(北京 100871)
李佩华,女,美国宾夕法尼亚州州立大学,副教授(美国宾夕法尼亚州 16802)
猜你喜欢
世界科学技术-中医药现代化(2021年7期)2021-11-04
逻辑学研究(2021年3期)2021-09-29
科教新报(2019年2期)2019-09-10
中国非营利评论(2019年1期)2019-06-18
电子制作(2019年9期)2019-05-30
统计与决策(2018年14期)2018-08-22
听力学及言语疾病杂志(2015年5期)2015-12-24
天津护理(2015年4期)2015-11-10
中国康复理论与实践(2015年7期)2015-05-09
中国医学科学院学报(2013年3期)2013-03-11
